
- 1探索Python数据容器之乐趣:列表与元组的奇妙旅程!
- 2RabbitMQ-Plugin configuration unchanged_enabling plugins on node rabbit@laptop-04itchu3: r
- 33_2Linux中内核级加强型火墙的管理
- 4记录一次mysql慢查询的优化过程
- 5美团团购订单系统优化记_团购订单系统的主要用户和作用
- 6C++轻量级界面开发框架ImGUI介绍
- 7LLMNR和NetBIOS欺骗攻击分析及防范_禁用netbios后会怎样
- 8H3C交换机ACL的单向访问解决方案_h3c 接口acl单向访问
- 9RK3568 OpenHarmony3.2 ADC按键驱动适配_open harmony 键盘驱动
- 10Windows环境部署安装Chatglm2-6B-int4
使用Kimi大语言模型实现知识图谱抽取_kim大模型
赞
踩
上一次我们用HuggingFists联合阿里通义大模型实现了知识图谱抽取,本次将利用最近比较热的月之暗面大模型Kimi来实现知识图谱抽取。
Kimi是由月之暗面公司开发的一款智能助手产品。2023年10月,Kimi智能助手初次亮相,支持约20万汉字的无损上下文能力,是当时全球首个同类产品。之后,Kimi的功能不断升级,如增加了联网搜索能力、上下文学习能力等。2024年3月18日,Kimi进一步提升其无损上下文长度,从最初的20多万字扩容到200万字,使得Kimi的人气急剧上升。因此我们也测试下Kimi的知识图谱抽取的能力。
由于HuggingFists的当前版本并未支持Kimi的算子,在验证使用前需要将算子导入HuggingFists中才能使用,可以从GitHub或者百度网盘中下载补充算子,在目录中中找到/moonshot/路径中下载。
下面将利用Kimi来抽取知识图谱,本次操作将对前期已经搭建的用阿里语言模型抽取知识图谱的例子进行修改。前期的操作可观看【玩转数据之利用LLM构建知识图谱】 视频,这里就不再具体操作了。
总体来说主要三个步骤:流程复制、流程修改、查看结果。
【流程复制】
在流程页面,点击右侧操作菜单栏,点击复制该流程,如下:
复制完成后,可以修改下流程的名称来区别开原流程。
【流程修改】
点击进程程进行编辑,可以将流程里面阿里语言大模型修改为Kimi大模型

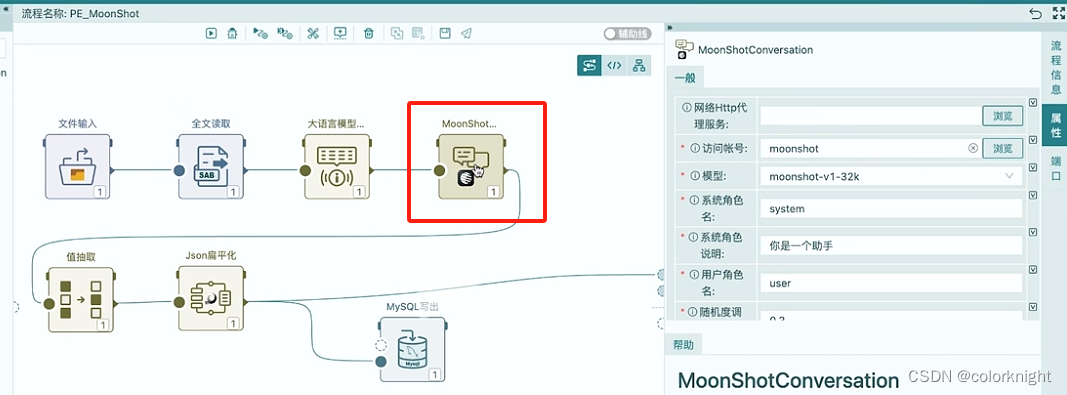
这里需要注意下,算子替换后,需要修改MoonShot算子的访问账号。以上配置完成后,我们验证下当前输出的结果与原来预期的输出结果是否一致。
可以用断点运行的方式,执行到该算子,验证输出到该处的数据是否符合要求。

运行完成后,在流程中的<查看数据>-><数据>中查看,如下。

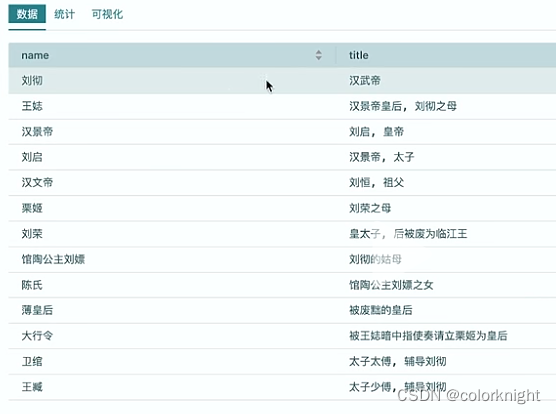
上图是本次修改后运行输出的结果,下图是原来阿里大模型反馈的结果。

经过对比后,我们发现输出结果有差异,主要包括:
- Kimi的输出结果不仅是人物和头衔,还输出了关系和事件;
- 字段的名称全部都有中文描述,与通义大模型的英文输出不同;
- 输出的Json符合标准格式,不需要做二次处理,如值剪切;
- Json数组的表达方式有中括号,需要做一些处理。
因此需要将后续的流程做一个调整,来适配当前的输出结果。我们先删除值剪切算子,然后将Json扁平化的格式做一个调整,与Kimi的输出结果想匹配,将原来的json结构调整为


【查看结果】
在启动流程的执行,查看下结果,发现其中有两个人的头衔title为空,对照原文,头衔信息没有描述,因此输出结果还比较令人满意。

反过来,再看下基于通义大模型的输出结果,一方面有的数据抽取有些不符合,另一方面抽取的信息里面包含了人物关系。
总体来说,两者抽取的没有太大差距,但是通义千问抽取出来的内容更多,可能提示的描述有关系。
最后欢迎大家尝试用HuggingFists联合Kimi做一些数据处理。相关演示过程我们已经录制了操作视频,可访问如下:BiliBili:《玩转数据之使用月之暗面Kimi抽取知识图谱》
HuggingFists的下载地址如下:
【Linux版】
Github:https://github.com/Datayoo/HuggingFists
百度网盘:https://pan.baidu.com/s/1zV_ScCtLgFQSYEb0wLmXIQ?pwd=2024
【windows版】
Github: https://github.com/Datayoo/HuggingFists4Win/tree/main
百度网盘:百度网盘 请输入提取码
【Mac版】
百度网盘:https://pan.baidu.com/s/12WxZ-2GgMtbQeP7AcmsyHg?pwd=2024
【补充算子】
GitHub: https://github.com/Datayoo/Operators
百度网盘:https://pan.baidu.com/s/1iqX0f8xzCXMWVDA7eaqH6Q?pwd=2024
如果使用过程中遇到问题,可加入我们的交流群:


