
- 1计算机网络地址怎么办,电脑ip地址错误怎么办 电脑ip地地址错误解决方法
- 2一文搞清楚LoRa网关,LoRa网关全知道_lora基站与lora传感器必须用用同一个品牌嘛
- 3STM32信息安全 1.1 课程架构介绍:信息安全特性概览
- 4Git远程仓库使用方法_git pull 指定仓库
- 5mysql知识点整理
- 6Git常用命令_git移除远程仓库链接
- 7大数据毕业设计:python校园舆情分析系统 可视化 情感分析 朴素贝叶斯分类算法 爬虫(源码)_python对情感分评分进行可视化
- 8机器学习初探之感知机_感知机在机器学习中的应用领域及重要性
- 9RocketMQ与Kafka架构深度对比_rocketmq和kafka
- 10namenode格式化_大数据系列~HDFS_NameNode工作原理
spark和scala环境安装与部署(超详细版),我保证你敢看,你就学会了_掌握scala的安装配置 掌握spark分布式环境的搭建
赞
踩
一.SPARK简介
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
二.spark搭建准备
-
JDK1.8
-
Hadoop安装
版本:2.7.7
参考:https://blog.csdn.net/tangyi2008/article/details/121908766
-
虚拟机完全分布式加hive
三.scala与spark搭建与安装
1)scala下载安装
首先从Scala官网链接:The Scala Programming Language (scala-lang.org)下载scala安装包
all releases 是选择历史版本
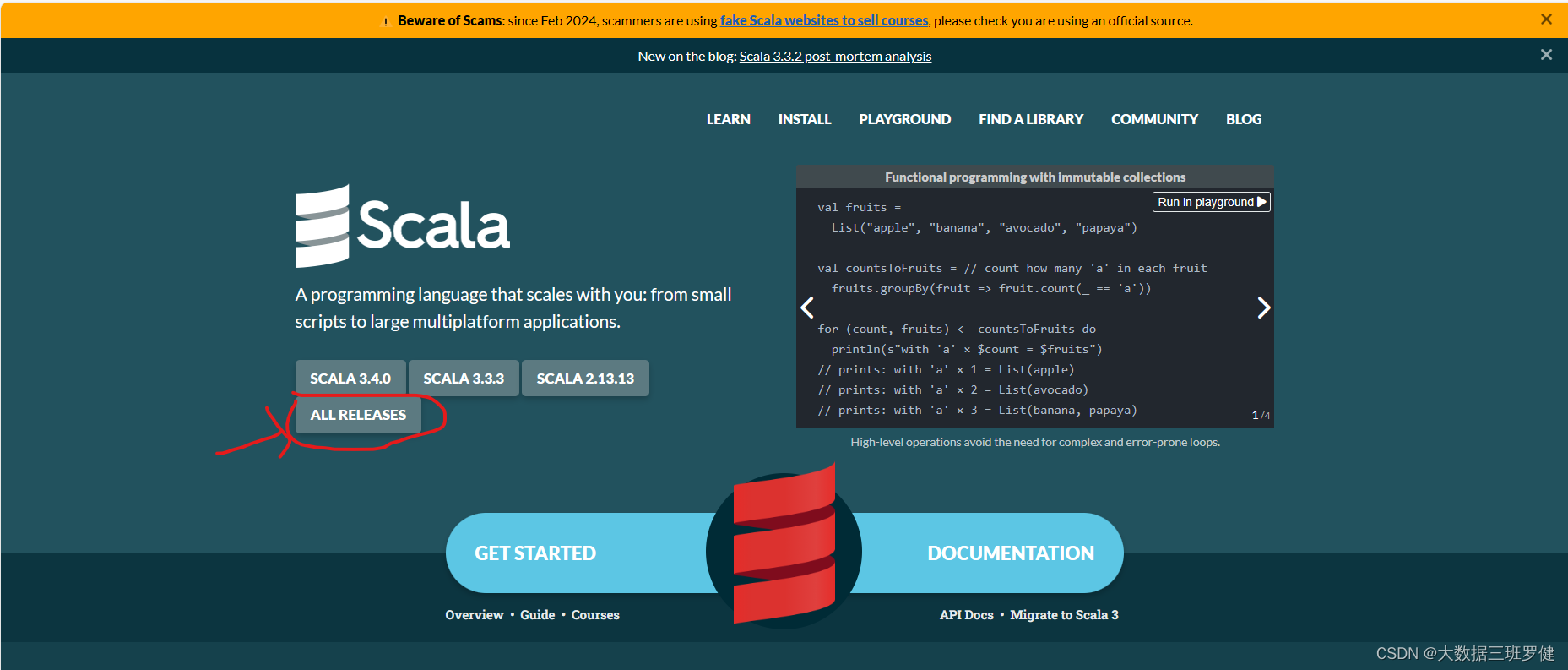
在这里选择scala2.12.12版本

如果我们要给虚拟机安装就选择tgz后缀的安装包,如果要给windows安装就选择msi安装包的后缀
我们这边就演示虚拟机的所以我们下载Linux版本。
附上Linux版本的下载链接:https://downloads.lightbend.com/scala/2.12.12/scala-2.12.12.tgz

2)前往spark下载安装包
首先进入官网,官网链接:Apache Spark™ - Unified Engine for large-scale data analytics
下载spark安装包,然后进入download

可以在下载页面的下方进入它的release archives:https://archive.apache.org/dist/spark/ 选择想要的版本。

这里以3.1.1版本为例,我们下载的安装文件应该是形如:spark-3.1.1-bin-xxxxxx.tgz的文件,很多人很困惑如何选择这些版本。

之所以会有这么多版本的选择,是因为Spark需要一些Hadoop客户端的依赖包(需要访问HDFS和YARN), 这些版本主要分为两类:
pre-packaged binary,将Hadoop客户端的依赖包编译到所下载的压缩包当中,比如spark-2.4.8-bin-hadoop2.6.tgz 和spark-2.4.8-bin-hadoop2.7.tgz ,
“Hadoop free” binary,需要自己通过配置 SPARK_DIST_CLASSPATH 变量,以便可以包含指定版本的Hadoop的相关jar包,比如:spark-3.1.1-bin-without-hadoop-scala-2.12.tgz、spark-2.4.8-bin-without-hadoop.tgz 。
我们这里选择“Hadoop free” binary形式的spark-3.1.1-bin-without-hadoop.tgz进行下载,直接使用浏览器下载过慢,可以使用迅雷加速下载,也可以去后面的网盘资源进行下载
3)上传安装包至虚拟机
我们如果是图形化界面可以进行直接拖拽,如果是mini版本的我们就需要xshell和xftp进行上传,我们这边是mini版本的我们就进行上传
我们用ifconfig命令查看我们主机的ip地址

打开xshell在文件新建中创建一个连接
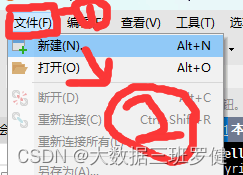
然后在主机里输入我们刚刚查到的ip
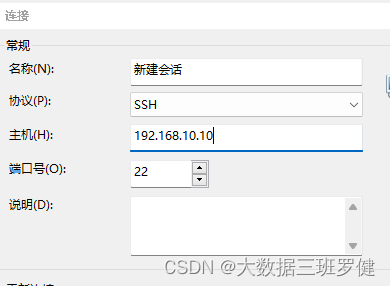
之后我们点击用户身份验证在这里输入我们的用户名和密码即可连接

连接成功后我们选择xftp进行传输

把我们刚刚下载的安装包拖拽到虚拟机中,这里我推荐到opt目录里

3)进行scala的安装配置
解压安装包 tar -zxvf /opt/scala-2.12.12.tgz -C /opt/


配置scala环境变量
vim /etc/profile
#SCALA
export SCALA_HOME=/opt/scala-2.12.12
export PATH=$PATH:${SCALA_HOME}/bin
图中SCALA_HOME是Scala的安装路径
![]()
然后source /etc/profile使环境变量生效,接着scala -version查看是否安装成功,出现画线版本号即为成功

4)进行spark安装配置
解压安装spark安装包
tar -zxvf / export/ software/ spark-3.1.1-bin-hadoop3.2.tgz
spark-1.1-bin-hadoop3.2文件名字太长,改名字为spark方便后续操作
mv spark-1.1-bin-hadoop3.2 spark

.配置环境变量 vim /etc/profile
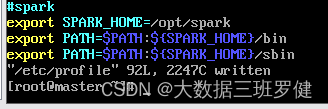
#SPARK
export SPARK_HOME=/opt/spark
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin
这里 SPARK_HOME是spark的安装路径
.source /etc/profile使环境生效
修改配置文件 进入spark里的conf目录备份文件
cd /opt/spark/conf
cp spark-env.sh.template spark-env.sh
![]()
修改配置文件 在spark下的conf目录打开env vim spark-env.sh
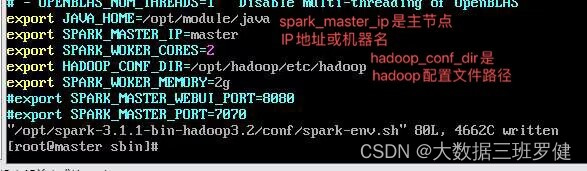
export SCALA_HOME=/opt/scala-2.12.12
export JAVA_HOME=/opt/module/java
export SPARK_MASTER_IP=master
export SPARK_WOKER_CORES=2
export SPARK_WOKER_MEMORY=2g
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
#export SPARK_MASTER_WEBUI_PORT=8080
#export SPARK_MASTER_PORT=7070
修改从节点ip
vi slaves 修改内容为slave1 slave2(我的子机分别为是slave1 slave2

(4)分发文件
scp -r /opt/spark / slave1:/opt/
scp -r /opt/spark/ slave2:/opt/


分别在slave1 slave2上设置环境变量
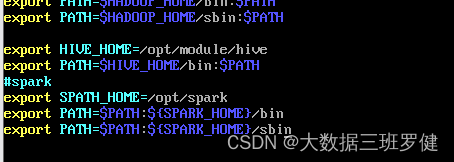
#SPARK
export SPARK_HOME=/opt/spark
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin
source /etc/profile使环境变量生效
启动集群:spark下sbin目录下:./start-all.sh 查看节点状态 在主节点master上出现Master 在s1上出现Worker在s2上出现Worker
master:
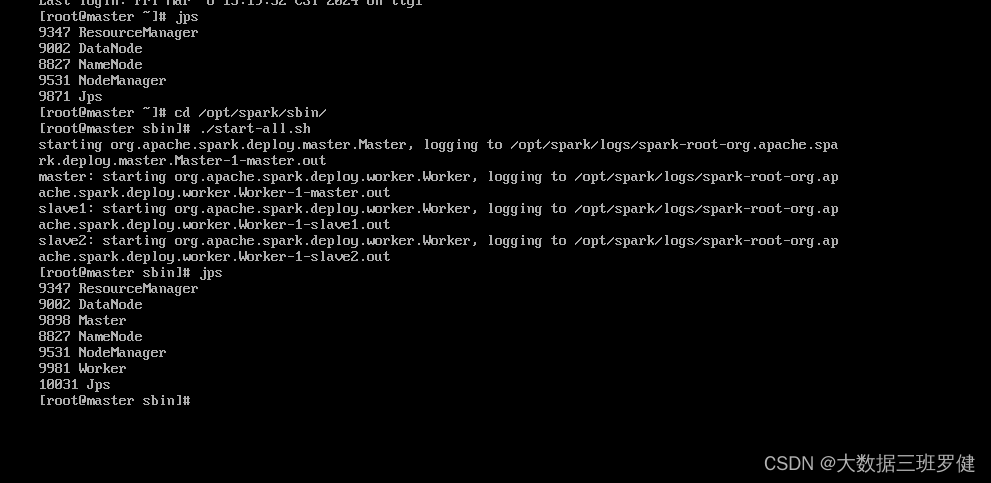
slave1

slave2

查看spark是否安装成功 返回主目录下输入Spark-shell



