
- 1探索Python数据容器之乐趣:列表与元组的奇妙旅程!
- 2RabbitMQ-Plugin configuration unchanged_enabling plugins on node rabbit@laptop-04itchu3: r
- 33_2Linux中内核级加强型火墙的管理
- 4记录一次mysql慢查询的优化过程
- 5美团团购订单系统优化记_团购订单系统的主要用户和作用
- 6C++轻量级界面开发框架ImGUI介绍
- 7LLMNR和NetBIOS欺骗攻击分析及防范_禁用netbios后会怎样
- 8H3C交换机ACL的单向访问解决方案_h3c 接口acl单向访问
- 9RK3568 OpenHarmony3.2 ADC按键驱动适配_open harmony 键盘驱动
- 10Windows环境部署安装Chatglm2-6B-int4
【大数据基础】Hadoop3.1.3安装教程_hadoop3.1.3安装详细步骤
赞
踩
来源:
https://dblab.xmu.edu.cn/blog/2441/
前言:重装解决一切bug!事实上,问题中的绝大部分衍生问题都可以通过重装解决。
实验内容
创建Hadoop用户
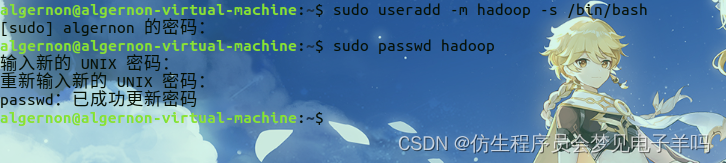
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash
- 1
接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop
- 1
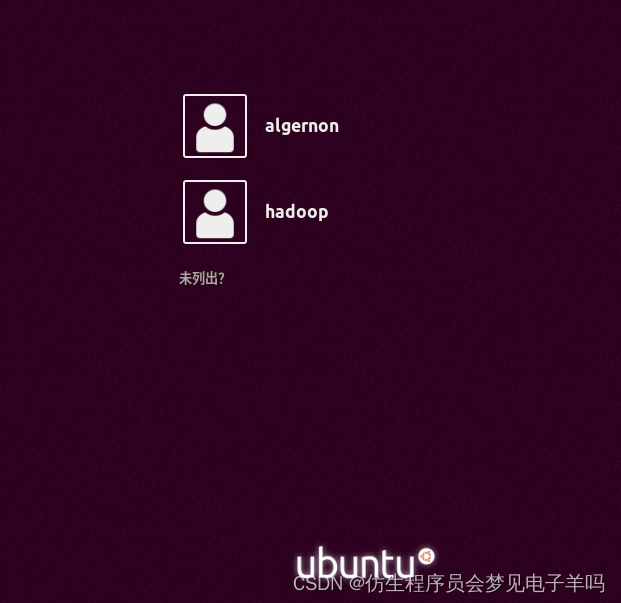
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
sudo adduser hadoop sudo
- 1



换源
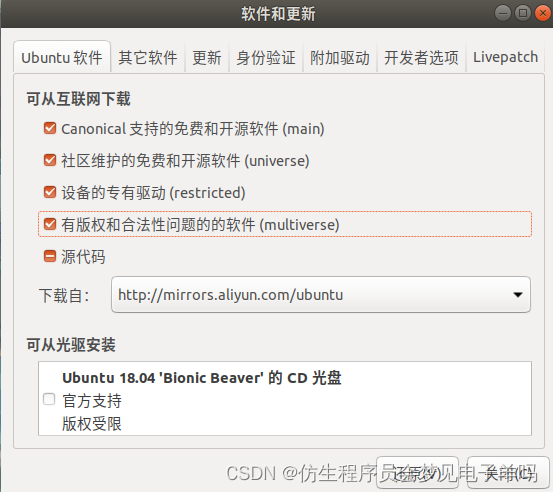
安装最强(bushi)编辑器vim
sudo apt-get install vim
- 1

vim的常用模式有分为命令模式,插入模式,可视模式,正常模式。本教程中,只需要用到正常模式和插入模式。二者间的切换即可以帮助你完成本指南的学习。
正常模式
正常模式主要用来浏览文本内容。一开始打开vim都是正常模式。在任何模式下按下Esc键就可以返回正常模式
插入编辑模式
插入编辑模式则用来向文本中添加内容的。在正常模式下,输入i键即可进入插入编辑模式
退出vim
如果有利用vim修改任何的文本,一定要记得保存。Esc键退回到正常模式中,然后输入:wq即可保存文本并退出vim
安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
- 1

安装后,可以使用如下命令登陆本机:
ssh localhost
- 1
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
- 1
- 2
- 3
- 4

~的含义: 在 Linux 系统中,~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,则 ~ 就代表 “/home/hadoop/”。 此外,命令中的 # 后面的文字是注释,只需要输入前面命令即可。
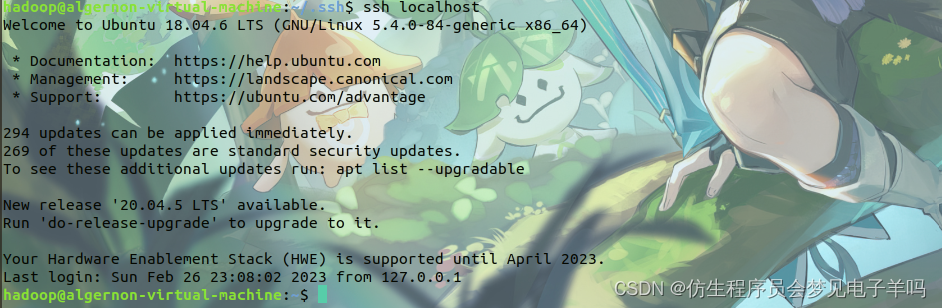
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。
安装java环境
在Linux命令行界面中,执行如下Shell命令(注意:当前登录用户名是hadoop):
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
- 1
- 2
- 3
- 4
- 5
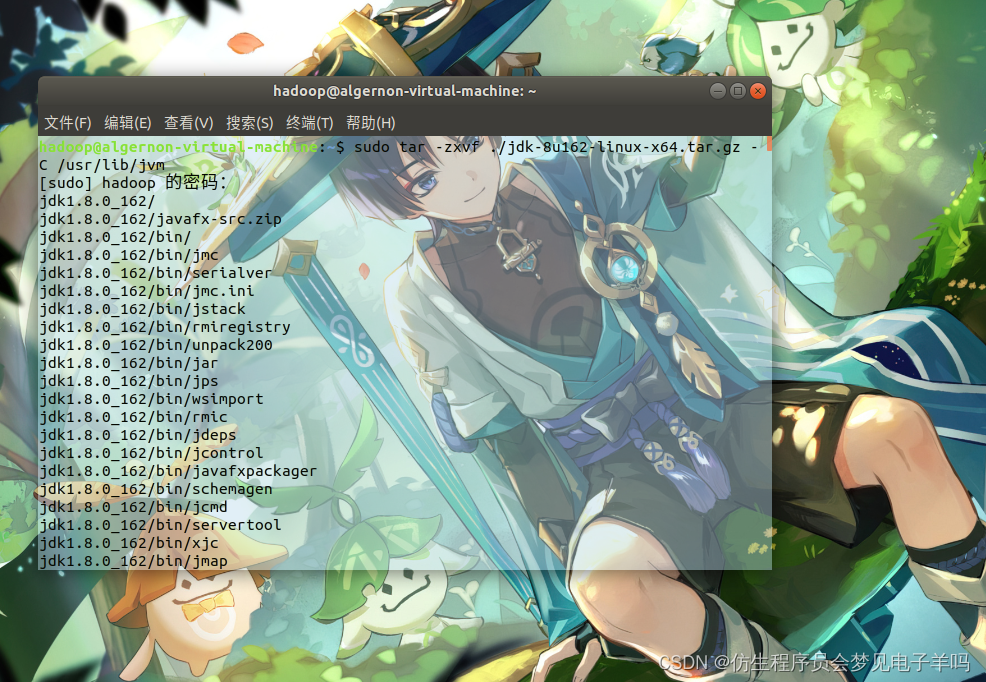

JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
cd /usr/lib/jvm
ls
- 1
- 2

可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_162目录。
下面继续执行如下命令,设置环境变量:
cd ~
vim ~/.bashrc
- 1
- 2
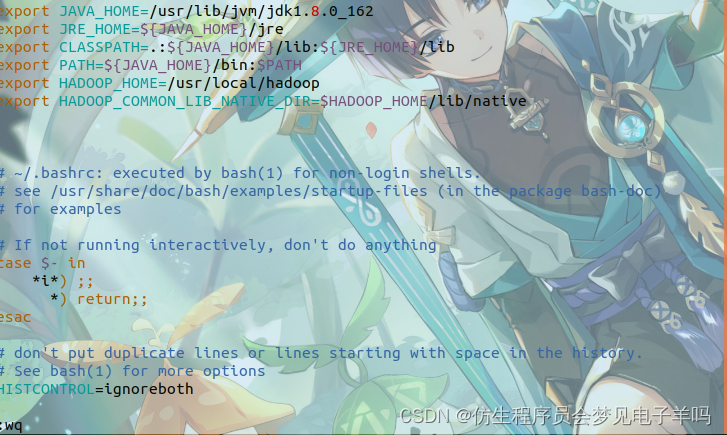
用vim打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
- 1
- 2
- 3
- 4
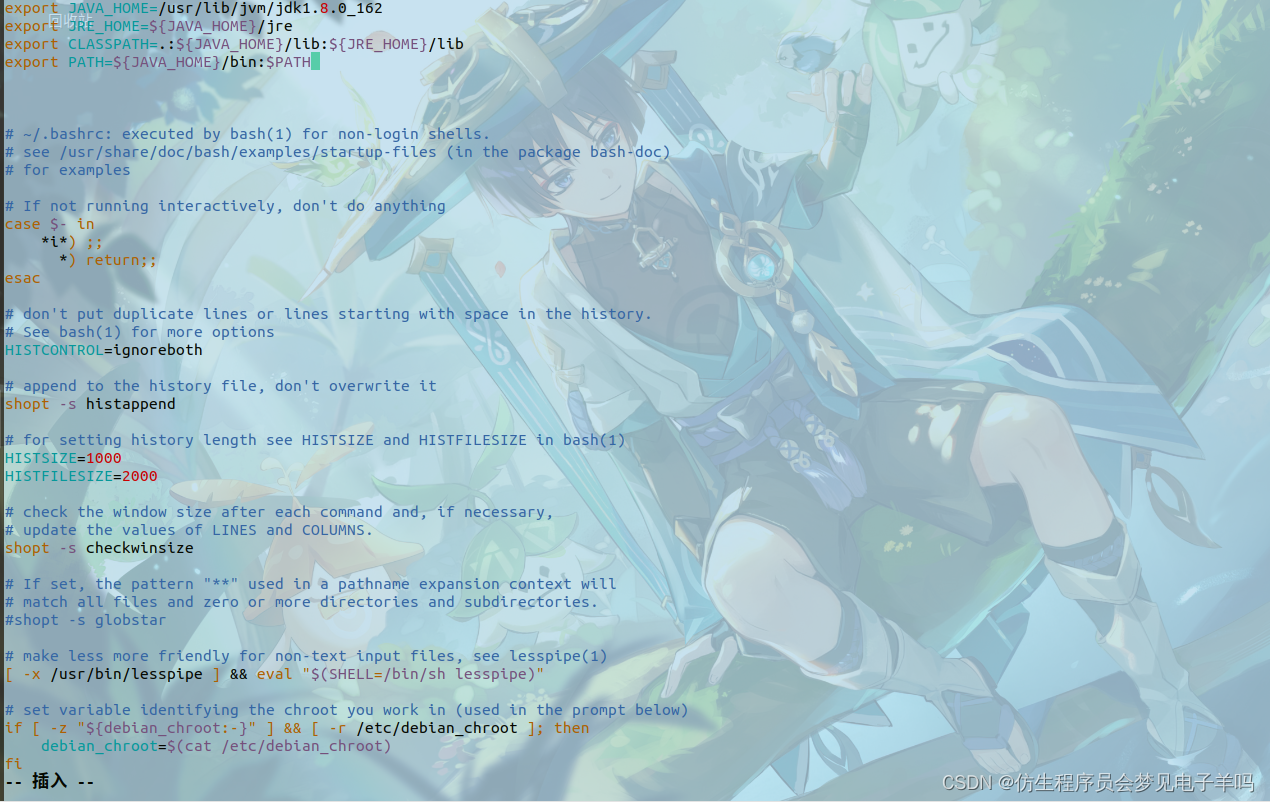
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
- 1
这时,可以使用如下命令查看是否安装成功:
java -version
- 1
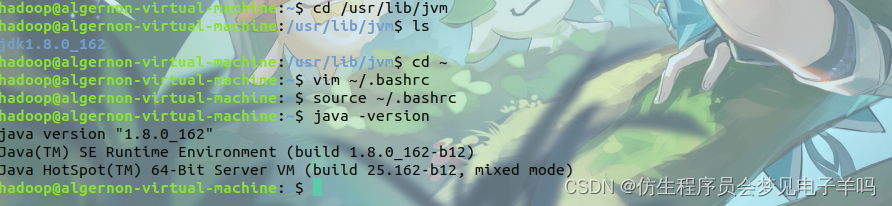
至此,就成功安装了Java环境。下面就可以进入Hadoop的安装。
安装 Hadoop3.1.3
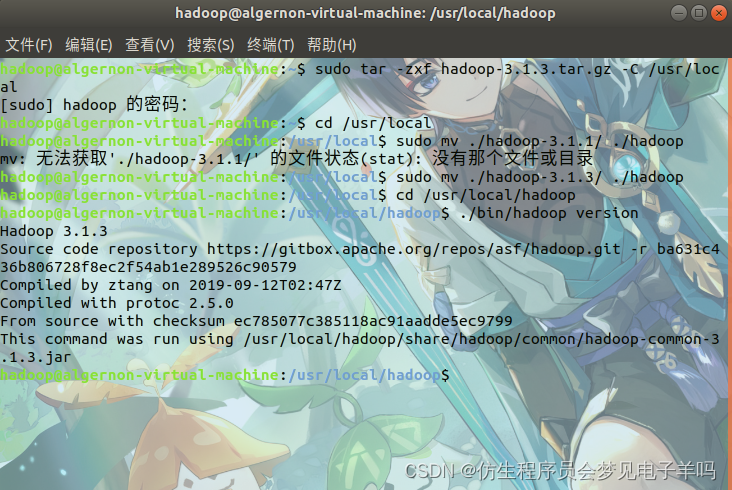
在这里最好将hadoop解压出的文件备份,这样如果后续安装出了问题便于重新配置。
sudo tar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
- 1
- 2
- 3
- 4
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
- 1
- 2
Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
- 1
- 2
- 3
- 4
- 5

执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词 dfsadmin 出现了1次
重装解决一切烦恼:

注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
rm -r ./output
- 1
Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
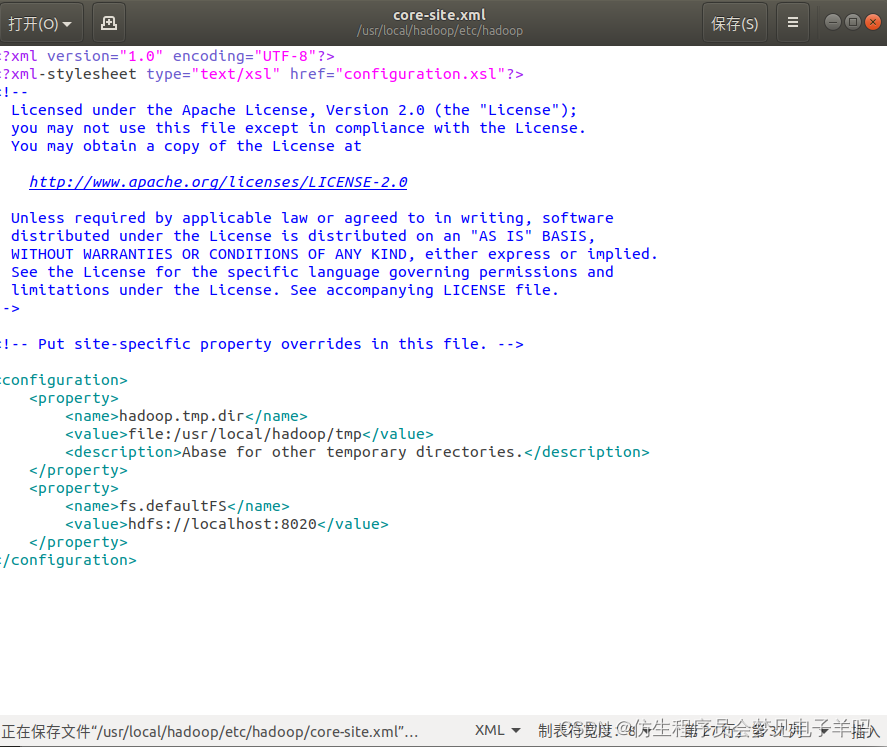
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
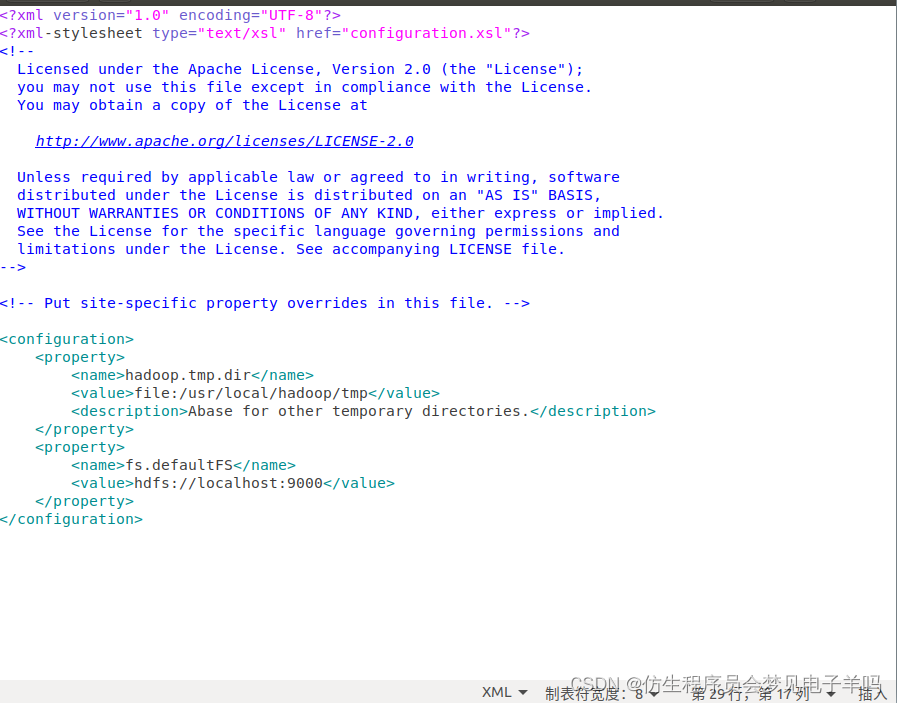
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),将当中的
<configuration>
</configuration>
- 1
- 2
修改为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
gedit ./etc/hadoop/core-site.xml
- 1
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
同样的,修改配置文件 hdfs-site.xml:
gedit ./etc/hadoop/hdfs-site.xml
- 1
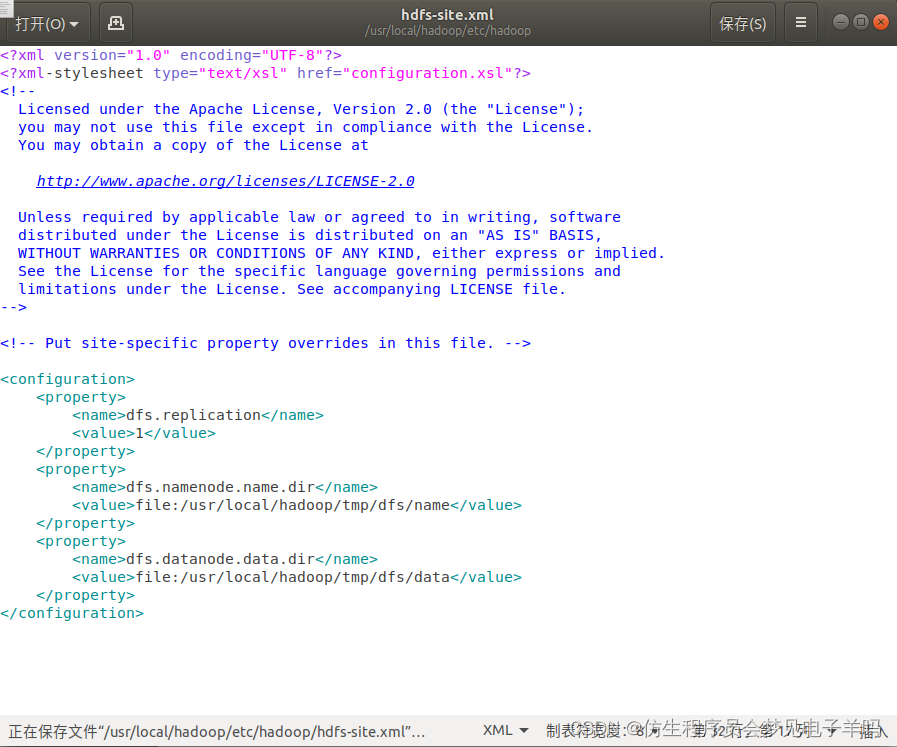
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Hadoop配置文件说明:
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
- 1
- 2


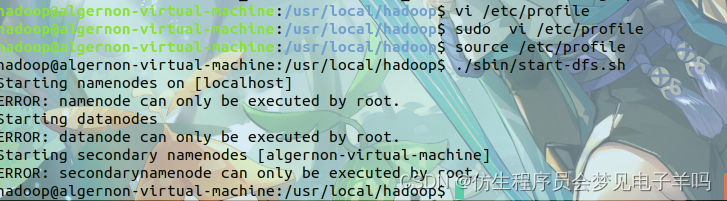
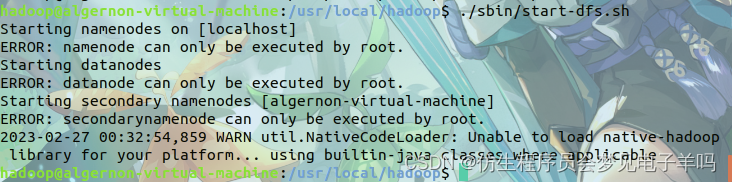
接着开启 NameNode 和 DataNode 守护进程。
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
- 1
- 2
启动时可能会出现如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable WARN 提示可以忽略,并不会影响正常使用。
在这一步可能遇到千奇百怪的问题,请移步“问题”目录。

启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、“DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。

成功启动后,可以访问 Web 界面 http://localhost:9870 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
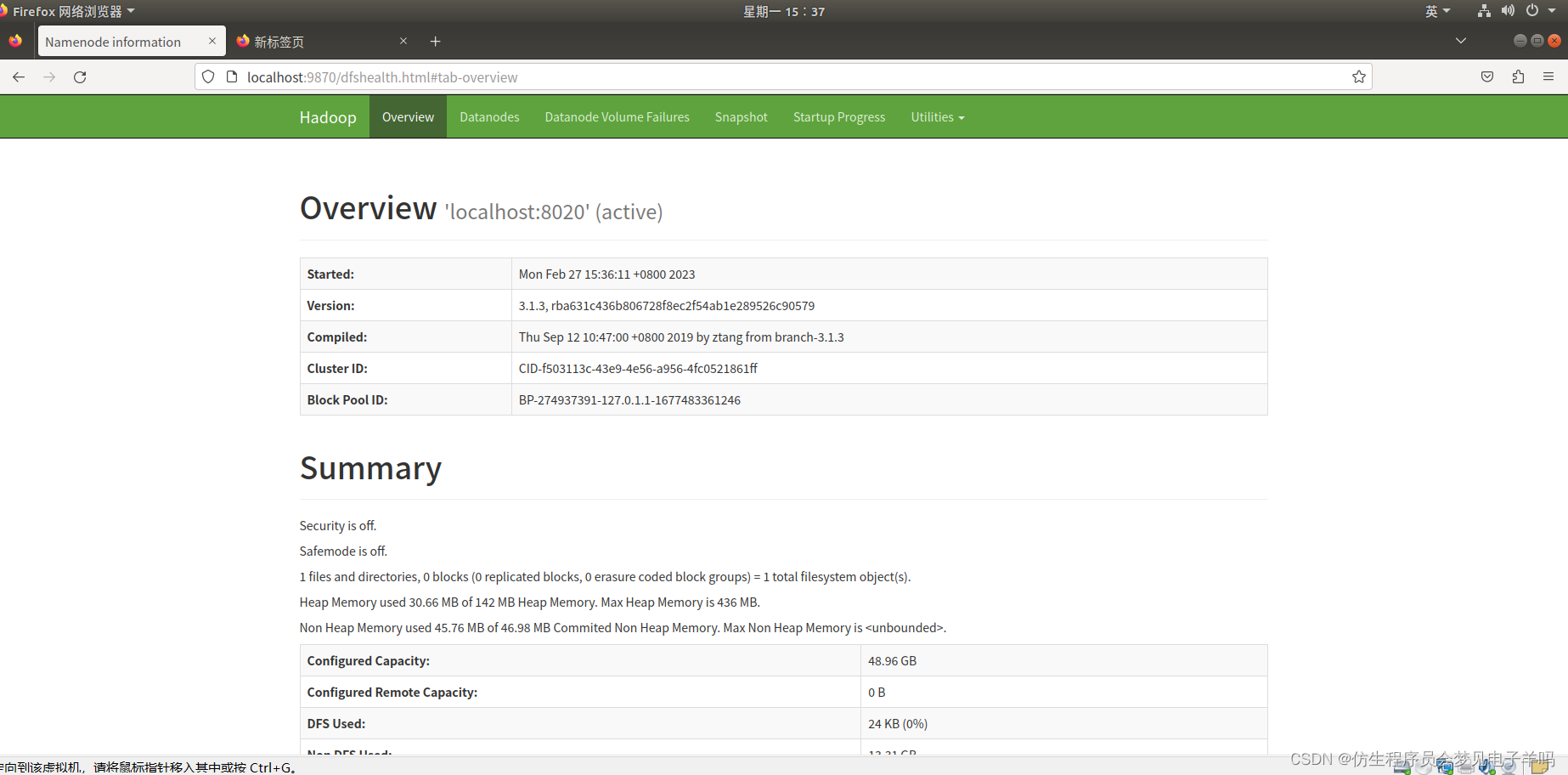
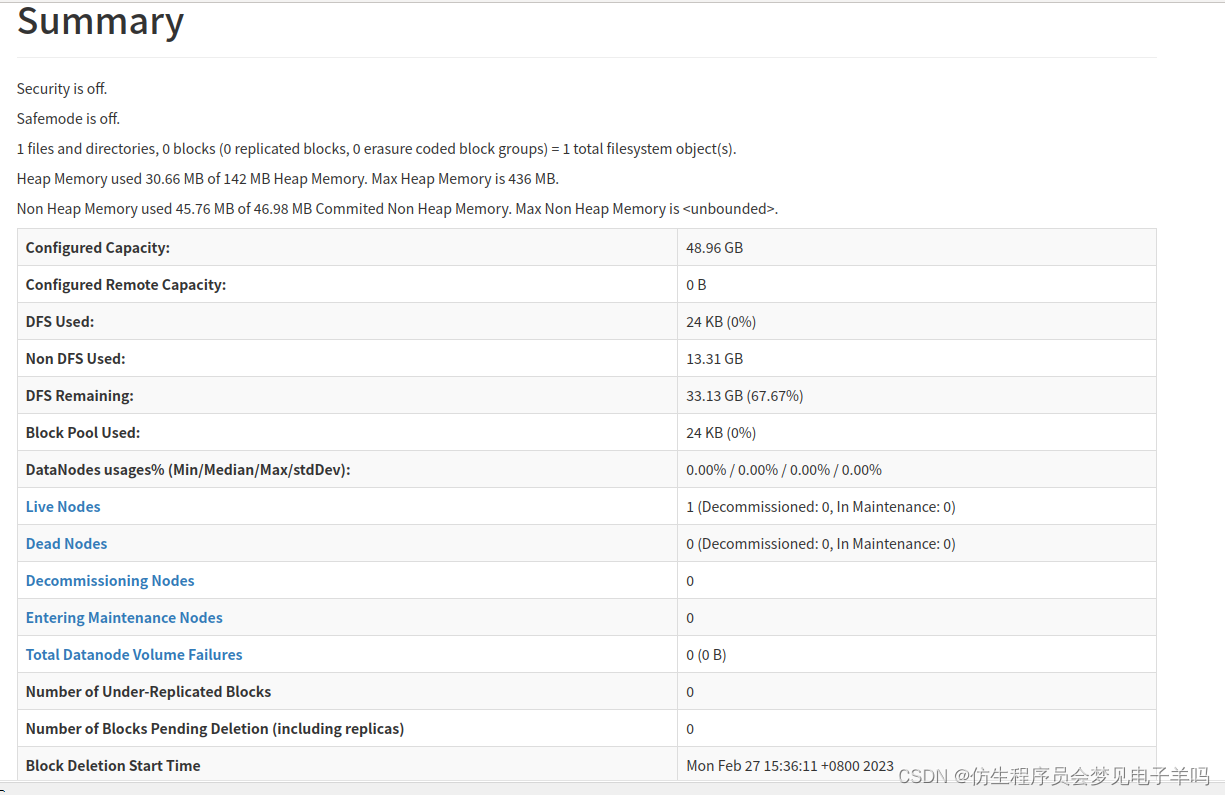
运行Hadoop伪分布式实例
上面的单机模式,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录:
./bin/hdfs dfs -mkdir -p /user/hadoop
- 1
注意: 教材《大数据技术原理与应用》的命令是以"./bin/hadoop dfs"开头的Shell命令方式,实际上有三种shell命令方式。
- hadoop fs
- hadoop dfs
- hdfs dfs
hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input:
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
- 1
- 2
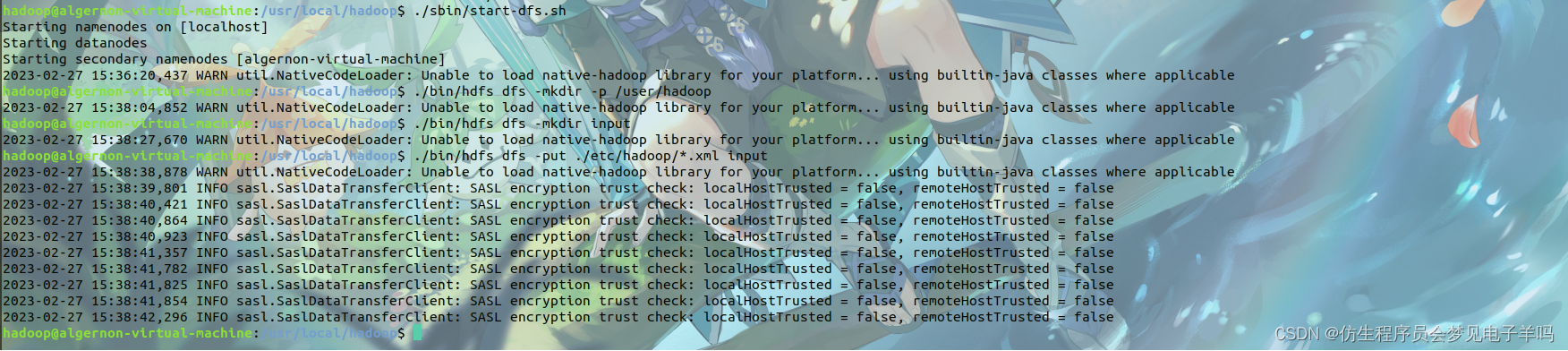
复制完成后,可以通过如下命令查看文件列表:
./bin/hdfs dfs -ls input
- 1

伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地 input 文件夹,输出结果 output 文件夹都删掉来验证这一点)。
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
- 1

查看运行结果的命令(查看的是位于 HDFS 中的输出结果):
./bin/hdfs dfs -cat output/*
- 1
结果如下,注意到刚才我们已经更改了配置文件,所以运行结果不同。

我们也可以将运行结果取回到本地:
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*
- 1
- 2
- 3

Hadoop 运行程序时,输出目录不能存在,否则会提示错误 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次执行,需要执行如下命令删除 output 文件夹:
./bin/hdfs dfs -rm -r output # 删除 output 文件夹
- 1

若要关闭 Hadoop,则运行
./sbin/stop-dfs.sh
- 1

下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 即可。
问题与处理
注意:问题2~5有一个一劳永逸的方法:重装。
事实上,2~5中的许多问题都是来自于一个bug,只是越改越多越改越杂,在查询资料的过程中可以学到许多相关知识,加深了解,但如果只是想把结果跑出来的话,不如像亚历山大那样,抽出宝剑,斩断复杂的绳结。简单,粗暴,但是有效。
如果想加深对技术和底层的了解,请移步问题2~5:
1.java安装失败


ERROR: JAVA_HOME is not set and could not be found.
参考文档:
https://blog.csdn.net/qq_44081582/article/details/104640421
- 切到 [hadoop]/etc/hadoop目录
- 执行:vim hadoop-env.sh
- 修改java_home路径和hadoop_conf_dir路径为具体的安装路径
例如:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export HADOOP_CONF_DIR=/usr/local/hadoop
- 1
- 2
- 3
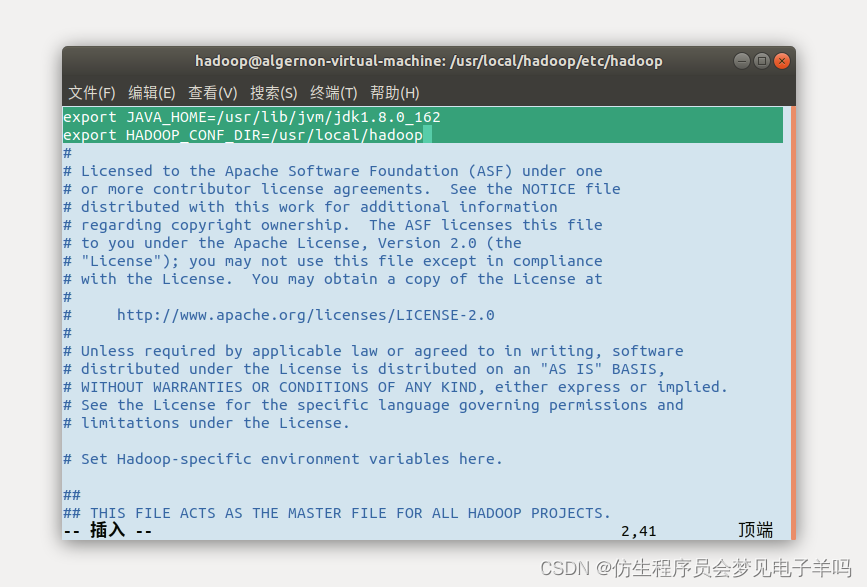
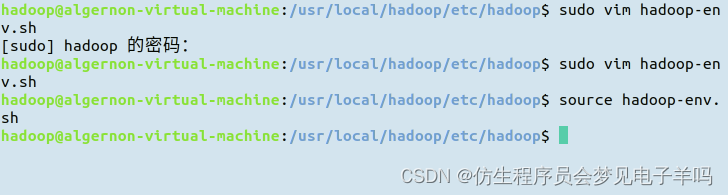
这样就配置好了。
2.ERROR: Attempting to operate on hdfs namenode as root
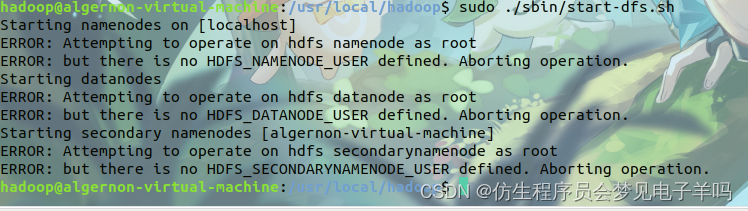
这是万恶之源,虽然命令行加sudo可以避免许多权限问题,但这次尽量不要加sudo。
参考文档:
https://blog.csdn.net/weixin_49736959/article/details/108897129、
使用vim配置:
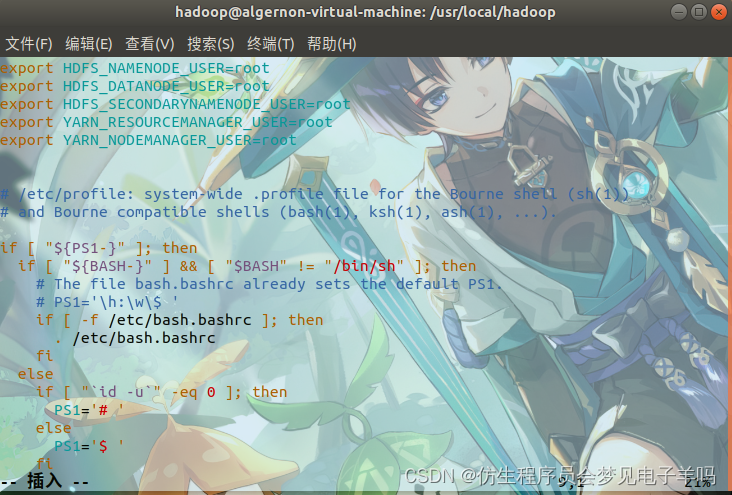
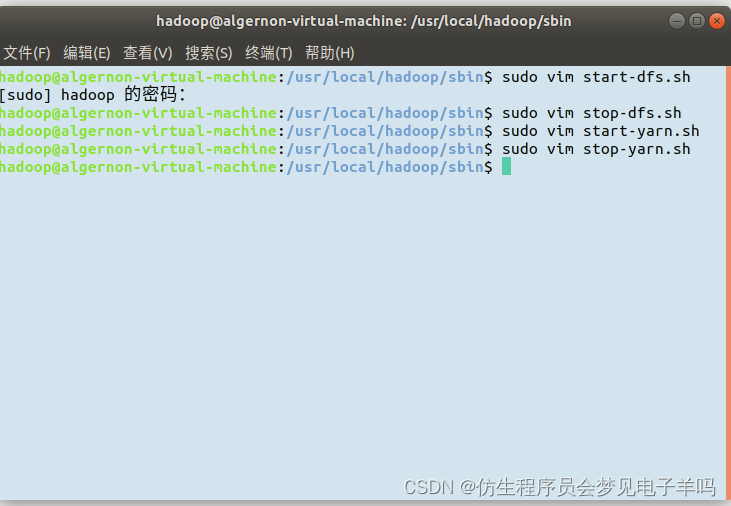
3.host:9000 failed on connection exception: java.net.ConnectException: 拒绝连接;
问题描述:
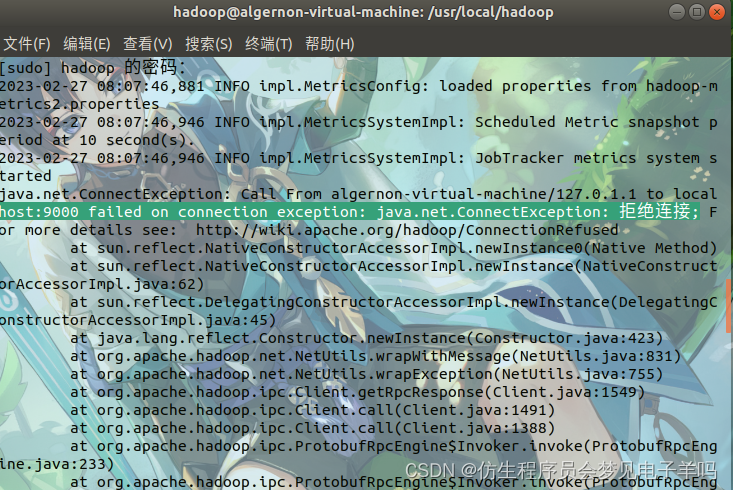
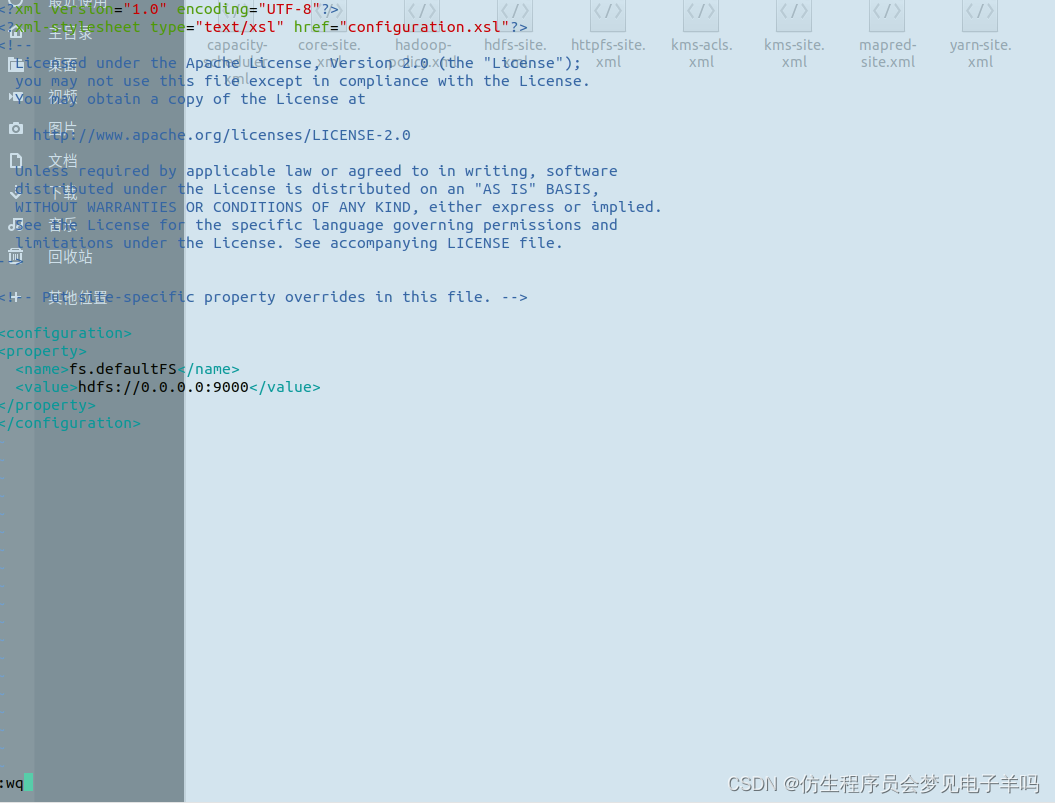
事实上是端口占用,我打开防火墙,把9000改成8020就解决了。
4.localhost: ERROR: Cannot set priority of datanode process 6374
问题描述:
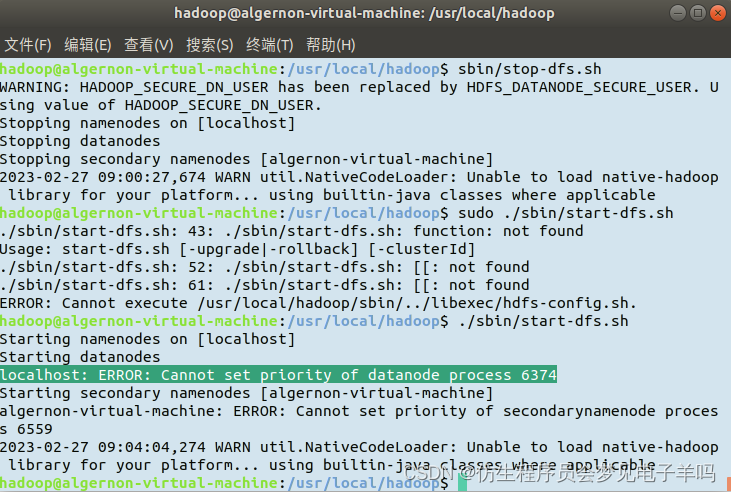
这个问题是真正的复杂,意味着你对配置文件的修改程度已经很大了,这个问题我查到的资料都没有很好的解决,这个时候重装为时未晚。
最终效果如下:
jps
- 1
5.mkdir: Call From algernon-virtual-machine/127.0.1.1 to localhost:9000 failed on connection exception: java.net.ConnectException: 拒绝连接;
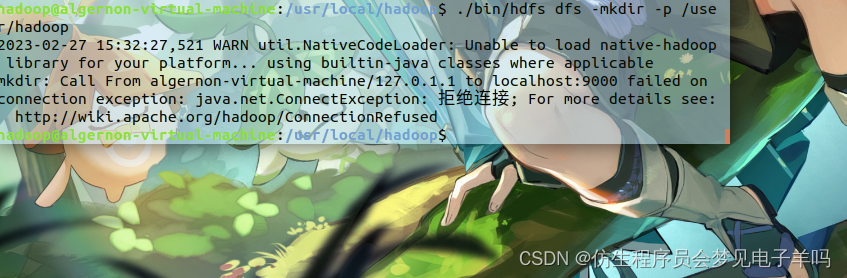
这个问题同问题3,修改9000为8020,完工。
成功结果
localhost可查询:
伪分布式输出结果:
事实上,这个实验最后就这两张图 ,每一张图的结果代表了一个实验的成功结果。linux配置操作的关键是,如果前一个步骤没有完成,后一个步骤自然也会被卡住。一条路通了,那之后就会一往无前;一旦卡住,短则一两分钟,长则一两周。
所谓“台上一分钟,台下十年功”,整个实验报告的含金量就在这两张图中,但为此不知重新配置了多少文件,甚至还重装了一次。
心得与体会
据说亚历山大大帝曾经解决了戈尔迪乌姆首都佛里吉亚的一个难题。
他在进城的时候发现了一辆旧战车,车轭上有许多绳结紧紧地系在一起,根本看不出它们原先是怎么被系上去的。神谕说,谁解开这些结,谁就能统治亚细亚。
亚历山大在这团粗糙的绳结前研究了一会儿,然后后退了两步,说神谕并不在意这个结是怎么解开的,接着他拔剑砍向绳结,被劈成两半的绳结就此解开了。
如果认真看了问题2~5的解决方式,会发现这些文档中有的解决方法是矛盾的,有的要把文件设为root,然后报错之后继续找,方法是把文件改为hadoop——然后又查,发现解决方法是使用root用户——这不又绕回去了嘛!但我今天在实验课的时候是这样的,不仅如此,网上的答案千奇百怪,有的治标不治本,如果看一篇博客就对自己的配置文件加以修改,到最后只能收获一堆自相矛盾的bug文件。当然,还有一些硬核知识。
事实上,计算机问题三板斧:重启、重装、重买,的确粗暴而有效。
但我们遇到问题是不是就要重装呢?
我一直认为:重装是最后手段。
如果只是跟着教程懵懵懂懂把流程跑一遍,如果一次成功还行,如果卡住就难受了。这时选择重装,老老实实按照教程来,根据经验规则,“那么多人都做出来了”,那跟着教材走总会没问题;
但学到什么了呢?在linux上配置环境做实验的过程犹如蒙眼于迷宫中寻找出路,被别人牵着绕啊绕,走到出口,实际上和在平地上并无区别,但如果自己去碰壁,找到经验、方法、教训,当没有人给予指引的时候,才会更容易找到方向。
所以说不要怕折腾,折腾着就熟练了。
等到系统被改的像忒修斯之船那样,在重装,从零开始也不迟。
不过,这对备份要求挺高,平时常备快照,软件记得备份。
同样,文件夹的分配,环境配置以及配置文件中的路径,一直都是bug高发地,在进行实验的过程中注意规范,也可以避免绝大多数问题。
亚历山大有着斩断绳结的魄力,也有横亘一切困难的毅力。
活跃于公元前4世纪的马其顿国王。他在远征波斯领地吕底亚的时候,神殿里供奉着一辆战车。战车是曾经的国王格尔迪奥斯捆在神殿支柱上的。当地流传着这样一个传说:“解开这个绳结的人就会成为亚细亚之王。”这是一个很多技艺高超的挑战者都没有解开的绳结。
哲人:那么,你认为面对那个绳结的亚历山大大帝会怎么做呢?
青年:是非常巧妙地解开了绳结,不久便成了亚细亚之王吧?
哲人:不,并非如此。亚历山大大帝一看绳结非常牢固,于是便立即取出短剑将其一刀两断。
青年:什么?!
哲人:据传,当时他接着说道:“命运不是靠传说决定而要靠自己的剑开拓出来。我不需要传说的力量而要靠自己的剑去开创命运。”

