
- 13GPP 38.311 NR Radio Resource Control (RRC) protocol specification_3gpp ts 38.331
- 2鸿蒙迎来纯血版本,你还不来学习一下
- 3千万流量秒杀系统-过载保护:如何通过熔断和限流解决流量过载问题?_微服务过载保护
- 4android ubuntu 桌面快捷方式,[转] 给ubuntu中的软件设置desktop快捷方式(以android studio为例)...
- 5netty实现webSocket握手处理并添加响应头_netty websocket 握手
- 6Windows安装DVWA(全过程)_windows搭建dvwa
- 7图像处理代码编写三:基于C++的高斯滤波程序实现_高斯滤波c++代码
- 8用通俗易懂的方式讲解:一文搞懂大模型 Prompt Engineering(提示工程)_prompt engineering 的原理
- 9Android针对视频部分截屏是黑色的解决办法_andorid 截屏视频控件是黑的
- 10限流算法总结:计数器、滑动窗口、漏桶算法、令牌桶算法(抄的)_滑动窗口限流算法
Chatglm3+langchain智能对话,本地文本库构建问答,图片文本库构建与问答搜索_本地搭建chatglm3 知识库问答
赞
踩
Chatglm3+langchain
主要功能:
- 调用语言模型
- 将不同数据源接入到语言模型的交互中
- 允许语言模型与运行环境交互
Langchain应用场景
**1. 文档问答:**常见的Langchain用例。在特定文档上回答问题,仅利用这些文档中的信息来构建问答答案(本次验证已实现,俗称打造自己的chatGPT问答库)。
**2. 个人助理:**主要用例之一。个人助理采取行动,记住互动,并了解您的数据。
**3. 查询表格数据:**使用语言模型查询表类型结构化数据(csv,SQL,DataFrame)
**4. 与API交互:**使用语言模型与API交互非常强大。它允许他们访问最新信息,并允许他们采取行动。
**5. 信息提取:**从文本中提取结构化数据。
**6. 文档总结:**压缩较长文档,一种数据增强生成。
Langchain中提供的关键模块
Modules: 支持的模型类型和集成。
Prompt:提示词管理、优化和序列化。
Memory:内存是只在链/代理调用之间持续存在的状态。
Indexes:当语言模型与特定于应用程序的数据相结合时,会变得更加强大-此模型包含用于加载、查询、更新外部数据的接口和集成。
Chain:链是结构化的调用序列【对LLM或其他使用程序】
Agents:代理是一个链,其中LLM在给定高级指令和一组工具的情况下,反复决定操作,执行操作并观察结果,直到高级指令完成。
Callbacks:回调允许您记录和流式传输任何链的中间步骤,从而轻松观察、调试、评估应用程序的内部。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
硬件需求
ChatGLM3简介
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,ChatGLM3-6B 引入了如下特性:
-
更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base
采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base
具有在 10B 以下的基础模型中最强的性能。 -
更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt
格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent
任务等复杂场景。 -
更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型ChatGLM3-6B-32K。
主要功能:
- 调用语言模型对话。
- 可以执行各种工具调用,如搜索、翻译、计算、绘图等。
- 支持多种语言和多种模式,如中文、英文、日文等。
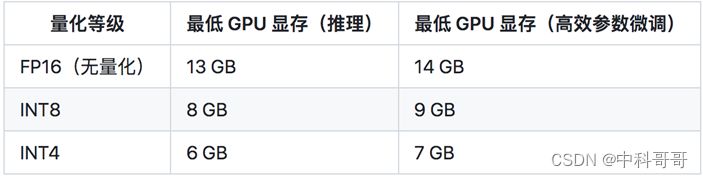
推理的GPU资源要求

langchain数据连接组件data connection
-
文档加载器:从许多不同的来源加载文档
-
文档转换器:分割文档,删除多余的文档等
-
文本嵌入模型:采取非结构化文本,并把它变成一个浮点数的列表 矢量存储:存储和搜索嵌入式数据
-
检索器:查询你的数据
langchain-ChatGLM3 本地知识库搭建的流程
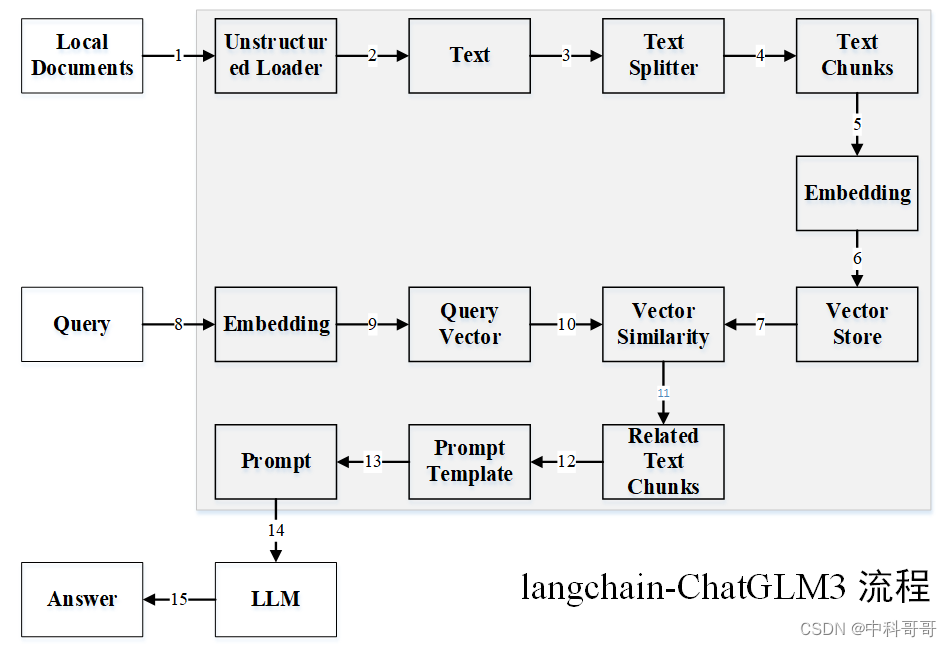
如上图,本地知识库搭建的流程如下:
(1-2)准备本地知识库文档目前支持 txt、docx、md、pdf 格式文件;
(3-4)对文本进行分割,将大量文本信息切分为chunks;
(5)选择一种embedding算法,对文本向量化;
(6)将知识库得到的embedding结果保存到数据库,就不用每次应用都进行前面的步骤;
(7)向量相似度计算方式;
(8-9)将问题也用同样的embedding算法,对问题向量化;
(10)从数据库中查找和问题向量最相似的N个文本信息;
(11)得到和问题相关的上下文文本信息;
(12)获取提示模板;
(13)得到输入大模型的prompt比如:问题:,通过以下信息汇总得到答案;
(14)将prompt输入到LLM得到答案;
(15)结果输出。
**总结:**过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
软件环境
主要包含以下功能模块与推荐版本
-
确保Python 3.8 - 3.11。- 1
-
pytorch 2.01,推荐2.0及以上版本。
-
CUDA 12.0,驱动525,建议使用11.4及以上版本。
-
Transformers,推荐版本4.30.2 及以上版本。
-
faiss-gpu, 推荐版本1.7.2及以上。
-
langchain,推荐版本0.1.1及以上。
-
langchain-community,推荐版本0.0.15及以上。
-
langchain-core,推荐版本0.1.15及以上。
-
langdetect,推荐版本1.0.9及以上。
-
langsmith,推荐版本0.0.83及以上。
-
prompt-toolkit,推荐版本3.0.43及以上。
-
semantic-version,推荐版本2.10.0及以上。
-
sentence-transformers,推荐版本2.2.2及以上。
-
sentencepiece,推荐版本0.1.99及以上。
-
tiktoken,推荐版本0.5.2及以上。
-
timm,推荐版本0.9.12及以上。
-
tokenizers,推荐版本0.15.0及以上。
-
typing_extensions,推荐版本4.9.0及以上。
-
unstructured,推荐版本0.11.8及以上。
-
unstructured-client,推荐版本0.15.2及以上。
-
unstructured-inference,推荐版本0.7.18及以上。
-
unstructured.pytesseract,推荐版本0.3.12及以上。
遇到错误与解决方案
该部分内容体量很大,错误很多,需自行百度与google等方式修改参数、环境与代码等解决。
难点与关键点
Split(切割文档)
因为大模型提示词有最大token限制,我们不能把太多的文档内容传给AI,通常是把相关的文档片段传过去就行,所以这里需要对文档切片处理。
Langchain虽然提供了很多文本切割的工具,其中langchain默认使用RecursiveCharacterTextSplitter。
- RecursiveCharacterTextSplitter():按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
- CharacterTextSplitter():按字符来分割文本。
- MarkdownHeaderTextSplitter():基于指定的标题来分割markdown 文件。
- TokenTextSplitter():按token来分割文本。
- SentenceTransformersTokenTextSplitter() : 按token来分割文本
- Language() - 用于 CPP、Python、Ruby、Markdown 等。
- NLTKTextSplitter():使用 NLTK(自然语言工具包)按句子分割文本。
- SpacyTextSplitter() - 使用 Spacy按句子的切割文本。
但是文本的切割依然是难点,切割结果直接影响到最后的问答结果,因此该部分的大量调参和方法需进一步深入研究
实现情况
目前已经完全实现Chatglm3+langchain 的整体功能流程与框架,所有流程借助Chatglm+langchain官方文档、百度、google等方式修改参数、环境与代码等实现。
目前已经实现本地文库加载的文件类型:
- .Txt
- .Doc
- .Docx
- .Md
- .Html
- .Csv
- .odt
- .json(目前中文解析乱码,需进一步处理)
- .ppt、.pptx
- .jpg、.png、.tif等图片格式(该部分需要引入OCR图片文字识别»【自然语言处理技术】)
- 扫描件文档
- 网络端信息(借助爬虫等技术)(尚未实现)
实现方式为:文件批量处理加载
模型大小
Chatgml3:11G
Langchain base:1.3G bge-large-zh
文本成果截图
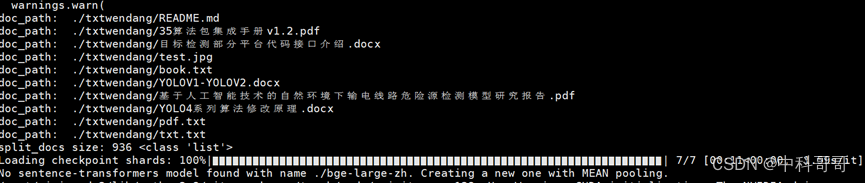

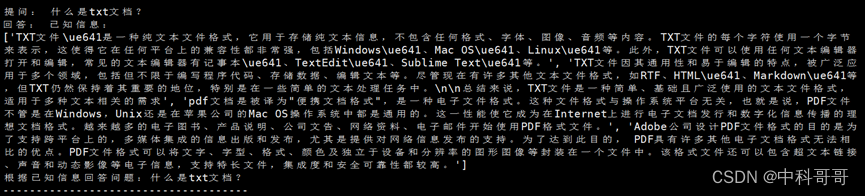


图片支持结果示例一(图像文本识别)
图片支持主要是实现图片文字的识别与提取,目前主要流行的方式为OCR模型算法识别
OCR简单介绍
OCR(Optical Character Recognition)是光学字符识别的缩写,是一种把纸质文件中的文字和图形信息转化成计算机可以处理的电子文件的技术。随着人工智能和深度学习技术的发展,OCR技术也得以快速发展和更新。
从原理上讲,OCR技术可以分为两个部分:图像处理和字符识别。图像处理部分对输入的图像进行预处理,包括图像旋转、裁剪、灰度化、二值化、噪声去除等。字符识别部分则是识别处理过后图像中的字符信息,并将识别结果输出。
图片OCR + langchain + chatglm3 框架图
图片OCR + langchain + chatglm3 框架图如下所示
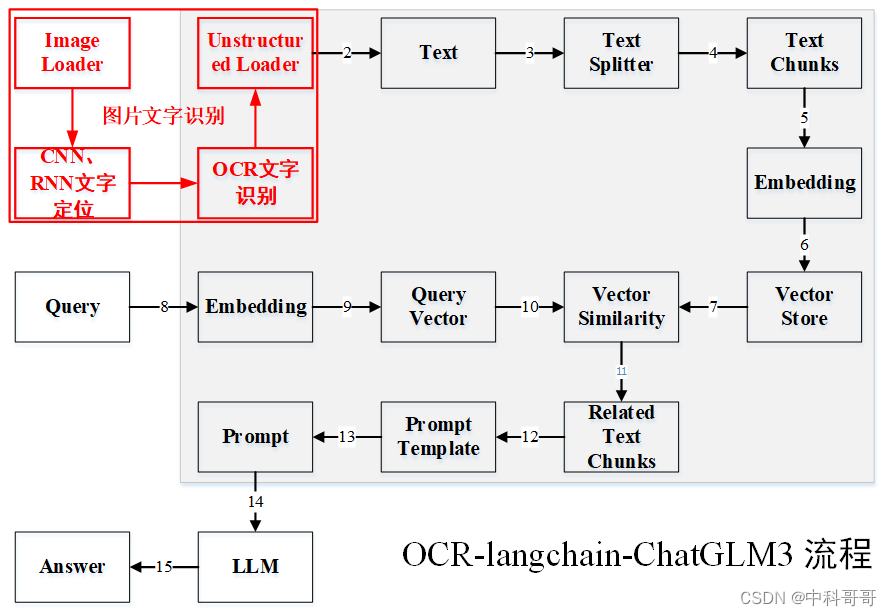
OCR + langchain + chatglm3框架图
该部分主要流程是图片文字识别算法
- 首先载入图片:如jpg、jpeg、png、tif等;
- 利用CNN 和RNN技术实现图片中文字定位;
- 对定位区域图片文字进行识别;
- 对识别结果进行文本话处理;
- 将处理结果接入langchain + chatglm3框架。
OCR算法选择RapidOCR算法原因
- 多语言支持
RapidOCR支持多达70种语言的OCR识别,覆盖了世界上大部分主要语言,可适应全球性的应用需求,例如中文、英语、日语、韩语和阿拉伯语等。 - 高精度识别
RapidOCR基于深度学习算法进行OCR识别,其精度比传统的基于规则的方法和传统基于特征的方法更高,有更好的适应性。 - 高效识别
RapidOCR的名字已经表明了其速度优势,它不仅能够快速识别文字字符,还可以快速预处理图像文件。对于大型图像文件,也可提供高效处理能力,提高程序的执行效率。 - 易于使用
RapidOCR设计简单易用,遵循易用性、稳定性和可扩展性原则,兼容Linux、Windows和MacOSX等多个操作系统平台,支持命令行和API两种方式,并提供详细的文档和示例代码供用户参考使用。
OCR 文字识别代码源
https://github.com/PaddlePaddle/PaddleOCR.git
https://gitee.com/owenwdx/RapidOCR#rapidocr
OCR 各算法性能对比
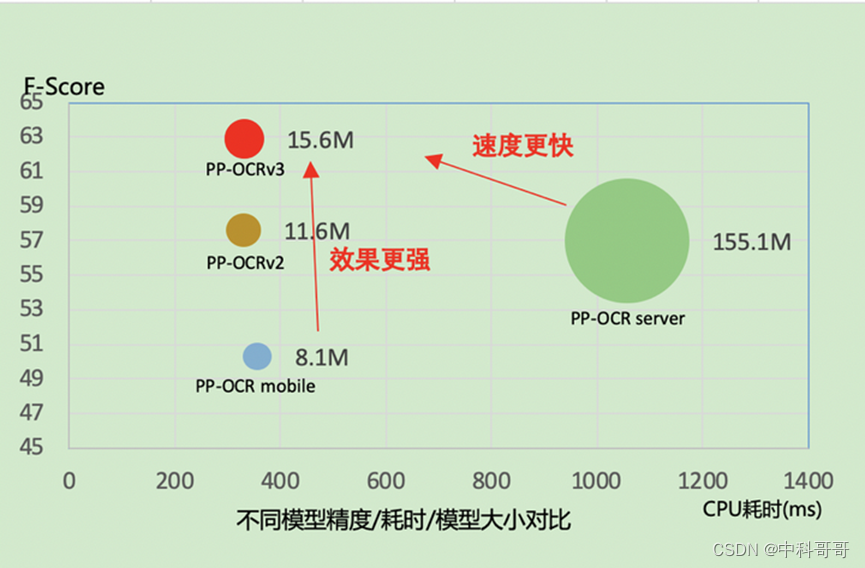
OCR的整体的框架图
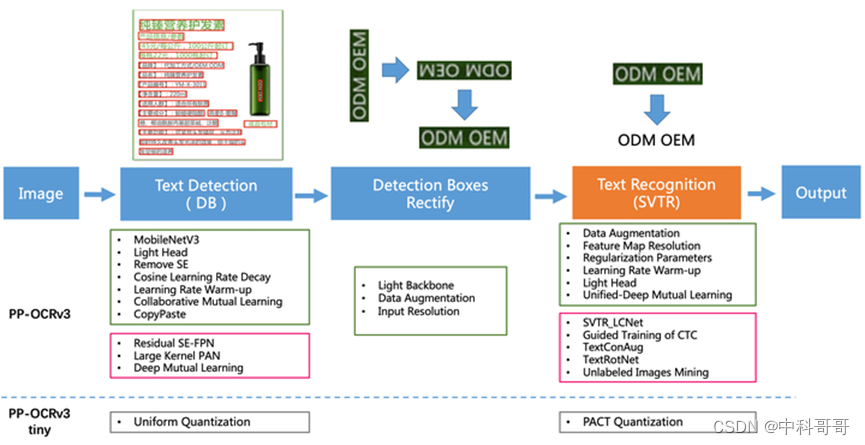
OCR的整体的框架关键点
- 检测模块
LK-PAN:大感受野的PAN结构
DML:教师模型互学习策略
RSE-FPN:残差注意力机制的FPN结构 - 识别模块
SVTR_LCNet:轻量级文本识别网络
GTC:Attention指导CTC训练策略
TextConAug:挖掘文字上下文信息的数据增广策略
TextRotNet:自监督的预训练模型
UDML:联合互学习策略
UIM:无标注数据挖掘方案
关键技术与应用场景统计
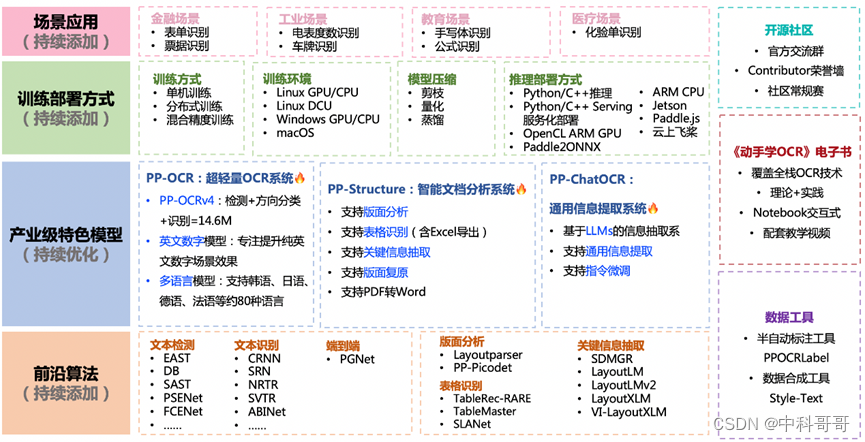
OCR + langchain + chatglm3识别结果问答示例
- 示例一、图片文字OCR 算法提取,创建矢量库并问答结果:

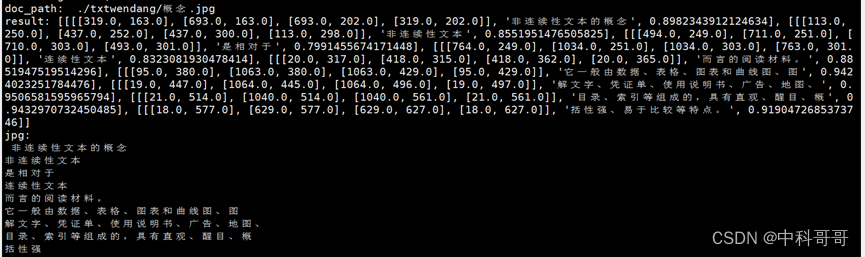

- 示例二、扫面件情况

扫描件识别结果
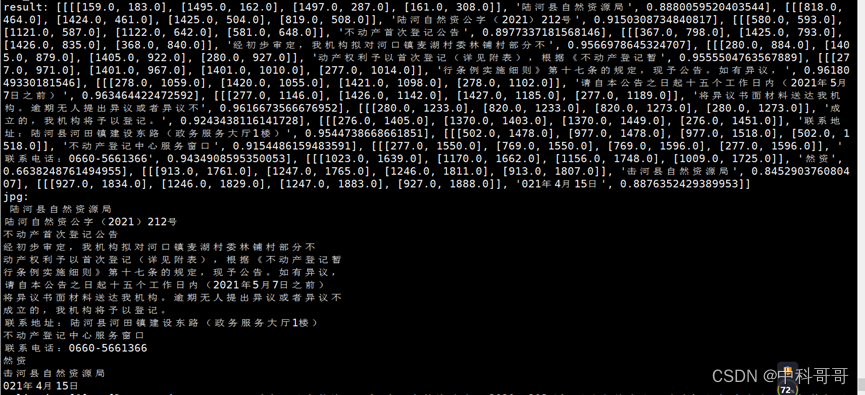
提问结果

- 示例三、英文支持情况

英文检测结果
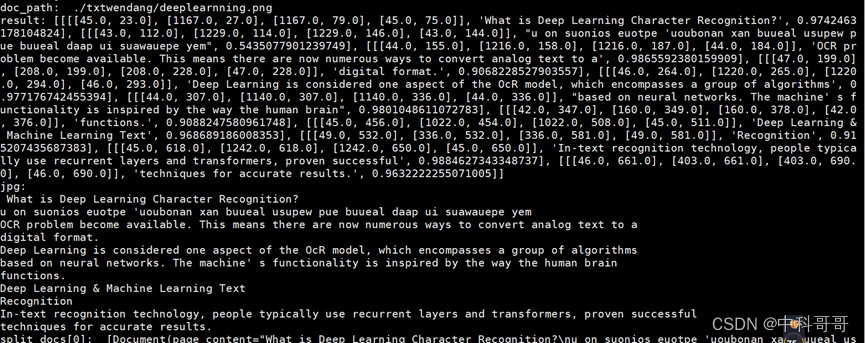
提问回答结果

扩展
OCR + langchain + chatglm3 框架完全支持视频内容文字识别与问答。
图片支持结果示例二(图像内容文本描述—文本提问搜图)
对于图片描述任务,应该尽可能写实,即不需要华丽的语句,只需要陈述图片所展现的事实即可。任务分为两个部分,一是图片编码,二是文本生成,基于此后续的模型也都是encoder-decoder的结构。
中文和英文的语言区别比较大,中文语义更加丰富且灵活多变,而当前针对中文的图像描述生成研究相对较少,大多模型借鉴于英文的IC技术,本次以中文为基础测试研发。
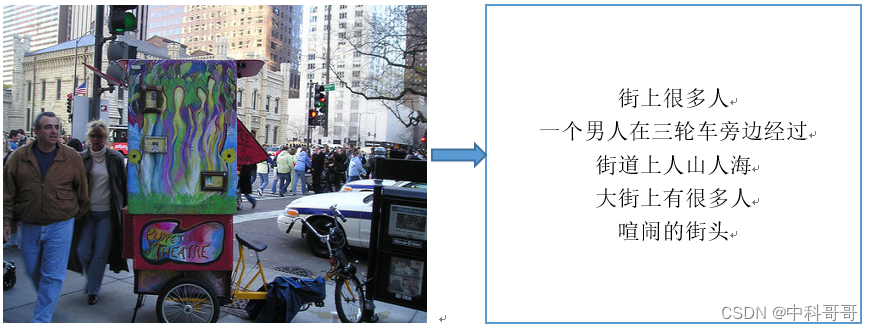
主要任务
1)检测图像中的目标;
2)目标的属性,比如颜色、尺寸等;
3)目标之间的关联;
4)语言模型,用于把上面的信息表述成句子;
Image Caption的实现方法
实现ImageCaption需要以下步骤:
- 数据准备:对原始图像添加标注信息,生成图像-标注对,并将其拆分为训练、验证和测试数据集。
- 模型构建:建立CNN和LSTM网络模型,训练 CNN 来从图像中提取特征,然后使用 LSTM 从这些特征中生成每张图片对应的文本描述。
- 模型训练:对模型进行训练,调整模型的超参数,使其生成更好的图像标注结果。
- 模型评估:使用BLEU、ROUGE等指标来评估模型的性能,并根据评估结果进行进一步的优化
算法选型
Chinese-IC-Baseline 是目前中文图像描述中非常经典的算法框架,Chinese-IC-Baseline 实现了CNN-LSTM-Attention结构,这是图像描述生成方向非常典型的基线模型,因此基于此项目学习基础并展开研究。
Chinese-IC-Baseline + langchain + chatglm3 框架图
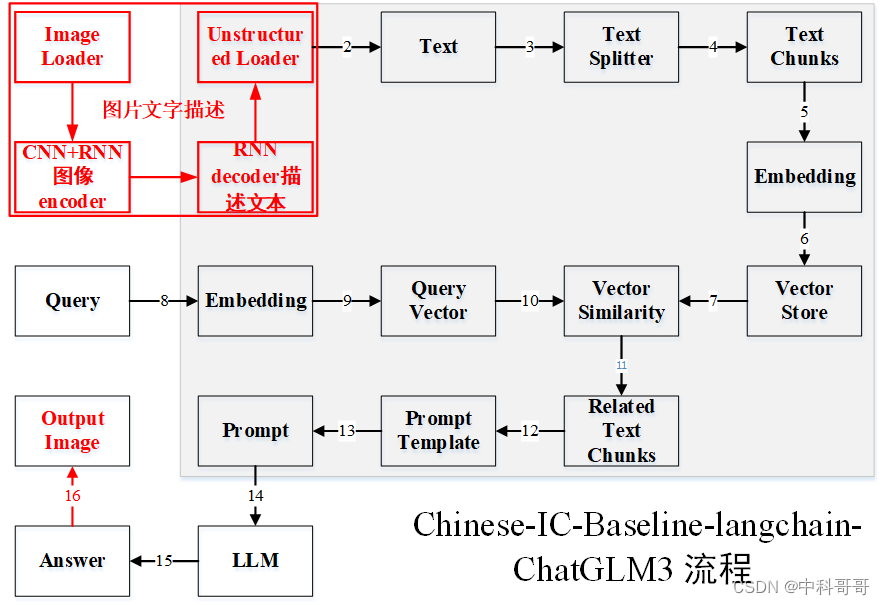
该部分主要流程是图片文字识别算法
- 首先载入图片:如jpg、jpeg、png、tif等;
- 利用CNN 和RNN技术对图片进行encoder操作生成特征;
- 利用RNN技术将特征进行decoder处理,生成图片描述文本;
- 对文本进行非结构化载入,然后接入langchain + chatglm3框架;
- 用户输入需要搜索的描述图片,利用langchain + chatglm3回答提问结果,输出对应图片描述文本,然后关联到对应图像,输出搜索图像,如图中(16)。
图文描述的整体的框架图
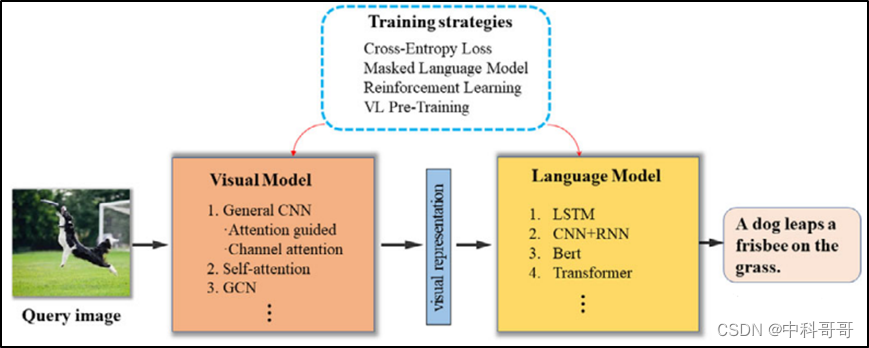
Image Caption算法主要包含两部分:一个用于提取图片信息的Visual Model模型,一个用户提取文本信息的Language Mode模型。Visual Model模型可以由CNN、Transformer、GCN等组成,Lanquage Mode模型可以由LSTM、CNN+RNN、Beat、Transformer等组成。
图文描述难点与关键点
- 任务复杂:
生成自然语言描述需要结合考虑图片的信息,而图片则可能涉及到更加复杂的情境,包括图像中每个像素的颜色、位置。大小以及物体之间的关系等。因此,lmage Caption算法需要在复杂的多元数据中寻找关联性和必要细节。 - 结构变体:
即便是同一类目的图片,其内容也可能非常不同。比如拍摄地点、拍摄时间、光线、角度等的差别都会让一张具有相似场景的图片变得截然不同。这种结构变体的存在,使得生成准确的描述变得更加困难。 - 视觉与语言之间的关联:
由于文本和视觉表示有很大的不同,机器学习算法需要通过学习到的特征来获取两种不同表示之间的联系。因此,图像和文本语言之间的联系不可能只是简单的像素到单词的一一映射,而是一个复杂的和很多层次的关联。 - 数据集大小和精度:
为了训练和评估lmae Caption算法,需要大量的图片和相应的描述数据。然而,这些数据集往往存在噪声、错误或者缺失信息。而这些问题会影响深度学习模型的训练和泛化能力。 - 实时性:
Image Caption任务需要处理大量的视觉和语言信息,因此需要消耗大量的计算资源。因此,对于实时性任务来说,算法的性能和效率是非常重要的挑战。
Chinese-IC-Baseline 图文描述代码源
https://github.com/Lieberk/Chinese-IC-Baseline.git
https://blog.csdn.net/lihuanyu520/article/details/131153219
Chinese-IC-Baseline + langchain + chatglm3 图文问答示例

Image Caption 结果


Image Caption 结果

提问回答结果

提问推荐图片

扩展
Chinese-IC-Baseline + langchain + chatglm3 框架完全支持视频内容图文描述与问答。
技术流程总结图


