
- 1计算机科学与技术心得,计算机科学与技术学习心得 (4)
- 2第12章 图像轮廓 -- 12.4 轮廓拟合_一个弧形宽轮廓,中间的边缘轮廓不完整,怎么拟合完整
- 3计算机网络基础知识 学习笔记_计算机网络技术基础第五版笔记
- 4Python机器学习案例——基于用户的电影推荐系统_电影评分推荐系统代码_使用机器学习的电影推荐系统
- 5This beta version of Typora is expired, please download and install a newer version_this beta version of typora is expired,please down
- 6Redis实现延迟队列方法介绍_redis 延时队列
- 7Git常用命令总结_git config --global
- 8关于最大似然与交叉熵损失函数和最小二乘法的思考_最小二乘损失函数与交叉熵损失
- 9Stata无法安装外部命令解决办法 cannot write in directory
- 10TS中的InstanceType函数和Typeof 操作符
人脸识别之表情识别(七)--面部表情识别阶段综述_表情识别目前遇到的问题
赞
踩
转自:https://blog.csdn.net/app_12062011/article/details/80504960
本文主要参考论文《Deep Facial Expression Recognition: A Survey》
首先我们来了解一下表情识别的相关背景知识以及发展近况。人脸表情是最直接、最有效的情感识别模式。它有很多人机交互方面的应用,例如疲劳驾驶检测和手机端实时表情识别。早在20世纪Ekman等专家就通过跨文化调研提出了七类基础表情,分别是生气,害怕,厌恶,开心,悲伤,惊讶以及中立。然而不断的研究发现这七类基本表情并不能完全涵盖人们在日常生活中所表露的情感。针对该问题,2014年在PNAS上发表的一篇文章研究提出了符合表情的概念,并且指出多个离散的基础表情能结合在一起从而形成复合表情。例如当人们遇到意外的惊喜时,应该是既开心又惊讶的。
人脸表情识别的具体应用如人机交互,驾驶员疲劳检测,医疗,谎言检测等(好像都不是很靠谱)。
Facial Expression Recognition 面部表情识别,以下简称FER,另外一个概念AFEA,Automatic Facial Expression Analysis。完整的FER包含静态图像FER和动态序列FER。静态图像FER,就是我们通常意义上的图片表情识别了,动态序列FER是基于视频序列建模,如RNN方式等。下面是历年来,FER上面的发展,主要是算法和数据集。

其实可以看出,主要还是基于静态图像的FER。主流的方式,从传统的手工特征(LBP,LBP-TOP等),浅层学习(SVM,Adaboost等),深度学习(CNN,DBN,RNN)。从2013年开始,开始有了表情识别的比赛,如FER2013,EmotiW等。
整个人脸表情识别的研究是跟随人脸识别的发展而发展的,人脸识别领域比较好的方法会同样适用于表情识别(这里主要是指静态图像FER,毕竟是个分类问题,跟人脸识别类似)。该综述从算法和数据库两方面调研了人脸表情识别领域的进展。在数据库方面,表情识别逐渐从传统的实验室统一控制下的小样本量数据库转移到了现实生活中的多样化大规模数据库。在算法方面,传统的手工设计特征乃至浅层学习特征也不再能很好地适应现实世界中种种与表情无关的干扰因素,例如光照变换,不同的头部姿态以及面部阻挡。于是越来越多的研究开始将深度学习技术运用到了人脸表情识别之中,来解决上述问题。
基于深度学习的面部表情识别,主要分以下3个过程。
1.预处理
所谓的预处理,是将计算特征之前,排除掉跟脸无关的一切干扰,因此,就有了人脸检测,人脸对齐,归一化等过程,主要有:人脸检测,人脸对齐,数据增强,人脸归一化。
人脸检测不做赘述。
人脸对齐,主流的有IntraFace,采用SDM算法,提供49个点。其他的如Mot,DRMF,Dlib,MTCNN,DenseReg,TinyFaces.作者这里的人脸对齐,主要是指根据人脸,检测出人脸定位点landmark.
数据增强,包含在线和离线两种。
主流的离线数据增强,包含随机扰动,变换(旋转,平移,翻转,缩放,对齐),噪声添加如椒盐噪声,斑点噪声,以及亮度,饱和度变化,以及在眼睛之间添加2维高斯随机分布的噪声。同时,还有其他的如GAN生成脸,3DCNN辅助AUs生成表情。但是,GAN生成的脸,是否对网路模型有性能提升,还没有证实。
在线数据增强,包含Crop,水平翻转等,主要的意思是指,在预测时,可以一次性对测试数据进行Crop,翻转等操作生成多张类似的测试图,然后每张测试出图预测出的输出做均值,这主要是基于随机扰动训练的模型,需要在测试时计算均值的原因而定的。
完整的FER系统示意图
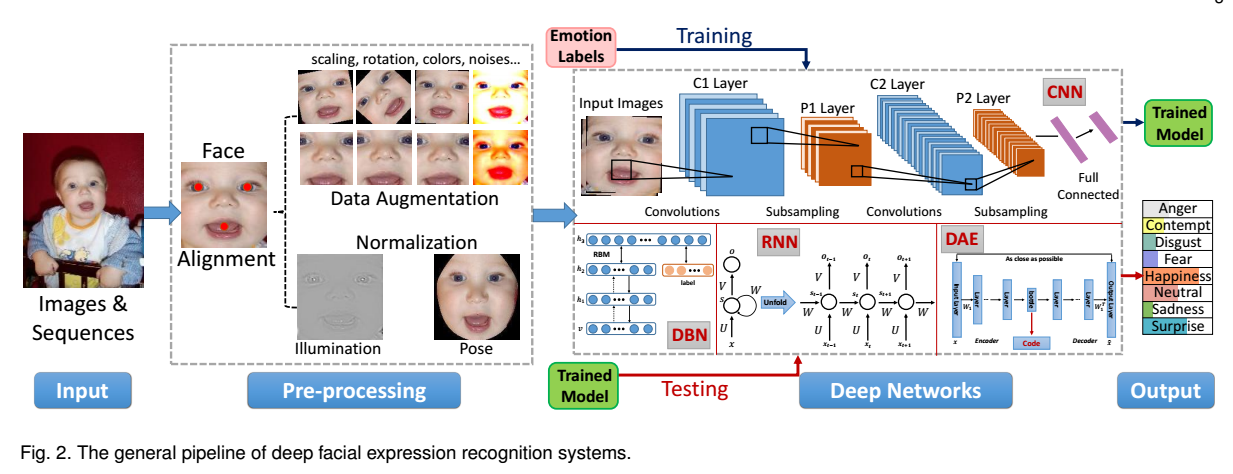
人脸归一化,主要是指亮度归一化和姿态归一化(就是人脸对齐拉正)。
亮度归一化,不仅包含亮度调整,也包含了对比度调整,常见的对比度调整方式 有直方图归一化,DCT归一化,DoG归一化,相关论文证明直方图归一化效果最稳定,适应各种网络模型,也有论文证明,全局对比度归一化,局部归一化,直方图归一化,三种方法中,全局对比度归一化和直方图归一化效果最好。所以,建议直方图归一化联合亮度归一化一起。
姿态归一化,其实这个是人脸项目中影响最大的了。目前大多数还是在小角度内,2D 的landmark对齐,比较可靠的方向是3D landmark,有通过图像和相机参数估计出来的,也有通过深度传感器测量然后计算出来的。比较新的估计模型有:FF-GAN,TP-GAN,DR-GAN等。
2.深度特征学习
这里不做过多描述,主要是基于CNN的网络模型,具有非常高性能的特征表达能力。特别适合基于图像的分类问题,另外一个基于DBN网络的特征提取,以及DAE转门用作特征提取。最后,还有一部分是基于序列建模的RNNs,如LSTM等。
3.面部表示分类
这里主要是说,可以基于深度学习,直接学习特征,预测概率(softmax),也可以把学习的深度特征,用SVM等浅层分类器进行分类。
下面开始介绍FER涉及到数据集。
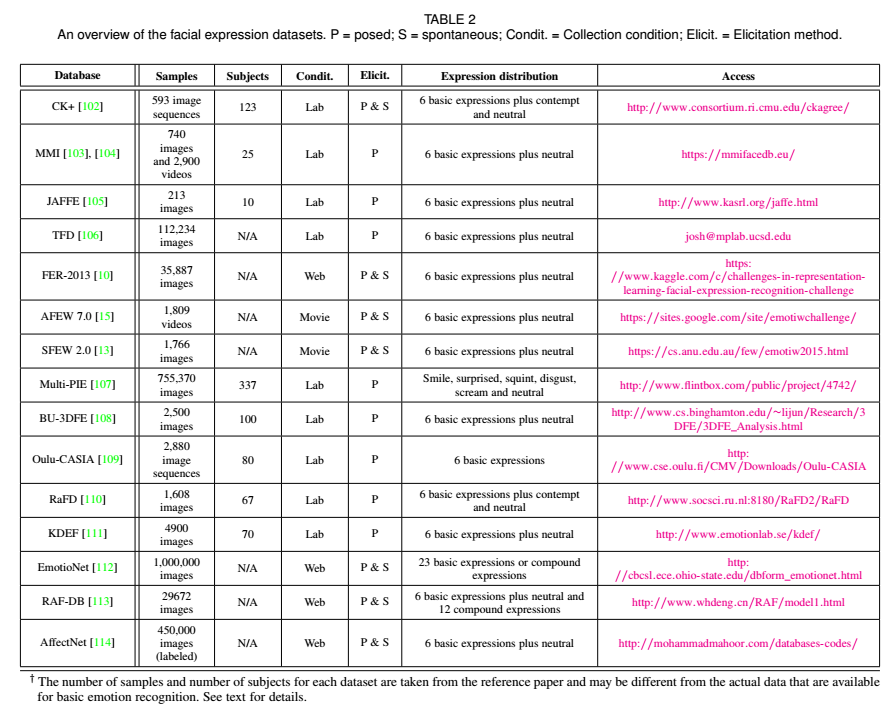
上图展示了作者收集整理的FER数据集,很全面,基本涵盖了从开始到当下,公开的数据集。
目前的数据结果分析:
这里分两部分,包含基于静态图像和基于动态序列。
1.静态图像FER进展
基于静态图像的FER,在使用深度学习进行分类时,分以下几种情况:
1.1预训练模型fineturn.
主要采用分类网络,或者人脸识别网络,相对来说,后者更好。只是有各种fineturn的方式,比如分级、固定某些层,不同层采用不同数据集,如下图:
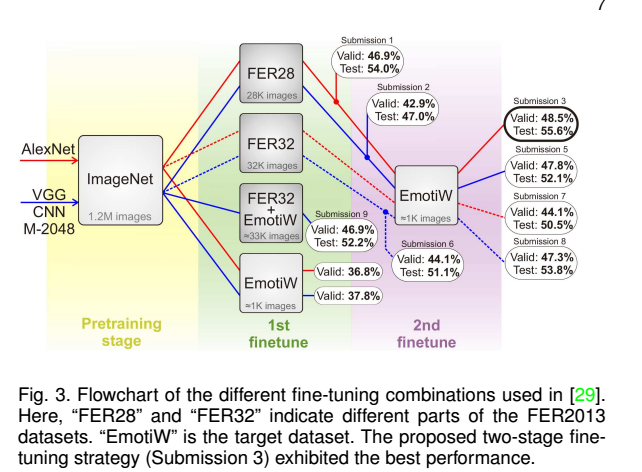
还有,考虑到人脸识别模型弱化了人脸情绪差异,可以用人脸识别模型提取特征,然后用表情识别网络消除人脸识别模型带来情绪差异的弱化。也就是这里人脸识别模型起到初始化表情网络的作用。

1.2差异化网络输入
实际上就是,除了常见的输入RGB原始脸部数据给网络,还有一些手工特征,如SIFT,LBP,MBP(人脸识别之表情识别(五)--MBP+CNN),AGE(3D angle,gradient edge),NCDV,还有LBP+HOG+Gray@51点landmark生成DSAE,PCA以及裁剪出五官进行特征学习而不是整个脸部等。个人觉得这个是有道理的,纯粹脸部表情,没有必要将全部脸部数据传递进去提取特征,毕竟,网络模型的权重更新,依据脸部全部数据的话,虽然大多数特征是好的, 但谁也说不好,脸部与表情无关的数据,对表情识别的贡献多大,以及生成的特征是否有效,因为最终的输出是部分节点的激活结果。
1.3辅助块或者层改进
基于经典CNN网络架构,一些人设计了更好的网络块或者网络层,如HoloNet(CReLU代替ReLU以及改进的残差块),还有下图这种结构(多模块监督):

需要注意的一点是,Softmax在表情识别领域,不是很合适,毕竟表情的类间区分本来就不高,这也是难点所在,所以,用人脸识别模型中的改进损失如A-Softmax等效果比普通分类的Softmax普遍好。但是,个人觉得思路还是有问题。作者也整理了了几种针对表情分类的loss,如基于center loss 改进的ISLand loss(增加类间距离),LP Loss(locality-preserving,减小类内距离)。基于triplet loss改进的exponential triplet-based loss(网络中增加困难样本的权重),(N+M)-tupes cluster loss(降低anchor的选择难度,以及阈值化triplet不等式),如下图:


1.4网络集成
集成的方式,在机器学习上面非常成功,如Adaboost就是一个很成功的例子,这里讲的是网络结构的集成,要考虑两点,一是网络模型要有充分多样性这样才可以具有互补性,二是一个可靠的集成算法。
对于深度学习来说,不同的训练数据,不同的网络架构,甚至不同的网络参数,不同的预处理,都有可能产生不同的网络模型,这个不多说了。
对于集成算法,这里需要考虑两点,一个是特征集成,另外一个就是输出的决策集成,对于特征集成,最常见的是不同网络模型的特征直接连接,还有如下图:
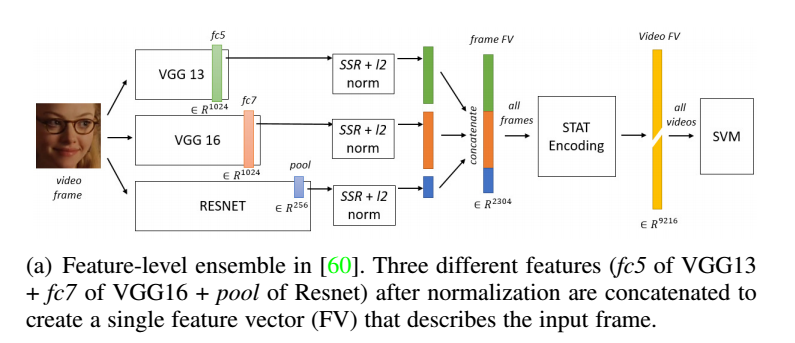
决策集成,如多模型输出加权投票,简单平均,加权平均,甚至可以一起学习每个模型的集成权重。
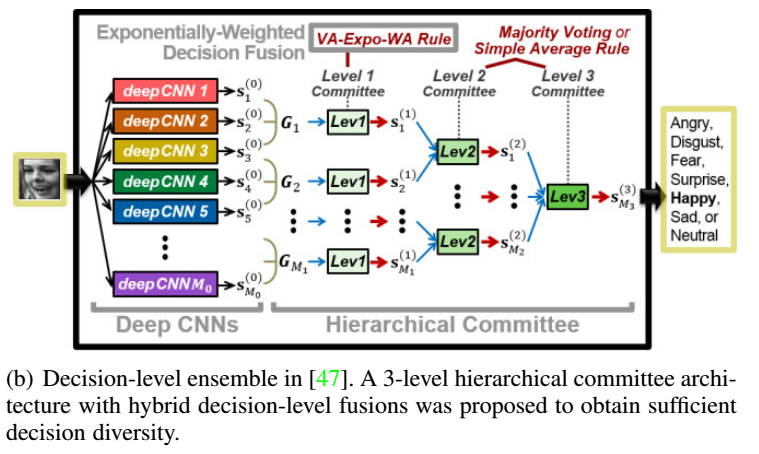
1.5多任务网络
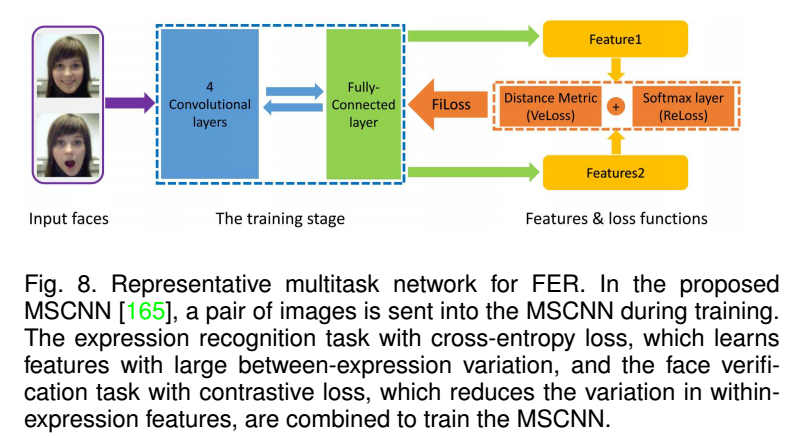
这里的多任务网络,不是指常见的检测和对齐一起做,而是表情和landmark一起、表情和人脸验证一起、以及表情和AUs分类一起。如disBM(高阶玻尔兹曼机),学习与表情有关的主要坐标以及后续的表情分类,值得注意的有SJMT解决AUs的多标签用以识别AUs,IACNN包含两种提取网络,一路用表情感知测度学习提取判别表情类别的特征,一路用身份感知测度学习提取表情中不变特征,类似的还有MSCNN,基于监督的表情识别和人脸验证一起,如下图
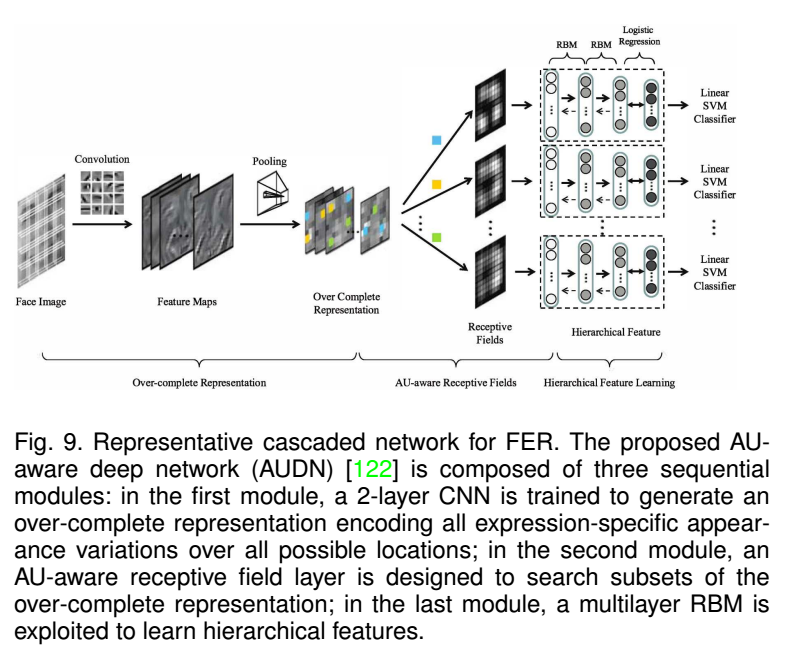
1.6网络级联
如下图,就是一个网络级联过程
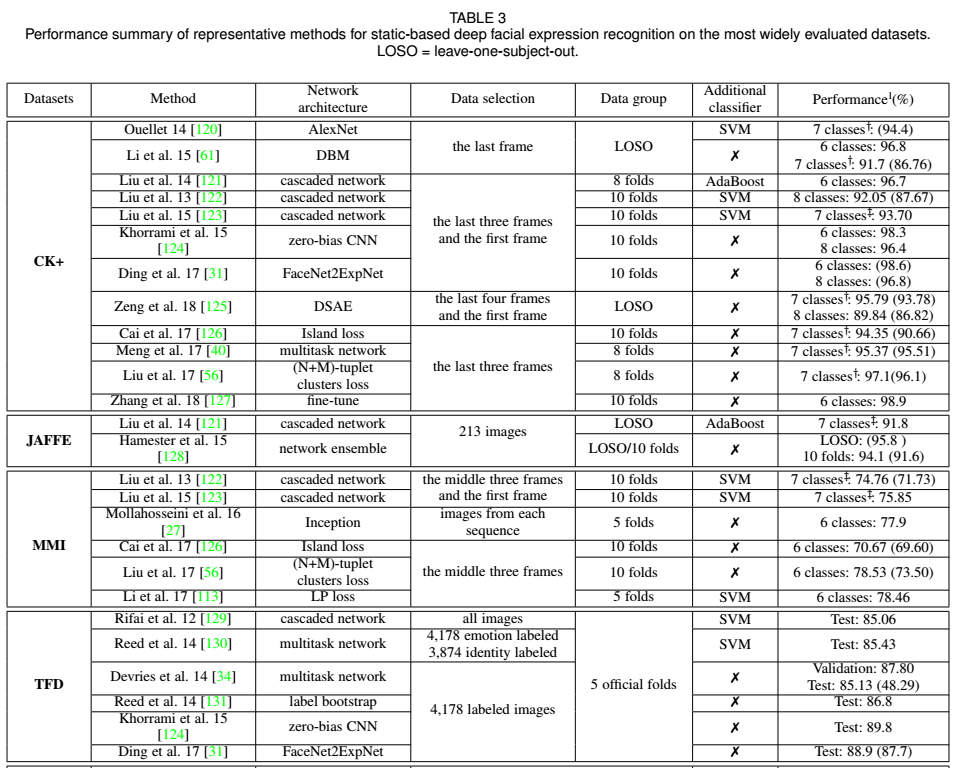
最后,给出一个目前在不同数据集上的结果图。

2.动态序列FER进展
基于时空上下文的表情分析,相比静态图像更全面,毕竟,人的表情,是在真实世界的一个时间和面部空间里变化的结果。这里的动态序列,主要是指表情在视频序列中的变化。
2.1帧聚合
考虑到表情的时空变化,单独的统计每帧的结果作为类别输出不太合适,因此,需要针对一段帧序列给出一个表情结果,这就涉及到帧聚合,也就是用一个特征向量,表示一段时间序列帧。通常有两类,一类是决策级帧聚合,一类是特征级帧聚类。
对于决策级帧聚合,例如有生成所有帧的表情类别概率,并连接成一个固定帧长度向量再进行分类。具体分类序列时,考虑到表情是一个实际由开始到结束的变化过程,因此,作者比较了这些向量最后的决策机制,如去平均,最大,或者WTA,平方再平均等等,具体可以看看论文。
对于特征级帧聚合,主要是指针对每帧的原始数据,提取特征,联合多帧,再做处理,如有人针对这些联合帧的特征数据,计算特征向量(eigenvector),协方差矩阵,以及高维高斯模型。还有人提出STAT,即统计编码模型,联合了均值,方差,最小,最大值等。还有采用GMM进行编码生成Fisher 向量的。有兴趣的可以看论文。这里不再赘述了。
2.2强度表达网络
这里的强度,是指在一段序列中,所有帧表现出某个表情的程度,一般中间位置最能表达某个表情,即为强度峰值。大多数方法,都关注峰值附近而忽略了开始和结束时的低谷帧。这部分,主要介绍几个深度网络,输入是具有一定强度信息的样本序列,输出是某一个类表情中不同强度帧之间的相关性结果。如PPDN(peak-piloted),用以内在表情序列里帧之间相关性识别,还有基于PPDN的级联PPDN网络DCPN,具有更深更强的识别能力。虽然,这些网络,都考虑了一段序列里的表情变换,甚至为了计算表情的变化趋势,设计了不同的损失函数,但是,真心觉得,这种代价,对于工程来说,其实是没有意义的。有兴趣的,可以看看论文里对应的方法,这里不再赘述了。
2.3深度时空FER网络
其实 ,到这里,你可以看出,上面的帧聚合,强度表达网络,都是属于传统的结构化流程,这里的时空网络,形成了端到到的序列分类。即输入单独的图像序列,输出某一类表情的分类结果。主要肯定是RNN啦,还有C3D:
RNN:这个不用多说,就是专门为序列建模的,经典的有LSTMs,GRUs等。
C3D:其实就是3D卷积核,对于通常图像上的2D空间卷积,沿着时间轴增加了一个时间维度,就是3D时空卷积。如3DCNN-DAP:

当然,你也可以不用考虑时间维度,直接将一段序列数据,拼接成大向量,进行CNN分类。这种思路简单粗暴如DTAN。
面部landmark运动轨迹
通过研究五官的变化轨迹,来分析表情变化,如DTGN,深度空间几何网络,联合每帧landmark点的x,y坐标值,归一化之后,作为一个运动轨迹维度。或者计算landmark特征点的成对L2距离特征,以及基于PHRNN用于获取帧内的空间变化信息。还有根据五官将landmark点分成4块,输入到BRNNs,定位局部特征,如下图:

级联网络
跟之前静态图像的级联网络思路一样,主要是CNN提取特征,级联RNN做序列特征分类。如LRCN,级联CNN与LSTM,类似的,还有级联DAE作为特征提取,LSTM进行分类,还有ResNet-LSTM,即在低级CNN层,直接用LSTM连接序列之间的低级CNN特征,3DIR用LSTM作为一个单元构建了一个3D Inception-ResNet特征层,其他还有很多类似的级联网络,包括,用CRFs代替了LSTM等等。
网络集成
如两路CNN网络模型用于行为识别,一路用多帧数据的稠密光流训练获取时间信息,一路用于单帧图像特征学习,最后融合两路CNN的输出。还有多通道训练,如一通道用于自然脸和表情脸之间的光流信息训练,一路用于脸部表情特征训练,然后用三种融合策略,平均融合,基于SVM融合,基于DNN融合。也有基于PHRNN时间网络和MSCNN空间网络相结合来提取局部整体关系,几何变化以及静动态信息。除了融合,也有联合训练的,如DTAN和DTGN联合fineturn训练。

最后,给出一个动态序列分析在各个数据集上的目前最佳效果:

补充:
遮挡和非正脸头部姿态,是两个FER上主要的问题,对于遮挡问题,有人尝试用DBNs提取特征,排除遮挡干扰,也有尝试用两个CNN网络,一个用于没有遮挡干扰数据训练,一个用遮挡数据训练。对于非正面头部姿态的影响,除了上文提到的SIFT特征,做3D/2D透视投影转换,将该转换过程直接放置在CNN模型中,其他,基本就是3D landmakr估计了。
还有,增加额外的数据,如IR近红外,深度数据等,用于辅助光线影响,3D真实脸部数据等。
总结:
1.静态/动态都有一定的应用空间,后者更接近真实客观表情理解。
2.可以看出,除了后面网络集成,网络级联更多的用在刷分,工程意义不大,当然,也不能说没有,在没有资源限制时可用。
3.主要关键过程有预处理,比如人脸检测,人脸对齐,亮度,对比度归一化,姿态归一化,保证输入数据干扰影响较少。
4.数据增强与常见的图片数据扩展一致,深度网络包括CNN分类/识别/RNN分类,与常见分类任务一致。
5.可以用预训练的分类/人脸识别网络fineturn,可以针对表情修改对应的损失函数,也可以局部或者针对某些层,块进行改进
6.可以将DL和Handcrafted特征结合,增加网络输入的多样性。
7.可以CNN+RNN进行端到端的序列识别。具体CNN设计,以及CNN+RNN如何设计(级联,集成,或者联合)需要实际结果测试你确认,说白了,这几种结合方式都有用。

