
- 1JDK1.8的新特性_jdk1.8 @elementtype
- 2TensorFlow什么意思?TensorFlow是什么?
- 3RCC——使用HSE/HSI配置时钟
- 4JDK1.8 新特性(未完待续)
- 5Dockerfile常用命令(安全)_[dockerfile动态参数"/bin/sh","-c
- 6数学建模 | MATLAB 学习 | 遗传算法_integer variable indices
- 7c#【 网络日志解析工具】开发篇-【媒体预览功能】--base64,webp响应解码为图片-》可做复制base64进行图片查看_21:/##x-ap6eblhxr31mo##1:/$dxdgaqk$
- 8Linux Centos 7查看文件内容_centos7查看文件内容
- 9【Docker】Docker的部署含服务和应用、多租环境、Linux内核的详细介绍_什么应用适合容器部署
- 10Win10 adb pull指定的文件_adb pull到本地
2023年软件测试岗必问的100+个面试题【含答案】_软件测试面试题目100及最佳答案
赞
踩
一、基础理论
1、开场介绍
介绍要领:个人基本信息、工作经历、之前所做过的工作及个人专长或者技能优势。扬长避短,一定要口语化,语速适中。沟通好的就多说几句,沟通不好的话就尽量少说两句。举例如下:
面试官你好,我叫XXX,来贵公司面试软件测试岗位,我之前从事软件测试工作大概有X年了,一直在XXX公司做,工作中所涉及的技术主要包括:功能测试相关的兼容、易用等,此外还涉及接口及自动化方面的测试,但还是及功能测试为主,所涉及的项目比如WEB/APP/小程序这些都做过,大致的情况请面试官看下我的简历,希望我的情况能够满足贵公司的要求,谢谢!
2、公司的测试流程?
1、阅读相关文档(如产品PRD、UI设计、产品流程图等)。
2、参加需求评审会议。
3、编写测试计划。(根据最终确定的需求文档)
4、编写测试用例(等价类划分法、边界值分析法等)。
5、用例评审,给出冒烟用例(主要参与人员:开发、测试、产品、测试leader)
6、开发冒烟测试,并发提测邮件
7、执行测试用例,记录bug
8、验证bug与回归测试。
9、写测试报告,给产品发验收邮件,并配合验收
10、版本上线
11、线上日志分析,跟踪
3、你用过哪些用例设计方法?
白盒测试:逻辑覆盖、循环覆盖、基本路径覆盖
黑盒测试:边界值分析法、等价类划分、错误猜测法、因果图法、状态图法、测试大纲法、随机测试场景法
4、如何测试一个 纸杯?
1、功能度:用水杯装水看漏不漏;水能不能被喝到
2、安全性:杯子有没有毒或细菌
3、可靠性:杯子从不同高度落下的损坏程度
4、可移植性:杯子在不同的地方、温度等环境下是否都可以正常使用
5、兼容性:杯子是否能够容纳果汁、白水、酒精、汽油等
6、易用性:杯子是否烫手、是否有防滑措施、是否方便饮用
7、用户文档:使用手册是否对杯子的用法、限制、使用条件等有详细描述
8、疲劳测试:将杯子盛上水(案例一)放 24 小时检查泄漏时间和情况;盛上汽油(案例二)
放 24 小时检查泄漏时间和情况等
9、压力测试:用根针并在针上面不断加重量,看压强多大时会穿透
5、设计一个登录页面的用例(提供某个场景设计用例,重点!)
● 功能测试:正确输入、为空输入、字符类型校验、长度校验、密码是否加密显示、大写提示、跳转页面是否成功、登出后用另一个账号登录
● UI:界面布局合理、风格统一、界面文字简洁好理解、没有错别字
● 性能测试:打开登录页面需要几秒、点击登录跳转首页需要几秒、多次点击、多人点击
● 安全性:用户名和密码是否加密发送给服务器、错误登录的次数限制(防止暴力破解)、一台机器登录多个用户、一个用户多方登录、检查元素能否看到密码
● 兼容性测试:不同浏览器、不同的平台(Windows Mac)、移动设备能否工作
● 易用性:输入框可否tab键切换、回车能否登录等
6、什么是代码覆盖率?
是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,所得比例称为代码覆盖率。在做单元测试时,代码覆盖率常常被拿来作为衡量测试好坏的指标,甚至,用代码覆盖率来考核测试任务完成情况,比如,代码覆盖率必须达到80%或 90%。
代码覆盖率 = 代码的覆盖程度,一种度量方式。
代码覆盖率的意义
- 分析未覆盖部分的代码,从而反推在前期测试设计是否充分,没有覆盖到的代码是否是测试设计的盲点,为什么没有考虑到?需求/设计不够清晰,测试设计的理解有误,工程方法应用后的造成的策略性放弃等等,之后进行补充测试用例设计。
- 检测出程序中的废代码,可以逆向反推在代码设计中思维混乱点,提醒设计/开发人员理清代码逻辑关系,提升代码质量。
- 代码覆盖率高不能说明代码质量高,但是反过来看,代码覆盖率低,代码质量不会高到哪里去,可以作为测试自我审视的重要工具之一。
覆盖率数据只能代表你测试过哪些代码,不能代表你是否测试好这些代码。不要过于相信覆盖率数据。不要只拿语句覆盖率(行覆盖率)来考核你的测试人员。测试人员不能盲目追求代码覆盖率,而应该想办法设计更多更好的案例,哪怕多设计出来的案例对覆盖率一点影响也没有。
7、了解中间件吗?有哪些?
1、服务注册、发现:
常见的有zookeeper,主要功能是让网关知道有哪些服务,还有服务的位置(注册中心),服务是否正常运行等(健康检查),与网关一起合作,将用户发送的请求导向正确的处理模块。
2、消息队列:
消息队列简介很透彻的文章 https://www.zhihu.com/question/54152397
常见的有reids等,主要功能是当请求量过大时,可以将请求放入到队伍中排队,再一一去处理,需要注意的是redis会将队列储存在内存里,需要准备足够的内存资源。
你为啥用MQ消息队列?
1、用于“异步、削峰、解耦”三大场景
消息队列有啥问题么?
1、比如消息重复消费、消息丢失、消息的顺序消费等等
3、NG
4、dubbo
5、MQ
8、以后的发展规划?
1.积累行业的业务知识
2.丰富测试技能如代码编写能力
3.提升开发小工具插件的能力
4.管理协调能力,独立带版本团队
8、测试开发、与测试的区别?
1、一个侧重业务,一个侧重自动化或工具
2、测试开发的核心职能依然是测试
3、测试开发:利用开发能力解决测试工作中的问题,小到生成数据、并发模拟等工具的开发,大到整个自动化测试平台的设计与实现,旨在提高效率,降低成本
9、什么是测试左移、右移?
测试左移:本质上是借助工具和测试手段更早地发现问题和预防问题。
1)需求:对需求、架构和设计模型的测试
2)开发:着重增加对单元、组件和服务层的测试
3)持续测试:自动化测试
落地:测试任务跟踪,不仅仅只是跟踪测试本身的工作,还需要介入到需求、技术方案、编码的全过程。只有前序每一步都跟踪到位,才能尽量避免测试过程中的不可控因素,从而保证产品质量
测试右移:
对测试同学来说,版本上线后需要持续关注线上监控和预警,及时发现问题并跟进解决,将影响范围降到最低。
1)灰度发布:新版本线上测试;
2)服务监控:合理的性能监测、数据监控和预警机制;
3)用户反馈:线上问题处理、跟踪机制
10、adb常用命令有哪些?
adb devices, 获取设备列表及设备状态
adb connect 127.0.0.1:7555 连接设备
db get-state , 获取设备的状态
adb shell ps | grep adbd ,可以找到该后台进程
adb install 用于安装
adb uninstall 用于卸载
adb shell pm list package 获取设备应用信息
adb logcat 在cmd窗口查看手机的Log日志
11、举例说明项目推进的能力(针对个人评价的举例说明)
● (例)推动开发解决菜单权限需退出登录才可应用的问题。描述:XX项目上线后,由于权限更新导致用户无法使用旧界面+用户不懂得自己退出登录以应用新菜单权限,线上多个用户反馈平台相关功能无法使用。处理:远程操作+线上指导出现问题的用户退出登录,凌晨脚本批量强制用户退出登录。推进:在下一次版本中,推动开发处理菜单权限更新问题,以防每次更新菜单都出现用户使用不了功能的问题。结果:处理为用户登录期间仍可使用旧界面,直到用户退出重新登录后,才应用新菜单权限
● 推动冒烟:冒烟不通,测试召开会议罗列项目不通的模块、存在的问题,一一对应到每个人去跟进,得到解决的时间,后续项目群说明并艾特每个人跟进。测试准时验收
● 推动文档质量:在日常工作中遇到需求文档、设计文档、接口文档不规范或不详细的在绝大多数,这个时候就要通过沟通或以bug的形式,促使各个岗位将各自的文档完善
● 结合自己的个人经验,从问题描述+处理过程+推进表现+结果,一一说明
12、印象深刻的一个bug?
○ 隐藏得比较深的bug、影响比较大的bug、处理过程比较曲折的bug。根据自己的经验描述:如何发现的、如何处理、影响、结果、反思。
○ 举例说明:如升级版本兼容性问题、接口安全性问题、数据库安全性问题、服务器资源占用溢出问题、代码逻辑问题等
13、你们公司是不是敏捷开发?介绍一下敏捷开发?
○ 是,敏捷快速迭代、多版本同时迭代
○ 敏捷开发属于增量式开发,对于需求范围不明确、需求变更较多的项目而言可以很大程度上响应和拥抱变化、主张简单、拥抱变化、可持续性、递增的变化、高质量的工作、快速反馈、软件是你的主要目标
14、复盘会议的主要内容有哪些?
○ 这点需要结合自己平时参与的项目会议举例说明。如线上bug分析、优化改进策略、bug优先级等等
15、app的兼容性怎么测,app的接口测试怎么测?
● 系统兼容(ios、安卓)、机型兼容(iPhone、华为、小米、三星、vivo、OPPO)、分辨率兼容、软件本身向前向后兼容
● 接口测试:获取接口文档,使用fiddler抓包工具获取接口的请求方式、url、请求参数、返回参数,然后使用postman、jmeter进行测试
16、web端测试和app端测试有何不同(常见)
● 系统结构方面
○ web项目,b/s架构,基于浏览器的;web测试只要更新了服务器端,客户端就会同步会更新
○ app项目,c/s结构的,必须要有客户端;app 修改了服务端,则客户端用户所有核心版本都需要进行回归测试一遍
● 兼容方面
○ web项目:a. 浏览器(火狐、谷歌、IE等)b. 操作系统(Windows7、Windows10、Linux等)
○ app项目:a. 设备系统: iOS(ipad、iphone)、Android(三星、华为、联想等) 、Windows(Win7、Win8)、OSX(Mac)b. 手机设备可根据 手机型号、分辨率不同
● 性能方面
○ web项目 需监测 响应时间、CPU、Memory
○ app项目 除了监测 响应时间、CPU、Memory外,还需监测流量、电量等
● 相对于 Wed 项目,APP有专项测试
○ 干扰测试:中断,来电,短信,关机,重启等
○ 弱网络测试(模拟2g、3g、4g,wifi网络状态以及丢包情况);网络切换测试(网络断开后重连、3g切换到4g/wifi 等)
○ 安装、更新、卸载
■ 安装:需考虑安装时的中断、弱网、安装后删除安装文件等情况
■ 卸载:需考虑 卸载后是否删除app相关的文件
■ 更新:分强制更新、非强制更新、增量包更新、断点续传、弱网状态下更新
● 界面操作:关于手机端测试,需注意手势,横竖屏切换,多点触控,前后台切换
● 安全测试:安装包是否可反编译代码、安装包是否签名、权限设置,例如访问通讯录等
● 边界测试:可用存储空间少、没有SD卡/双SD卡、飞行模式、系统时间有误、第三方依赖(QQ、微信登录)等
● 权限测试:设置某个App是否可以获取该权限,例如是否可访问通讯录、相册、照相机等
二、测试工具篇
1、介绍一下测试中常用的工具(基础,掌握!)
○ 需求问题跟进、测试计划、风险评估登记、测试报告、复盘会议:wiki
○ 测试用例:Xmind编写,testlink管理
○ 测试执行:elk、Xshell等
○ bug管理:Jira、bugfree、禅道等
○ 接口相关:charles、fiddler、postman、jmeter等
○ 自动化相关:selenium、appium、pytest、locust、jmeter等
2、用什么工具对用例进行管理
○ testlink管理用例的一般步骤:新建计划、新建版本、上传xml文件、添加测试用例到测试计划中、分配测试用例给开发、查看用例执行报告
○ xmind:xxxxxx
○ excel:xxxxxxx
3、怎么使用elk定位日志
○ 查看产品推送是否成功。产品从A平台推送到B平台,根据A平台的链接id,搜索对应的日志。搜索不到,则为A平台推送失败。搜索到了,查看推送的状态,进一步判断问题所在。
○ 使用官方文档,可以进一步了解elk日志查看
4、Xshell如何登录,如何切换目录
○ 使用ssh密钥登录:生成密钥公钥和私钥-上传公钥到服务器-配置Xshell使用密钥认证方式登录到服务器(参考:https://www.cnblogs.com/Black-rainbow/articles/9418713.html)34
○ 使用账号密码登录:配置中输入被连接服务器的账号、密码、ip及端口连接
○
5、埋点测试怎么测试,使用什么工具,数据要不要入库
○ 使用charles、fiddler抓包,查看对应的来源记录、事件等必要参数是否正确,查看数据库记录是否正确
6、介绍fiddler和postman的区别
○ fiddler主要是抓包,postman主要进行接口请求
7、怎么使用postman进行多个接口请求?
○ 将多个接口请求归纳到一个集合里,在集合的右上角点击展开箭头,点击run
8、日常工作中jmeter是怎么用的?
○ 接口测试:通过对指定接口进行请求访问,验证数据出入的准确性与安全性
○ 性能测试:编写对应的测试集,通过脚本控制线程数,实现逐步加压等
○ 结合自己项目经验,没有经验千万不能盲目举例乱说,避免坑自己
9、例举熟悉的自动化测试工具,并说明其实现原理
○ selenium 过程如下:
ⅰ. 运行用python写好的selenium脚本,它会像web service中发送一个http请求
ⅱ. 浏览器驱动中的web service 会根据这个请求生成对应的js脚本,因为不同的浏览器,相同的操作生成的js脚本会有所不同,因此不同的浏览器要有不同的驱动
ⅲ. js脚本驱动浏览器,产生各种操作,并返回给web service
ⅳ. web service将结果通过http响应的形式返回给客户端
○ appium的加载过程
ⅰ. 调用Android adb完成基本的系统操作
ⅱ. 向Android上部署bootstrap.jar
ⅲ. bootstrap.jar Forward Android的4723端口到PC机器上
ⅳ. PC上监听端口接收请求,使用webdriver协议
ⅴ. 分析命令并通过forward 端口发给bootstrap.jar
ⅵ. bootstrap.jar接收请求并把命令发给uiautomator
ⅶ. uiautomator执行命令
三、测试管理题目
1. 如果项目周期很短,测试人力匮乏,你是怎么协调的?
答: 依据代码review的结果和影响范围,对测试内容进行适当的裁剪。
借助自动化工具的支持,提高测试案例的执行效率。
调整组内任务的优先级,进行人力协调,优先投入最紧要的项目。
必要的情况下加班
2. 你团队的测试如何进行分工?
答:业务压力大的时候,业务为主,技术为辅
业务少的时候,技术为主,业务也不丢
老人带新人,新人帮老人,选出业务领头人和技术领头人,形成团队梯队
3. 对于团队成员,你是如何打kpi的?
答: 成员自评和一对一沟通,了解成员的想法对于老黄牛类型的,吃苦卖力但是没有突破的,给中等绩效
对于老白兔类型的,混吃等死,计划淘汰
对于独狼类型的,抢食,不听指挥的,果断淘汰
对于头狼类型的,吃苦卖力,有惊喜,给优秀绩效
4、做了哪些来提升版本质量?
1.测试左移,右移
2.需求分析阶段,找出业务复杂点重点设计测试用例
3.提测要有输出,整理修改哪些功能,自测,代码检查
4.回归测试,自动化测试来辅助
5.bug回溯与分析总结
6.需求分享与总结
7.代码覆盖率检查用例是否有遗漏场景
5、如何做好软件测试管理人员?
1.具有较好的人格魅力和亲和力
2.最好具备较强的测试技术水平
3.乐意处理下属在项目中碰到的困难
4.勇于承担责任,把功劳推给测试团队
5.对下属多一些宽容和生活关心
6.力争多给下属争取福利
7.多给下属锻炼机会,培养下属能力
8.多给下属精神鼓励,奖惩公私分明
9.知人善用,用人之长,合理分工
10.较强的行业和业务知识背景
四、接口测试题目
1、如何使用抓包工具fiddler、Charles对APP抓包?
Fiddler可以抓取支持http代理的任意程序的数据包
如果要抓取https会话,要先安装证书。默认端口是8888
1.设置fiddler https
2.电脑Fiddler和手机设备需要在同一个局域网,查看电脑IP,cmd命令行执行ipconfig查看
3.设置代理IP,手机上打开无线局域网的设置
4.通过浏览器/Safari下载安装证书
5.安装了证书不是默认启用的,而是需要手动开启。设置-通用-关于本机-证书信任设置
iOS与Android的区别是:iOS需要安装证书,Android不需要
2、给你一个接口怎么测试?
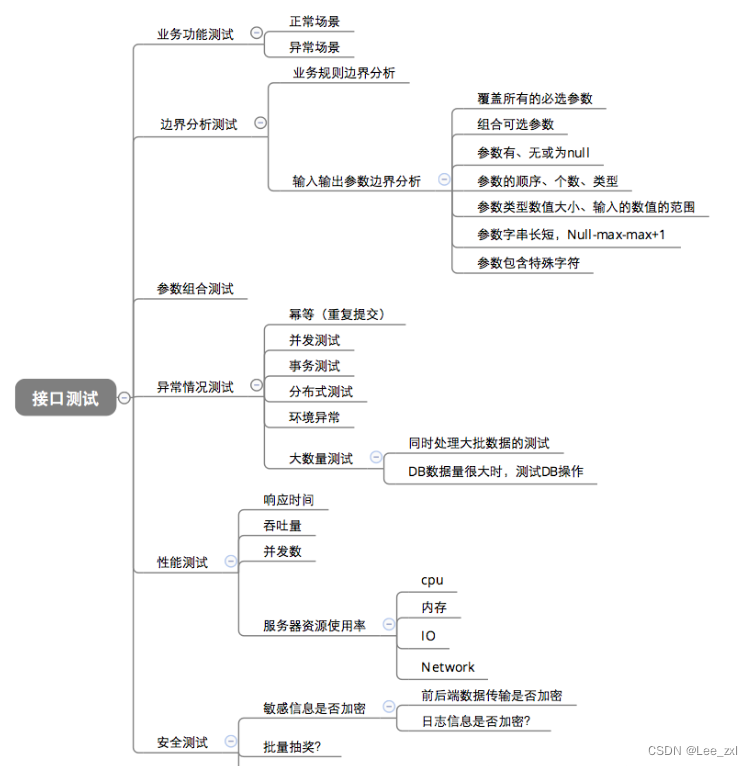
五、自动化测试题目
1、自动化测试的目的?
a.用来回归
b.用来监控系统稳定性
c.提高工作效率
2、三种等待时间的区别和应用场景?
1、强制等待sleep(10)
2、隐式等待
driver.implicitly_wait(10)
1)在每个页面加载的时候自动等待
2)一般在打开浏览器后进行声明
3)在设置等待时间内页面都没有加载完,就超时抛出异常
3、显示等待
wait = WebDriverWait(driver,10,0.5)
1)针对于某个特定的元素设置的等待时间,在设置时间内,默认每隔一段时间检测一次当前页面某个元素是否存在
2)如果在规定的时间内找到了元素,则直接执行,即找到元素就执行相关操作
3)如果超过设置时间检测不到则抛出异常。
4)默认检测频率为0.5s,默认抛出异常为:NoSuchElementException
3、之前项目做过自动化测试吗?如何进行推进的?
来源:https://testerhome.com/articles/25754
前端 UI 方面我是用 selenium 这个开源框架加上 Python 基础架构来实现自动化
实现原理:用一些单元测试框架 pytest去组织我们的测试用例
数据驱动:比如说我们用 execl 表去做一个数据驱动,然后我们用到一些关键字驱动
对你公司项目产生了什么样的价值?
成为我们公司的一个固定资产。
不管是开发、产品、运营,都会用到咱们的这个自动化脚本。可以帮我们线上监控,帮我们自动化回归,帮我们造数据,帮我们跑数据,提高了迭代效率,释放了很多人力。
4、jmeter什么是采样器(samplers)和线程组(thread group)?
线程组:对于任何测试计划,线程组元件都是 JMeter 的开始部分。这是 JMeter 的重要原件,你可以再其中设置多个用户和时间来加载线程组中给出的所有用户。
采样器:采样器生成一个或多个采样结果,这些采样结果具有许多属性,例如经过时间、数据大小等。采样器允许 JMeter 通过采样器将特定类型的请求发送到服务器,线程组决定需要发出的请求类型,一些有用的采样器包括 HTTP 请求,FTP 请求、JDBC 请求等
5、自动化测试流程?
1.编写自动化测试计划
2.设计自动化测试用例
3.编写自动化测试框架和脚本
4.调试并维护脚本
5.无人值守测试
6.后期脚本维护(添加用例、开发更新版本)
6、你觉得自动化测试的价值在哪里?你们公司为什么要做自动化测试?
引用自动化测试之后,能代替大量繁琐的回归测试工作,把业务测试人员解放出来,既而让业务测试人员把精力集中在复杂的业务功能模块上,自动化测试一般是对稳定下来的功能进行自动化,保证不会因为产品的更新导致之前稳定下来的功能出现BUG
7、什么是PO模式?
PO是Page Object 模式的简称,它是一种设计思想,意思是,把一个页面,当做一个对象,页面的元素和元素之间操作方法就是页面对象的属性和行为,PO模式一般使用三层架构,分别为:基础封装层BasePage,PO页面对象层,TestCase测试用例层。
8、自动化代码中,用到了哪些设计模式
○ 单例模式
○ 工厂模式
○ PO模式
○ 数据驱动模式
9、什么是断言
○ 检查一个条件,如果它为真,就不做任何事,用例通过。如果它为假,则会抛出AssertError并且包含错误信息。
10、UI自动化中,如何做集群
○ selenium grid,分布式执行用例
○ appium 使用stf管理多设备
○ docker+k8s管理集群
11、怎么对含有验证码的功能进行自动化测试
○ 万能验证码
○ 测试环境屏蔽验证
○ 其他操作不推荐
12、如何优化和提高selenium脚本的执行速度
○ 尽量使用by_css_selector()方法:by_css_selector()方法的执行速度比by_id()方法的更快,因为源码中by_id()方法会被自动转成by_css_selector()方法处理
○ 使用等待时,尽量使用显示等待,少用sleep(),尽量不用隐式等待
○ 尽量减少不必要的操作:可以直接访问页面的,不要通过点击操作访问
○ 并发执行测试用例:同时执行多条测试用例,降低用例间的耦合
○ 有些页面加载时间长,可以中断加载
13、接口测试能发现哪些问题
○ 可以发现很多在页面上操作发现不了的 bug
○ 检查系统的异常处理能力
○ 检查系统的安全性、稳定性
○ 前端随便变,接口测好了,后端不用变
○ 可以测试并发情况,一个账号,同时(大于 2 个请求)对最后一个商品下单,或不同账号,对最后一个商品下单
○ 可以修改请求参数,突破前端页面输入限制(如金额)
14、selenium 中隐藏元素如何定位?
○ 如果单纯的定位的话,隐藏元素和普通不隐藏元素定位没啥区别,用正常定位方法就行了,这个很多面试官也搞不清楚
○ 元素的属性隐藏和显示,主要是 type="hidden"和 style="display: none;"属性来控制的,接下来在元素属性里面让它隐藏,隐藏元素可以正常定位到,只是不能操作(定位元素和操作元素是两码事,很多初学者傻傻分不清楚),操作元素是 click,clear,send_keys 这些方法
○ JS 操作隐藏元素
15、如何判断一个页面上元素是否存在?
○ 方法一:用 try…except…
○ 方法二:用 elements 定义一组元素方法,判断元素是否存在,存在返回 True,不存返回 False
○ 方法三:结合 WebDriverWait 和 expected_conditions 判断(推荐)
16、如何提高脚本的稳定性
○ 不要右键复制 xpath(十万八千里那种路径,肯定不稳定),自己写相对路径,多用 id 为节点查找
○ 定位没问题,第二个影响因素那就是等待了,sleep 等待尽量少用(影响执行时间)
○ 定位元素方法重新封装,结合 WebDriverWait 和 expected_conditions 判断元素方法,自己封装一套定位元素方法
17、如何定位动态元素
○ 动态元素有 2 种情况,一个是属性动态,比如 id 是动态的,定位时候,那就不要用 id 定位就是了
○ 还有一种情况动态的,那就是这个元素一会在页面上方,一会在下方,飘忽不定的动态元素,定位方法也是一样,按 f12,根据元素属性定位(元素的 tag、name的步伐属性是不会变的,动的只是 class 属性和 styles 属性)
18、如何通过子元素定位父元素
○ 使用element.parent方法
19、平常遇到过哪些问题? ?如何解决的
○ 可以把平常遇到的元素定位的一些坑说下,然后说下为什么没定位到,比如动态id、有 iframe、没加等待等因素
20、一个元素明明定位到了,点击无效(也没报错),如果解决?
○ 使用 js 点击,selenium 有时候点击元素是会失效
21、**测试的数据你放在哪? **
○ 对于账号密码,这种管全局的参数,可以用命令行参数,单独抽出来,写的配置文件里(如 ini)
○ 对于一些一次性消耗的数据,比如注册,每次注册不一样的数,可以用随机函数生成
○ 对于一个接口有多组测试的参数,可以参数化,数据放 yaml,text,json,excel都可以
○ 对于可以反复使用的数据,比如订单的各种状态需要造数据的情况,可以放到数据库,每次数据初始化,用完后再清理
○ 对于邮箱配置的一些参数,可以用 ini 配置文件
○ 对于全部是独立的接口项目,可以用数据驱动方式,用 excel/csv 管理测试的接口数据
○ 对于少量的静态数据,比如一个接口的测试数据,也就 2-3 组,可以写到 py脚本的开头,十年八年都不会变更的
22、什么是数据驱动,如何参数化?
○ 参数化的思想是代码用例写好了后,不需要改代码,只需维护测试数据就可以了,并且根据不同的测试数据生成多个用例
23、其他接口都需要登录接口的信息,怎么去让这个登录的接口只在其他接口调用一次
○ 使用单例模式
○ 使用自定义缓存机制
○ 使用测试框架中的setup机制
○ pytest中fixture机制
24、接口产生的垃圾数据如何清理
○ 造数据和数据清理,需用 python 连数据库了,做增删改查的操作测试用例前置操作,setUp 做数据准备后置操作,tearDown 做数据清理
25、怎么用接口案例去覆盖业务逻辑?
○ 考虑不同的业务场景,一个接口走过的流程是什么样的,流程的逻辑是什么样的,什么样的参数会有什么样的结果,多场景覆盖
六、性能测试题目
1、做性能测试,你需要关注哪些指标?
1.从用户角度出发响应时间
2.站在管理员的角度考虑需要关注的性能点
(1)、 响应时间
(2)、 服务器资源使况是否合理
(3)、 应用服务器和数据库资源使用是否合理
(4)、 系统能否实现扩展
(5)、 系统最多支持多少用户访问、系统最大业务处理量是多少
(6)、 系统性能可能存在的瓶颈在哪里
(7)、 更换那些设备可以提高性能
(8)、 系统能否支持7×24小时的业务访问
3.站在开发(设计)人员角度去考虑
(1)、 架构设计是否合理
(2)、 数据库设计是否合理
(3)、 代码是否存在性能方面的问题
(4)、 系统中是否有不合理的内存使用方式
(5)、 系统中是否存在不合理的线程同步方式
(6)、 系统中是否存在不合理的资源竞争
4.站在测试工程师角度考虑
(1)连接超时
(2)崩溃
(3)系统交互
(4)弱网下的运行情况
(5) CPU使用问题
2、java语言的服务性能测试的时候,用什么命令打印线程栈信息?
jstack
3、性能测试指标包括哪些
○ 最大并发用户数,HPS(点击率)、事务响应时间、每秒事务数、每秒点击量、吞吐量、CPU使用率、物理内存使用、网络流量使用等。
○ 前端需主要关注的点是:
■ 响应时间:用户从客户端发出请求,并得到响应,以及展示出来的整个过程的时间。
■ 加载速度:通俗的理解为页面内容显示的快慢。
■ 流量:所消耗的网络流量。
○ 后端需主要关注的是:
■ 响应时间:接口从请求到响应、返回的时间。
■ 并发用户数:同一时间点请求服务器的用户数,支持的最大并发数。
■ 内存占用:也就是内存开销。
■ 吞吐量(TPS):Transaction Per Second, 每秒事务数。在没有遇到性能瓶颈时:TPS=并发用户数*事务数/响应时间。
■ 错误率:失败的事务数/事务总数。
■ 资源使用率:CPU占用率、内存使用率、磁盘I/O、网络I/O。
■ 从性能测试分析度量的度角来看,主要可以从如下几个大的维度来收集考察性能指标:
■ 系统性能指标、资源性能指标、稳定性指标
4、如果一个需求没有明确的性能指标,要如何开始进行性能测试?
○ 先输出业务数据,如pv、pu、时间段等,计算出大概的值,然后不断加压测到峰值
5、介绍JMeter聚合报告包括哪些内容
○ 请求名、线程数、响应时间(50 95 99 最小 最大)错误率、吞吐量
6、如果有一个页面特别卡顿,设想一下可能的原因
○ 后台:接口返回数据慢,查询性能等各种问题
○ 前端:使用chrome工具调试,判断js执行久或是其他问题
○ 网络问题
7、说一说项目中的实际测试内容
○ 根据自己项目中的经验实话实说,有没有经验很容易露馅
8、介绍一下JMeter进行性能测试的过程
○ www.baidu.com98
9、介绍一下JMeter和LoadRunner的区别
○ www.baidu.com98
七、安全测试题目
八、测试框架搭建
九、python面试题
1、python 装饰器,作用,用法
python的装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。简单的说装饰器就是一个用来返回函数的函数。
它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
什么是装饰器语法糖?
python提供了@符号作为装饰器的语法糖,使我们更方便的应用装饰函数。但使用语法糖要求装饰函数必须return一个函数对象
2、python 的垃圾回收机制?
Python 中的垃圾回收机制中有三部分内容:“引用计数”、“标记 - 清除”、“分代回收”
来源:https://testerhome.com/topics/29769
3、python中类方法,类实例方法,静态方法的区别
○ 实例方法:由对象调用;至少一个self参数;执行普通方法时,自动将调用该方法的对象赋值给self;
○ 类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类复制给cls;
○ 静态方法:由类调用;无默认参数;
4、dict和tuple及list的区别(这里列的是主要区别,面试足够)
○ tuple是不可变对象,list和dict都是可变对象,这里的不可变指的是指向地址不可变
○ list是有序的,dict是无序的,不可存放有序集合
○ dict查找速度快,不管有多少个元素时间都一样,list查找速度慢,需要有序查找
○ dict的key为不可变对象,且不可重复,list则可以重复,存放任意对象
5、json和dict的区别
○ json是一种数据格式,纯字符串。dict是一种完整的数据结构
○ dict是一个完整的数据结构,是对Hash Table这一数据结构的一种实现,是一套从存储到提取都封装好了的方案。它使用内置的哈希函数来规划key对应value的存储位置,从而获得O(1)的数据读取速度。
○ json的key只能是字符串,python的dict可以是任何可hash对象(不可变对象)
○ json的key可以是有序、可重复的;dict的key不可重复,且无序。
○ json任意key存在默认值undefined,dict默认没有默认值
○ json访问方式可以是[],也可以是.,遍历方式分in、of;dict的value仅可以下标访问
○ dict可以嵌套tuple,json里只有数组
6、python会不会出现内存泄漏,为什么
○ 当对象之间互相引用的时候再删除的时候,可能会造成无法释放对象的情况,出现泄漏
○ 上面为个人了解,如有其它请补充
7、python的同步和异步
○ 直接得到最终结果的结果,就是同步调用。
○ 不直接得到的最终的结果,就是异步调用。
○ 同步与异步区别在于:调用者是否得到了想要的最终结果。
8、常见手撕代码
十、数据库面试题
1、mysql 删除语句有哪些?
1)drop 语句,用来删除数据库和表:例子【drop database db;drop table tb】、
2)delete 语句,用来删除表中的字段:例子【delete from tb where id=1】
3)用 truncate 来删除表中的所有字段:例子【truncate table tb】
2、数据库事务、主键与外键的区别?
数据库的事务:
事务即用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的工作单位,
它具有四个特性,ACID,原子性,一致性,隔离性,持续性
主键和外键的区别:
1、主键是能确定一条记录的唯一标识,不能重复,能唯一确定该条数据;
2、外键用于与另一张表的关联,是能确定另一张表记录的字段,用于保持数据的一致性
3、工作中常使用的SQL语法有哪些?
○ create table、create view、 select from where、insert into、update set values、delete、alter、order by、having
4、数据库存储过程
○ 一组数据库操作命令,当作是自己写的一个方法,一系列步骤自己去封装(个人理解)
5、SQL常见查询语句编写
(此处仅举例常见的查询语句,如有更多坑,希望补充)
○ 查询所有学生的数学成绩,显示学生姓名 name, 分数, 由高到低。SELECT a.name, b.score FROM student a, grade b WHERE a.id = b.id AND kemu = ‘数学’ ORDER BY score DESC;
○ 统计每个学生的总成绩(由于学生可能有重复名字),显示字段:学生 id,姓名,总成绩。SELECT a.id, a.name, c.sum_score from student a, (SELECT b.id, sum(b.score) as sum_score FROM grade b GROUP BY id) c WHERE a.id = c.id ORDER BY sum_score DESC;
○ 列出各门课程成绩最好的学生, 要求显示字段: 学号,姓名,科目,成绩SELECT c.id , a.name, c.kemu, c.score FROM grade c, student a,(SELECT b.kemu, MAX(b.score) as max_score FROM grade b GROUP BY kemu) t WHERE c.kemu = t.kemu AND c.score = t.max_score AND a.id = c.id
6、慢查询是什么意思?
○ 开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
7、导致数据库性能差的可能原因有哪些?
○ 硬件环境问题,如磁盘IO
○ 查询语句问题,如join、子查询、没建索引
○ 索引失效,建了索引,查询的时候没用上
○ 查询关联了太多的join
○ 服务器关联缓存,线程数等
○ 表中存在冗余字段,在生成笛卡尔积时耗费多余的时间
8、redis缓存应用场景
○ 需要将数据缓存在内存中,提升查询效率
○ 本人没经验,希望补充
9、怎么定位redis缓存失效问题(缓存坏了)
○ 不知道,看不懂
十一、shell和liunx面试题
1、介绍Linux管道?
举例:ls -a | grep mysql
说明:就是把前一个命令的结果当成后一个命令的输入。结合本例就是先显示所有的文件,然后再用grep命令在ls的结果中查找包含mysql的文件
2、工作中常用的Linux命令有哪些?
○ awk、sed、vim、iotop、dstat、cp、top、ifconfig、pwd、cd、ll、ls、cat、tail、grep、mv、rm、mkdir、df、du
3、什么命令可以帮助Linux执行Windows上传的脚本
○ 改变编码格式
○ vim test.sh
○ :set ff?// 显示dos的话
○ :set ff=unix:wq
4、简述linux三剑客
○ grep命令:根据用户指定的模式pattern对目标文本进行过滤,显示被模式匹配到的行,grep [options] pattern [file],常用参数:
■ -v 显示不被pattern匹配到的行
■ -i 忽略字符的大小写
■ -n 显示匹配的行号
■ -c 统计匹配的行数
■ -o 仅显示匹配到的字符串
■ -E 使用ERE,相当于egrep(可以识别更多的正则表达式规则)
○ sed:流编辑器,用来处理一行数据。将一行数据存储在模式空间中->用sed命令处理->送入屏幕->清空空间,常用参数:
■ -h 显示帮助
■ -n 仅显示script处理后的结果
■ -e 指定的脚本来处理输入的文本文件
■ -f 以指定的脚本文件来处理
■ 常用动作
● a: 新增 sed -e ‘4 a newline’
● c: 取代 sed -e ‘2,5c No 2-5 number’
● d: 删除 sed -e ‘2,5d’
● i: 插入 sed -ed ‘2i newline’
● p: 打印 sed -n ‘/root/p’
● s: 取代 sed -e ‘s/old/new/g’
● g: 代表全局
○ awk:把文件逐行的读入,以空格为默认分隔符将每行切片。 把行作为输入,并赋值给$0->将行切段,从$1开始->对行匹配正则/执行动作->打印内容,awk ‘pattern + action’ [filenames],常用语法:
■ filename awk浏览的文件名
■ begin 处理文本前要执行的操作
■ end 处理文本之后要执行的操作
■ fs 设置输入域分隔符,等价于命令行-F选项
■ nf 浏览记录的域的个数(列数)
■ nr 已读的记录数(行数)
■ 常用参数
● ofs 输出域分隔符
● ors 输出记录分隔符
● rs 控制记录分隔符,换行标志
● $0 整条记录
● $1 第一条分隔后的记录
5、如何通命令定位Linux服务器下的日志?
○ 如果要监控日志,那么使用tail -f | grep xxx命令,过滤需要的字段
○ 如果在完整日志中查看内容,使用cat xxx.log | grep xxxx | awk '{print $1}'等命令过滤自己需要的内容
6、简述项目中的环境搭建和维护
○ 结合自身经验先从系统安装开始,如常用的centos和Ubuntu说起,系统安装主要是磁盘分区和磁盘阵列问题
○ 基础环境依赖,如MySQL、Redis、jenkins、docker、项目中用到的其他依赖环境等
○ 维护方便主要从遇到的错误说起,如无法远程连接、服务器加固等
十二、计算机网络面试题
1、七层模型有哪些,分别有哪些协议?
1)应用层包含的主要协议:
FTP(文件传送协议)、
Telnet(远程登录协议)、
DNS(域名解析协议)、
SMTP(邮件传送协议),
POP3协议(邮局协议),
HTTP协议(Hyper Text Transfer Protocol)
2)表示层
3)会话层
4)传输层
包含的主要协议:
TCP协议(Transmission Control Protocol,传输控制协议)、
UDP协议(User Datagram Protocol,用户数据报协议);
重要设备:网关
5)网络层
包含的主要协议
IP协议(Internet Protocol,因特网互联协议);
ICMP协议(Internet Control Message Protocol,因特网控制报文协议);
ARP协议(Address Resolution Protocol,地址解析协议);
RARP协议(Reverse Address Resolution Protocol,逆地址解析协议)
6)数据链路层
数据链路层为网络层提供可靠的数据传输
主要的协议:以太网协议
基本数据单位为:帧
两个重要设备名称:网桥和交换机
7)物理层
中继器(Repeater,也叫放大器)和集线器
2、HTTP网络请求返回码分别表示?
● 1xx(临时响应)
● 2xx (成功)
● 3xx (重定向)
● 4xx(请求错误)
● 5xx(服务器错误)
来源:https://blog.csdn.net/G_spring/article/details/85071737
3、输入url到网页显示出来的全过程
a. 输入网址
b. DNS解析
c. 建立tcp连接
d. 客户端发送HTTP请求
e. 服务器处理请求
f. 服务器响应请求
g. 浏览器展示HTML
h. 浏览器发送请求获取其他在HTML中的资源。
4、http和https的区别
○ https里面是要有证书的,http并没有证书,证书的作用是证明你是这个网站的拥有者,谁去证明,最顶级的CA去帮你证明,这些顶级的CA都是浏览器、操作系统本身就自动帮你集成,而且自动添加到设置信任里面去
○ https要兼顾安全+性能的方面,由于对称式加密虽然速度很快,但是安全性特别的低,因为双方要规定对称式加密的秘钥,别人都无法知道,但你怎么能确保别人不知道你的秘钥呢,因此需要有非对称式加密去保证安全,但非对称式加密速度又很慢,如果客户端和服务器端都用非对称式加密,网络得卡死了。所以当双方建立好了非对称加密后,再约定一个随机数,等大家都非对称解密了之后呢,就拿到只有对方知道的唯一随机数(秘钥),就可以用秘钥来进行对称式加密和解密了
5、HTTP的报文结构
○ HTTP请求报文:一个HTTP请求报文由请求行、请求头部、空行和请求数据4个部分组成
○ HTTP响应报文:HTTP响应也由三个部分组成,分别是:状态行、消息报头、响应正文
6、htt常见的响应状态码
○ 200 请求已成功,请求所希望的响应头或数据体将随此响应返回。
○ 201 请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其 URI 已经随 Location 头信息返回
○ 202 服务器已接受请求,但尚未处理
○ 301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
○ 302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
○ 303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
○ 304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。 305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
○ 307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
○ 401 当前请求需要用户验证。如果当前请求已经包含了 Authorization 证书,那么 401 响应代表着服务器验证已经拒绝了那些证书
○ 403 服务器已经理解请求,但是拒绝执行它。与 401 响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交
○ 404 请求失败,请求所希望得到的资源未被在服务器上发现
○ 500 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器的程序码出错时出现。
○ 501 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
○ 502 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
○ 503 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。
7、cookie和session机制的区别
○ cookies 数据保存在客户端,session 数据保存在服务器端;
○ cookies 可以减轻服务器压力,但是不安全,容易进行 cookies 欺骗;
○ session 较安全,但占用服务器资源
8、TCP和UDP的区别
○ TCP:面向连接,可靠的,速度慢,效率低
○ UDP:无连接、不可靠、速度快、效率高
9、TCP为什么是三次握手和四次挥手
○ 三次握手能保证数据可靠传输又能提高传输效率。若握手是两次:如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认。
○ 要保证双方都关闭了连接。因为TCP是全双工的,就是要等到两边都发送fin包确认双方都没有数据传输后才关闭
10、TCP为什么最后挥手后会有time_wait
○ 为了保证可靠的断开TCP的双向连接,确保足够的时间让对方收到ACK包。若客户端回复的ACK丢失,server会在超时时间到来时,重传最后一个fin包,处于TIME_WAIT状态的client可以继续回复Fin包,发送ACK。
○ 保证让迟来的TCP报文段有足够的时间被识别和丢弃,避免新旧连接混淆。有些路由器会缓存没有收到的数据包,如果新的连接开启,这些数据包可能就会和新的连接中的数据包混在一起。连接结束了,网络中的延迟报文也应该被丢弃掉,以免影响立刻建立的新连接。
11、简要说明http请求中的post和get有哪些区别的地方
○ 请求头多了content-length和content-type字段
○ post可以附加body,可以支持form、json、xml、binary等各种数据格式
○ 行业通用规范
○ 无状态变化的建议使用get
○ 数据的写入与状态的修改建议使用post
○ 基于http协议:都是请求返回数据,get将请求体放在头上,只发一次请求,post将请求体放在内部,需要发送两次请求
○ GET 在浏览器回退时是无害的,而 POST 会再次提交请求。
○ GET 请求会被浏览器主动 cache,而 POST 不会,除非手动设置。
○ GET 请求只能进行 url 编码,而 POST 支持多种编码方式。
○ GET 请求在 URL 中传送的参数是有长度限制的,而 POST 么有。
○ 对参数的数据类型,GET 只接受 ASCII 字符,而 POST 没有限制。
○ GET 比 POST 更不安全,因为参数直接暴露在 URL 上,所以不能用来传递敏感信息。
12、如果一个请求,返回的状态码是200,但是没有内容,可能发生了什么?
○ 请求头缺失或错误
○ 参数length不符
十三、10大灵魂拷问
1、自己的优点和缺点
○ 避开岗位的核心技能
○ 把缺点放在场景中描述
○ 对缺点进行合理化解释
○ 优点随便说,主要方向还是在岗位上
2、是否能接受加班,建议分情况作答
○ 第一种情况:假设公司有重要的项目要赶。示范回答:贵公司现在正处于发展上升期,也在官网上有看到公司的重要项目成果,我觉得有时候因为赶项目进度、工作需要等忙起来是非常正常的,面对这种情况,我是非常愿意配合公司和团队的工作,让工作能够更顺利地完成,此外,我也相信自己一定能在公司安排的工作中获得到锻炼,获得更快地成长。
○ 第二种情况:假设自己作为新人,对业务不熟悉。示范回答:我作为公司刚进去的新人,可能刚开始进入公司接触业务时不太熟练,会出现需要加班的情况,但我更愿意提高工作效率,并积极向公司的前辈请教学习,在一定的时间内完成工作而不是拖到下班之后。当然, 如果有紧急的事情,忙起来需要加班也是可以接受的。
3、薪酬的要求
○ 薪资并不是我求职的唯一标准,我上家公司基本在A~B 之间(建议合理提高,避免部分HR压价)
○ 我来贵司求职的主要动机是兴趣,这份工作是我喜欢做的,也相信自己可以胜任,更相信公司会给出一个合理的薪酬。
○ 相比薪酬,我更在意的是收入,所以,我很愿意了解贵司的薪酬架构,可以简单介绍下吗?
○ 我希望薪资可以达到**,据我了解,贵司这个岗位薪资范围是A~B ,而结合岗位职责及任职要求,我对自己也进行了相应评估,也愿意接受贵司的下一步考核。
4、未来5年的职业规划
○ 自我认知。对自己是否了解,了解是不是靠谱。
○ 动机和价值观。你是否能接受我们并不一定能给你公平的职业发展机会这个现实?
○ 组织承诺。你到底能在我们这踏实的干几年?
5、我们为什么要聘用你
○ 描述应聘岗位的胜任条件,强调自己的工作能力和工作经验跟岗位的匹配度,岗位要求的工作技能是否自己掌握了,掌握的程度是怎样的,最好在面试中说出来。因此,在面试前最好是要针对应聘岗位,把自己胜任的条件一一列出来,做到知己知彼。可以谈论一下自己之前的工作情况,用成绩、用数据来说明自己的成就。
○ 描述自己能为公司做出什么贡献,公司是一个讲究利益的地方,聘用你肯定要你为公司做出贡献。那么你在回答这个问题时,就需要说出你的加入可以为公司带来什么,这非常重要。因此,一定要明确你的工作目标和职业规划,表明你的立场和专业程度,让HR信任你。
○ 描述出自身的优势。公司为何要聘用你,而不聘用别人,肯定是你有比别人优秀的地方。那么在回答这个问题时,就一定要说出自己与众不同的地方,最好是要举一个例子,来支持你的观点。
○ 建立个人和公司的联系,HR想要得到一个怎样的答案呢?无非就是想通过这个问题,来进一步了解你各方面的信息,以及看看你为这次面试做了多少功课。那么在面试前,你最好是要尽可能获取有关公司可行业的资料信息。在回答的时候,结合自己所做的功课,建立个人和公司的联系,说明自己在哪一方面能够匹配公司的要求。HR看到你对应聘岗位这么了解,肯定会对你有好感。
○ 说出你对这份工作的兴趣以及热情
6、对我们公司有多少了解
○ 实时回答就好,知道多少就说多少,一般去面试对这个公司的了解都是从网上查到的,不会太深入
7、为什么愿意到我们公司
○ 有所准备,了解公司
○ 个人目标要与公司目标一致
○ 强调你能如何为公司提高价值
8、与领导意见不一致时,该如何处理
○ 不要假设我已经完全的掌握了对这件事的认知。向领导询问确认自己有可能缺失的信息。要寻找对领导没有告知的信息,和领导不能透露的信息。
○ 不要假设领导已经完全的掌握了我对这件事的认知。检查一下,是否已经将事情的前因后果,自己对事情的理解,明确清晰的传达给了领导,以及,他是否真的已经明确了解。
○ 在进行有效的认知沟通后,重新思考整件事情。如果意见还是有不一致,那么:
■ 按领导要求执行。不理解,也执行,在执行中理解。
■ 执行过程中,收集反馈,不断调整,提升认知。
■ 执行完成后,及时复盘,回顾决策和行动过程,沉淀知识。
9、缺乏工作经验,如何胜任这份工作
○ 承认工作经验的重要性。这样能带给面试官的印象是:该位候选人认知能力较强,具有理性思维与客观公正的处事态度及判断能力,尤其是对于自己也能客观公正地看待,勇于承认自己的缺失。
○ 突显个人优势。用自己的其他优势特长来补足经验上的不足,比如说记忆力好、动手能力强、语言能力强、学习能力强等。
○ 强调自己会不断提高工作能力。切忌用假大空的话,要用具体的与工作相关的事例或是数据来说明自己的学习力。
10、工作中与同事发生争执,如何处理
○ 在沟通之前,做好充分的准备
○ 学会认知倾听,让别人把话说完
○ 借用一些工具,来解决交流障碍
十四、反问面试官
1、职责
○ 团队中初级和高级人眼如何平衡
○ 针对员工有哪些培训和提升计划
2、技术
○ 公司内部的技术栈
○ 产品的架构
○ 版本控制及迭代速度
○ 服务器管理权限,本机家算计管理权限
3、团队
○ 团队内和团队之间如何沟通
○ 遇到了分歧如何解决
○ 团队正在经历的尚未解决的挑战是什么
○ 绩效考核是如何算的
4、公司
○ 晋升机会
○ 是否有自己的学习资源
○ 假期,加班工资等
○ 过去半年最糟糕的一天是怎么样的
○ 是什么让你来到并留在这里
○ 是否能够平衡工作与生活
福利
为方便大家自学软件测试,分享更多测试资料
主体内容包含:测试面试题,功能测试、性能测试、自动化测试等学习知识内容。
软件测试自学资料包领取

