
- 1xHci-PCI驱动设计_xhci驱动
- 2鸿蒙harmonyOS 使用轻量级数据存储Preferences出现的一个问题_preferences鸿蒙
- 3ContentProvider(内容提供者)和ContentResolve(内容访问者)_内容提供者是哪个函数实习的
- 4Android Button#background 在MaterialComponents主题下无效问题
- 5一些比较小众的小程序类型,如AI算命,影视视频等_好看小众的微信小程序
- 6你知道几个中文编程语言,快来瞧瞧这些有趣的中文编程语言。
- 7Wget用法、参数解释的比较好的一个文章 _wget成功
- 8mpi4py 中的组管理 API_python mpi4py api
- 9Android笔记四_android create new keystore的country code
- 10(十九)数据结构-图的应用-有向无环图表达形式、拓扑排序、关键路径_有向无环图的一个有效的拓扑排序
C++ AMP在GPU上做并行计算_amp并行内核调用函数
赞
踩
遇见C++ AMP:在GPU上做并行计算
Written by Allen Lee
I see all the young believers, your target audience. I see all the old deceivers; we all just sing their song.
– Marilyn Manson, Target Audience (Narcissus Narcosis)
从CPU到GPU
在《遇见C++ PPL:C++的并行和异步》里,我们介绍了如何使用C++ PPL在CPU上做并行计算,这次,我们会把舞台换成GPU,介绍如何使用C++ AMP在上面做并行计算。
为什么选择在GPU上做并行计算呢?现在的多核CPU一般都是双核或四核的,如果把超线程技术考虑进来,可以把它们看作四个或八个逻辑核,但现在的GPU动则就上百个核,比如中端的NVIDIA GTX 560 SE就有288个核,顶级的NVIDIA GTX 690更有多达3072个核,这些超多核(many-core)GPU非常适合大规模并行计算。
接下来,我们将会在《遇见C++ PPL:C++的并行和异步》的基础上,对并行计算正弦值的代码进行一番改造,使之可以在GPU上运行。如果你没读过那篇文章,我建议你先去读一读它的第一节。此外,本文也假设你对C++ Lambda有所了解,否则,我建议你先去读一读《遇见C++ Lambda》。
并行计算正弦值
首先,包含/引用相关的头文件/命名空间,如代码1所示。amp.h是C++ AMP的头文件,包含了相关的函数和类,它们位于concurrency命名空间之内。amp_math.h包含了常用的数学函数,如sin函数,concurrency::fast_math命名空间里的函数只支持单精度浮点数,而concurrency::precise_math命名空间里的函数则对单精度浮点数和双精度浮点数均提供支持。
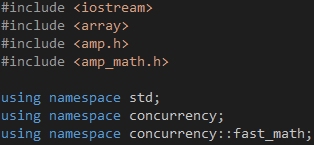
代码 1
把浮点数的类型从double改成float,如代码2所示,这样做是因为并非所有GPU都支持双精度浮点数的运算。另外,std和concurrency两个命名空间都有一个array类,为了消除歧义,我们需要在array前面加上"std::"前缀,以便告知编译器我们使用的是STL的array类。
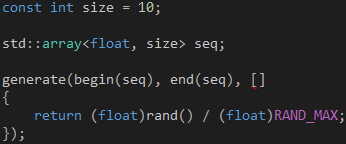
代码 2
接着,创建一个array_view对象,把前面创建的array对象包装起来,如代码3所示。array_view对象只是一个包装器,本身不能包含任何数据,必须和真正的容器搭配使用,如C风格的数组、STL的array对象或vector对象。当我们创建array_view对象时,需要通过类型参数指定array_view对象里的元素的类型以及它的维度,并通过构造函数的参数指定对应维度的长度以及包含实际数据的容器。

代码 3
代码3创建了一个一维的array_view对象,这个维度的长度和前面的array对象的长度一样,这个包装看起来有点多余,为什么要这样做?这是因为在GPU上运行的代码无法直接访问系统内存里的数据,需要array_view对象出来充当一个桥梁的角色,使得在GPU上运行的代码可以通过它间接访问系统内存里的数据。事实上,在GPU上运行的代码访问的并非系统内存里的数据,而是复制到显存的副本,而负责把这些数据从系统内存复制到显存的正是array_view对象,这个过程是自动的,无需我们干预。
有了前面这些准备,我们就可以着手编写在GPU上运行的代码了,如代码4所示。parallel_for_each函数可以看作C++ AMP的入口点,我们通过extent对象告诉它创建多少个GPU线程,通过Lambda告诉它这些GPU线程运行什么代码,我们通常把这个代码称作Kernel。

代码 4
我们希望每个GPU线程可以完成和结果集里的某个元素对应的一组操作,比如说,我们需要计算10个浮点数的正弦值,那么,我们希望创建10个GPU线程,每个线程依次完成读取浮点数、计算正弦值和保存正弦值三个操作。但是,每个GPU线程运行的代码都是一样的,如何区分不同的GPU线程,并定位需要处理的数据呢?
这个时候就轮到index对象出场了,我们的array_view对象是一维的,因此index对象的类型是index<1>,这个维度的长度是10,因此将会产生从0到9的10个index对象,每个GPU线程对应其中一个index对象。这个index对象将会通过Lambda的参数传给我们,而我们将会在Kernel里通过这个index对象找到当前GPU线程需要处理的数据。
既然Lambda的参数只传递index对象,那Kernel又是如何与外界交换数据的呢?我们可以通过闭包捕获当前上下文的变量,这使我们可以灵活地操作多个数据源和结果集,因此没有必要提供返回值。从这个角度来看,C++ AMP的parallel_for_each函数在用法上类似于C++ PPL的parallel_for函数,如代码5所示,我们传给前者的extent对象代替了我们传给后者的起止索引值。
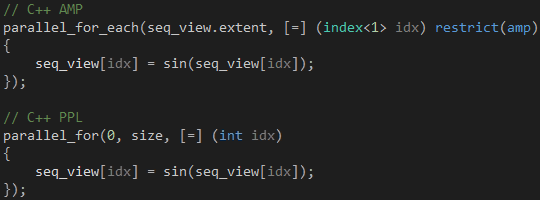
代码 5
那么,Kernel右边的restrict(amp)修饰符又是怎么一回事呢?Kernel最终是在GPU上运行的,不管以什么样的形式,restrict(amp)修饰符正是用来告诉编译器这点的。当编译器看到restrict(amp)修饰符时,它会检查Kernel是否使用了不支持的语言特性,如果有,编译过程中止,并列出错误,否则,Kernel会被编译成HLSL,并交给DirectCompute运行。Kernel可以调用其他函数,但这些函数必须添加restrict(amp)修饰符,比如代码4的sin函数。
计算完毕之后,我们可以通过一个for循环输出array_view对象的数据,如代码6所示。当我们在CPU上首次通过索引器访问array_view对象时,它会把数据从显存复制回系统内存,这个过程是自动的,无需我们干预。
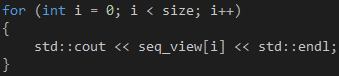
代码 6
哇,不知不觉已经讲了这么多,其实,使用C++ AMP一般只涉及到以下三步:
- 创建array_view对象。
- 调用parallel_for_each函数。
- 通过array_view对象访问计算结果。
其他的事情,如显存的分配和释放、GPU线程的规划和管理,C++ AMP会帮我们处理的。
并行计算矩阵之和
上一节我们通过一个简单的示例了解C++ AMP的使用步骤,接下来我们将会通过另一个示例深入了解array_view、extent和index在二维场景里的用法。
假设我们现在要计算两个100 x 100的矩阵之和,首先定义矩阵的行和列,然后通过create_matrix函数创建两个vector对象,接着创建一个vector对象用于存放矩阵之和,如代码7所示。
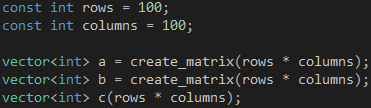
代码 7
create_matrix函数的实现很简单,它接受矩阵的总容量(行和列之积)作为参数,然后创建并返回一个包含100以内的随机数的vector对象,如代码8所示。
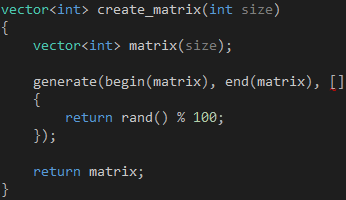
代码 8
值得提醒的是,当create_matrix函数执行"return matrix;"时,会把vector对象拷贝到一个临时对象,并把这个临时对象返回给调用方,而原来的vector对象则会因为超出作用域而自动销毁,但我们可以通过编译器的Named Return Value Optimization对此进行优化,因此不必担心按值返回会带来性能问题。
虽然我们通过行和列等二维概念定义矩阵,但它的实现是通过vector对象模拟的,因此在使用的时候我们需要做一下索引变换,矩阵的第m行第n列元素对应的vector对象的索引是m * columns + n(m、n均从0开始计算)。假设我们要用vector对象模拟一个3 x 3的矩阵,如图1所示,那么,要访问矩阵的第2行第0列元素,应该使用索引6(2 * 3 + 0)访问vector对象。
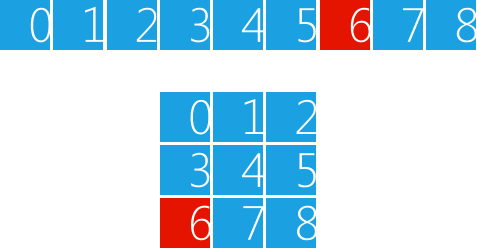
图 1
接下来,我们需要创建三个array_view对象,分别包装前面创建的三个vector对象,创建的时候先指定行的大小,再指定列的大小,如代码9所示。

代码 9
因为我们创建的是二维的array_view对象,所以我们可以直接使用二维索引访问矩阵的元素,而不必像前面那样计算对应的索引。还是以3 x 3的矩阵为例,如图2所示,vector对象会被分成三段,每段包含三个元素,第一段对应array_view对象的第一行,第二段对应第二行,如此类推。如果我们想访问矩阵的第2行第0列的元素,可以直接使用索引 (2, 0) 访问array_view对象,这个索引对应vector对象的索引6。
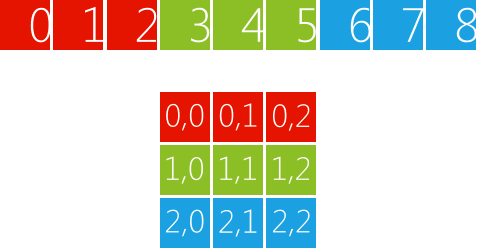
图 2
考虑到第一、二个array_view对象的数据流动方向是从系统内存到显存,我们可以把它们的第一个类型参数改为const int,如代码10所示,表示它们在Kernel里是只读的,不会对它包装的vector对象产生任何影响。至于第三个array_view对象,由于它只是用来输出计算结果,我们可以在调用parallel_for_each函数之前调用array_view对象的discard_data成员函数,表明我们对它包装的vector对象的数据不感兴趣,不必把它们从系统内存复制到显存。
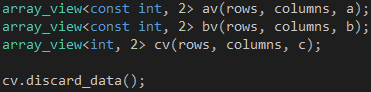
代码 10
有了这些准备,我们就可以着手编写Kernel了,如代码11所示。我们把第三个array_view对象的extent传给parallel_for_each函数,由于这个矩阵是100 x 100的,parallel_for_each函数会创建10,000个GPU线程,每个GPU线程计算这个矩阵的一个元素。由于我们访问的array_view对象是二维的,索引的类型也要改为相应的index<2>。

代码 11
看到这里,你可能会问,GPU真能创建这么多个线程吗?这取决于具体的GPU,比如说,NVIDIA GTX 690有16个多处理器(Kepler架构,每个多处理器有192个CUDA核),每个多处理器的最大线程数是2048,因此可以同时容纳最多32,768个线程;而NVIDIA GTX 560 SE拥有9个多处理器(Fermi架构,每个多处理器有32个CUDA核),每个多处理器的最大线程数是1536,因此可以同时容纳最多13,824个线程。
计算完毕之后,我们可以在CPU上通过索引器访问计算结果,代码12向控制台输出结果矩阵的第14行12列元素。
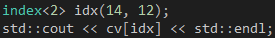
代码 12
async + continuation
掌握了C++ AMP的基本用法之后,我们很自然就想知道parallel_for_each函数会否阻塞当前CPU线程。parallel_for_each函数本身是同步的,它负责发起Kernel的运行,但不会等到Kernel的运行结束才返回。以代码13为例,当parallel_for_each函数返回时,即使Kernel的运行还没结束,checkpoint 1位置的代码也会照常运行,从这个角度来看,parallel_for_each函数是异步的。但是,当我们通过array_view对象访问计算结果时,如果Kernel的运行还没结束,checkpoint 2位置的代码会卡住,直到Kernel的运行结束,array_view对象把数据从显存复制到系统内存为止。
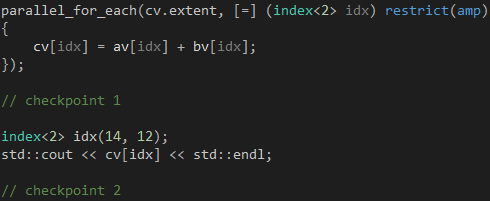
代码 13
既然Kernel的运行是异步的,我们很自然就会希望C++ AMP能够提供类似C++ PPL的continuation。幸运的是,array_view对象提供一个synchronize_async成员函数,它返回一个concurrency::completion_future对象,我们可以通过这个对象的then成员函数实现continuation,如代码14所示。事实上,这个then成员函数就是通过C++ PPL的task对象实现的。
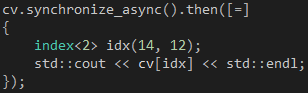
代码 14
你可能会问的问题
1. 开发C++ AMP程序需要什么条件?
你需要Visual Studio 2012以及一块支持DirectX 11的显卡,Visual C++ 2012 Express应该也可以,如果你想做GPU调试,你还需要Windows 8操作系统。运行C++ AMP程序需要Windows 7/Windows 8以及一块支持DirectX 11的显卡,部署的时候需要把C++ AMP的运行时(vcamp110.dll)放在程序可以找到的目录里,或者在目标机器上安装Visual C++ 2012 Redistributable Package。
2. C++ AMP是否支持其他语言?
C++ AMP只能在C++里使用,其他语言可以通过相关机制间接调用你的C++ AMP代码:
- How to use C++ AMP from C#
- How to use C++ AMP from C# using WinRT
- How to use C++ AMP from C++ CLR app
- Using C++ AMP code in a C++ CLR project
3. C++ AMP是否支持其他平台?
目前C++ AMP只支持Windows平台,不过,微软发布了C++ AMP开放标准,支持任何人在任何平台上实现它。如果你希望在其他平台上利用GPU做并行计算,你可以考虑其他技术,比如NVIDIA的CUDA(只支持NVIDIA的显卡),或者OpenCL,它们都支持多个平台。
4. 能否推荐一些C++ AMP的学习资料?
目前还没有C++ AMP的书,Kate Gregory和Ade Miller正在写一本关于C++ AMP的书,希望很快能够看到它。下面推荐一些在线学习资料:
- C++ AMP open specification
- Parallel Programming in Native Code (team blog)
- C++ AMP (C++ Accelerated Massive Parallelism)
- C++ AMP Videos
*声明:本文已经首发于InfoQ中文站,版权所有,《遇见C++ AMP:在GPU上做并行计算》,如需转载,请务必附带本声明,谢谢。

