- 1深度学习 - 张量的广播机制和复杂运算
- 2各个版本的tensorflow和python, cuda,cudnn对应的版本_tensorflow历史版本
- 3git分支打tag_gitlab 给分支设置 tag操作
- 4base64 前端显示 data:image/jpg;base64_base64 jpg
- 5AI大模型应用开发实践:3.使用 tiktoken 计算 token 数量_tiktoken 统计token
- 6CNN中的卷积的作用及原理通俗理解_添加卷积cnn的作用是什么?
- 7使用git将本地代码上传到gitee远程仓库_git上传本地代码到指定的仓库
- 8Python の TypeError 及解决方案(一)_typeerror: argument of type 'int' is not iterable
- 9【软件安装】结合树莓派4B(4G)和Ubuntu20.04的GitLab服务器搭建和使用_烧录ubuntu20系统树莓派需要更新的软件
- 10OpenCV 教程_machine learning classes
nlp入门之nltk_nltk分词
赞
踩
源码请到:自然语言处理练习: 学习自然语言处理时候写的一些代码 (gitee.com)
三、nltk工具的使用
3.1 nltk工具的安装
使用命令
pip install nltk安装nltk,但是仅仅是安装了nltk的框架,内部的软件包需要使用命令
nltk.download()执行命令会弹出一个窗口
无法下载软件包的问题可以参考这篇:NLTK语料库nltk.download()安装失败及下载很慢的解决方法_深度学习菜鸟的博客-CSDN博客
将服务器地址改为了http://www.nltk.org/nltk_data/
就可以正常安装软件包了
3.2 nltk分词操作
安装成功后就可以使用分词器进行分词了
示例:
- input_str = "Today's weather is good, very windy and sunny, we have no classes in the afternoon. We have to play " \
- "basketball tomorrow"
- tokens = word_tokenize(input_str)
- print(tokens)

3.3 nltk简单文本操作
nltk可以进行一些简单的文本操作,如统计词的个数,查找词的位置等
示例:
- # 文本操作
- t = Text(tokens)
- print(t.count('good'))
- print(t.index('good'))
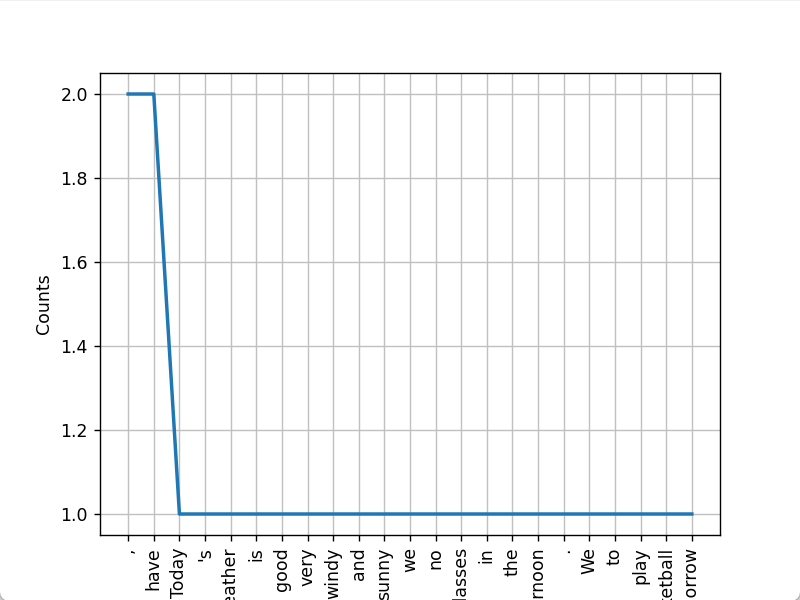
- print(t.plot())
![]()
3.4 停用词
出现频率很高但是对自然语言处理价值很低的词被叫做停用词
nltk自带了一些停用词表,输入命令就可以查看支持语言的停用词表
示例:
print(stopwords.fileids())
可以看到支持的语言不包含中文,所有接下来我们只使用英文语料库
输入命令就可以查看英文停用词表
示例:
print(stopwords.raw('english'))
数量很多就不全部展示了,接下来查找目前语料库中的停用词
print(test_words_set.intersection(set(stopwords.words('english'))))![]()
为了进一步进行自然语言处理,很多时候我们需要将停用词进行筛除,nltk就可以做到这个功能。
示例:
- filterd = [w for w in test_words_set if w not in stopwords.words('english')]
- print(filterd)
![]()
3.5 词性标注
nltk还可以将每个词的词性标注出来,词性表如下
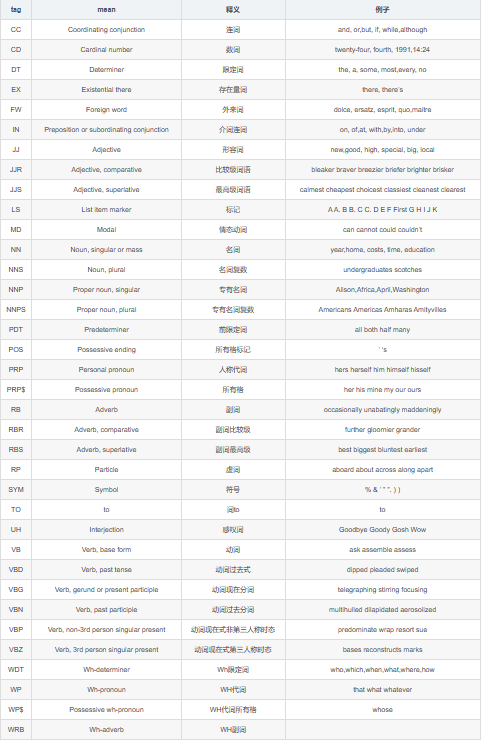
示例:
- tags = pos_tag(tokens)
- print(tags)

3.6 分块
可以根据词性对词进行分块
示例:
我定义了一个MY_NP的词并且用正则表达式写出这个块的句子词性是什么样的,nltk可以找出语料库中符合的块
- sentence = [('the', 'DT'), ('little', 'JJ'), ('yellow', 'JJ'), ('dog', 'NN'), ('died', 'VBD')]
- grammer = "MY_NP: {<DT>?<JJ>*<NN>}"
- cp = nltk.RegexpParser(grammer)
- result = cp.parse(sentence)
![]()
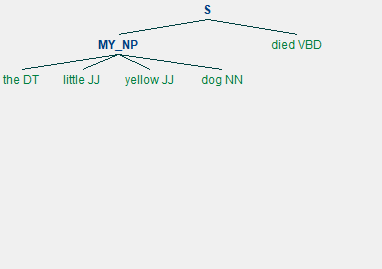
3.7 命名实体识别
nltk可以提取出一些语句中的实体
示例:
# 命名实体识别
- sentence = "Edison went to Tsinghua University today"
- print(ne_chunk(pos_tag(word_tokenize(sentence))))

Edison被识别出是个人,清华大学被识别出是个组织
3.8 数据清洗
网络上爬取的语料中有可能有很多特殊符号,对nlp造成了很大的影响,所以需要一些方法来进行数据清理,利用nltk可以很好的办到这些
示例:
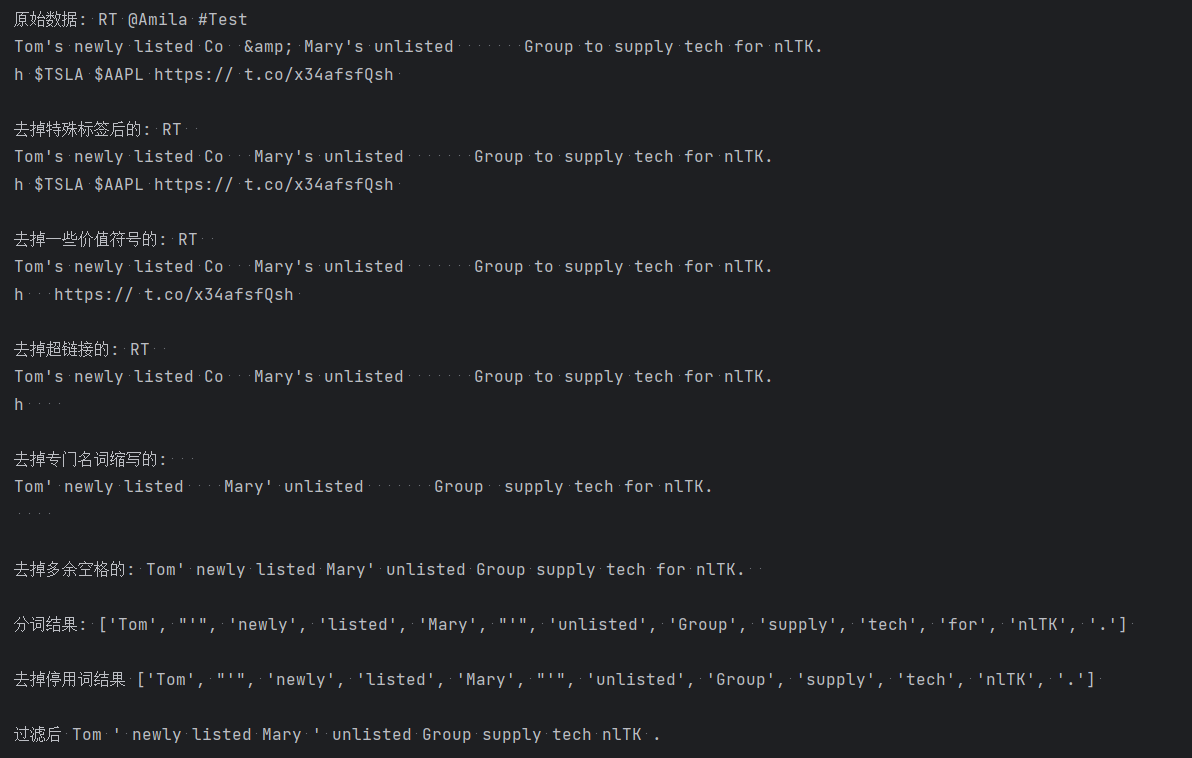
- # 数据清洗
- s = "RT @Amila #Test\nTom\'s newly listed Co & Mary\'s unlisted Group to supply tech for nlTK.\nh $TSLA " \
- "$AAPL https:// t.co/x34afsfQsh"
- cache_english_stopwords = stopwords.words('english')
-
-
- def text_clean(text):
- print('原始数据:', text, "\n")
-
- # 去掉HTML标签(e.g. &)
- text_no_special_entities = re.sub(r'&\w*;|#\w*|@\w*', '', text)
- print("去掉特殊标签后的:", text_no_special_entities, '\n')
- # 去掉一些价值符号
- text_no_tickers = re.sub(r'\$\w*', '', text_no_special_entities)
- print("去掉一些价值符号的:", text_no_tickers, '\n')
- # 去掉超链接
- text_no_hyperlinks = re.sub(r'https?://.*/\w*', '', text_no_tickers)
- print("去掉超链接的:", text_no_hyperlinks, '\n')
- # 去掉一些专门名词缩写,简单来说就是字母较少的词
- text_no_small_words = re.sub(r'\b\w{1,2}\b', '', text_no_hyperlinks)
- print("去掉专门名词缩写的:", text_no_small_words, '\n')
- # 去掉多余空格
- text_no_whitespace = re.sub(r'\s\s+', " ", text_no_small_words)
- text_no_whitespace = text_no_whitespace.lstrip(' ')
- print("去掉多余空格的:", text_no_whitespace, '\n')
- # 分词
- tokens = word_tokenize(text_no_whitespace)
- print("分词结果:", tokens, '\n')
- # 去停用词
- list_no_stopwords = [i for i in tokens if i not in cache_english_stopwords]
- print('去掉停用词结果', list_no_stopwords, '\n')
- # 过滤后结果
- text_filtered = ' '.join(list_no_stopwords)
- print('过滤后', text_filtered)
-
-
- text_clean(s)