
准备数据是数据分析的第一步,由数据构成集合,我们称作数据集,数据集的结构是行列式的,行表示观测,列表示变量。把数据读入到R中,转换为合适的数据结构,能够提高数据分析的效率。在数据分析中,常用的存储数据的结构有标量、向量、因子和数据框,另外,还有矩阵和列表,多样化的数据结构赋予了R灵活处理数据的能力,本文简单介绍常用的数据结构(标量、向量、因子和数据框)及其使用方法。
一,常用的数据结构
标量通常是常量,每一个标量都有特定的数据类型,常用的数据类型是数值类型,字符类型,逻辑类型和日期类型。
对于逻辑类型,可能的值是TRUE和FALSE,用于逻辑操作的运算符:与(&)、或(|)、非(!)
R语言中经常会遇到一些特殊值:
- 缺失值 NA(Not Avaiable),是不可用的缩写;
- NaN为“不是一个数”,意味着计算没有数学意义;
- NULL值,空值,表示一个空的变量,不会占用任何空间,通过is.null(x)来测试变量是否为NULL值;
- 特殊的数字:Inf、-Inf 表示正无穷,负无穷;
1,向量
向量是用于存储同一类型的一维数组,同一向量中无法存储不同类型的数据,标量是只含一个元素的向量。向量使用c()函数来定义,向量元素的数据类型必须相同。
myvector <- c("a","b","c")
2,因子
因子是一个枚举类型,用于表示类别。因子有字面标签(Lable)和级别(Level)两个属性。函数factor()以一个整数向量的形式存储类别。
参数:levels代表原始类别名称,lables相当于对类别名称进行重命名。
- factor(x = character(), levels, labels = levels,
- exclude = NA, ordered = is.ordered(x), nmax = NA)
例如,定义一个向量,把向量转化为因子,对因子的级别进行重命名。
- > sex<-c("男","女","男")
- > f<-factor(sex,levels=c("男","女"),labels=c("male","female"))
- > f
- [1] male female male
- Levels: male female
通过函数levels(f)和nlevels(f)查看因子的级别和级数:
- > levels(f)
- [1] "male" "female"
- > nlevels(f)
- [1] 2
3,数据框
数据框是数据分析中,最常用的存储结构,其最大的特征是:不同的列可以包含不同的数据类型,同一列的数据类型必须相同。
数据框可以通过函数data.frame()创建:
- data.frame(..., row.names = NULL, check.rows = FALSE,
- check.names = TRUE, fix.empty.names = TRUE,
- stringsAsFactors = default.stringsAsFactors())
创建数据框的参数注释:
- ...:用于指定数据框的数据,通常是多个向量,每个变量元素的类型必须相同,所有变量的长度必须相同,可以指定变量的名称,例如,var1=c(1:5),var2=c("a","b","c","d","e")。
- row.names:字符串向量,用于指定行的名称
- check.rows:逻辑值,检查行名称是否和行的数量匹配
- check.names:逻辑值,检查变量的名称,确保变量名称合法
- fix.empty.names:逻辑值,当设置为TRUE时,自动为没有名称的变量重命名,默认值是TRUE;当设置为FALSE时,为无名变量保留名称“”;
- stringsAsFactors:逻辑值,是否把字符串类型的变量转换为因子类型
二,创建数据框
创建数据框的方法有多种,常用的方法有三种,根据实际的业务场景,选择合适的方法。
1,使用data.frame()函数
这种方法最简单,但创建的数据框包含的数据相对较少。
- > age<-c(13,15,17,20)
- > name<-c("s1","s2","s3","s4")
- > stu<-data.frame(age,name)
- > stu
- age name
- 1 13 s1
- 2 15 s2
- 3 17 s3
- 4 20 s4
2,从文件中导入数据
使用read.table()函数,从带分隔符的文本文件中导入数据,该函数的格式是:
mydata <- read.table(file, options)
常用的选项是:
- header:逻辑值,表示文件的第一行是否包含变量的标题;
- sep:表示在同一行内,用于分割变量值的分隔符,默认值是",";
- row.names:字符串类型的向量,用于指定行的名称。可以是一个向量,包含所有数据行的名称,也可以指定一个字符串,该字符串是文件的列名,那么数据集使用该列的值作为行的名称。
- col.names:字符串类型的向量,如果文件的第一行不包含变量的标题,使用该参数指定变量的名称;如果参数header=FALSE,col.names参数被省略了,变量会被命名为V1、V2,以此类推。
- na.strings:用于表示缺失值的字符串向量,在读取数据时,当变量值匹配这些字符串中的任意一个时,把变量的值转换为NA。
- colClass:用于指定每一个变量的数据类型,例如,colClasses=c("numeric","character","NULL"),当类为NULL时,表示跳过该列。
- quote:用于对有特殊字符的字符串划定界限的符号,默认值是双引号或单引号。
- skip:读取数据前跳过的行数,常用于跳过文件开头的注释行。
- stringAsFactors:逻辑值,默认值是TRUE,用于指定是否把字符向量转换为因子。
在处理大型文本数据时,设置colClasses参数,把stringAsFactors设置为FALSE,能够显著提高数据处理的速度。
举个例子,从csv文件中读取数据,文件的第一行是列名:
mydata <- read.table("stu.csv",header=TRUE,sep=",",row.names="StudentID")
三,使用R连接数据库
通过ODBC驱动程序连接数据库,用户需要安装ODBC驱动程序,然后创建ODBC数据源。在R脚本中引用数据源,从数据库中读取数据,对数据进行分析。
1,创建ODBC数据源
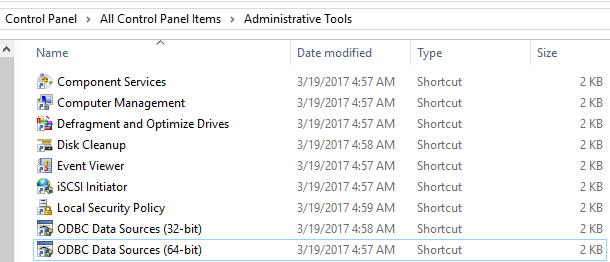
step1:从管理员工具中选择ODBC Data Source (64-bit),添加用户数据源:
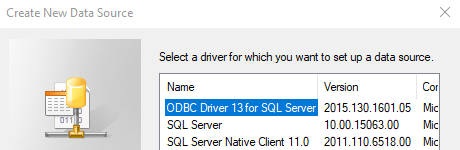
step2:选择驱动程序,ODBC Driver 13 for SQL Server
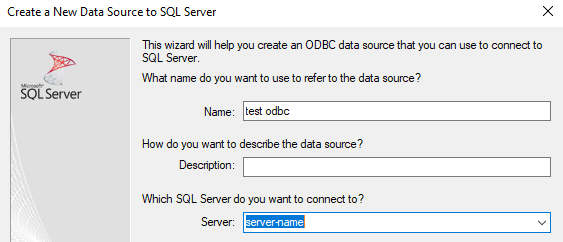
step3:输入ODBC数据源的名称,想要连接的SQL Server的名称:
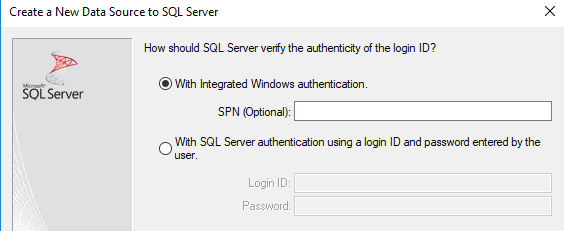
step4:选择验证模式
在Windows域账户中,选择集成Windows验证模式
step5:选择默认连接的数据库
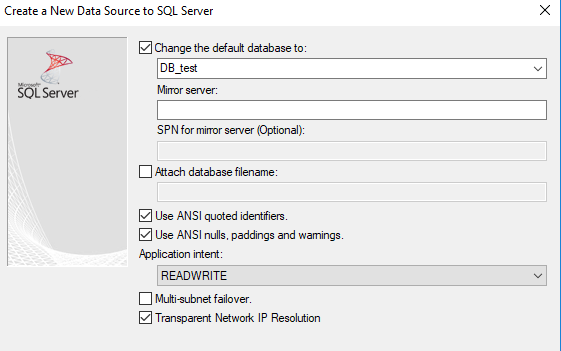
step6:使用默认的配置
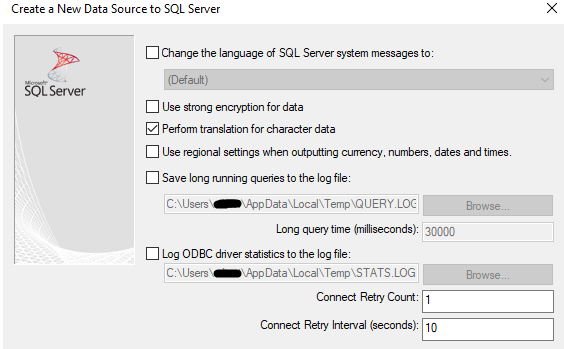
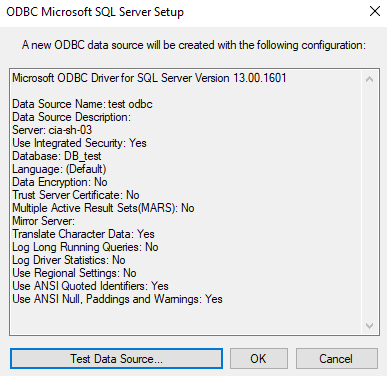
step7:测试数据源,点击OK,创建数据源
step8,查看创建的用户数据源(DSN)
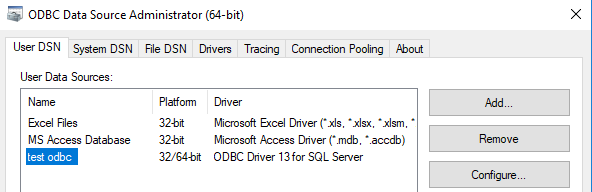
2,引用ODBC数据源
首先需要安装RODBC包,并在R脚本中引用包:
- install.packages("RODBC")
- library(RODBC)
该包中主要包含三个常用的函数,分别用于连接ODBC数据源,从数据库中执行查询返回数据框,关闭数据源。
- channel <- odbcConnect(dsn,uid="",pwd="")
- sqlQuery(channel,query)
- close(channel)
举个例子,从ODBC数据源中,执行SQL语句,返回数据框,并及时关系连接。
- > library(RODBC)
- > myconn <- odbcConnect("test odbc")
- > mydata <- sqlQuery(myconn,"SELECT [ID] ,[Name] ,[CreateTime] FROM [DB_test].[dbo].[Users]")
- > close(myconn)
- > mydata
- ID Name CreateTime
- 1 1 Vic 2017-11-09 15:58:07
- 2 2 Joe 2017-11-09 15:58:07
- >
四,检查对象的属性
创建数据框之后,需要检查数据框的各个属性,这是对准备的数据做一个初步检查。
1,查看对象的结构
- > str(mydata)
- 'data.frame': 2 obs. of 3 variables:
- $ ID : int 1 2
- $ Name : Factor w/ 2 levels "Joe","Vic": 2 1
- $ CreateTime: POSIXct, format: "2017-11-09 15:58:07" "2017-11-09 15:58:07"
2,查看对象的行数量和变量数量
- > NROW(mydata)
- [1] 2
- > NCOL(mydata)
- [1] 3
- > dim(mydata)
- [1] 2 3
3,查看数据框的变量名
- > names(mydata)
- [1] "ID" "Name" "CreateTime"
4,查看数据框的头部或尾部数据行
- head(mydata)
- tail(mydata)
参考文档:

