
- 1harmonyos分层,HarmonyOS开发--1、组件化的设计方案
- 2mycat分库分表(超详细)
- 3等保2.0测评:VMware ESXI_retry=3 min=disabled,disabled,disabled,7,7
- 4[教程]使用 Git 克隆指定分支_git clone 指定branch
- 5控制el-table的列显示隐藏_el-table设置某列不显示
- 6计算机基础-------硬盘、内存、cpu的理解_电脑磁盘硬盘内存都是什么意思
- 7fastapi路径参数于请求体(最简单的教程)_路径参数 请求参数 请求体
- 8故障诊断常用数据集_故障诊断数据集
- 9汇编文件.S 和 .s的区别_.s 与 .s
- 10开源 台账 预算 管理系统_3个坚持预算的开源工具
大数据采集技术工具及应用场景_数据采集的典型应用场景
赞
踩
大数据采集可以细分为数据抽取、数据清洗、数据集成、数据转换等过程,将分散、零乱、不统一的数据整合到一起,以一种结构化、可分析的形态加载到数据仓库中,从而为后续的数据使用奠定坚实基础。
数据采集可以分为内部采集与外部采集两个方面。
(1)离线数据采集技术,首先要是基于文件的数据采集系统、日志收集系统等,代表性的工具有Facebook公司开发的Scribe、Cloudera公司开发的Flume和Apache基金会支持的Chukwa等;其次是基于数据库和表的数据采集技术,基于数据库的数据采集系统中代表性工具有GoldenGate 公司的TMD、迪思杰公司而数据采集软件、IBM公司的CDC、MySQL支持的Binlog 采集工具等;在基于表的批量抽取软件中,广泛应用的是Sqoop和其他ETL工具。
(2)开放API类,即数据源提供者开放的数据采集接口,可以用来软取限定的数据。在外部数据中,除了互联网数据采集技术,也有基于传感器应用的采集技术,这种技术在物联网中用得较多。此外,还有电信公司特有的探针技术,例如,我们在打电话、利用手机上网时,电信公司的路由器、交换机等设备中都会有数据交换,探针就是从这些设备上采集数据的技术。
目前,数据抽取、清洗、转换面临的挑战在于∶数据源的多样性问题、数据的实时性问题、数据采集的可靠性问题、数据的杂乱性问题。这里要特别指出的是,通过采集系统得到的原始数据并不是干净的数据,大部分的数据都是带有重复、错误、缺失的所谓脏数据。实际上,数据科学家几乎80%的工作都是处理这些脏数据,可见由数据的杂乱性带来的麻烦是非常大的。因此,如何高效精准地处理好这些原始数据,也是大数据采集技术研究面临的重大挑战。以下我们来介绍两种数据采集工具。
一、结构化数据采集工具
在Hadoop大数据应用生态系统中,Sqoop作为Apache的顶级项目,主要用来在Hadoop和关系数据库之间传递数据。通过Sqoop可以方便地将数据从关系数据库导入HDFS、HBase或Hive中,或者将数据从HDFS 导出到关系数据库中。下图是Sqoop系统架构示意图。
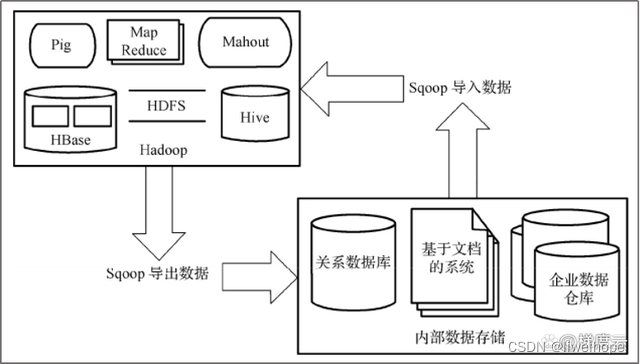
从理论上讲,支持JDBC的数据库都可以使用Sqoop和HDFS进行数据交互。Sqoop系统数据具有以下特点∶支持多种文件类型,支持数据追加、可以数据选取和压缩,支持Map数定制,支持将关系数据库中的数据导入Hive和HBase中。
二、日志收集工具与技术
企业每天都会产生大量的数据,这些数据将会被用来进行分析使用,我知道日志收集是大数据的基石,日志收集系统的最主要的特征是高可用、高扩展。
1.日志收集
日志收集模块需要使用一个分布式的、具有高可靠性和高可用性、能够处理海量日志数据的框架,并且应该能够支持多源采集和集中存储。Flume、Scribe使用比较广泛的日志收集系统。Flume是由Cloudera开发的一个分布式、高可靠性和高可用性的海量日志收集系统,支持在系统中定制各类数据发送方,用于收集数据;Flume的工作流程是先收集数据源的数据,再将数据发送到接收方。为了保证这个过程的可靠性,在发送到接收方之前,会先对数据进行缓存,等到数据真正到达接收方后,才会删除缓存的数据。
2.数据分发工具Kafka
Flume收集的数据和进行日志处理的系统之间可能存在多对多的关系,为了解耦和保证数据的传输延迟,可以选用Kafka作为消息中间层进行日志中转分发。Flume发送源数据流的速度不太稳定,有时快有时慢,当Flume 的数据流发送速度过快时,会导致下游的消费系统来不及处理,这样可能会丢弃一部分数据。Kafka在这两者之间可以扮演一个缓存的角色,而且数据是写入到磁盘上的,可保证在系统正常启动/关闭时不会丢失数据。
Kafka是Apache开发的一个开源分布式消息订阅系统,该系统的设计目标是给实时数据处理提供一个统一、高吞吐量、低等待的平台。Kafka 提供了实时发布订阅的解决方案,克服了实时数据消费和更大数量级的数据量增长的问题,Kafka也支持Hadoop中的并行数据加载。下图是Kafka 的架构图。
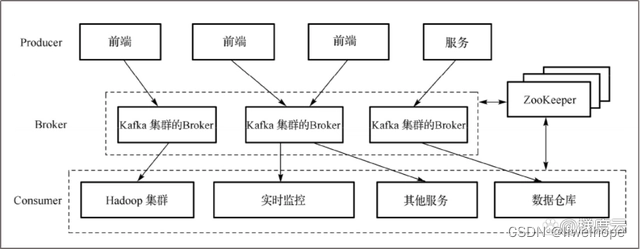
Kafka需要使用ZooKeeper(分布式应用管理框架)进行协调,从而保证系统的可用性,以及保存一些元数据ZooKeeper与Broker、Producer、Consumer之间是通过TCP协议进行通信的。
Kafka的典型使用场景如下。
(1)消息系统
常规的消息系统,Kafka 是个不错的选择。分区、多复本和容错等机制可以使Kafka具有良好的扩展性和性能优势。Kafka只能作为常规的消息系统使用,并不能确保消息发送与接收绝对可靠。
(2)网站活性跟踪
Kafka可以将网页/用户操作等信息进行实时监控或者分析等。例如,各种形式的Web活动产生的大量数据,用户活动事件(如登录、访问页面、单击链接),社交网络活动(如喜欢、分享、评论),以及系统运行日志等,由于这些数据的高吞吐量(每秒百万级的消息),因此通常由日志收集系统和日志聚合系统来处理。这些传统方案可将日志数据传输给Hadoop来进行离线分析。但是,对于需要实时处理的系统,就需要其他工具的支持。
(3)日志聚合系统
Kafka的特性使它非常适合作为日志聚合系统,可以将操作日志批量、异步地发送到Kafka 集群中,而不是保存在本地或者数据库中。
总之,Kafka是一个非常通用的系统,允许多个Producer和Consumer共享多个Topic。Flume发送数据、优化数据、集成Hadoop的安全特性。如果数据被多个系统消费,则建议使用Kafka;如果向Hadoop发送数据,则建议使用Flume。

