
- 1高手过招, 为什么 Redis Cluster 是16384个槽位?_redis16384个槽
- 2android约束布局ConstraintLayout_constraintlayout 比例
- 3oracle常见单词_数据库中常用的英文单词
- 4Python与Excel的完美结合:操作技巧与自动化应用
- 5完全卸载Android Studio的方法_android studio卸载
- 6【前端Vue3】——JQuery知识点总结(超详细)
- 7(openstack搭建)openstack云平台部署-详细完整教程_openstack部署
- 8往届生和应届生、同等学历复试材料有什么区别?
- 9文本识别综述 <软件学报_王建新等、中国图象图形学报_刘崇宇等>
- 10探索FTP:原理、实践与安全优化_ftp s3存储
疯狂的 H100:现代 GPU 体系结构浅析,从算力焦虑开始聊起
赞
踩
得益于 ChatGPT 引发的新一波 AI 浪潮,2023 年各大科技公司大量采购 NVIDIA 生产的 H100 等系列 GPU。据 NVIDIA 2024 财年第二季度财报[1],NVIDIA 收入创下纪录新高,达到 135.07 亿美元,远超分析师给出 110.4 亿美元预期。目前市场上对 H100 的需求在 43.2 万张左右,每张售价约 3.5 万美元,受限于台积电的产能,2023 年 NVIDIA H100 的产量早已销售一空,目前 GPU 的短缺或将持续到 2024 年[2]。
在 eBay 上,一张 NVIDIA H100 SXM 80GB 的 GPU 售价目前 (2023.10) 已经被炒到了 4.5 万美元[3]。于此同时,估值仅 20 亿美元的 CoreWeave 以 NVIDIA H100 为抵押,却拿到了 23 亿美元的债务融资[4]。要知道,CoreWeave 手上目前并没有这么多的等价 NVIDIA H100,它有的仅仅只是 NVIDIA 的 H100 供货承诺。仿佛过去二十年国内狂飙的土地财政一般,房地产商通过土地拍卖拿到的土地,又可以快速抵押拿到银行的贷款,NVIDIA H100 在当下也成为了如土地一般的硬通货。
本文尝试深入到硬件,从英伟达 H100 系列 GPU 入手,解析现代 GPU 体系结构,试图去理解在大模型继续狂飙的当下,为何卖的如此之贵的 H100 还能够卖的这么好。正式开始之前,我们可以先听听 GPU Utils 的这首「GPUs Are Fire」[5],感受大家对于 H100 的热情。
TLDR
本文所有的资料来自于互联网公开信息,更多是从程序员的角度去理解现代 GPU 的体系结构,强烈推荐大家阅读本文附录的原始资料,文中的观点与本人雇主无关。
除了以 H100 为代表的英伟达 GPU,市场上同场竞争的还有很多其他类型的 GPU:比如来自 AMD、Intel 的 GPU,以华为昇腾 910 AI 加速芯片,Google 的 TPU,AWS 自研 Tranium 和 Inferentia,乃至来自壁仞等创业公司的 GPU 等。因为工作中主要使用的是英伟达的 GPU,本文目光也主要集中在英伟达的 H100。
随着时代的发展,最早源于图形渲染领域的 GPU,不断在 HPC、图形学和深度学习这三个领域游走,前几年还在加密货币中发挥了重要作用。本文不太会详细介绍其图形渲染方向的能力,更多侧重于像计算侧能力的演进与发展。 受限于篇幅,本文暂时不会涉及 MIG 和机密计算等新特性,也不太介绍 NVLink 等通信能力。
作为一名软件工程师,本文作者对于硬件的理解也并不算深刻与全面,甚至可能会存在偏差与错误,在介绍相关方向的时候也肯定会存在遗漏,欢迎大家交流与指正。
本文相对较长,全文超过 10000 字,阅读预计需要 20 分钟左右。建议关注、收藏后观看,也可访问我的博客获得更好阅读体验 https://loop.houmin.site/context/gpu-arch
Technical Terms
在真正开始之前,这里先简单介绍下本文可能会碰到的技术缩略语,现在不需要深刻理解其含义,只需要有初步印象即可。
| 英文 | 缩写 | 中文释义 |
|---|---|---|
| FLOPS | Floating point Operations per Second | FLOPS 为每秒浮点数运算次数,FLOPs 则表示浮点运算次数 |
| DGX | Deep-learning GPU Accelerator | NVIDIA 推出的一系列专门用于加速深度学习工作负载的高性能计算平台 |
| HGX | High-Performance GPU Accelerator | NVIDIA 推出的服务器参照平台。OEM 厂商用于构建 4 GPU 或 8 GPU 服务器,由 Supermicro 等第三方 OEM 制造 |
| SXM[6] | Server PCI Express Module | NVIDIA 用于连接 GPU 的高带宽 socket 接口,相比 PCIe 具有高带宽、低延迟、高拓展性、直接互联等特点 |
| HBM | High Bandwidth Memory | 一种先进的内存技术,相对于 GDDR 等具有高带宽、低功耗、封装紧凑等特点 |
| CoWoS[7] | Chip on wafer on Substrate | 三维堆叠,相对于 GDDR 等具有高带宽、低功耗、封装紧凑等特点 |
| GPC | Graphics Processor Cluster | 图形处理集群,每个 GPC 包含若干个 TPC |
| TPC | Texture Processor Cluster | 纹理处理集群,每个 TPC 包含若干个 SM |
| SM | Streaming MultiProcessor | NVIDIA GPU 架构中的核心计算单元,负责执行并行计算任务 |
| SIMT | Single Instruction Multiple Thread | 单指令多线程,NVIDIA GPU 中的一种并行计算模型,将 SIMD 和多线程结合起来,使得多个线程可以同时执行相同的指令,但是处理不同的数据 |
| GEMM | General Matrix Multiplication | 通用矩阵乘,是一种广泛用于深度学习神经网络模型的计算操作 |
| MMA | Matrix Multiply-Accumulate | 矩阵乘加 |
| FMA | Fused Multiply-Accumulate | 融合矩阵乘加,通过单个指令实现矩阵乘加 |
| TMA | Tensor Memory Accelerator | 张量内存加速器 |
| MIG | Multi-Instance GPU | 多实例 GPU |
| TEE | Trusted Execution Environments | 可信执行环境 |
| SHARP | Scalable Hierarchical Aggregation and Reduction Protocol | 可扩展分层次聚合和归约协议,NVIDIA 推出的一种高性能集合通信协议,将聚合操作卸载到交换机,消除多次传输数据的需要 |
| DSA | Domain Specific Architecture | 领域专用架构,是一种针对特定应用场景进行优化的芯片架构,旨在提高芯片的性能和效率 |
算力需求膨胀,大模型训练需要多少卡
昂贵 H100 的一时洛阳纸贵,供不应求,大模型训练究竟需要多少张卡呢? GPT-4 很有可能是在 10000 到 20000 张 A100 的基础上训练完成的[8]。按照 Elon Musk 的说法,GPT-5 的训练可能需要 3 万到 5 万张 H100,尽管之后被 Sam Altman 否认,也可窥见大模型训练对于算力的巨大需求。
Inflection 公司宣布他们正在构建世界上最大的 AI 集群,包含 22000 张 NVIDIA H100,FP16 算力可以达到 22 exaFLOPS,如果更低精度的算力(也就是 FP8)得到使用,则可以获得更高算力 [9]。这是一个非常惊人的数字,要知道 Frontier 超级计算机是目前唯一达到 ExaFLOPS 算力量级的超级计算机。对比目前排名第七的神威太湖之光超级计算机,最大算力也只有 94.64 PetaFlOPS。Inflection 自豪地宣称,如果参与超级计算机 Top 500 排行[10],他们可以很轻松地排到第二名,并且逼近排名第一的 Frontier 超级计算机。
The deployment of 22,000 NVIDIA H100 GPUs in one cluster is truly unprecedented, and will support training and deployment of a new generation of large-scale AI models. Combined, the cluster develops a staggering 22 exaFLOPS in the 16-bit precision mode, and even more if lower precision is utilized. [9]
Inflection 基于超过 3500 张 NVIDIA H100 实现了在 C4 数据集下仅用了不到 11 分钟,即训练完 GPT-3 的模型[11]。对比 OpenAI 在 2020 年时使用数千张 NVIDIA V100 训练 GPT-3,花了一个月左右的时间,对比 V100,H100 算力显著增长。这里截图不全,只大致反映当前参与 Benchmark 的厂商与系统[12]。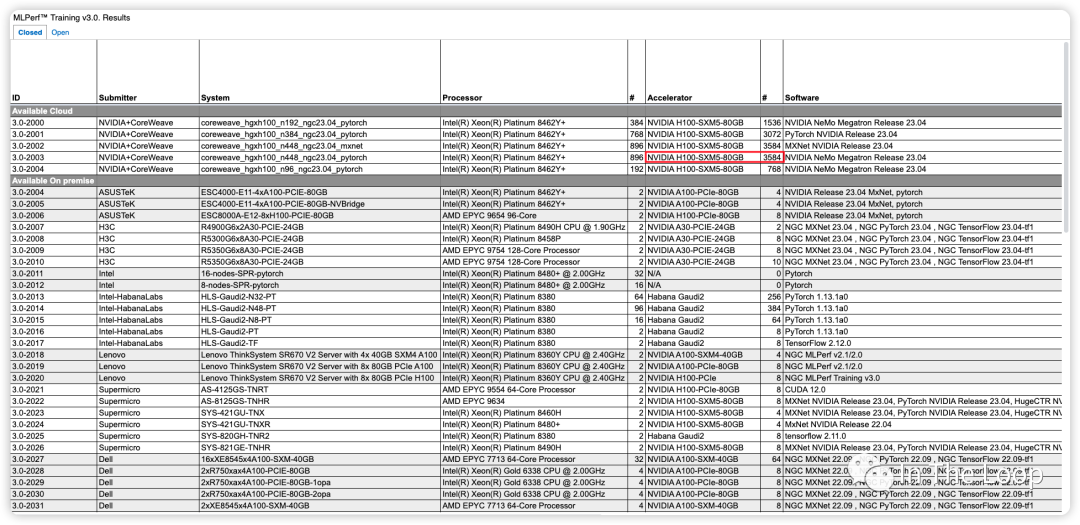
22000 张 NVIDIA H100 构成的 AI 集群,微软和英伟达投资给 Inflection 的 13 亿美元也许就要花去大半了。这一幕令人惊奇,也许存在泡沫,但真金白银不会骗人,我们也好好算算为什么需要这么多卡。OpenAI 早在 2020 年的 Scaling Laws[13] 论文中给我们提出了一个经验公式:
这里面:
是训练一个 Transformer 模型所需要的算力,单位是 FLOPs
是一个 Transformer 模型中参数的数量
是训练数据集的大小,也就是用多少 tokens 来训练
是指训练集群中所有硬件总的算力吞吐,单位是 FLOPs,计算方法为
是指训练这个模型需要的时间,单位是 seconds
Scaling Law 论文 Section 2.1 对于这个公式的做了简单的推导,在 forward pass 需要的 FLOPs 数为 ,在 backward pass 需要的 FLOPs 数大致是 forward pass 的 2 倍,因此 ,这即是系数 6 的来源。
之所以有这样简洁的公式,是因为无论是 bias vector addition,layer normalization,residual connections, non-linearities,还是 softmax,甚至是 attention 的计算都不是占算力的主要因素,最关键的还是 Transformer 中的矩阵运算。
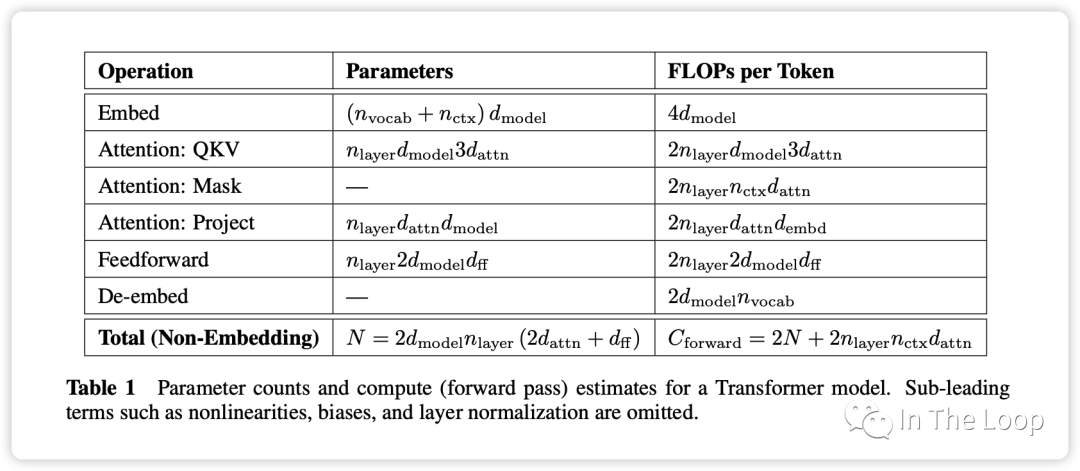
记住上面的假设之后,我们就可以简单地算出这里的系数 6 了,前向 2 次,反向 4 次,如下图所示。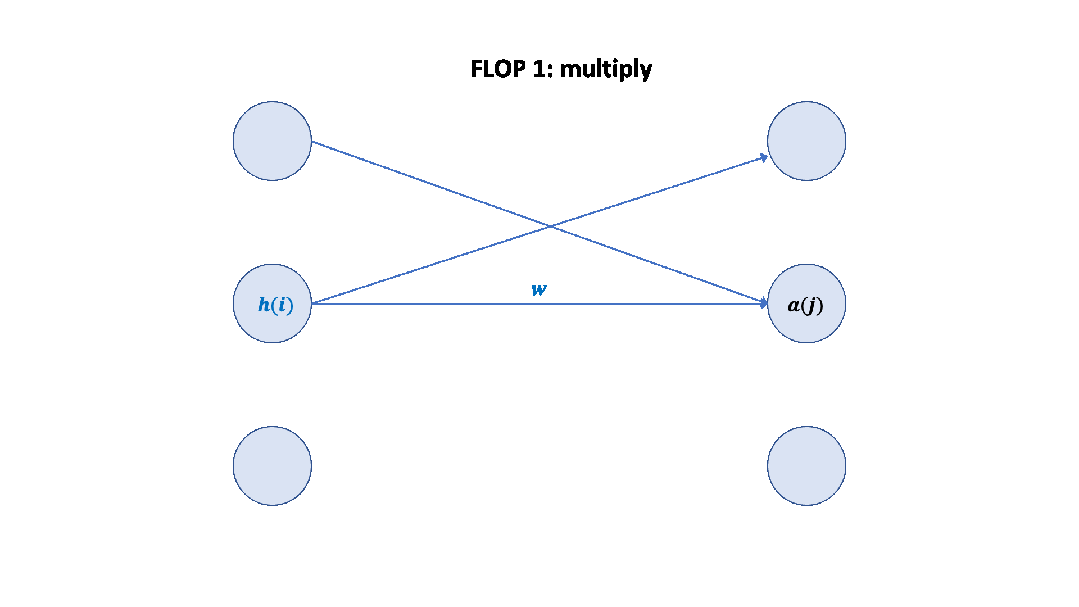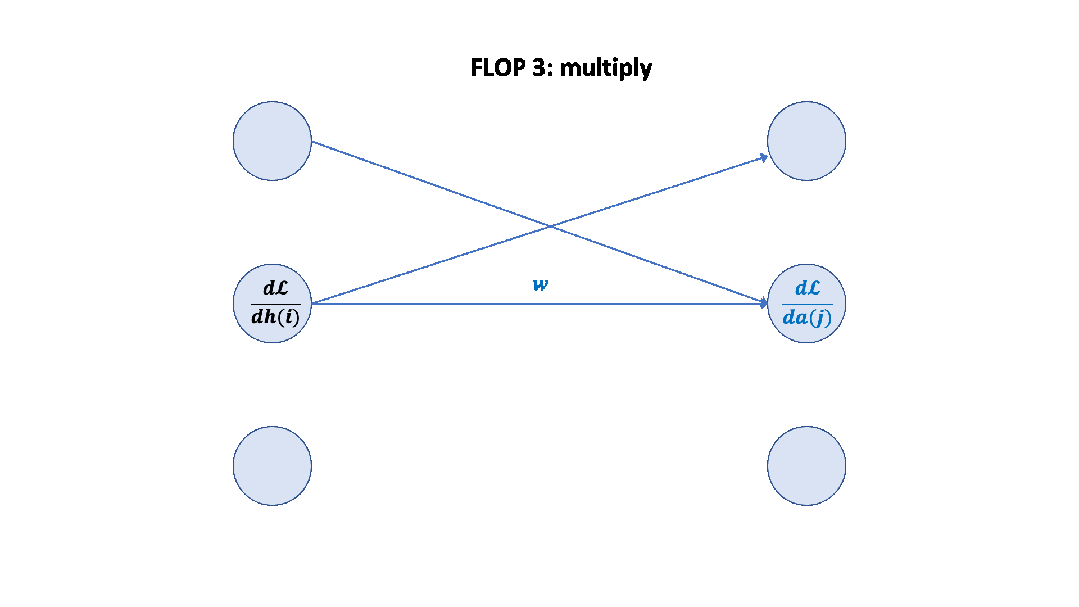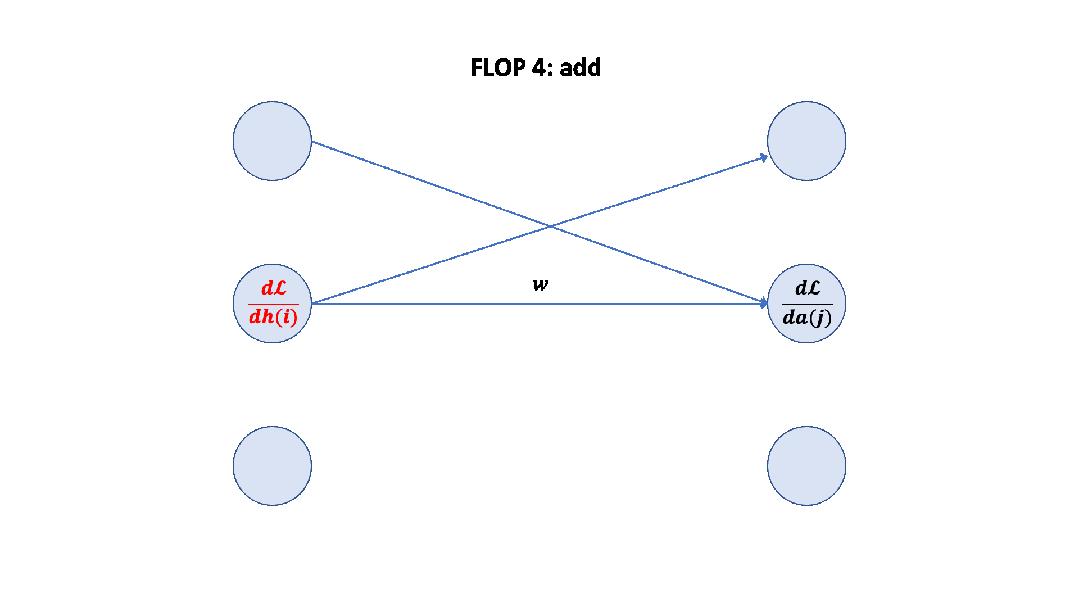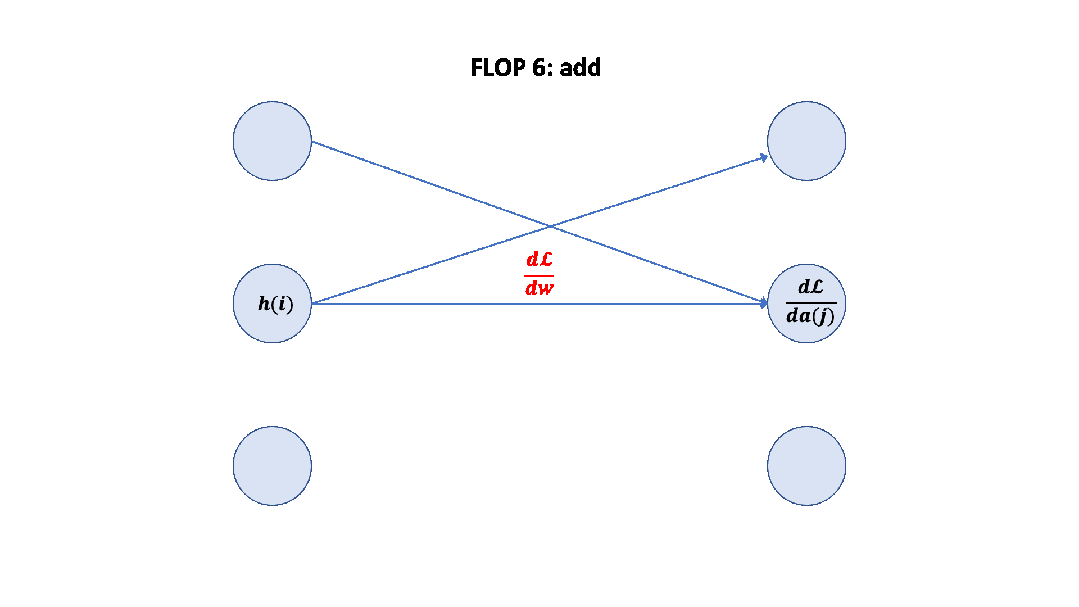 至此,基于上面的假设,我们已经推导出了经验经验公式中 6 的来源,至于为什么这个假设是正确的,可以参考 Scaling Law 的论文或者这篇文章[14]。
至此,基于上面的假设,我们已经推导出了经验经验公式中 6 的来源,至于为什么这个假设是正确的,可以参考 Scaling Law 的论文或者这篇文章[14]。
这个经验公式在 GPT-3 的论文中也再次得到了验证,可以看到对于 GPT-3 这种 decoder-only 结构的 transformer 模型,每个参数每个 token 所需要的 FLOPs 即为 6。而对于 T5 这种 encoder-decoder 结构的 transformer 模型,在 forward pass 和 backward pass,因为对每个 token 只有一半的参数是 active 的,因此这个经验公式里面的系数为 3。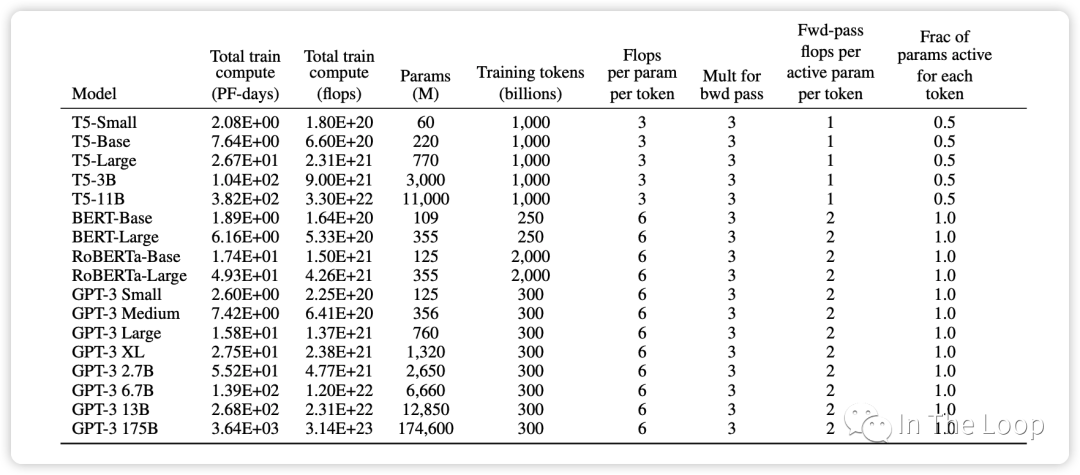
在计算所需算力的时候,我们刚才都是使用 FLOPS 这个单位,也就是 FLOP-seconds,Scaling Laws 论文中倾向于使用 PetaFLOP-days 的单位,这样能够更加直观的感受出训练一个模型需要多长时间。以 Meta 年初开源的 LLaMA-1 为例,65B 的模型基于 1.4T 的 tokens 训练,使用了 2048 块 NVIDIA A100 GPU,那么需要训练多久呢?
所需算力
NVIDIA A100 WhitePaper 中给出 BF16 Tensor Core 的算力为 312 TFLOPS[15],但是实际上算力一般在 130 到 180 TFLOPS 中间,这里我们取中间值 150 TFLOPS[16]
根据实际算力计算集群算力吞吐为
训练 LLaMA-1 所需耗时为
这一计算和 LLaMA-1 在论文中实际训练时间基本一致:
When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM. This means that training over our dataset containing 1.4T tokens takes approximately 21 days.
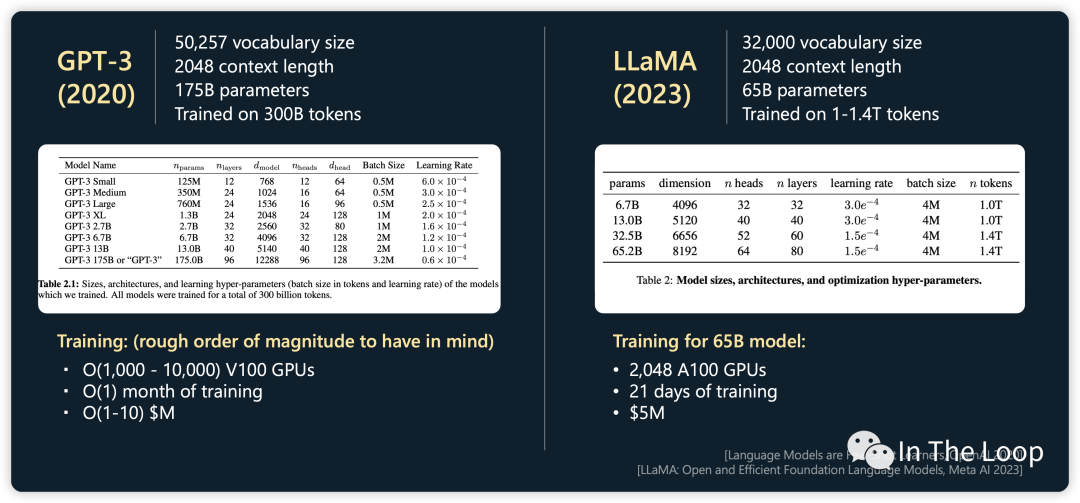
进一步计算,NVIDIA H100 WhitePaper 上给出 BF16 1979 TFLOPS,因为这个指标包含了 sparsity,实际稠密算力大约在 1000 TFLOPS[17]。对比 A100,差不多有 3 倍的增长,那么同样数目的 GPU,不考虑其他因素做最粗糙的计算,LLaMA-1 65B 的训练时长差不多可以减少到 10 天以下[18]。考虑到 H100 新推出的 FP8 Tensor Core 3,958 TFLOPS 的算力,以及新一代 NVLink Network 的通信带宽,训练速度可以进一步加快,GPT-3 175B 训练可以相比 A100 可以快 6 倍多。
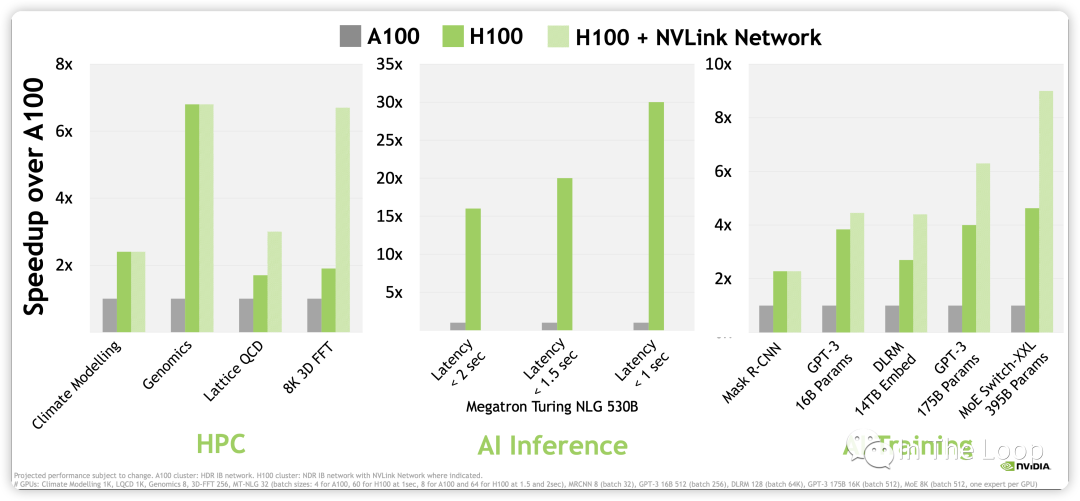
除了性能上相对于 A100 有明显优势,H100 在成本上也优于 A100。虽然 H100 在单位成本上是 A100 的 1.5 到 2 倍,但是效率上是 A100 的 3 倍,因此 H100 的每美元性能要比 A100 要更高。这就是老黄说的 「The More You Buy,The More You Save」,NVIDIA 赢麻了
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

