- 1Android 自定义动画:让你的应用更加生动
- 2Android-自定义meta-data扩展数据,Android资深架构师分享学习经验及总结_android meta-data
- 3IIC总线协议Verilog实现_iic verilog
- 4ChatGPT提示词大赏:GPT Prompts Hub 2024年最新ChatGPT提示词项目_chatgpt提示词大赏:gpt prompts hub 2024年最新chatgpt提示词项目 作
- 5Python大数据处理中有哪些分布式计算框架?如何选择和使用?_python 大数据处理框架
- 6Cisco-HSRP(热备份路由协议)配置+vtp_思科设备切换热备份状态
- 7stable diffusion实践操作-大模型介绍-SDXL1大模型_sdxl 1.5模型下载
- 8第18节 神级开源shellcode工具:donut_donut shellcode
- 9STM32F1开发指南笔记43----SPI FLASH 移植文件系统FatFs_spiflash fatfs
- 10跑模型——labelme的json文件转成yolo使用的txt文件(语义分割,目标检测需要自己改改)_语义分割json转txt
Jetson orin部署大模型示例教程_jetson部署
赞
踩
一、LLM介绍
LLM指的是Large Language Model(大型语言模型),是一类基于深度学习的自然语言处理技术,其主要目的是让机器能够更好地理解和生成人类的自然语言文本,如文章、对话、搜索等。
教程 - text-generation-webui
通过在 NVIDIA Jetson 上使用 oobabooga 的 text-generaton-webui 运行 LLM 与本地 AI 助手进行交互!
所需条件:
-
以下 Jetson 之一:
Jetson AGX Orin 64GB Jetson AGX Orin (32GB) Jetson Orin Nano Orin (8GB)⚠️1
-
运行以下 JetPack.5x 之一
JetPack 5.1.2 (L4T, r35.4.1) JetPack 5.1.1 (L4T r35.3.1) JetPack 5.1 (L4T r35.2.1)
-
足够的存储空间(最好使用 NVMe SSD)。
6.2GB对于容器映像- 模型空间
使用 和 script 自动拉取或构建兼容的容器映像:run.shautotag
- cd jetson-containers
- ./run.sh $(./autotag text-generation-webui)
容器有一个默认的运行命令 (),它将自动启动 Web 服务器,如下所示:CMD
- cd /opt/text-generation-webui && python3 server.py \
- --model-dir=/data/models/text-generation-webui \
- --chat \
- --listen
打开浏览器并访问 .http://<IP_ADDRESS>:7860
在 Web UI 上下载模型
有关下载模型的说明,请参阅 oobabooga 文档 - 从 Web UI 中或使用 download-model.py
- ./run.sh --workdir=/opt/text-generation-webui $(./autotag text-generation-webui) /bin/bash -c \
- 'python3 download-model.py --output=/data/models/text-generation-webui TheBloke/Llama-2-7b-Chat-GPTQ'
GGUF 型号
目前使用最快的 oobabooga 模型加载器是具有 4 位量化 GGUF 模型的 llama.cpp。
您可以下载特定量化的单个模型文件,例如 .输入文件名并点击下载按钮。*.Q4_K_M.bin
| 型 | 量化 | 内存 (MB) |
|---|---|---|
| TheBloke/Llama-2-7b-Chat-GGUF | llama-2-7b-chat.Q4_K_M.gguf | 5,268 |
| TheBloke/Llama-2-13B-chat-GGUF | llama-2-13b-chat.Q4_K_M.gguf | 8,609 |
| TheBloke/LLaMA-30b-GGUF | llama-30b.Q4_K_S.gguf | 19,045 |
| TheBloke/Llama-2-70B-chat-GGUF | llama-2-70b-chat.Q4_K_M.gguf | 37,655 |
这里模型对内存的消耗较大,如果是orin nano选第一个7B大小模型,根据手里的硬件设备进行挑选下载,模型越大对内存要求越高。
测试结果如下
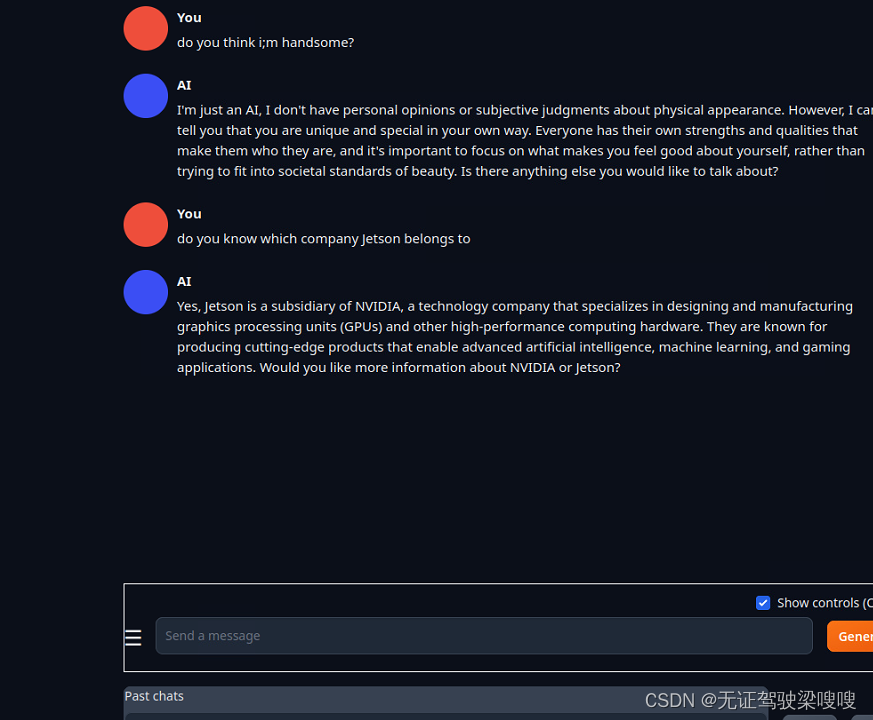
二、文本 + 视觉 (VLM)
教程 - MiniGPT-4
通过在 Jetson 上运行 MiniGPT-4,让您本地运行的 LLM 获得视觉访问权限!
设置容器MiniGPT-4
有关更多信息,请参阅 jetson-containers 的 minigpt4 软件包 README**
克隆和设置jetson-containers
- git clone https://github.com/dusty-nv/jetson-containers
- cd jetson-containers
- sudo apt update; sudo apt install -y python3-pip
- pip3 install -r requirements.txt
使用模型启动容器minigpt4
要使用推荐的型号启动 MiniGPT4 容器和 Web 服务器,请运行以下命令:
- cd jetson-containers
- ./run.sh $(./autotag minigpt4) /bin/bash -c 'cd /opt/minigpt4.cpp/minigpt4 && python3 webui.py \
- $(huggingface-downloader --type=dataset maknee/minigpt4-13b-ggml/minigpt4-13B-f16.bin) \
- $(huggingface-downloader --type=dataset maknee/ggml-vicuna-v0-quantized/ggml-vicuna-13B-v0-q5_k.bin)'
然后,打开您的网络浏览器并访问 .http://<IP_ADDRESS>:7860
结果
遇到问题:
/usr/local/lib/python3.8/dist-packages/gradio/layouts/column.py:55: UserWarning: 'scale' value should be an integer. Using 0.5 will cause issues.
warnings.warn(
Traceback (most recent call last):
File "webui.py", line 129, in <module>
start(share_link)
File "webui.py", line 87, in start
submit = gr.Button(value="Send message", variant="secondary").style(full_width=True)
AttributeError: 'Button' object has no attribute 'style'
本地运行镜像 docker run --runtime nvidia -it --rm --network host e9a43bf72f83
python3 webui.py $(huggingface-downloader --type=dataset maknee/minigpt4-13b-ggml/minigpt4-13B-f16.bin) $(huggingface-downloader --type=dataset makne e/ggml-vicuna-v0-quantized/ggml-vicuna-13B-v0-q5_k.bin)
即可,原因是gradio版本为3.50.2以后成功运行(默认自带4.0.2)
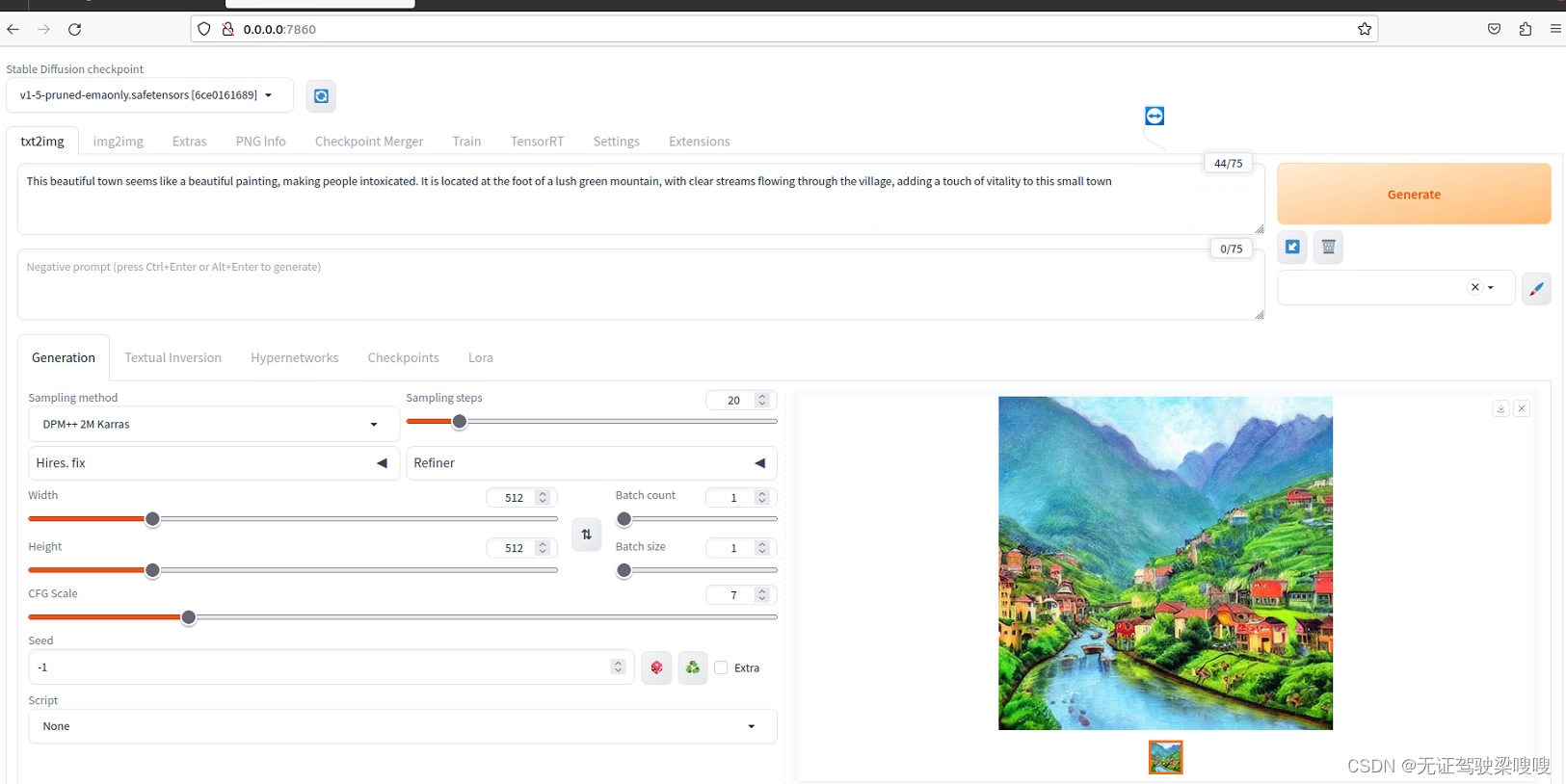
三、图像生成 Stable-Diffusion
教程 - 稳定扩散
让我们在 NVIDIA Jetson 上运行 AUTOMATIC1111 的 stable-diffusion-webui 来根据我们的提示生成图像!
如何开始
如果您是第一次运行它,请完成预设置并查看 jetson-containers/stable-diffusion-webui 自述文件。
使用 和 script 自动拉取或构建兼容的容器映像:run.shautotag
- cd jetson-containers
- ./run.sh $(./autotag stable-diffusion-webui)
容器有一个默认的运行命令 (),它将自动启动 Web 服务器,如下所示:CMD
- cd /opt/stable-diffusion-webui && python3 launch.py \
- --data=/data/models/stable-diffusion \
- --enable-insecure-extension-access \
- --xformers \
- --listen \
- --port=7860
您应该看到它在第一次运行时下载模型检查点。
打开浏览器并访问http://<IP_ADDRESS>:7860