
- 1腾讯健康推出多款AI产品:大模型、智能问答、数智医疗影像_腾讯“云深”(idrug)平台
- 2Web开发常见问题汇总_提关于web开发基础的问题
- 3自学黑客(网络安全)
- 4【目标检测】YOLO+DOTA:小目标检测策略_dota目标检测
- 5HTML 总结
- 6zookeeper is not a recognized option解决方案_z is not a recog
- 7Linux上安装matlab_matlab linux
- 8Android报错:have you declared this activity in your AndroidManifest.xml?
- 9强人工智能与物流行业:提高效率与降低成本
- 10Redis部署方式(一)四种部署方式介绍_redis 部署
Redis搭建分片集群_redis分片集群
赞
踩
一、什么是Redis分片集群
1、概念
Redis分片集群是用于将Redis的数据分布在多个Redis节点上的分布式系统。通过分片集群,可以将数据分成多个部分,并将每个部分存储在不同的节点上,以便实现Redis的高可用性和高性能。
2、Redis分片集群原理
Redis分片集群原理是将数据分成多个部分,并将每个部分存储在不同的节点上。这样可以实现Redis的高可用性和高性能。Redis分片集群采用一种称为“哈希分片”的方法来将数据分配到不同的节点上。具体来说,哈希分片使用一个称为键的字符串作为输入,并根据键的哈希值来确定该键所属的节点。这样可以保证相同键的请求始终路由到同一个节点上,从而实现数据的分区和负载均衡。
在Redis分片集群中,节点之间会互相通信,以便实现数据的一致性和高可用性。当一个节点发生故障时,其他节点可以自动地将故障节点上的数据转移到其他可用的节点上,以保证数据的可用性。此外,当客户端需要访问某个键时,它需要先找到该键所属的节点,然后才能进行后续操作。为了实现这个功能,Redis分片集群通常会使用一种称为“代理”的组件,来帮助客户端找到正确的节点。
总的来说,Redis分片集群的原理是通过对数据进行分区和负载均衡来实现高可用性和高性能。通过使用哈希分片和代理等技术,Redis分片集群可以有效地处理大规模的数据和高并发请求。
二、搭建分片集群
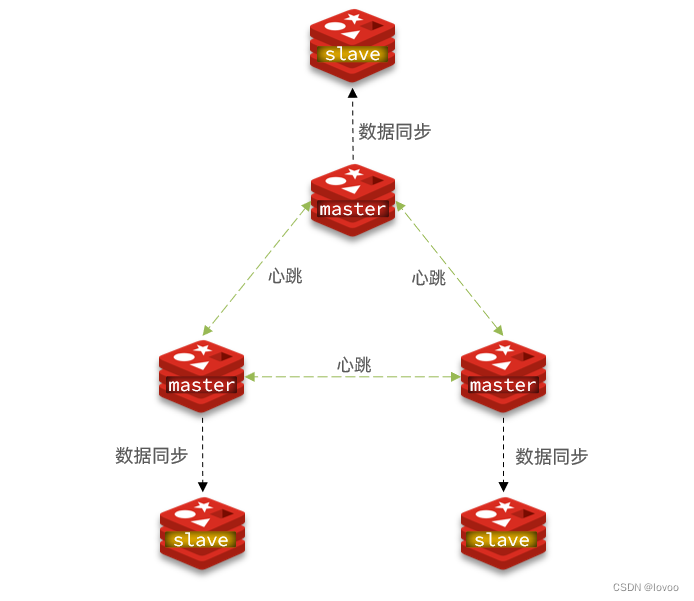
2.1.集群结构
分片集群需要的节点数量较多,这里我们搭建一个最小的分片集群,包含3个master节点,每个master包含一个slave节点,结构如下:
这里我们会在同一台虚拟机中开启6个redis实例,模拟分片集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | master |
| 192.168.150.101 | 7003 | master |
| 192.168.150.101 | 8001 | slave |
| 192.168.150.101 | 8002 | slave |
| 192.168.150.101 | 8003 | slave |
2.2.准备实例和配置
删除之前的7001、7002、7003这几个目录,重新创建出7001、7002、7003、8001、8002、8003目录:
# 进入/tmp目录
cd /tmp
# 删除旧的,避免配置干扰
rm -rf 7001 7002 7003
# 创建目录
mkdir 7001 7002 7003 8001 8002 8003
- 1
- 2
- 3
- 4
- 5
- 6
在/tmp下准备一个新的redis.conf文件,内容如下:
port 6379
# 开启集群功能 cluster-enabled yes # 集群的配置文件名称,不需要我们创建,由redis自己维护 cluster-config-file /tmp/6379/nodes.conf # 节点心跳失败的超时时间 cluster-node-timeout 5000 # 持久化文件存放目录 dir /tmp/6379 # 绑定地址 bind 0.0.0.0 # 让redis后台运行 daemonize yes # 注册的实例ip replica-announce-ip 192.168.150.101 # 保护模式 protected-mode no # 数据库数量 databases 1 # 日志 logfile /tmp/6379/run.log

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
将这个文件拷贝到每个目录下:
# 进入/tmp目录
cd /tmp
# 执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf
- 1
- 2
- 3
- 4
修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致:
# 进入/tmp目录
cd /tmp
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
- 1
- 2
- 3
- 4
2.3.启动
因为已经配置了后台启动模式,所以可以直接启动服务:
# 进入/tmp目录
cd /tmp
# 一键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
- 1
- 2
- 3
- 4
通过ps查看状态:
ps -ef | grep redis
- 1
发现服务都已经正常启动:

如果要关闭所有进程,可以执行命令:
ps -ef | grep redis | awk '{print $2}' | xargs kill
- 1
或者(推荐这种方式):
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown
- 1
2.4.创建集群
虽然服务启动了,但是目前每个服务之间都是独立的,没有任何关联。
我们需要执行命令来创建集群,在Redis5.0之前创建集群比较麻烦,5.0之后集群管理命令都集成到了redis-cli中。
1)Redis5.0之前
Redis5.0之前集群命令都是用redis安装包下的src/redis-trib.rb来实现的。因为redis-trib.rb是有ruby语言编写的所以需要安装ruby环境。
# 安装依赖
yum -y install zlib ruby rubygems
gem install redis
- 1
- 2
- 3
然后通过命令来管理集群:
# 进入redis的src目录
cd /tmp/redis-6.2.4/src
# 创建集群
./redis-trib.rb create --replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
- 1
- 2
- 3
- 4
2)Redis5.0以后
我们使用的是Redis6.2.4版本,集群管理以及集成到了redis-cli中,格式如下:
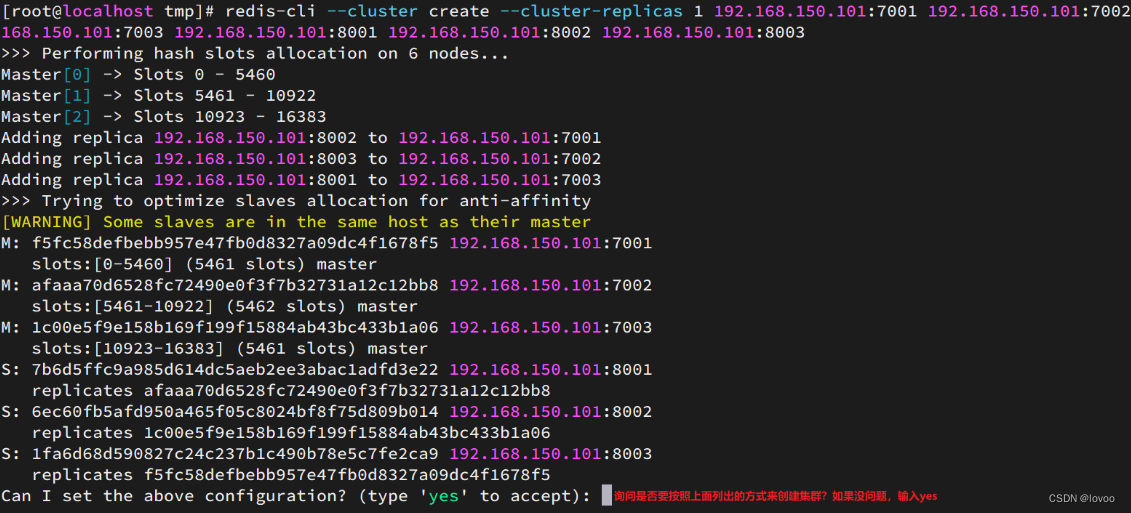
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
- 1
命令说明:
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
运行后的样子:
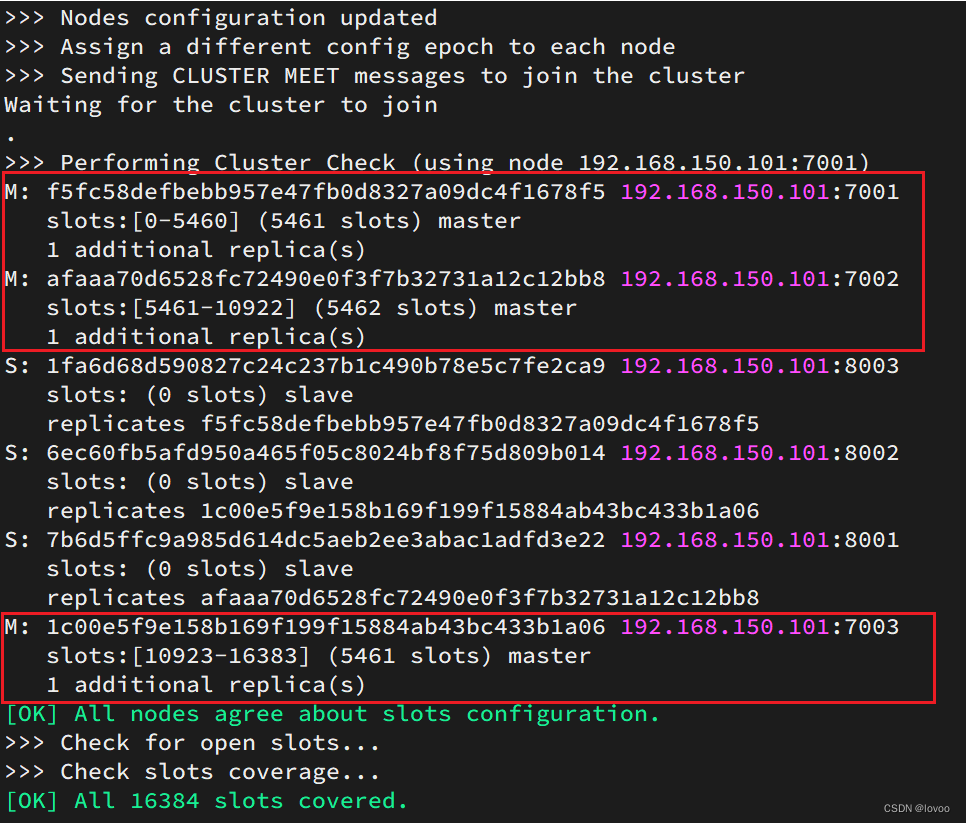
这里输入yes,则集群开始创建:
通过命令可以查看集群状态:
redis-cli -p 7001 cluster nodes
- 1

2.5.测试
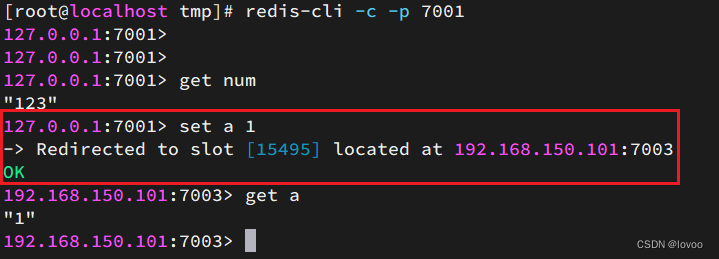
尝试连接7001节点,存储一个数据:
# 连接
redis-cli -p 7001
# 存储数据
set num 123
# 读取数据
get num
# 再次存储
set a 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果悲剧了:
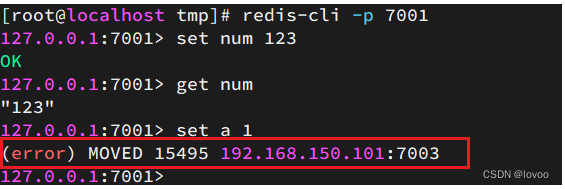
集群操作时,需要给redis-cli加上-c参数才可以:
redis-cli -c -p 7001
- 1
这次可以了:
三、作用、优点和缺点
1、作用
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
2、优点
- 所有的逻辑都是可控的,不依赖于第三方分布式中间件;
- 服务端的Redis实例彼此独立,相互无关联,每个Redis实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强;
- 开发人员清楚怎么实现分片、路由的规则,不用担心踩坑。
3、缺点
- 客户端需要实现分片逻辑,需要开发额外代码;
- 客户端分片技术使用的一致性哈希算法存在哈希冲突的问题,虽然可以使用其他哈希算法解决,但是会增加算法的复杂度;
- 集群中某个Redis实例宕机时,需要手动将数据迁移到其他实例中,以保证数据的一致性。
四、源码下载
https://gitee.com/charlinchenlin/koo-erp

