
- 1卡尔曼滤波matlab程序实现_extractball函数
- 2centos7安装英伟达驱动教程和nvidia-smi命令大全_centos安装nvidia-sim工具
- 3Selenium与JavaScript--Selenium深入浅出之三_自动化js点击和selenium点击的区别
- 4带你解锁AC/DC、DC/DC转换器基础_通过fb force 电流控制输出电压
- 5vscode clangd 插件,无法下载clangd包的解决办法_clangd下载
- 6虚拟机VMware16安装Windows sever 2003 standard详细教程(内含下载链接)_windows2003server镜像下载
- 7win7驱动程序未经签名可以使用吗_w7禁用驱动程序签名
- 8docker容器内外的操作_docker 容器内的mysql,访问容器外的文件
- 92022 年 9 月青少年软编等考 C 语言一级真题解析
- 10MYSQL 5.5不支持字段类型为datetime且默认值为NOW()的建表语句_mysql5没有datetime类型吗
ChatGPT 价格里掩盖的算力分布秘密 | 新程序员
赞
踩

【导读】当前,大语言模型的商业化持续进行,本文聚焦这一变革背景下的 ChatGPT 定价机制,深入剖析其核心技术内涵。通过细致研究 ChatGPT-3.5 turbo 采用的 Decode-Only 架构,作者系统地探讨了模型在接收到输入提示并生成相应输出的过程中,如何差异化利用 GPU 算力资源,进而阐明了支撑该定价策略的独特技术原理。
本文精选自《新程序员 007:大模型时代的开发者》,《新程序员 007》聚焦开发者成长,其间既有图灵奖得主 Joseph Sifakis、前 OpenAI 科学家 Joel Lehman 等高瞻远瞩,又有对于开发者们至关重要的成长路径、工程实践及趟坑经验等,欢迎大家点击订阅年卡。
作者 | 李波
责编 | 王启隆

2022 年 8 月,美国科罗拉多州举办艺术博览会,《太空歌剧院》获得数字艺术类别冠军,此作品是游戏设计师 Jason Allen 使用 AI 绘图工具 Midjourney 生成;同年 11 月 30 日由 OpenAI 研发的一款聊天机器人程序 ChatGPT 发布,生成式 AI(AIGC)概念开始极速式地席卷全球,逐渐深入人心,预示着一个新的 AI 时代。

现在回过头来看这幅《太空歌剧院》,你有什么感觉?
随着 ChatGPT 用户爆发式的增长,大型语言模型(Large Language Model,简称 LLM)受到企业、政府、大众的广泛关注。由于 ChatGPT 的闭源策略,开源大语言模型在 2023 年迭代频繁,种类繁多。随着语言模型研究的深入,大多数从业人员对语言模型的本质及其功能有了基本的了解,但在模型商业化方向上,不同的模型到底如何定义模型的服务成本,又为什么该这样的定义,常常无从下手。ChatGPT 作为 LLM 应用的开创者,自然有其答案,但是又如此的不明显或让人困惑。
本文试图通过深入分析模型结构,了解成本成因,提炼 ChatGPT 的定价方法论,指导通用语言模型推理的基础方向,其中涉及的技术分析均以 ChatGPT-3.5 turbo 采用的 Decode-Only 架构结构为基础,重点讨论宏观逻辑方向,并不做精确指向。

令人困惑的价格
ChatGPT 是一个复杂的自然语言处理平台,利用先进的机器学习算法来分析和创建类似人类的文本或说话方式。它的功能非常广泛,包括文本推演、文本分类和语言翻译等。针对这类模型,合理的定价方式会是一个有意思的问题。
对此,OpenAI 给出的答案非常新颖,其 ChatGPT 平台并没有按调用次数定价,而是对数据处理进行定价,这让人有点匪夷所思,甚至违反常识(参见图 1)。更有特点的是,ChatGPT 定价针对输入数据与输出数据的差异,可见其不仅在应用层面带来惊艳,定价也是与众不同。
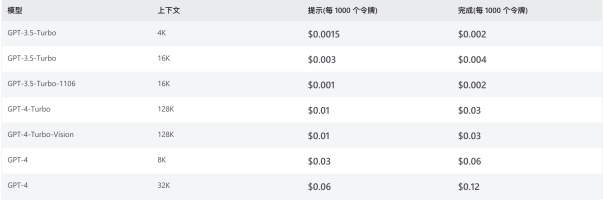
图 1 ChatGPT 定价表
我曾与 Gartner 高级分析师就此问题展开过讨论,对方的观点更倾向于 OpenAI 是出于商业竞争考虑做出的定价策略,此策略对成本的相关性较弱,为了更快速的市场占有率而制定。我同意这样的观点。
由于 ChatGPT 的模型结构、部署卡数、限流策略、服务器资源的水位控制、最大的并发能力以及首 token 的延迟标准等影响推理系统的重要信息未被披露,我们无法计算出真实的推理成本以及他们的 API 毛利率。但作为世界上用户人数增长最快的应用,先拉低初次使用费用,再利用规模效应,优化算法与推理系统,以达到低成本的长尾收获,不失为一种冷启动的商业模式。只是,这种思路并没有完整的回答我内心的关于输入与输出定价不同的问题:它们之间的价格为什么是成倍的?且大多为 2 倍?这似乎隐约映射着某种底层逻辑。
我们先回顾一下图 1 中的几处关键概念:
-
token
token 是大语言模型的一个基本概念,它本质上是用于分析和处理的语言的构建块。在像 ChatGPT 这样的语言模型中,token 对于理解和生成自然语言文本方面起着至关重要的作用。
-
上下文窗口
上下文窗口是语言模型在处理文本时可以考虑的最大文本量。ChatGPT 系列的模型中都带有一个上下文窗口,如 GPT-416K,GPT-432K 这类,其中的 16K 就是指的模型可以一次性处理的 token 数量;如果用户输入的提示超出了模型的上下文窗口限制,它就会忘记限制之后的内容。
-
提示词
提示词是大语言模型的输入,是对话的开始,亦是一段指令、背景描述、几个例子或任何用户想告诉大语言模型的事情。
我们再看一下通用模型的一般服务成本:
-
推理成本,即调用 LLM 生成响应的成本。
为硬性支出成本,表现为 GPU 物理服务器或云 GPU 服务器成本,高速网络成本,存储成本等。
-
调整成本,即调整定制的 LLM 预训练/微调模型响应的成本。
为软性支出成本,主要表现为研发人力的投入,对模型加速、服务化、监控等方面的投入成本。
-
托管成本,即部署和维护 API 背后的模型、支持推理或调优的成本。
为硬性支持成本,私有化或云的托管费用。
也许还有更多成本与商业定价策略未包含其中,但是以上 3 点会在定价策略中优先考虑,其中推理成本占比最高,尤其是其中的 GPU 算力成本,为了便于讨论,我们姑且将 ChatGPT 的定价策略都归因到算力上。

提示 Token 应该计费吗?又为什么更便宜?
LLM 目前的主流模型为 Decoder-Only 类型中的 CausalLM(Causal Language Model,因果语言模型),它的算力释放全过程如图 2 表示。
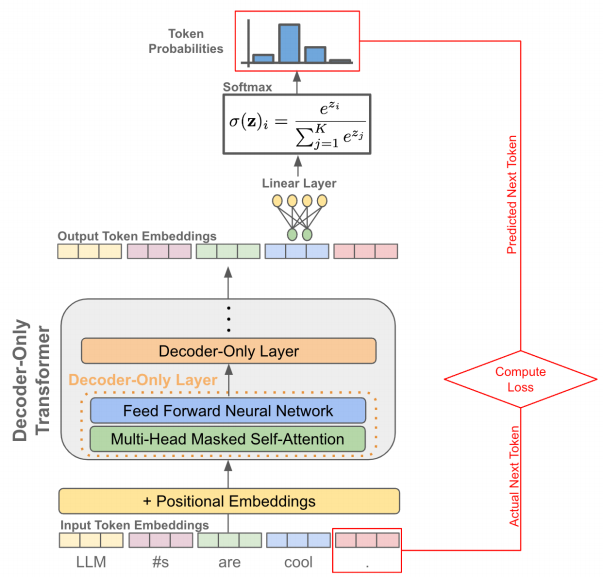
图 2 CausalLM 的算力释放全过程
全流程中核心算力密度集中在 Decoder-Only 层,细化步骤如图 3。
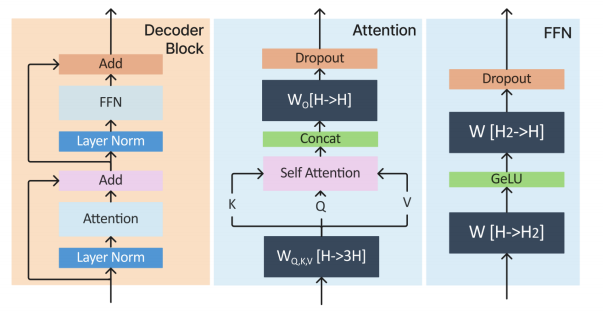
图 3 细化步骤示意图
Decoder-Block 主要分 2 部分,Attention 和 FFN:
-
Attention,模型参数有 Q,K,V 的权重矩阵 WQ,WK,WV 以及 Bias,输出权重矩阵 Wo 以及 Bias,4个权重矩阵的维度为 [hidden_size, hidden_size],4 个 Bias 的维度是 [hidden_size]。
-
FFN,由 2 个线性层组成,一般首层会将维度从 H 映射到 3H 或者 4H,后层再将 3H/4H 映射回 H。
我们继续推演,窥探一下推理过程的算力分布,这里仅列出过程中的关键操作,省略计算的详细推导过程,同时忽略 embedding,位置编码,logits 的计算。下面先简短回顾核心公式以及计算张量的维度变化(参见图 4、图 5、图 6、图 7)。
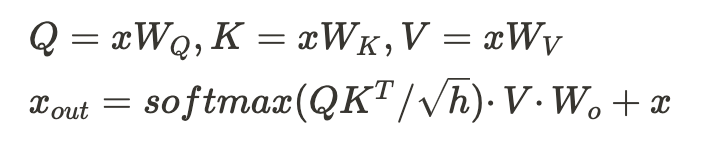
图 4 Attention 计算量公式
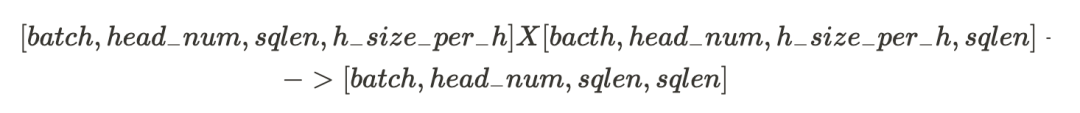
图 5 QK^T 矩阵乘法的输入和输出形状

图 6 Xout 输入和输出形状
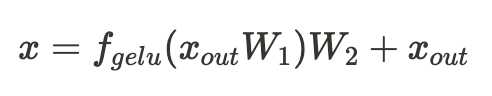
图 7 FFN 计算量公式
在 embedding 维度为 d’ 的情况下,提示 sqlen 在第一次推理时的单一 token 需要的算力分布大致如下,单位为 Flops(见图 8):
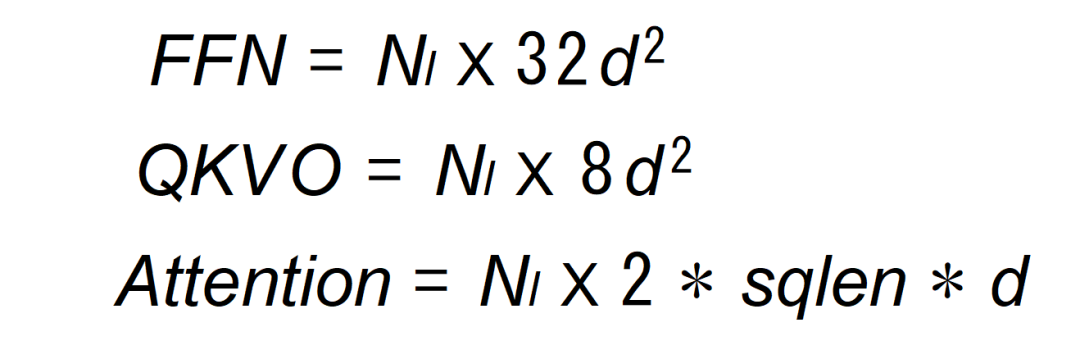
图 8 算力分布公式
这里重点解释一下 Attention 的计算为什么不是 Nl×4×sqlen×d,针对自回归解码器模型而言,token 只会关注先前的 token 序列,这意味着注意力分数矩阵 S 是一个下三角矩阵,不需要计算上三角部分,即 QKT 的计算只计算下三角,为 (sqlen+1)×d。另外,在 Attention 输出变换时(计算图 2 的维度中, SOFTMAX 的返回值为下三角),也能减少一半计算,最后计算量为 Nl×2×sqlen×d。
以上是在 Batch Size=1 的一次向前推理,后续的每一次推理理论上都需要相同的计算量。实际情况中,由于推理框架加速技术和 KVcache 的作用,实际计算量会显著下降,但推理速度并不会显著提升,这是因为还涉及到模型的计算需求与访存需求的限制或权衡。
对于访存密集型模型来说,其推理速度受限于 GPU 访存带宽,每种不同 GPU 的访存带宽不一,模型大小不一,其推理速度差别较大,这里只从宏观层面阐述一般性总结,忽略模型数据或中间结果的数据传输与访存带宽之间的关系。
Decoder-Only Transformer 模型为访存密集型模型,其推理过程分为 2 个阶段,Stage 1(阶段 1)是 Prefill,Stage 2(阶段 2)为 Decode,Prefill 由于可以通过大 Batch Size 计算,使得这一阶段为计算密集型,推理速度较快。
Decode 为逐个 token 解码,采用自回归形式,期间需要在 HBM 和 SDRAM 中频繁搬运数据,导致模型进入访存密集型阶段,推理速度较慢,GPU 显存分布可见图 9,从上到下,访存带宽指数级减少。
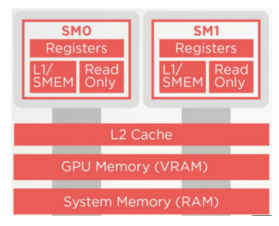
图 9 GPU 显存分布示意图
图 10 和图 11 是 LLaMA-13B 在 A6000 上对输入序列 1024 的测试表现,我们可以交叉来看,在 Batch Size 递增时,Prefill 的推理时间几乎不变,各类计算阶段涨跌不大,但计算密度在增加;在 Decode 阶段,Batch Size=1 的情况下 Decode 的延迟达到了 Prefill 的 200+ 倍,因为其计算密度几乎为 0,随着 Batch Size 递增,计算密度缓慢提高,但(FFN+QKVO)的线性算子的延迟急剧下降到 20+ 倍以下。
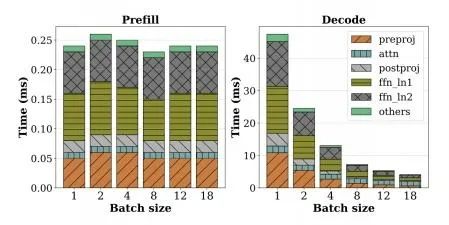
图 10 测试表现图其一
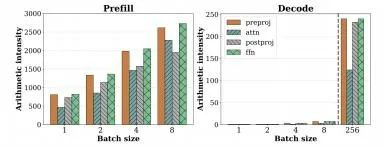
图 11 测试表现图其二
可以推断,Decode 阶段增大 Batch Size 可以提高计算密度,对整体延迟降低有较大帮助,在此例子中如果达到 256,Decode 会重新回到计算密集型,整体推理延迟会显著下降,但在达到这个临界 BatchSize 之前,相比 Prefill 是数量级的缓慢。
在真实的生产场景,由于 GPU 显存的限制,不可能直线增大 Batch Size,因为还要留给 KV Cache 一些空间。就本例而言,Batch Size=18 或许已经是最优选择。这里比较有意思的是 Attention 的计算延迟并没有从大 Batch Size 中受益,几乎没有变化。最后一句话总结,Decode 无论是否真实的占用了 GPU 算力,都是占用了 GPU 的使用时间,理论上 GPU 在单位时间内的价格是固定的,占用时长直接与使用费用成正比。
回到我们的问题,我们很容易分辨出 Prefill 阶段对应 API 输入 prompt 处理,API 回复对应 Decode 阶段的处理。由于对算力占用时长的不同,它们的定价有差异性才是正常,图 1 定价 Prefill 阶段几乎是 Decode 阶段的 2 倍,但是时长占比可能是 20 ~ 200 倍,似乎中间还有一个 scale 值;这或是因为我们只是考虑单卡单 session 的情况,在真实的 GPU 集群场景下,除了单卡加速外,TP/PP 的并行计算,在集群性能的极限并发情况下,scale 可能达到 10 ~ 100 倍。另外,由于 Prefill 的延迟极短,针对单 token 而言费用极低,从定价策略来说,可能只是象征性的,Decode 阶段才是核心,内容是持续产生的,也是我们需要的。某种程度上可以理解为,API 的单一定价策略,即总体成本以输出 Decode 阶段为主。

新势力带来的新趋势
ChatGPT 的 tokens 价格在业内是极具竞争力的,OpenAI 的 AI infra 能力起到了决定性的作用,通过量化、TT、模型分布式部署、算子融合、显存管理和 CPU offload 等技术,再加之商业让利,是可能达到这样的定价水平。
ChatGPT 在 2023 年的几次降价都说明了 OpenAI 算法和工程化能力的快速进步,向技术拿收益确实是实打实的,不断降低模型推理成本是推动大语言模型广泛应用及实现 AGI 目标的关键驱动力。2024 年所有的模型创新和推理加速技术创新一定会围绕高性能低成本这个目标。
基于 Decoder-Only Transformer 类似的 LLM,存在计算与存储都与输入成二次方的关系,对算力、显存大小、访存带宽都有极高的要求,加上对上下文窗口的限制以及窗口内部分遗忘的问题,对 LLM 应用也产生了一定阻力,学术界因此也在不断发展新的模型结构,试图解决这些问题。
目前比较有创新力的新模型结构有 Striped Hyena 和 Mamba,它们突破了随着文本长度的增加,算力需求成二次方的要求,几乎可以做到算力对输入文本线性增长,并可以分段拆分输入文本,并行计算,极大提高推理速度,使得推理成本会进一步大幅降低。
另外,新的模型组合方式有 Mistral AI 发布的 Mixtral-7B×8-MoE(混合专家模型),由 8 个 7B 参数组成的网络,这种方式不仅可以提高模型处理信息的效率,提升模型性能(几乎已超越 LLaMa-70B),更重要的是降低了运行成本。据官方说明,Mixtral-7B×8-MoE 实际参数并非 56B,而是 45B。该模型中只有前馈层是各专家独有,其余参数与 7B 模型情况相同,各专家共享。每次推理过程,门控路由网络只会选择 2 个专家进行实际推理,过程中只会使用其中 120 亿参数,每个 token 会被 2 个模型处理。于是,MoE 模型的推理速度和成本与 12B 参数规模的模型是一样的。当然,这暂时忽略了 45B 模型的部署成本,部署成本根据模型的量化程度所需要的启动 GPU 显存开销是不同的,比如 FP16 精度下,至少需要 90GB 的空间才能启动,这需要 2 张 A100/800-80GB 的卡,或者 3 张 A100-40GB 的卡。如果精度降到 4bit,只要大于 23GB 就满足要求。MoE 开启了用相对的低算力却可以达到需要高算力才能产生的模型精度的新范式,以独特的维度降低了大模型的服务成本。
2024 年,新的模型结构与加速方式,配合新一代 GPU 硬件的发展,预计将对后续的模型研究产生积极的影响,并可能改写现行的计价模式——回归传统的按调用次数计费。这种转变不仅预期大幅降低使用成本,同时有利于简化计费系统架构设计及其流量控制管理等方面的操作。然而,调用次数计费模式的核心在于揭示了一个趋势:模型能力的价值在定价中的比重将显著提升(当前这一比例接近个位数);与此同时,模型推理成本在定价中的比重则会大幅下降(当前几乎占据了 100%)。
随着成本逐渐走低,商业价值得到提升,应用回归商业底层逻辑,最终让大语言模型真正走进千行百业,发挥推动产业变革,企业数字化升级的新手段。
![[ 云计算 | AWS ] ChatGPT 竞争对手 Claude 3 上线亚马逊云,实测表现超预期](https://img-blog.csdnimg.cn/direct/73f803739ca04eefb804ccda18780f38.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

