
- 1项目中,如何写 readme.md 文件 | 写项目总结
- 2论文阅读《Fine-Grained Face Swapping via Regional GAN Inversion》
- 3Python自动化测试系列[v1.0.0][html-testRunner测试报告]_pip install html-testrunner==1.0.3
- 4【Git-Clone】Git Clone 命令直接使用用户名:密码_使用账号密码clone项目
- 5Android 组件化工程结构分析以及项目方案的实施_安卓工程分析
- 6uni-app心得体会_uniapp心得
- 7雨云:不一样的服务器体验
- 8Linux发送邮件(Mail)_阿里云服务器 linux 发送邮件
- 9视频智能识别技术安全监管方案保障露营慢生活
- 10Spring Boot Serverless 实战系列“架构篇” 首发 | 光速入门函数计算
SQL中用到LIKE模糊检索的几种优化场景
赞
踩
SQL开发中经常会碰到使用LIKE模糊检索的场景,'%'的位置,可能影响索引的正常使用,看到刘老师公众号的一篇文章,介绍了相关场景的改造策略,非常受用,推荐阅读。
测试表t1,object_name列创建索引,
- create table t1 as select * from dba_objects;
- create index idx_t1_01 on t1(object_name);
场景一,'%'在后
select object_name from t1 where object_name like 'BISAL%';明显能使用索引,但是要注意,这种情况下,'%'前字符串越短,索引的选择性就可能越差,

场景二,'%'在前
select object_name from t1 where object_name like '%BISAL'因为这个索引是按照object_name列的正序在索引中组织的,头部的模糊检索,无法直接通过索引定位数据,只是因为检索列只有object_name,所以用到的是索引快速全扫描,实际还是扫描的所有索引叶子节点,
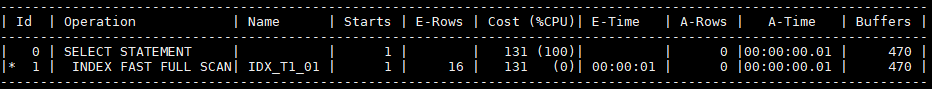
为了说明清楚,我们检索object_id列,他不在索引中,
select object_id from t1 where object_name like '%BISAL';因此,Oracle选择了成本更低的全表扫描,

作为比对,我们按照'BISAL%',能用到索引的场景测试下,
select object_id from t1 where object_name like 'BISAL%';可以看到,用到的是索引范围扫描,得到rowid,再回表得到具体的数据,不需要扫描整个索引或者整张表,
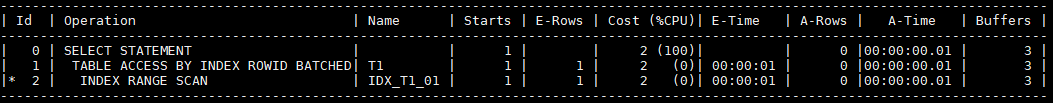
我们拉回来,如果非得用'%BISAL'检索,可以创建一个object_name列的反向索引,
create index idx_t1_02 on t1(reverse(object_name));查询语句中LIKE的右值同样使用reverse函数,
select object_name from t1 where reverse(object_name) like reverse('%BISAL');此时,'%BISAL'用到了索引,细心的朋友可能发现执行计划和上面的略有不同,这里多了回表的操作,原因就是索引是按照reverse(object_name)组织的,但是检索的是object_name,因此要根据索引进行回表,

场景三,前后'%'
例如'%BISAL%',能不能使用索引?
分为三种情况,
(1) ABC始终从字符串开始的某个固定位置出现,可以创建函数索引进行优化。
(2) ABC始终从字符串结尾的某个固定位置出现,可以创建函数组合索引进行优化。
(3) ABC在字符串中位置不固定,可以通过改写SQL进行优化。
第一种情况,ABC始终从字符串开始的某个固定位置出现。
可以通过substr函数截取字符串的功能,创建函数索引。
例如,BISAL从字符串的第五位出现,创建函数索引,
create index idx_t1_03 on t1(substr(object_name, 5, 30));执行如下SQL,相当于每次都从原字符串的第五位开始截取,
select object_name from t1 where substr(object_name, 5, 30) like 'BISAL%';可以用到索引,

第二种情况,ABC始终从字符串结尾的某个固定位置出现,可以创建函数组合索引进行优化。
相当于需要倒序截取字符串,可以通过reverse和substr组合函数索引,例如BISAL从字符串倒数第五位出现,创建函数索引,
create index idx_t1_04 on t1(reverse(substr(object_name, 1, length(object_name)-4)));检索的时候,需要用到reverse和substr函数组合,like右值用'%BISAL',就可以实现‘%BISAL%’检索功能,
select object_name from t1 where reverse(substr(object_name, 1, length(object_name)-4)) like reverse ('%BISAL');第三种情况,ABC在字符串中位置不固定,可以通过改写SQL进行优化。
这种就需要改写,假设object_name存在索引,要求执行如下,
select object_name from t1 where object_name like '%BISAL%';我们改写成,通过一个子查询,和条件object_name关联,
select object_name from t1 where object_name in (select object_name from t1 where object_name like '%BISAL%');此时的执行计划,如下所示,索引快速全扫描和索引范围扫描的组合,

即使我们检索object_id这个不在索引中的字段,
select object_id from t1 where object_name in (select object_name from t1 where object_name like '%BISAL%');同样避免了全表扫描,虽然还是要索引快速全扫描,但至少扫描的成本降低了(1/N(索引块数和数据块数的比例)),单就这点来说,表越大,效果可能越明显。但是这种IN改写,如果子查询返回的记录数较少,执行效率就可能提高了N倍,但如果较多,改写的效率,可能和之前相差不大了,

虽然以上的'%'有各种改造的方案,但至少都得改写一些SQL,所以还是建议,从需求层面,确定使用LIKE模糊检索的场景到底合理不合理,他的非功能指标是否满足要求,不要上来就改,谋定而后动,就可能事半功倍。
近期更新的文章:
《最近碰到的问题》
《关于数据治理的读书笔记 - 企业数据治理的“道、法、术、器”》
文章分类和索引:

