
- 1Android 不同屏幕字体自适应的实现方式_android字体大小适配
- 2Flask--orm
- 3MySQL主从复制搭建详解
- 4【0基础学爬虫】爬虫基础之自动化工具 Selenium 的使用_extract-stealth-evasions
- 5企业信息化建设包括哪些主要内容?帆软如何帮助企业完成数字化转型?
- 6cesium 加载 3dtiles 具体参数说明(配最优说明)_maximumscreenspaceerror
- 7flutter doctor 无法将”unblock-file” 项识别为 cmdlet,函数,脚本文件或可运行程
- 8Linux平台利用Ollama和Open WebUI部署大模型_open webui 如何添加模型(1)_open webui 离线部署
- 9GitBook+Markdown制作精美电子书_gitbook将markdown文件以文档网页的形式
- 10Could not connect to Redis at 127.0.0.1:6379: 由于目标计算机积极拒绝,无法连接。
详解pandas的read_csv函数_pandas read_csv参数详解
赞
踩
一、官网参数
pandas官网参数网址:pandas.read_csv — pandas 1.5.2 documentation
如下所示:

二、常用参数详解
1、filepath_or_buffer(文件)
一般指读取文件的路径。比如读取csv文件。【必须指定】
- import pandas as pd
-
- df_1 = pd.read_csv(r"C:\Users\wwb\Desktop\data1.csv")
-
- print(df_1)
2、sep(分隔符)
指定分隔符。如果不指定参数,默认逗号分隔。常见的分隔符:英文逗号(,),制表符(\t),竖线(|)。其中,英文逗号最常用。
- import pandas as pd
-
- df_1 = pd.read_csv(r"C:\Users\wwb\Desktop\data1.csv",sep=',')
-
- print(df_1)
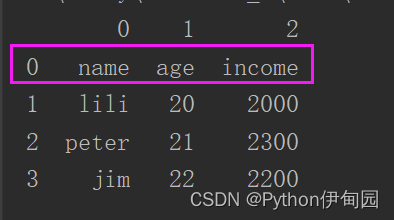
3、 header(表头)
表头即列名,默认第0行数据为表头。【从0开始计数】,以下为excel示意表头。

如果数据没有表头,可以通过header=None表示。
- import pandas as pd
-
- df_1 = pd.read_csv(r"C:\Users\wwb\Desktop\data1.csv",sep=',',header=None)
-
- print(df_1)
结果如下,第0行成为数据,列名重置为0、1、2。因此,需要仅对无表头数据设置此参数。
4、names(列名)
用于原始数据无表头,又想设置列名的情况。如下数据,直接读取,默认0、1、2为列名:
- import pandas as pd
-
- df_1 = pd.read_csv(r"C:\Users\wwb\Desktop\data1.csv",sep=',',header=None)
-
- print(df_1)


如果需要给列命名,可以通过names参数设定列名,即可将数据列命名。
- import pandas as pd
-
- df_1 = pd.read_csv(r"C:\Users\wwb\Desktop\data1.csv",sep=',',header=None,
- names=['name','age','income'])
-
- print(df_1)

5、dtype(数据类型)
指定字段数据类型。例如:
- import pandas as pd
-
- df_1 = pd.read_csv(r"C:\Users\wwb\Desktop\data1.csv",sep=',',header=None,
- names=['name','age','income'],
- dtype={'name':str,'age':int,'income':int})
-
- print(df_1)
- print(df_1.dtypes)
指定name列为str类型,age和income为int数据类型。【pandas中的object即python的str】
6、engine(引擎)
pandas解析数据时用的引擎。pandas 目前的解析引擎提供两种:c、python,默认为 c,因为 c 引擎解析速度更快,但是特性没有 python 引擎全。如果使用 c 引擎没有的特性时,会自动退化为 python 引擎。
与我们使用密切相关的:有时候读取数据文件会报错:OSError: Initializing from file failed
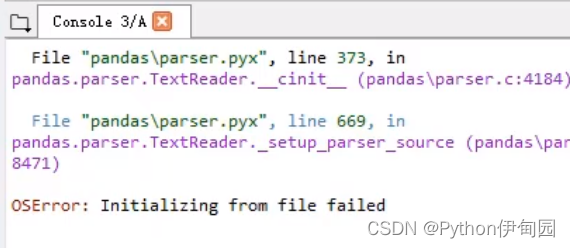
那么此时需要设定 engine='python' ,即可成功读取文件。
- import pandas as pd
-
- df_1 = pd.read_csv(r"C:\Users\wwb\Desktop\data1.csv",sep=',',header=None,
- names=['name','age','income'],engine='python')
-
- print(df_1)
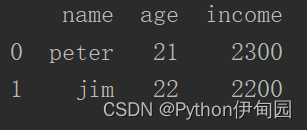
7、skiprows(跳过指定行)
对于前N行数据不想要读进内存,可以指定此参数跳过。
未指定结果:
指定 skiprows=1 即跳过一行结果:
- import pandas as pd
-
- df_1 = pd.read_csv(r"C:\Users\wwb\Desktop\data1.csv",sep=',',header=None,
- names=['name','age','income'],engine='python',skiprows=1)
-
- print(df_1)
8、encoding(编码)
文件编码:一般为 utf8 或者 gbk 编码。
如何查看与修改文件编码:如何修改文件的编码_Python伊甸园的博客-CSDN博客_如何修改文件的编码格式
- import pandas as pd
-
- df_1 = pd.read_csv(r"C:\Users\wwb\Desktop\data1.csv",sep=',',header=None,
- names=['name','age','income'],engine='python',skiprows=1,
- encoding='utf8')
-
- print(df_1)
以上就是最常用的pandas读取数据文件参数信息。
公众号内有更多干货分享哦~~


