- 1阿里云Nodejs SDK——子设备接入物联网平台_const iot = require('./utils/aliyun-iot-sdk.js');
- 2保护IP地址不被窃取的几种方法_黑客是怎么防止别人查自己的ip地址的
- 3搜索回溯算法—全排列(leetcode 46)_怎么用搜索和回溯做全排列
- 4DA FMC子卡设计资料yuanlit:FMCJ456-基于JESD204B的2路3GspsAD 2路3Gsps DA FMC子卡_adda 板卡 详细 设计 文档
- 5Git 原理详解及实用指南_git原理
- 6鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:Navigation)_鸿蒙navpathstack
- 7重磅!测试人收入情况大曝光!你的收入在什么水平?
- 8基于SpringBoot的在线考试管理系统_相比于国内,国外的线上管理系统建设比较早,在上世纪就已经很先进,但受七十年代的
- 9idea 如何将本地新建项目上传到gitlab_idea将本地项目上传到gitlab下
- 10Yolov5如何训练自定义的数据集,以及使用GPU训练,涵盖报错解决_yolov5指定使用gpu训练
基于检索的自然语言处理模型研究梳理
赞
踩
© 作者|张北辰
研究方向 | 自然语言处理
导读
大规模预训练模型可以隐式的编码知识并应用于下游任务,为开放域问答、对话、摘要等任务带来了巨大的性能提升。然而不断扩大语言模型参数量以及训练数据规模也可能带来如下问题:
低效。模型规模数量级增大带来的性能增益可能越来越小。
静态。预训练模型编码隐式知识的方式难以对具有时效性的知识进行调整。
不透明。研究者很难判断模型本身掌握了什么知识,在完成任务时用到了哪些知识。在很多下游任务中,语言模型可能会产生事实幻觉(Fact hallucination)。
为了解决上述问题,研究者们提出了改进任务表现的另一种思路:基于检索的自然语言模型。这类模型可以在外部知识库中搜索所需信息,结合外部知识以及语言模型的本身优势完成任务。
本文整理了基于检索的自然语言模型及其下游应用的部分研究进展,欢迎大家批评和交流。
Generalization through memorization: Nearest neighbor language models [ICLR 2020]
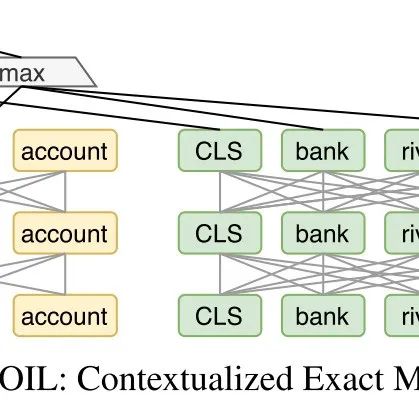
这篇论文提出了一种将 kNN 最近邻模型与语言模型预测分布相结合的方法,NN-LM。该方法可以有效提高预训练语言模型对例如事实知识等稀有文本形式的建模能力。
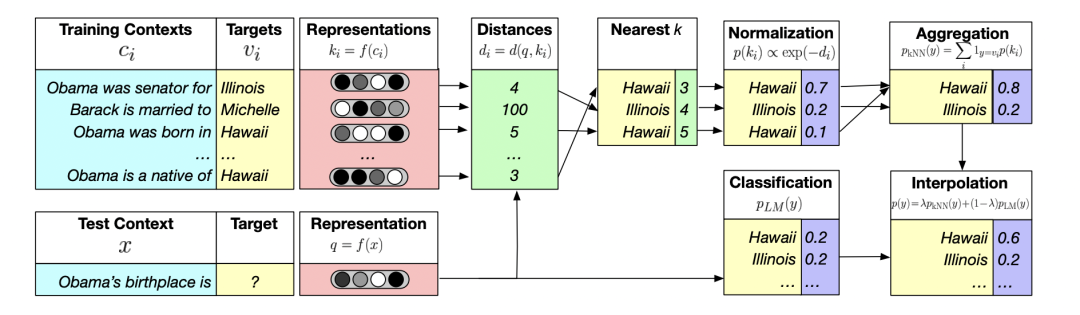
基于训练集 建立数据库,其中键为词预训练权重,值为目标词。在给定上下文 预测当前目标词 时,从数据库中找到的 的 个最近邻词,并将具有相同目标词的概率进行聚合,得到分布 ,将该分布与语言模型分布结合得到最终的预测目标词概率分布。
文章指出,最能体现 NN-LM 改进的样本通常包含稀有模式,包括事实性知识、名字以及与训练集重叠较多的句子。在这些例子中,将训练样本和测试样本映射到相似的表示似乎比隐式记忆下一个句子更容易。
REALM: Retrieval-Augmented Language Model Pre-Training [ICML 2020]
这篇论文在语言模型预训练阶段中引入了一个知识检索模型。相比于不能在下游任务中微调的 NN-LM,REALM 能够在预训练、微调和推理阶段显式利用大型语料库中的知识。
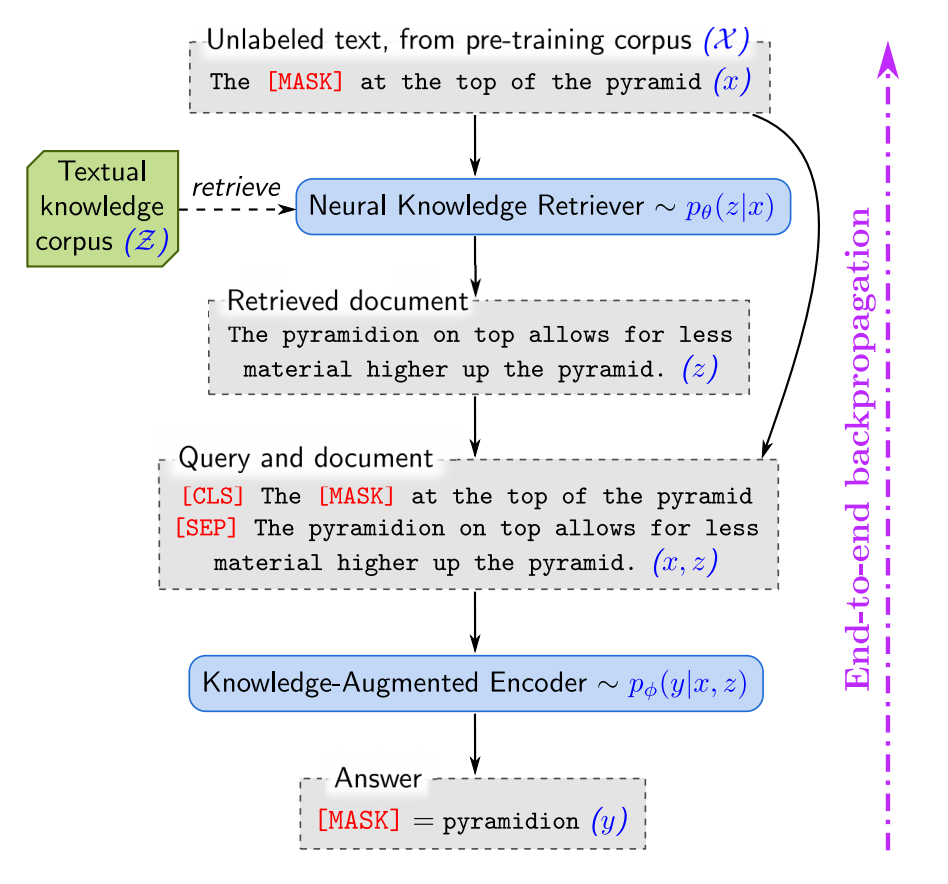
REALM 将模型输出分布 分解为检索、预测两个步骤:
给定输入 ,从知识库中检索可能对模型有帮助的文档集合 。文章将这个过程建模为
依据检索结果 和输入 生成输出 ,建模为 ,将 视为隐变量,将目标 建模为对于所有可能有用的文档集合 的边缘概率分布:
402 Payment Required
模型包括知识检索器和知识增强编码器:
知识检索器将 建模为输入 和文档 内积的归一化指数函数。该论文从反向传播公式的角度出发,证明了检索模型的训练能够更好的完成最终任务目标。
知识增强编码器将输入 和文档 拼接输入到 Transformer 编码器中。预训练任务采用 masked language modeling (MLM),开放域问答任务中采用了预测 span 的训练方式。
在具体实现中,该工作用可能性最高的 个文档的概率来近似 ,从而实现对检索器的反向传播。由于参数更新,对整个知识库进行重新编码计算量巨大。因此作者在预训练阶段选择每隔若干训练步刷新知识库索引。
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks [NeurIPS 2020]
这项工作引入文档检索器和外部知识库来增强生成式语言模型在知识密集任务中表现。相比于 REALM 使用抽取式的方法完成下游任务,RAG 将检索技术用于生成式语言模型,形式更灵活,适用范围更广。
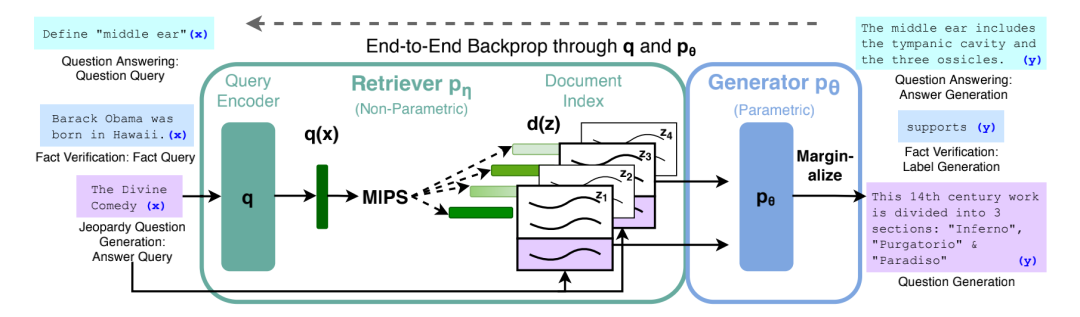
RAG 模型框架包括检索器 和生成器 两部分。检索器在给定输入 的条件下返回 top-K 文档分布,生成器基于上下文 token、原始输入 和一篇检索文档 生成当前 token。
文章提出了两种对隐文档进行边缘化的方法来端到端地训练模型。
RAG-Sequence Model 与 REALM 的思路比较相似,使用相同的文档来生成整个目标序列。将单个检索文档作为单一隐变量进行边缘化,并做 top-K 近似。
402 Payment Required
RAG-Token Model 在生成每个 token 时使用不同的检索文档进行边缘化,使得模型在生成一个答案时可以参考不同的检索文档。
相比于直接从知识库中检索答案,生成答案有一定优势。只包含答案线索而不包含正确答案的检索样本仍然有助于生成答案,使得模型能够更有效地训练;即使正确答案不包含在任何检索样本中,RAG 仍可能生成正确答案。
Dense Passage Retrieval for Open-Domain Question Answering [ACL 2020]
这篇论文提出一种不进行额外预训练的稠密检索方法完成开放域问答任务。相比于基于反向填空任务 ICT 来进行额外预训练的 ORQA,DPR 只使用问题答案对训练检索器。
DPR 模型架构为双塔 BERT 模型,以最大化问题和相关文档表示的内积为目标进行优化。在负例选取方面,DPR 采用训练集中其它问题对应的正例作为当前问题的负例,并具体实现中使用 batch 内负例进行训练,这样可以利用矩阵乘法加快训练过程。
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering [EACL 2021]
这项工作提出了一种文档利用文档检索结合生成式语言模型完成开放域问答任务的方法。以往的生成式问答需要参数量较大的生成式语言模型,而 FiD 借助检索外部知识来提高生成式问答的性能。

FiD 采用先检索后生成的范式。检索器基于 BM25 或 DPR;生成器将问题与各检索文档拼接后分别编码后拼接,解码器对拼接后的表示进行 cross attention,各检索文档信息在解码器部分融合。
具体实验中,当检索文档数量增多时,模型性能显著提升,这表明生成式语言模型能够很好地将多个文档检索结果融合。
Adaptive Semiparametric Language Models [TACL 2021]
这篇论文提出了一种将参数化神经网络与非参数化外部记忆模块结合的语言模型。与 kNN-LM 的不同是,SPALM 通过门控机制对检索片段进行后处理,将检索样本加入了训练过程。
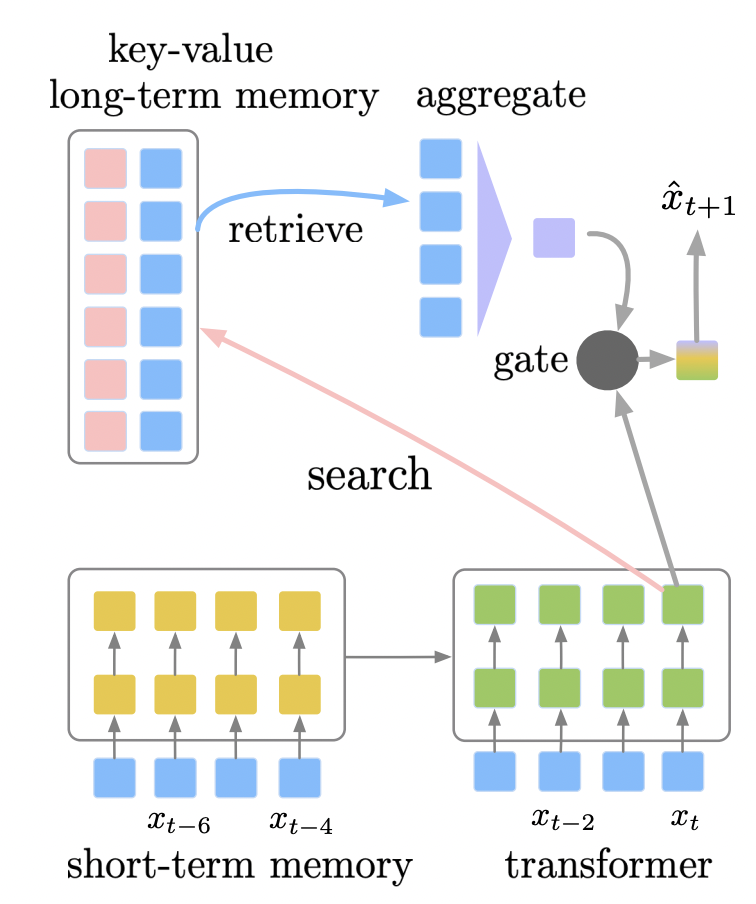
模型架构包括两部分。对于短期记忆,基于 Transformer-XL,将扩展上下文编码成隐状态进行缓存;对于长期记忆,使用永久数据库,并基于稀疏检索最近邻方法对数据进行检索。除此之外,文章设计了一种上下文依赖的门控机制来结合局部、扩展和全局信息。
End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering [NeurIPS 2021]
这篇论文提出了一种端到端的结合多个检索文档信息的开放域问答方法。
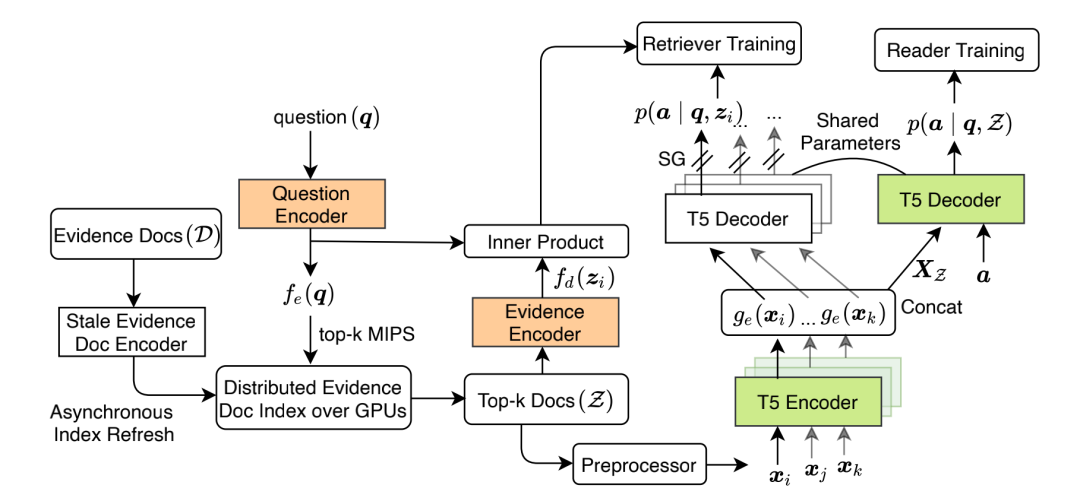
EMDR 的模型结构包括检索器、阅读器两部分。检索器是经典的双塔 BERT 模型,使用无监督训练过程进行初始化;阅读器基于 FiD 模型。
端到端训练方法中,与 REALM 将单个检索文档作为隐变量不同,本文将检索文档集合作为隐变量 , 是 的可能取值,则答案的边缘似然是
402 Payment Required
,训练目标是找到使得上述似然函数最大化的 和 。文章采用 EM 算法来学习隐变量模型,给定所有观察变量,迭代计算 的后验来更新参数,使用 和 两种估计来更新两个模块的参数:阅读器参数 。利用 top-K 文档集合及其对应分数来构造 ,这等价于用先验 来估计 。
检索器参数 。文章基于后验估计,使用答案 的额外信息来评估 ,从而更新 。文章假设检索文档集合中每个文档的概率之和最大化与集合概率最大化等价,将 转换为 ,再进一步基于贝叶斯定理转换。
最终的训练目标如下,优化过程采用 EM 算法迭代求解,其中 为停止梯度操作符:
Internet-Augmented Dialogue Generation [arXiv:2107]
这项研究将互联网作为外部知识库,并通过实时搜索来增强对话生成,使对话系统能够聚合更多的常识,并将其反映在对话中。

具体方法由两个部分组成,一是搜索查询生成器,二是基于 FiD 的编码器-解码器模型。搜索查询生成器是一个编码器-解码器模型,将对话环境作为输入,并生成一个搜索查询,随后在互联网中检索相关文档。FiD 式模型对每个文档进行单独编码,并将其与对话环境编码拼接,最后用解码器生成目标序列。
Improving Language Models by Retrieving from Trillions of Tokens [arXiv:2112]
这项工作提出了一种从大规模语料库中检索文档块用于增强自回归模型的方法。相较于之前检索增强生成的方法,该论文使用了超大规模的检索语料库,表明了检索语料库规模的可扩展性。
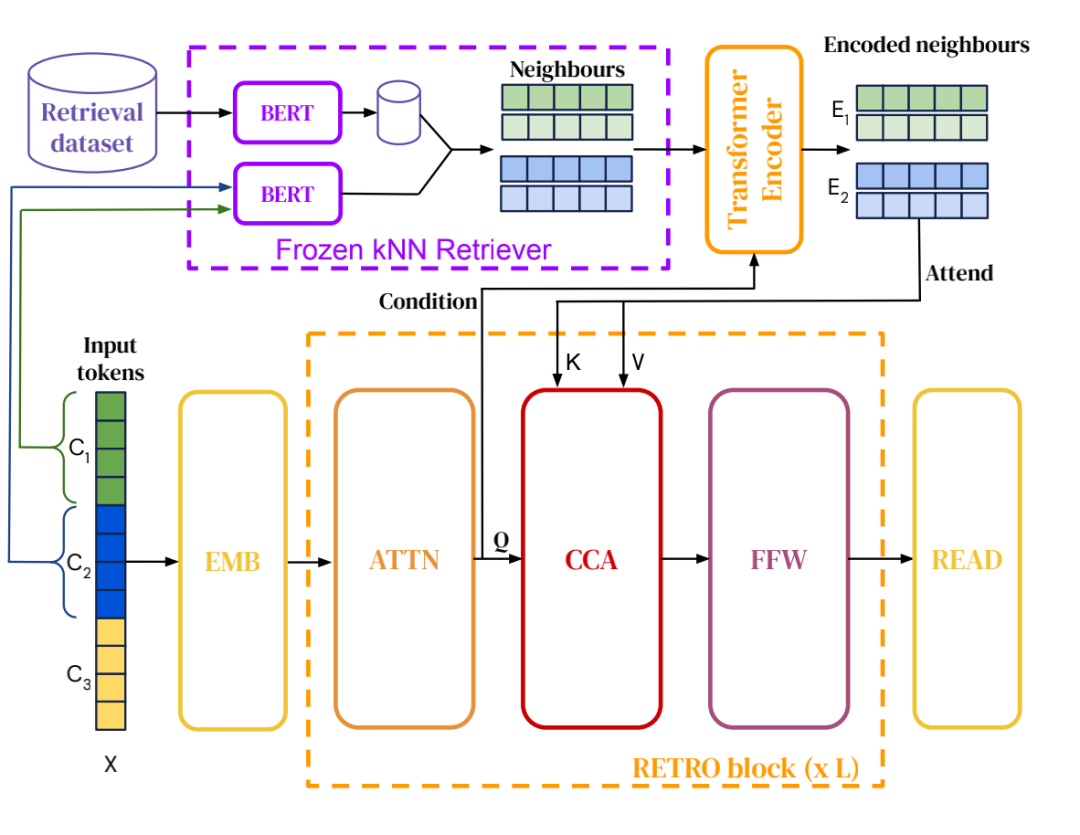
首先,RETRO 建立了用于检索的数据库,其键为 BERT 编码表示,值为对应的文档块以及该文档块的下一个文档块。RETRO 的模型架构包含检索器,编码器以及带有块注意力(Chunked cross attention, CCA)模块的解码器。模型将输入也分为若干固定大小的块,基于已经生成的上下文及上下文分块检索到的文档块生成当前目标词。
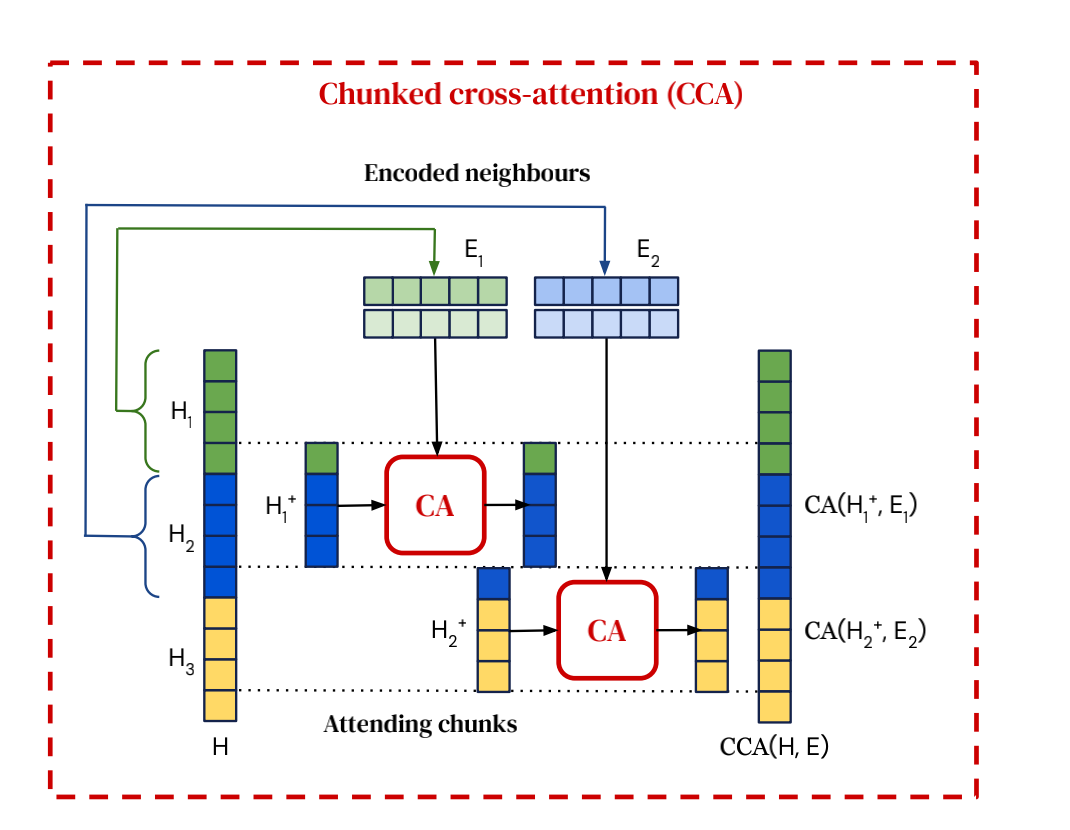
检索器基于固定的 BERT 预训练模型,给定查询块,在数据库中搜索最近邻,输出检索到的文档块及后续文档块。
编码器负责编码检索文档块。其中检索文档块的编码过程会对输入文档块表示进行 cross attention,使得检索文档块的编码能够以可导的方式进行优化。
解码器是类似于 GPT 的自回归模型,负责编码输入文档块,输出生成结果。其模型结构包含常规的 Transformer 解码模块和 CCA 解码模块。CCA 模块与正常 cross attention 模块的不同在于键为 的最后一个 token 到 的头 个 token,其中 是检索文档块对应的原始文档块,这样的设计可以有效减低 cross attention 的计算复杂度。
实验证明,相较于增大模型参数量,增大检索语料库同样可以有效提升模型性能,使得较小规模模型的性能与大规模模型相当。
小结
以上论文从端到端训练方式、外部数据使用方式、下游任务适配等角度对基于检索的自然语言模型展开研究。相较于扩大模型规模的涨点方式,这类模型可以通过扩展数据库规模和更新数据库的方式来解决模型复杂度和知识更新的问题,显式的检索文档集合也让模型输出的依据更加透明。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

- END -