
- 1php redis消息订阅与发布_php+redis 实现发布订阅功能
- 2NLP+Diffusion=?UMN最新《NLP中的扩散模型》综述 ,全面阐述离散和嵌入扩散模型方法...
- 3openmv串口数据 串口助手_STM32 串口接收不定长数据 STM32 USART空闲检测中断
- 4Arduino跨平台开发——卡尔曼滤波_卡尔曼 arduino
- 5RabbitMQ核心内容:实战教程(java)_java mq
- 6linux离线手动安装升级gcc_gcc离线安装
- 7Quartus II的基本使用及仿真_quartus仿真
- 8node.js毕业设计更美个人美妆穿搭分享微信小程序(源码+程序+LW+部署)_毕业设计微信小程序美妆类怎么做
- 9error: 'lianxi/' does not have a commit checked out fatal: adding files failed 解决方案
- 10【大语言模型+Lora微调】10条对话微调Qwen-7B-Chat并进行推理 (聊天助手)
机器学习之特征变换-标签和索引的转化_机器学习特征变换
赞
踩
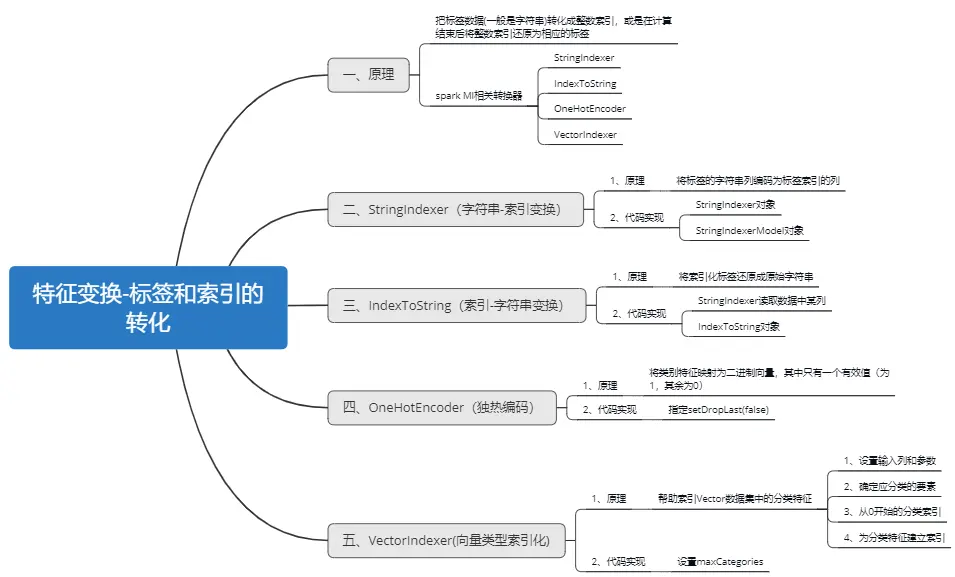
一、原理
在机器学习处理过程中,为了方便相关算法的实现,经常需要把标签数据(一般是字符串)转化成整数索引,或是在计算结束后将整数索引还原为相应的标签.
Spark ML 包中提供了几个相关的转换器:
StringIndexer,IndexToString,OneHotEncoder,VectorIndexer,他们提供了十分方便的特征转换功能,这些转换器都位于org.apache.spark.ml.feature包下。
值得注意的是,用于特征转换的转换器和其他的机器学习算法一样,也属于Ml Pipeline模型的一部分,可以用来构成机器学习流水线,以StringIndexer为例。
StringIndexer(字符串-索引变换)将字符串的标签编码成标签索引。标签索引序列的取值范围是[0,numLabels(字符串中所有出现的单词去掉重复的词后的总和)],按照标签出现频率排序,出现最多的标签索引为0。如果输入是数值型,我们先将数值映射到字符串,再对字符串进行索引化。如果下游的pipeline(例如:Estimator或者Transformer)需要用到索引化后的标签序列,则需要将这个pipeline的输入列名字指定为索引化序列的名字。大部分情况下,通过setInputCol设置输入的列名。
下面来具体介绍StringIndexer、IndexToString、OneHotEncoder、VectorIndexer。
二、StringIndexer(字符串-索引变换)
2.1、原理
StringIndexer将标签的字符串列编码为标签索引的列。 索引位于[0,numLabels)中,并支持四个排序选项:“frequencyDesc”:按标签频率的降序(最频繁的标签分配为0),“frequencyAsc”:按标签频率的升序(最不频繁的标签分配为0) ,“alphabetDesc”:降序字母顺序和“alphabetAsc”:升序字母顺序(默认=“frequencyDesc”)。 如果用户选择保留,则看不见的标签将放置在索引numLabels处。 如果输入列为数字,则将其强制转换为字符串并为字符串值编制索引。 当下游管道组件(例如Estimator或Transformer)使用此字符串索引标签时,必须将组件的输入列设置为此字符串索引列名称。 在许多情况下,可以使用setInputCol设置输入列。
2.2、代码实现
首先引入需要用的包:
import java.util.Arrays; import java.util.List; import org.apache.spark.ml.feature.IndexToString; import org.apache.spark.ml.feature.OneHotEncoderEstimator; import org.apache.spark.ml.feature.StringIndexer; import org.apache.spark.ml.feature.StringIndexerModel; import org.apache.spark.ml.feature.VectorIndexer; import org.apache.spark.ml.feature.VectorIndexerModel; import org.apache.spark.ml.linalg.VectorUDT; import org.apache.spark.ml.linalg.Vectors; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.RowFactory; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.Metadata; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; import scala.collection.immutable.Set;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
获取spark:
SparkSession spark = SparkSession.builder().appName("StringIndexerTest").master("local").getOrCreate();
- 1
构造一些简单数据:
List<Row> rowRDD = Arrays.asList(RowFactory.create(0,"a"),
RowFactory.create(1,"b"),
RowFactory.create(2,"c"),
RowFactory.create(3,"a"),
RowFactory.create(4,"a"),
RowFactory.create(5,"c"));
StructType schema = new StructType(new StructField[] {
new StructField("id",DataTypes.IntegerType,false,Metadata.empty()),
new StructField("category",DataTypes.StringType,false,Metadata.empty())
});
Dataset<Row> df = spark.createDataFrame(rowRDD, schema);
df.show(false);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出结果:
+---+--------+
|id |category|
+---+--------+
|0 |a |
|1 |b |
|2 |c |
|3 |a |
|4 |a |
|5 |c |
+---+--------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
然后构建StringIndexer模型,我们创建一个StringIndexer对象,设定输入输出列名,其余参数采用默认值,并对这个DataFrame进行训练,产生StringIndexerModel对象:
StringIndexer indexer = new StringIndexer().setInputCol("category").setOutputCol("categoryIndex");
StringIndexerModel model = indexer.fit(df);
- 1
- 2
之后我们即可利用StringIndexerModel对象对DataFrame数据进行转换操作,可以看到,默认情况下,StringIndexerModel依次按照出现频率的高低,把字符标签进行了排序,即出现最多的“a”被编号成0,“c”为1,出现最少的“b”为0。
Dataset<Row> indexed1 = model.transform(df);
indexed1.show(false);
- 1
- 2
输出结果:
+---+--------+-------------+
|id |category|categoryIndex|
+---+--------+-------------+
|0 |a |0.0 |
|1 |b |2.0 |
|2 |c |1.0 |
|3 |a |0.0 |
|4 |a |0.0 |
|5 |c |1.0 |
+---+--------+-------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
如果我们使用已有的数据构建了一个StringIndexerModel,然后再构建一个新的DataFrame,这个DataFrame中有着模型内未曾出现的标签“d”,用已有的模型去转换这一DataFrame会有什么效果?
实际上,如果直接转换的话,Spark会抛出异常,报出“Unseen label: d”的错误。
为了处理这种情况,在模型训练后,可以通过设置setHandleInvalid("skip")来忽略掉那些未出现的标签,这样,带有未出现标签的行将直接被过滤掉,所下所示:
List<Row> rowRDD2 = Arrays.asList(RowFactory.create(0,"a"),
RowFactory.create(1,"b"),
RowFactory.create(2,"c"),
RowFactory.create(3,"a"),
RowFactory.create(4,"a"),
RowFactory.create(5,"d"));
Dataset<Row> df2 = spark.createDataFrame(rowRDD2, schema);
Dataset<Row> indexed2 = model.transform(df2);
indexed2.show(false);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出结果:
Unseen label: d.
- 1
Dataset<Row> indexed2 = model.setHandleInvalid("skip").transform(df2);
indexed2.show(false);
- 1
- 2
输出结果:
+---+--------+-------------+
|id |category|categoryIndex|
+---+--------+-------------+
|0 |a |0.0 |
|1 |b |2.0 |
|2 |c |1.0 |
|3 |a |0.0 |
|4 |a |0.0 |
+---+--------+-------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
三、IndexToString(索引-字符串变换)
3.1、原理
与StringIndexer对应,IndexToString将索引化标签还原成原始字符串。一个常用的场景是先通过StringIndexer产生索引化标签,然后使用索引化标签进行训练,最后再对预测结果使用IndexToString来获取其原始的标签字符串。
3.2、代码实现
首先我们用StringIndexer读取数据集中的“category”列,把字符型标签转化成标签索引,然后输出到“categoryIndex”列上,构建出一个新的DataFrame数据集
List<Row> rawData = Arrays.asList(RowFactory.create(0, "a"),
RowFactory.create(1, "b"),
RowFactory.create(2, "c"),
RowFactory.create(3, "a"),
RowFactory.create(4, "a"),
RowFactory.create(5, "c"));
Dataset<Row> df3 = spark.createDataFrame(rawData, schema);
Dataset<Row> indexed3 = indexer.fit(df3).transform(df3);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
然后我们创建IndexToString对象,读取“categoryIndex”上的标签索引,获得原有数据集的字符型标签,然后再输出到“originalCategory”列上。最后,通过输出“originalCategory”列,就可以看到数据集中原有的字符标签了。
IndexToString converter = new IndexToString().setInputCol("categoryIndex").setOutputCol("originalCategory");
Dataset<Row> converted3 = converter.transform(indexed3);
converted3.show(false);
- 1
- 2
- 3
输出结果:
+---+--------+-------------+----------------+
|id |category|categoryIndex|originalCategory|
+---+--------+-------------+----------------+
|0 |a |0.0 |a |
|1 |b |2.0 |b |
|2 |c |1.0 |c |
|3 |a |0.0 |a |
|4 |a |0.0 |a |
|5 |c |1.0 |c |
+---+--------+-------------+----------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
四、OneHotEncoder(独热编码)
4.1、原理
独热编码(One-hot encoding)将类别特征映射为二进制向量,其中只有一个有效值(为1,其余为0)。这样在诸如Logistic回归这样需要连续数值值作为特征输入的分类器中也可以使用类别(离散)特征。
One-Hot编码适合一些期望类别特征为连续特征的算法,比如说逻辑斯蒂回归等。
4.2、代码实现
首先创建一个DataFrame,其包含一列类别性特征,需要注意的是,在使用OneHotEncoder进行转换前,DataFrame需要先使用StringIndexer将原始标签数值化
List<Row> rawData4 = Arrays.asList(RowFactory.create(0.0, 1.0),
RowFactory.create(1.0, 0.0),
RowFactory.create(2.0, 1.0),
RowFactory.create(0.0, 2.0),
RowFactory.create(0.0, 1.0),
RowFactory.create(2.0, 0.0));
StructType schema4 = new StructType(new StructField[] {
new StructField("id",DataTypes.DoubleType,false,Metadata.empty()),
new StructField("category",DataTypes.DoubleType,false,Metadata.empty())
});
Dataset<Row> df4 = spark.createDataFrame(rawData4, schema4);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我们创建OneHotEncoder对象对处理后的DataFrame进行编码,可以看见,编码后的二进制特征呈稀疏向量形式,与StringIndexer编码的顺序相同,需注意的是最后一个Category(”b”)被编码为全0向量,若希望”b”也占有一个二进制特征,则可在创建OneHotEncoder时指定setDropLast(false)。
OneHotEncoderEstimator encoder = new OneHotEncoderEstimator()
.setInputCols(new String[] {"id","category"})
.setOutputCols(new String[] {"categoryVec1","categoryVec2"});
Dataset<Row> encoded4 = encoder.fit(df4).transform(df4);
encoded4.show(false);
- 1
- 2
- 3
- 4
- 5
输出结果:
+---+--------+-------------+-------------+
|id |category|categoryVec1 |categoryVec2 |
+---+--------+-------------+-------------+
|0.0|1.0 |(2,[0],[1.0])|(2,[1],[1.0])|
|1.0|0.0 |(2,[1],[1.0])|(2,[0],[1.0])|
|2.0|1.0 |(2,[],[]) |(2,[1],[1.0])|
|0.0|2.0 |(2,[0],[1.0])|(2,[],[]) |
|0.0|1.0 |(2,[0],[1.0])|(2,[1],[1.0])|
|2.0|0.0 |(2,[],[]) |(2,[0],[1.0])|
+---+--------+-------------+-------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
五、VectorIndexer(向量类型索引化)
5.1、原理
VectorIndexer帮助索引Vector数据集中的分类特征。 它既可以自动确定哪些特征是分类的,又可以将原始值转换为分类索引。 具体来说,它执行以下操作:
1、设置类型为Vector的输入列和参数maxCategories。
2、根据不同值的数量确定应分类的要素,其中最多具有maxCategories的要素被声明为分类。
3、为每个分类特征计算从0开始的分类索引。
4、为分类特征建立索引,并将原始特征值转换为索引。
索引分类特征允许诸如决策树和树组合之类的算法适当地处理分类特征,从而提高性能。
5.2、代码实现
首先,我们读入一个数据集DataFrame,然后使用VectorIndexer训练出模型,来决定哪些特征需要被作为类别特征,将类别特征转换为索引,这里设置maxCategories为2,即只有种类小于2的特征才被认为是类别型特征,否则被认为是连续型特征:
List rawData5 = Arrays.asList(RowFactory.create(Vectors.dense(-1.0, 1.0, 1.0)),
RowFactory.create(Vectors.dense(-1.0, 3.0, 1.0)),
RowFactory.create(Vectors.dense(0.0, 5.0, 1.0)));
StructType schema5 = new StructType(new StructField[] {
new StructField(“features”,new VectorUDT(),false,Metadata.empty())
});
Dataset df5 = spark.createDataFrame(rawData5, schema5);
df5.show(false);
VectorIndexerModel indexModel = new VectorIndexer()
.setInputCol(“features”)
.setOutputCol(“indexed”)
.setMaxCategories(2).fit(df5);
Set categoricalFeatures = indexModel.categoryMaps().keySet();
System.out.println(categoricalFeatures.mkString(“,”));
输出结果:
0,2
- 1
Dataset<Row> indexed5 = indexModel.transform(df5);
indexed5.show(false);
- 1
- 2
输出结果:
+--------------+-------------+
|features |indexed |
+--------------+-------------+
|[-1.0,1.0,1.0]|[1.0,1.0,0.0]|
|[-1.0,3.0,1.0]|[1.0,3.0,0.0]|
|[0.0,5.0,1.0] |[0.0,5.0,0.0]|
+--------------+-------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7


