
- 1还在用手画太阳花,太out了,python教你如何轻松画一朵!_idle如何画一朵花
- 2“Git:不容错过的现代化版本控制系统” 基础入门篇_初探git,理解和使用版本控制的魔法
- 3c++ STL less 的视角
- 4Java正则表达式汇总_java正则表达式,不能输入引号(单引号和双引号)以及特殊字符<、>、#和&
- 5C语言的printf的介绍_printf("%g%+gi\n", a.rp, a.ip);
- 6【蓝桥杯选拔赛真题50】python充电器 青少年组蓝桥杯python 选拔赛STEMA比赛真题解析_蓝桥杯青少组stema
- 7框架技术 ---- SPA和Vue的组件化开发_vue和spa
- 8git命令(使用git review)
- 9【Django】Django实现对IP地址访问过滤_django 限制 国内 ip 访问
- 10图像处理: 马赛克艺术_马赛克是什么纹理
Segment Anything 试用体验_seg anything体验网站
赞
踩
近日,Meta 发布首个可 " 任意图像分割 " 的基础模型 Segment-Anything Model(SAM)和最大规模的 " 任意分割 10 亿掩码数据集「Segment Anything 1-Billion mask dataset ( SA-1B ) 」,将自然语言领域的 prompt 范式引入了 CV 领域,进而为 CV 基础模型提供更广泛的支持与深度研究。
链接如下:
SAM Demo:https://segment-anything.com/
开源地址:https://github.com/facebookresearch/segment-anything
论文地址:https://arxiv.org/abs/2304.02643
数据集:https://segment-anything.com/dataset/index.html
我们来试试分割效果如何。首先进入网站(https://segment-anything.com/),点击右上角的demo链接,进入Demo页:

此处,可选择网站提供的照片或者上传照片。
此处上传一张566*387 的照片,上传过程可能有点长,要耐心点。

我们可以看到,左侧有三种操作模式,分别是 “Hover & Click”、“Box”和“Everything”。下面分别点击三个选项框,演示三种模式下的效果。
1 Hover and click(悬浮点击模式)
选中 “Hover & Click”框后,把鼠标放到一只猫上,网页上的图片分割系统就开始工作了。

依次点击三只猫。如下:
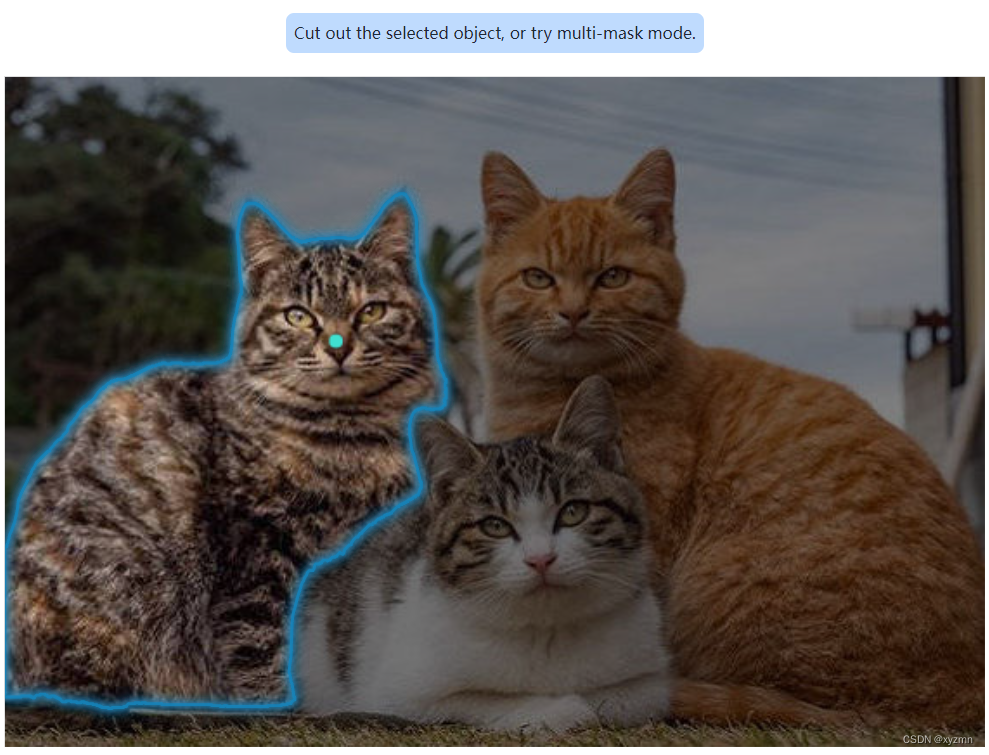

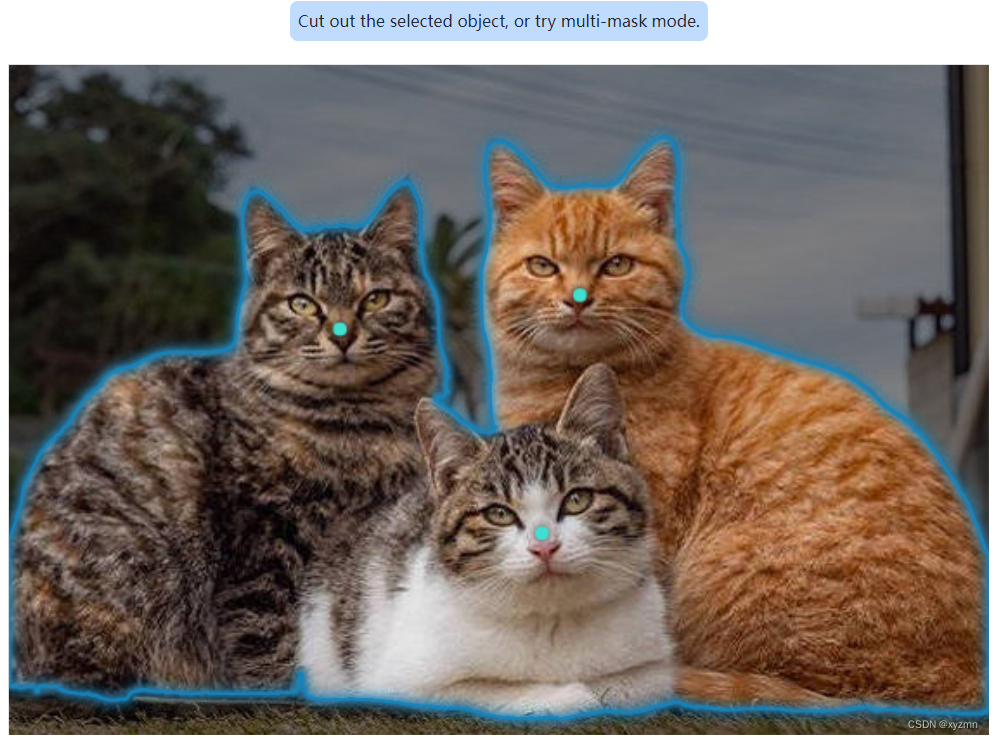
显然效果可以,三只猫所占的相应区域被很好的识别了。
2 Box( 框选模式 )
我们先画个小框,看看效果。

效果不太理想。
再放大框选区域。

感觉也不大好,比之前的第一种模式差点。
3 everything(全图模式)
选中“Everything”框后,图片就开始被处理了。
很快,图片分割结果就出来了,如下:

效果还不错! 就是下面那只猫的两只眼睛差不多,怎么其中一只眼睛被单独提取了?
还有,Demo中没提示分割的结果是什么,希望后面的升级版会给出来!
参考文章:

