
- 1Python插入排序
- 2解析葵花熊胆痔灵膏/栓 大广赛赛题细节及顶尖作品分享_葵花熊胆痔灵膏市场分析
- 3Prometheus监控kafka+jvm_promethues监控kafka remotejmx
- 4HJ4 字符串分隔_print("{0:0<8s}".format(l[i:i+8]))
- 5实验七 基于广度优先搜索的六度空间 理论验证_实验七 基于广度优先搜索的六度空间 理论验证 一、实验目的 1.掌握图的邻接矩阵和
- 6Java 观察者模式(Observer Pattern)详解_观察者模式java
- 7数据库常用命令——单表查询_数据库查看表命令
- 850w字+的Android技术类校招面试题汇总,国内一线互联网公司面试题汇总
- 9广义表+ADT+C语言实现_c实现广义表并且画图
- 10微信小程序wifi接口wx.getWifiList报错解决_getwifilist:fail fail:require permission desc
关于大模型微调,你想知道的都在这里了
赞
踩
LLM大语言模型 一般训练过程
Step 1.预训练阶段
大模型首先在大量的无标签数据上进行训练,预训练的最终目的是让模型学习到语言的统计规律和一般知识。在这个过程中模型能够学习到词语的语义、句子的语法结构、以及文本的一般知识和上下文信息。需要注意的是,预训练本质上是一个无监督学习过程;得到预训练模型(Pretrained Model), 也被称为基座模型(Base Model),模型具备通用的预测能力。如GLM-130B模 型、OpenAI的A、B、C、D四大模型,都是基座模型;
Step 2.微调阶段
预训练好的模型然后在特定任务的数据上进行进一步的训练。这个过程通常涉及对模型的权重进行微小的调整,以使其更好地适应特定的任务;得到最终能力各异的模型,例如 gpt code系列、gpt text系列、 ChatGLM-6B等模型;
什么是大模型微调?
感性理解:大模型微调指的是“喂”给模型更多信息,对模型的特定功能进行 “调教”,即通过输入特定领域的数据集,让其学习这个领域的知识,从而让 大模型能够更好的完成特定领域的NLP任务,例如情感分析、命名实体识别、文本分类、对话聊天等;
为什么需要微调?
核心原因还是在于需要“赋予”大模型更加定制化的功能,例如结合本地知识库进行检索、围 绕特定领域问题进行问答等; 例如,VisualGLM是通用多模态大模型,但应用于医学影像判别领域,则需要代入医学影像 领域的数据集来进行大模型微调,从而使得模型能够更好的围绕医学影像图片进行识别; 就像机器学习模型的超参数优化,只有调整了超参数,才能让模型更佳适用于当前的数据 集; 同时,大模型是可以多次进行微调,每次微调都是一次能力的调整,即我们可以在现有的、 已经具备某些特定能力的大模型基础上进一步进行微调;
深度学习模型(大语言模型)微调算法基本背景及核心概念介绍
- 微调并不是大模型领域独有的概念,而是伴随着深度学习技术发展,自然诞生的一个技术分支,旨在能够有针对性的调整深度学习模型的参数(或者模型结构),从而能够使得其更佳高效的执行某些特定任务,而不用重复训练模型;
- 伴随着大模型技术的蓬勃发展,微调技术一跃成为大模型工程师必须要掌握的核心技术。并且,伴随着大模型技术的蓬勃发展,越来越多的微调技术也在不断涌现;
- 微调数据:不同于大模型预训练过程可以代入无标签样本,深度学习模型微调过程 需要代入有标签的样本来进行训练,微调的本质是一个有监督学习过程;
- 微调的本质:相比海量数据在超大规模模型上进行预训练,微调只需要一部分有标 签数据、并对模型的部分参数进行修改即可使得模型获得某种特殊能力;因此,从所需数据量和算力消耗来看,相比于训练微调的⻔槛和成本都要低很多;
- 例如:对于一个经过预训练的大模型,如果我们代入诸多标有“垃圾邮件”和“非垃圾 邮件”的标签文本进行训练,则可训练其具备垃圾邮件分类这一能力;
- 从模型本身⻆度而言:微调阶段相当于是进一步进行训练,该过程会修改模 型参数,并最终使模型“记住”了这些额外信息;让大模型永久记住信息的唯 一方法就是修改参数;
- 有监督微调:supervised fine-tuning,简称SFT;
- 数据标注:高质量的有标签数据集在微调过程中必不可少, 数据标注工作则 是用于创建这些有标签的数据集;伴随着大模型发展,人们也在尝试使用大 模型来完成很多数据标注工作;
微调与高效微调
- 微调,Fine-Tuning,一般指全参数的微调(全量微调),指是一类较早诞生的微调方法,全参数微调需要消耗大量的算力,实际使用起来并不方便,因此不久之后又诞生了只围绕部分参数进行微调的高效微调方法;
- 高效微调,State-of-the-art Parameter-Efficient Fine- Tuning (SOTA PEFT),特指部分参数的微调方法,这种方法算力功耗比更高,也是目前最为常见的微调方法;
- 除此之外,Fine-Tuning可以代指全部微调方法,同时OpenAl中模型微调AP1的名称也是Fine-Tuning, 需要注意的是,OpenAl提供的在线微调方法也是一种高效微调方法,并不是全量微调;
微调的方法有哪些?
- 第一类方法:借助OpenAI提供的在线微调工具进行微调;
- 第二类方法:借助开源微调框架进行微调;
借助OpenAI提供的在线微调工具进行微调
OpenAI系列模型微调关系
官网说明地址: https://platform.openai.com/docs/ model-index-for-researchers
OpenAI大模型微调API API地址
https://platform.openai.com/docs/guides/fine-tuning
- OpenAI提供了GPT在线大模型的微调API: Fine-tuning,用于在线微调在线大模型;
- 目前支持A、B、C、D四大模型在线微调; 根据格式要求在线提交数据集并支付算力费
- 用,即可在线进行模型微调;
- 微调后会生成单独模型的API供使用; 一个模型可以多次微调;
- OpenAI在线微调是黑箱算法;
OpenAI提供的了“傻瓜式”微调流程,用户只需要:
- 按照格式要求,准备并上传数据集;
- 排队、支付费用并等待微调模 型训练完成;
- 赋予微调模型API单独编号,调用API即可使用;
借助开源微调框架进行微调(以下均属于借助开源微调框架进行微调)
基于强化学习的进阶微调方法RLHF
RLHF方法 论文地址:https://arxiv.org/abs/2203.02155九天Hector
- RLHF:Reinforcement Learning from Human Feedback,即基于人工反馈机制的强化学习。最早与2022年4月,由OpenAI研究团队系统总结并提出, 并在GPT模型的对话类任务微调中大放异彩,被称为 ChatGPT“背后的功臣”; RLHF也是目前为止常用的、最为复杂的基于强化学 习的大语言模型微调方法,目前最好的端到端RLHF 实现是DeepSpeedChat库,由微软开源并维护;
- Hugging Face PEFT项目地址 https://github.com/huggingface/peft
- 深度学习微调方法非常多,主流方法包括LoRA、 Prefix Tuning、P- Tuning、Promt Tuning、 AdaLoRA等; 目前这些方法的实现均已集成至Hugging Face项目的库中,我们可以通过安装和调用Hugging Face的PEFT(高效微调)库,来快速使用这些方法;
- Hugging Face 是一家专注于自然语言处理 (NLP)技术的公司,同时也开发并维护了多个广受欢迎的自然语言处理的开源库和工具,如 Transformers 库、ChatGLM-6B库等; 高效微调,State-of-the-art Parameter-Efficient Fine-Tuning (SOTA PEFT),与之对应的更早期的简 单的全量参数训练微调的方法(Fine- Tuning), 高效微调则是一类算力功耗比更高的方法;
- 最早由OpenAI研究团队提出,并用于训练OpenAI的InstructGPT模型;
- 效果惊艳:根据OpenAI相关论文说明,基于RLHF训练的InstructGPT模型, 在仅拥有1.3B参数量的情况下,输出效果已经开源和GPT-3 175B模型媲美。 这充分说明了RLHF方法的实践效果;
- 目前Hugging Face、PyTorch和微软研究院都有提供RLHF实现方法,其中微 软研究院的DeepSpeed Chat是目前最高效稳定的端到端RFHL训练系统;
RLHF训练流程
项目地址: https://github.com/microsoft/ DeepSpeed/
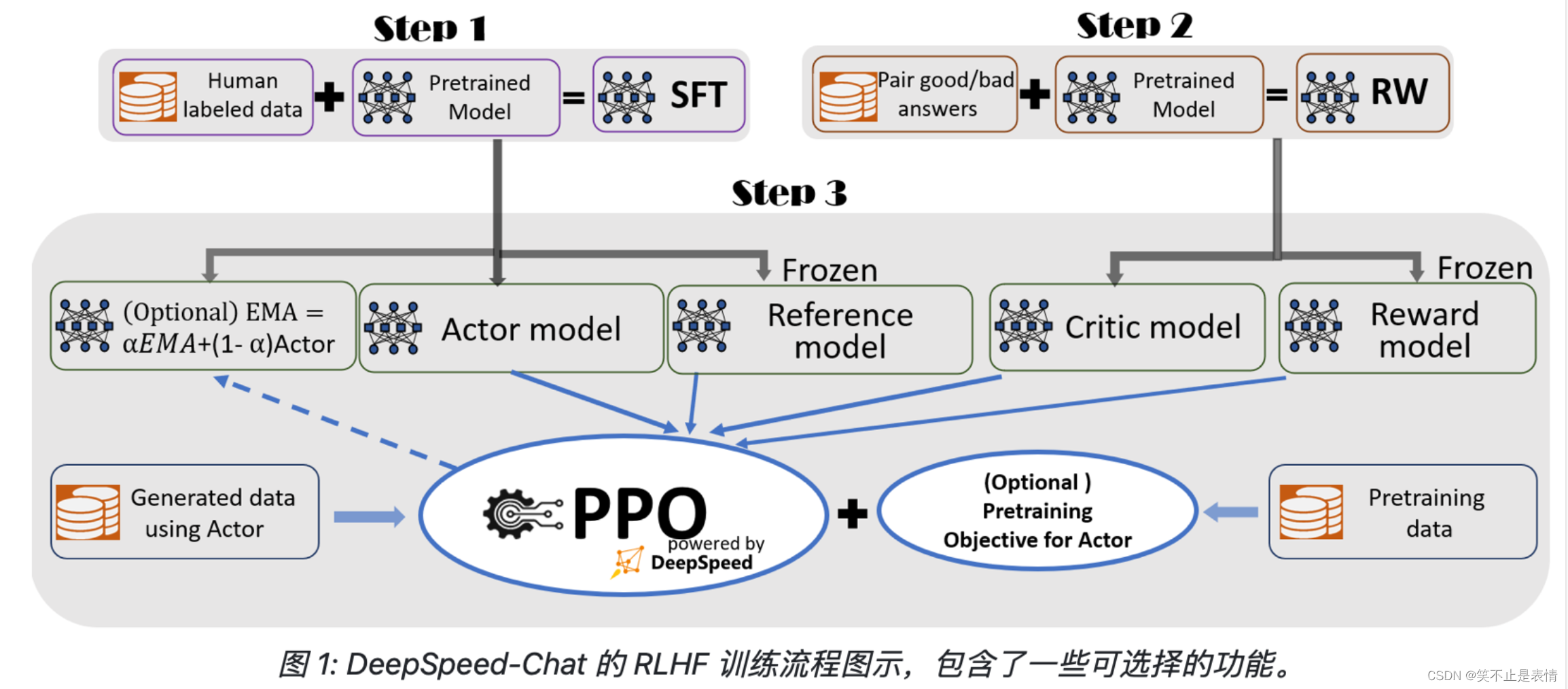
步骤1:监督微调(SFT) —— 使用精选的人类回答来微调预训练的语言模型以应对各种查询;
步骤2:奖励模型微调 —— 使用一个包含人类对同一查询的多个答案打分的数据集来训练一个独 立的(通常比 SFT 小的)奖励模型(RW);
步骤3:RLHF 训练 —— 利用 Proximal Policy Optimization(PPO)算法,根据 RW 模型的奖励 反馈进一步微调 SFT 模型。
RLHF是实现难度最大的微调方法,不太支持windows系统,最好使用linux系统。
高效微调方法一:LoRA
Github地址: https://github.com/microsoft/LoRA
论文地址: https://arxiv.org/abs/2106.09685
LoRA:LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS(2021) 基于低阶自适应的大语言模型微调方法
- 原理简述:基于大模型的内在低秩特性,增加旁路矩阵来模拟全参数微调; LoRA最早由微软研究院发布的一项微调技术; 简而言之,是通过修改模型结构进行微调,是一种四两拨千斤的微调方法, 是目前最通用、同时也是效果最好的微调方法之一;
- 概念辨析:大模型微调LoRA与通信技术LoRa,二者相差一个字母的大小 写,是完全两种不同的技术;
- LoRA除了可以用于微调大语言模型(LLM)外,目前还有一个非常火爆的 应用场景:围绕diffusion models(扩散模型)进行微调,并在图片生成任务中表现惊艳;
高效微调方法二:Prefix-Tuning
论文地址: https://aclanthology.org/2021.acl-long.353/
Prefix-Tuning: Optimizing Continuous Prompts for Generation(2021) 基于提示词前缀优化的微调方法
- 来源于斯坦福大学的一种高效微调方法; 原理简述:在原始模型基础上,增加一个可被训练的Embedding 层,用于给提示词增加前缀进行信息过滤,从而让模型更好的理解提示词意图, 并在训练过程中不断优化这些参数;
- Prefix Tuning既能够在模型结构上增加一些新的灵活性,又能够在 模型使用上提供一种自动的、能够改进模型表现的提示机制;
高效微调方法三:Prompt Tuning
论文地址: https://arxiv.org/abs/2104.08691
The Power of Scale for Parameter-Efficient Prompt Tuning (2021)
- 由谷歌提出的一种轻量级的优化方法;
- 原理简述:该方法相当于是Prefix Tuning的简化版本,即无需调整模型参数,而是在已有的参数中,选择一部分参数作为可学习参数,用于创建每个Prompt的前缀,从而帮助模型更好地理解和处理特定的任务;
- 不同于Prefix方法,Prompt Tuning训练得到的前缀是具备可解释性的, 我们可以通过查看这些前缀,来查看模型是如何帮我们优化prompt的;
- 该方法在参数规模非常大的模型微调时效果很好,当参数规模达到 100亿时和全量微调效果一致;
高效微调方法四:P-Tuning v2
GitHub地址:https://github.com/THUDM/P-tuning-v2 论文地址: https://aclanthology.org/2021.acl-long.353/
ChatGLM-6B+P-Tuning微调项目地址: https://github.com/ THUDM/ChatGLM-6B/blob/main/ptuning/README.md
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks(2022)
- 来源于清华大学团队提出的高效微调方法;
- 原理简述:可以理解为Prefix tuning的改进版本,即P-Tuning v2不仅在输 入层添加了连续的prompts(可被训练的Embedding层),而且还在预训 练模型的每一层都添加了连续的prompts;
- 这种深度的prompt tuning增加了连续prompts的容量,出于某些原因,P- Tuning v2会非常适合GLM这种双向预训练大模型微调;
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/696865
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

