
- 1【AI OpenDevin】开源AI程序员,帮您写代码,开发程序_opendevin怎么使用
- 2sourceTree中git工作流使用_sourcetree git工作流不能用
- 3【计算机毕业设计】基于微信小程序的开发项目150套(附源码+演示视频+LW)
- 4【2024 信息素养大赛c++模拟题】算法创意实践挑战赛(基于 C++)_温州市信息素养提升实践活动计算思维项目c++作品
- 5【数据库&sql】EXISTS、NOT EXISTS、IN、NOT IN的分析及示例_sql 查询 not exists
- 6全网最全深度学习案例整理汇总
- 7【软件工程】建模工具之开发各阶段绘图——UML2.0常用图实践技巧(功能用例图、静态类图、动态序列图&状态图&活动图)_功能模块用uml拿个图
- 8【解决】报错:部署Deformable-DETR环境问题_no module named 'deformable_detr_ops
- 9EEPROM AT24C08的操作_at24c08 page addr
- 10FFmpeg音视频开发知识点(二)_avcodec_receive_frame -11
[机器学习与scikit-learn-49]:特征工程-特征选择(降维)-4-二级过滤-特征值与标签之间的关系:卡方过滤
赞
踩
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/124073917
目录
2.1 在scikit-learn中,有两种方式实现卡方过滤:
前言
方差过滤,只考虑了不同样本的同一个特征值之间的互异性(即数学上的方差),如果方差小,这说明,该特征,对于不同样本没有啥差异,没有差异性的特征,对区分不同的样本,属于次要矛盾的次要因素,因此可以忽略。
然后,方差比较大的特征,对于区分样本的标签,就是主要矛盾和主要因素吗?很显然,不一定,还需要检查样本特征与样本标签之间有没有相关性!!!对于样本特征与样本标签具有强相关的特征,说明样本特征对于区分不同标签是强相关的, 否则样本标签对于区分不同的样本的标签,没有帮助或帮助不大,这样的特征,不管方差有多大,也可以过滤掉。
在sklearn当中,我们有三种常用的方法来评判特征与标签之间的相关性:卡方,F检验,互信息。
第1章 卡方过滤概述
1.1 概述
卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤。
(1)卡方检验类feature_selection.chi2计算每个非负特征和标签之间的卡方统计量,并依照卡方统计量由高到低为特征排名。
(2)再结合feature_selection.SelectKBest这个可以输入”评分标准“来选出前K个分数最高的特征的类,我们可以借此除去最可能独立于标签,与我们分类标签无关的特征。
SelectKBest的输入,可以是任意过滤后的特征,也可以是原始特征,它只是按照某个评分标准,对特征进行排序,然后选出评分标准最高的K个特征。
(3)把过滤后的特征用于模型训练。
(4)过滤后特征的训练评估
如果选出的降低维度后的特征对模型进行训练导致的精确度降低,说明过多的过滤掉了对分类产生较大影响的特征,需要通过调整K值,重新还原部分特征,直到过滤掉的特征,对分类效果没有影响或影响控制在可以接受的范围。
特征过滤,有非常大的可能性会降低部分的分类性能,但会极大地降低模型所需要的内存和训练时间。这是特征过滤的重要意义。
1.2 卡方过滤的基本原理
卡方检验,统计学的方法。卡方检验是英文Chi-Square Test 的谐音。
在大数据运营场合,它用于检测某个自变量(即特征)值是不是和因变量有显著关系。Y=F(X1, X2, X3.....Xn),对于自变量与因变量关系不大的自变量(即特征),就可以直接过滤掉。这就是卡方过滤的基本思想。
1.3 卡方检验的案例说明
我们要观察性别特征和在线上买不买(标签)生鲜食品有没有关系。
现实生活中,女性通常去菜市场买菜的比较多,也就是说,性别特征与买不买菜有强相关性,且女性占比较大。
那么在线上是不是也这样呢?
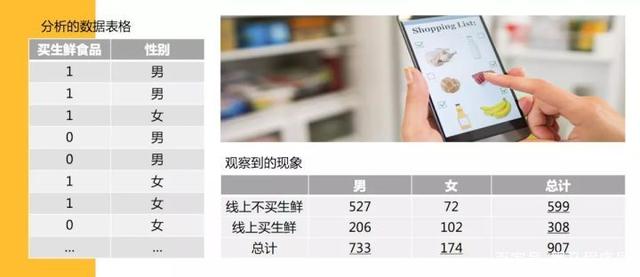
我们得出观察到数据,并且形成表格后,我们需要计算理论的数据,在上面的例子我们发现,我们发现有66%的人不在线上买生鲜(599除以907),34%的人会在线上买。
那如果,男的有733个人,女的有174个人,根据这些比例,我们可以得出的理论值是什么呢?
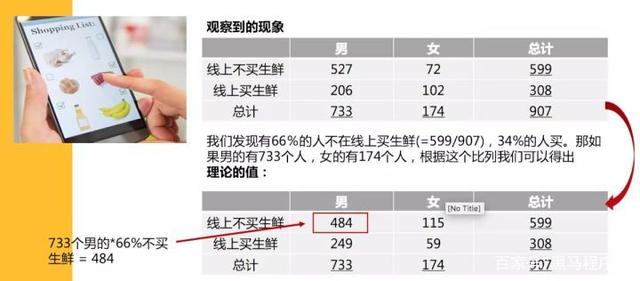
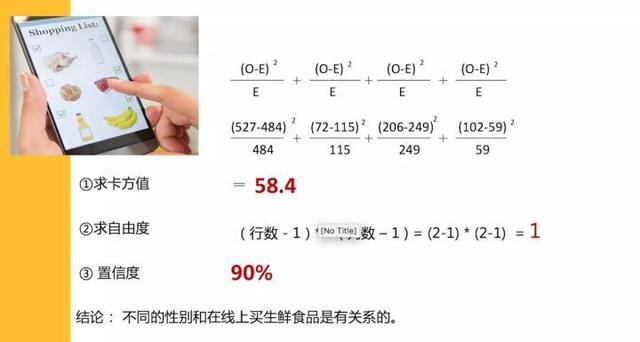
根据理论和实际值,我们可以算出卡方值,自由度,并且结合我们定义的置信度,查表得到性别和线上买生鲜是显著相关的。
看了这几个例子,是不是觉得卡方检验一点都不复杂,其实和我们生活这么贴近,我们平时的思维方式,其实就隐含着卡方检验的道理。
第2章 scikit-learn中的卡方过滤
2.1 在scikit-learn中,有两种方式实现卡方过滤:

(1)使用selectKbest:选择包含K个特征值的样本,选择的规则可以是卡方过滤或其他过滤
(2)直接使用卡方过滤chi2:它直接对样本数据进行过滤,获得所有样本的卡方值和所有样本的p值,然后在使用K值和p值进行过滤。
2.2 卡方过滤的基本步骤
(1)选择合适的分类算法:这里选择随机森林,它的运行时间与样本特征的个数无关,不影响执行效率。
(2)准确率分数评估:这里选择交叉验证评估方法,进行多次交叉验证,最后选择平均分作为样本标签过滤前后统计分数的工具。
(3)卡方过滤前:使用方差过滤后的数据集进行分类算法和交叉评估
(4)卡方过滤:方差过滤后的数据集的基础上进行样本特征的二次过滤 。
(4)卡方过滤后:使用卡方过滤后的数据集进行分类算法和交叉评估
2.3 selectKbest + chi2实现卡方过滤
(1)随机森林 + 方差特征过滤后数据集 + 交叉评估
- # 使用随机森林算法进行比较
- from sklearn.ensemble import RandomForestClassifier as RFC
- # 使用样本的交叉验证进行模型评估
- from sklearn.model_selection import cross_val_score
-
- # X_fsvar_mid:经过方差过滤后的样本
- # 使用随机森林算法进行比较
- oRFCModel = RFC(n_estimators=10,random_state=0)
- scores = cross_val_score(oRFCModel ,X_fsvar_mid, y, cv=5)
- score = scores.mean()
- print("scores=", scores)
- print("score=", score)
scores= [0.9397619 0.93821429 0.93833333 0.93690476 0.94202381]
score= 0.9390476190476191
(2)手工设定特征数量
- # 特征选择通用算法
- from sklearn.feature_selection import SelectKBest
- # 特征过滤规则:卡方
- from sklearn.feature_selection import chi2
-
- #假设手工选择300特征
- oSelectKbest = SelectKBest(chi2, k=300)
- X_fschi = oSelectKbest.fit_transform(X_fsvar_mid, y)
- print("过滤前特征数:", X_fsvar_mid.shape)
- print("过滤后特征数:", X_fschi.shape)
过滤前特征数: (42000, 392) 过滤后特征数: (42000, 300)
(3)用手工选择的特征数进行分类
- # 使用随机森林算法进行比较
- from sklearn.ensemble import RandomForestClassifier as RFC
- # 使用样本的交叉验证进行模型评估
- from sklearn.model_selection import cross_val_score
-
- oRFCModel = RFC(n_estimators=10,random_state=0)
- scores = cross_val_score(oRFCModel ,X_fschi, y, cv=5)
- score = scores.mean()
- print("scores=", scores)
- print("score=", score)
scores= [0.93190476 0.9372619 0.93261905 0.93345238 0.93714286]
score= 0.9344761904761905
备注:
使用300个卡方过滤后的特征进行分类,交叉验证的分数并没有提升,反而是下降了0.5个百分点。
为什么?
- 降维造成的部分权重较低特征的丢失
- 卡方过滤了过多的特征,手工选择的300个特征并非是最优的特征数
如何选择最后的特征数呢?
(4)自动评估不同K值下的分数
- #!!!!!!【TIME WARNING: 5 mins】!!!!!#
- %matplotlib inline
- import matplotlib.pyplot as plt
-
- # 自动K值选择程序
- score = []
- for i in range(200,390,10):
- # 卡方过滤特征
- X_fschi = SelectKBest(chi2, k=i).fit_transform(X_fsvar_mid, y)
- # 随机森林分类
- oRFC = RFC(n_estimators=10,random_state=0)
- # 样本的交叉验证
- once = cross_val_score(oRFC, X_fschi, y, cv=5).mean()
- score.append(once)
- plt.plot(range(200,390,10),score)
- plt.show()

备注:
- 设定特征值个数K在【200, 390之间】,步长为20.
- 计算几个每个K值时,随机森林分类算法+样本交叉验证的分数
- 由于需要执行多次,因此耗时比较长!!!
- 从可视化的图中可以看出:当特征数在325到375之间时,分数比较高。
(5)选择370个特征进行验证
- # 特征选择通用算法
- from sklearn.feature_selection import SelectKBest
- # 特征过滤规则:卡方
- from sklearn.feature_selection import chi2
-
- #假设手工选择300特征
- oSelectKbest = SelectKBest(chi2, k=370)
- X_fschi = oSelectKbest.fit_transform(X_fsvar_mid, y)
- print("过滤前特征数:", X_fsvar_mid.shape)
- print("过滤后特征数:", X_fschi.shape)
-
- # 使用随机森林算法进行比较
- from sklearn.ensemble import RandomForestClassifier as RFC
- # 使用样本的交叉验证进行模型评估
- from sklearn.model_selection import cross_val_score
-
- oRFCModel = RFC(n_estimators=10,random_state=0)
- scores = cross_val_score(oRFCModel ,X_fschi, y, cv=5)
- score = scores.mean()
- print("scores=", scores)
- print("score=", score)
过滤前特征数: (42000, 392)
过滤后特征数: (42000, 370)
scores= [0.93797619 0.93797619 0.93761905 0.94 0.93964286]
score= 0.9386428571428571
备注:
- 此时分数有所提升。
2.4 chi2独自过滤
- chivalue, pvalues_chi = chi2(X_fsvar, y)
-
- print("卡方c值:" , chivalue.shape)
-
- print("卡方p值:" , pvalues_chi.shape)
-
- # k取多少?我们想要消除所有p值大于设定值,比如0.05或0.01的特征:
- k = chivalue.shape[0] - (pvalues_chi > 0.01).sum()
- print("满足条件的样本数:k=", k)
-
- X_fschi = SelectKBest(chi2, k=392).fit_transform(X_fsvar_mid, y)
-
- score = cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()
-
- print("score=", score)
卡方c值: (392,) 卡方p值: (392,) 满足条件的样本数:k= 392 score= 0.9390476190476191
备注:
很显然,经过方差过滤后,一共有392个特征,p>0.01选择后,还是392个特征
这说明,在本案例中,方差过滤后的特征,与标签都是强相关的。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/124073917

