
- 1使用idea连接gitee(码云)_idea登录gitee
- 2Linux开发工具之make/makefile和git怎么样
- 3python车牌识别系统开源代码_python实现车牌识别的示例代码
- 4Caused by: redis.clients.jedis.exceptions.JedisException: Could not get a resource from the pool_caused by: redis.clients.jedis.exceptions.jedisdat
- 5OpenTofu路在何方:定量分析Terraform issue数据,洞察用户需求|OpenTofu Day 闪电演讲
- 6mySQL笔记_csdn mysql笔记
- 7【Python】使用Opencv裁剪指定区域,再重构大小和保存示例_cv2裁剪特定区域
- 8commitizen 的使用_commitizen使用
- 9Golang面向对象编程(二)
- 10C++架构之美:设计卓越应用_c++ 开发架构
机器学习实战(基于scikit-learn和TensorFlow)-第十一章训练深度神经网络笔记(一)_warnings.warn('`tf.layers.dense` is deprecated and
赞
踩
关注微信公共号:小程在线


关注CSDN博客:程志伟的博客
Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)]
Type "copyright", "credits" or "license" for more information.
IPython 7.12.0 -- An enhanced Interactive Python.
from __future__ import division, print_function, unicode_literals
# Common imports
import numpy as np
import os
import tensorflow.compat.v1 as tf
# to make this notebook's output stable across runs
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
# To plot pretty figures
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "tensorflow"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
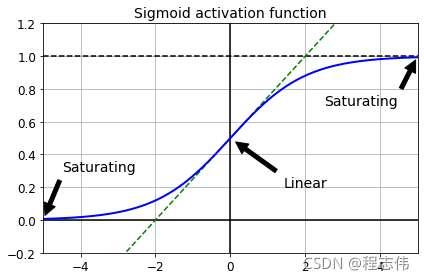
##################### 梯度消失/爆炸问题 ############################
def logit(z):
return 1 / (1 + np.exp(-z))
z = np.linspace(-5, 5, 200)
plt.plot([-5, 5], [0, 0], 'k-')
plt.plot([-5, 5], [1, 1], 'k--')
plt.plot([0, 0], [-0.2, 1.2], 'k-')
plt.plot([-5, 5], [-3/4, 7/4], 'g--')
plt.plot(z, logit(z), "b-", linewidth=2)
props = dict(facecolor='black', shrink=0.1)
plt.annotate('Saturating', xytext=(3.5, 0.7), xy=(5, 1), arrowprops=props, fontsize=14, ha="center")
plt.annotate('Saturating', xytext=(-3.5, 0.3), xy=(-5, 0), arrowprops=props, fontsize=14, ha="center")
plt.annotate('Linear', xytext=(2, 0.2), xy=(0, 0.5), arrowprops=props, fontsize=14, ha="center")
plt.grid(True)
plt.title("Sigmoid activation function", fontsize=14)
plt.axis([-5, 5, -0.2, 1.2])
save_fig("sigmoid_saturation_plot")
plt.show()
Saving figure sigmoid_saturation_plot
####Xavier初始化和He初始化
tf.compat.v1.disable_eager_execution()
reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
he_init = tf.variance_scaling_initializer()
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,
kernel_initializer=he_init, name="hidden1")
E:\anaconda3\lib\site-packages\keras\legacy_tf_layers\core.py:236: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.
warnings.warn('`tf.layers.dense` is deprecated and '
E:\anaconda3\lib\site-packages\keras\engine\base_layer_v1.py:1676: UserWarning: `layer.apply` is deprecated and will be removed in a future version. Please use `layer.__call__` method instead.
warnings.warn('`layer.apply` is deprecated and '
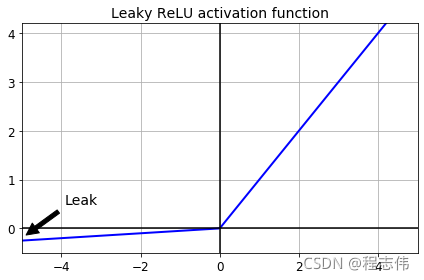
def leaky_relu(z, alpha=0.01):
return np.maximum(alpha*z, z)
plt.plot(z, leaky_relu(z, 0.05), "b-", linewidth=2)
plt.plot([-5, 5], [0, 0], 'k-')
plt.plot([0, 0], [-0.5, 4.2], 'k-')
plt.grid(True)
props = dict(facecolor='black', shrink=0.1)
plt.annotate('Leak', xytext=(-3.5, 0.5), xy=(-5, -0.2), arrowprops=props, fontsize=14, ha="center")
plt.title("Leaky ReLU activation function", fontsize=14)
plt.axis([-5, 5, -0.5, 4.2])
save_fig("leaky_relu_plot")
plt.show()
Saving figure leaky_relu_plot
####在TensorFlow中实现泄漏ReLU:
reset_graph()
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
def leaky_relu(z, name=None):
return tf.maximum(0.01 * z, z, name=name)
hidden1 = tf.layers.dense(X, n_hidden1, activation=leaky_relu, name="hidden1")
####让我们使用泄漏的ReLU在MNIST上训练一个神经网络。首先,让我们创建图形:
tf.compat.v1.disable_eager_execution()
reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=leaky_relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=leaky_relu, name="hidden2")
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:]
def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
n_epochs = 40
batch_size = 50
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
if epoch % 5 == 0:
acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_valid = accuracy.eval(feed_dict={X: X_valid, y: y_valid})
print(epoch, "Batch accuracy:", acc_batch, "Validation accuracy:", acc_valid)
save_path = saver.save(sess, "./my_model_final.ckpt")
0 Batch accuracy: 0.9 Validation accuracy: 0.906
5 Batch accuracy: 0.94 Validation accuracy: 0.9484
10 Batch accuracy: 0.9 Validation accuracy: 0.9628
15 Batch accuracy: 0.92 Validation accuracy: 0.9694
20 Batch accuracy: 1.0 Validation accuracy: 0.9738
25 Batch accuracy: 1.0 Validation accuracy: 0.9766
30 Batch accuracy: 0.98 Validation accuracy: 0.9756
35 Batch accuracy: 0.98 Validation accuracy: 0.9764
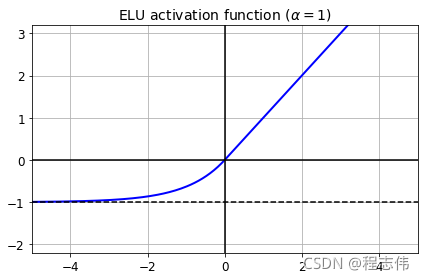
####ELU激活函数
def elu(z, alpha=1):
return np.where(z < 0, alpha * (np.exp(z) - 1), z)
plt.plot(z, elu(z), "b-", linewidth=2)
plt.plot([-5, 5], [0, 0], 'k-')
plt.plot([-5, 5], [-1, -1], 'k--')
plt.plot([0, 0], [-2.2, 3.2], 'k-')
plt.grid(True)
plt.title(r"ELU activation function ($\alpha=1$)", fontsize=14)
plt.axis([-5, 5, -2.2, 3.2])
save_fig("elu_plot")
plt.show()
Saving figure elu_plot
###在TensorFlow中实现ELU很简单,只需在构建每个层时指定激活函数:
reset_graph()
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.elu, name="hidden1")
E:\anaconda3\lib\site-packages\keras\legacy_tf_layers\core.py:236: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.
warnings.warn('`tf.layers.dense` is deprecated and '
E:\anaconda3\lib\site-packages\keras\engine\base_layer_v1.py:1676: UserWarning: `layer.apply` is deprecated and will be removed in a future version. Please use `layer.__call__` method instead.
warnings.warn('`layer.apply` is deprecated and '
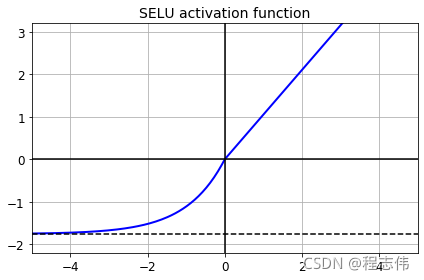
#######SELU
from scipy.special import erfc
# alpha and scale to self normalize with mean 0 and standard deviation 1
# (see equation 14 in the paper):
alpha_0_1 = -np.sqrt(2 / np.pi) / (erfc(1/np.sqrt(2)) * np.exp(1/2) - 1)
scale_0_1 = (1 - erfc(1 / np.sqrt(2)) * np.sqrt(np.e)) * np.sqrt(2 * np.pi) * (2 * erfc(np.sqrt(2))*np.e**2 + np.pi*erfc(1/np.sqrt(2))**2*np.e - 2*(2+np.pi)*erfc(1/np.sqrt(2))*np.sqrt(np.e)+np.pi+2)**(-1/2)
def selu(z, scale=scale_0_1, alpha=alpha_0_1):
return scale * elu(z, alpha)
plt.plot(z, selu(z), "b-", linewidth=2)
plt.plot([-5, 5], [0, 0], 'k-')
plt.plot([-5, 5], [-1.758, -1.758], 'k--')
plt.plot([0, 0], [-2.2, 3.2], 'k-')
plt.grid(True)
plt.title(r"SELU activation function", fontsize=14)
plt.axis([-5, 5, -2.2, 3.2])
save_fig("selu_plot")
plt.show()
Saving figure selu_plot
'''
默认情况下,SELU超参数(scale和alpha)的调整方式使每个神经元的平均输出保持接近0,
标准偏差保持接近1(假设输入也用平均值0和标准偏差1标准化)。
使用此激活函数,即使是1000层深度的神经网络也能在所有层上保留大致的平均值0和标准偏差1,
从而避免了梯度爆炸/消失问题:
'''
np.random.seed(42)
Z = np.random.normal(size=(500, 100)) # standardized inputs
for layer in range(1000):
W = np.random.normal(size=(100, 100), scale=np.sqrt(1 / 100)) # LeCun initialization
Z = selu(np.dot(Z, W))
means = np.mean(Z, axis=0).mean()
stds = np.std(Z, axis=0).mean()
if layer % 100 == 0:
print("Layer {}: mean {:.2f}, std deviation {:.2f}".format(layer, means, stds))
Layer 0: mean -0.00, std deviation 1.00
Layer 100: mean 0.02, std deviation 0.96
Layer 200: mean 0.01, std deviation 0.90
Layer 300: mean -0.02, std deviation 0.92
Layer 400: mean 0.05, std deviation 0.89
Layer 500: mean 0.01, std deviation 0.93
Layer 600: mean 0.02, std deviation 0.92
Layer 700: mean -0.02, std deviation 0.90
Layer 800: mean 0.05, std deviation 0.83
Layer 900: mean 0.02, std deviation 1.00
####让我们使用SELU激活函数为MNIST创建一个神经网络:
reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=selu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=selu, name="hidden2")
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 40
batch_size = 50
####现在让我们训练它。不要忘记将输入缩放为平均值0和标准偏差1
means = X_train.mean(axis=0, keepdims=True)
stds = X_train.std(axis=0, keepdims=True) + 1e-10
X_val_scaled = (X_valid - means) / stds
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
X_batch_scaled = (X_batch - means) / stds
sess.run(training_op, feed_dict={X: X_batch_scaled, y: y_batch})
if epoch % 5 == 0:
acc_batch = accuracy.eval(feed_dict={X: X_batch_scaled, y: y_batch})
acc_valid = accuracy.eval(feed_dict={X: X_val_scaled, y: y_valid})
print(epoch, "Batch accuracy:", acc_batch, "Validation accuracy:", acc_valid)
save_path = saver.save(sess, "./my_model_final_selu.ckpt")
####批量归一化
tf.compat.v1.disable_eager_execution()
reset_graph()
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
training = tf.placeholder_with_default(False, shape=(), name='training')
hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1")
bn1 = tf.layers.batch_normalization(hidden1, training=training, momentum=0.9)
bn1_act = tf.nn.elu(bn1)
hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2")
bn2 = tf.layers.batch_normalization(hidden2, training=training, momentum=0.9)
bn2_act = tf.nn.elu(bn2)
logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs")
logits = tf.layers.batch_normalization(logits_before_bn, training=training,
momentum=0.9)
WARNING:tensorflow:From E:\anaconda3\lib\site-packages\keras\layers\normalization\batch_normalization.py:520: _colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
E:\anaconda3\lib\site-packages\keras\legacy_tf_layers\normalization.py:424: UserWarning: `tf.layers.batch_normalization` is deprecated and will be removed in a future version. Please use `tf.keras.layers.BatchNormalization` instead. In particular, `tf.control_dependencies(tf.GraphKeys.UPDATE_OPS)` should not be used (consult the `tf.keras.layers.BatchNormalization` documentation).
'`tf.layers.batch_normalization` is deprecated and '
#让我们为MNIST构建一个神经网络,在每一层使用ELU激活函数和批次标准化:
reset_graph()
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
training = tf.placeholder_with_default(False, shape=(), name='training')
#为了避免重复相同的参数,我们可以使用Python的partial()函数:
from functools import partial
my_batch_norm_layer = partial(tf.layers.batch_normalization,
training=training, momentum=0.9)
hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1")
bn1 = my_batch_norm_layer(hidden1)
bn1_act = tf.nn.elu(bn1)
hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2")
bn2 = my_batch_norm_layer(hidden2)
bn2_act = tf.nn.elu(bn2)
logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs")
logits = my_batch_norm_layer(logits_before_bn)
reset_graph()
batch_norm_momentum = 0.9
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y")
training = tf.placeholder_with_default(False, shape=(), name='training')
with tf.name_scope("dnn"):
he_init = tf.variance_scaling_initializer()
my_batch_norm_layer = partial(
tf.layers.batch_normalization,
training=training,
momentum=batch_norm_momentum)
my_dense_layer = partial(
tf.layers.dense,
kernel_initializer=he_init)
hidden1 = my_dense_layer(X, n_hidden1, name="hidden1")
bn1 = tf.nn.elu(my_batch_norm_layer(hidden1))
hidden2 = my_dense_layer(bn1, n_hidden2, name="hidden2")
bn2 = tf.nn.elu(my_batch_norm_layer(hidden2))
logits_before_bn = my_dense_layer(bn2, n_outputs, name="outputs")
logits = my_batch_norm_layer(logits_before_bn)
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
'''
注意:由于我们使用的是tf.layers.batch_normalization()而不是tf.contrib.layers.batch_norm()(如本书中所述),
因此我们需要显式运行批规范化所需的额外更新操作(sess.run([training_op,extra_update_ops],…)。
'''
n_epochs = 20
batch_size = 200
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run([training_op, extra_update_ops],
feed_dict={training: True, X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid})
print(epoch, "Validation accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_model_final.ckpt")
0 Validation accuracy: 0.8956
1 Validation accuracy: 0.9172
2 Validation accuracy: 0.9294
3 Validation accuracy: 0.9388
4 Validation accuracy: 0.948
5 Validation accuracy: 0.9532
6 Validation accuracy: 0.9588
7 Validation accuracy: 0.9604
8 Validation accuracy: 0.962
9 Validation accuracy: 0.9646
10 Validation accuracy: 0.9668
11 Validation accuracy: 0.9684
12 Validation accuracy: 0.969
13 Validation accuracy: 0.9696
14 Validation accuracy: 0.9714
15 Validation accuracy: 0.9712
16 Validation accuracy: 0.9718
17 Validation accuracy: 0.9736
18 Validation accuracy: 0.9738
19 Validation accuracy: 0.9738
[v.name for v in tf.trainable_variables()]
Out[45]:
['hidden1/kernel:0',
'hidden1/bias:0',
'batch_normalization/gamma:0',
'batch_normalization/beta:0',
'hidden2/kernel:0',
'hidden2/bias:0',
'batch_normalization_1/gamma:0',
'batch_normalization_1/beta:0',
'outputs/kernel:0',
'outputs/bias:0',
'batch_normalization_2/gamma:0',
'batch_normalization_2/beta:0']
[v.name for v in tf.global_variables()]
Out[46]:
['hidden1/kernel:0',
'hidden1/bias:0',
'batch_normalization/gamma:0',
'batch_normalization/beta:0',
'batch_normalization/moving_mean:0',
'batch_normalization/moving_variance:0',
'hidden2/kernel:0',
'hidden2/bias:0',
'batch_normalization_1/gamma:0',
'batch_normalization_1/beta:0',
'batch_normalization_1/moving_mean:0',
'batch_normalization_1/moving_variance:0',
'outputs/kernel:0',
'outputs/bias:0',
'batch_normalization_2/gamma:0',
'batch_normalization_2/beta:0',
'batch_normalization_2/moving_mean:0',
'batch_normalization_2/moving_variance:0']
#######梯度剪裁
#让我们为MNIST创建一个简单的神经网络,并添加梯度剪裁。
tf.compat.v1.disable_eager_execution()
reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 50
n_hidden3 = 50
n_hidden4 = 50
n_hidden5 = 50
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3")
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4")
hidden5 = tf.layers.dense(hidden4, n_hidden5, activation=tf.nn.relu, name="hidden5")
logits = tf.layers.dense(hidden5, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
learning_rate = 0.01
现在我们应用梯度剪裁。为此,我们需要获得渐变,使用clip_by_value()函数剪裁渐变,然后应用渐变:
threshold = 1.0
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
for grad, var in grads_and_vars]
training_op = optimizer.apply_gradients(capped_gvs)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 20
batch_size = 200
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid})
print(epoch, "Validation accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_model_final.ckpt")
0 Validation accuracy: 0.5434
1 Validation accuracy: 0.84
2 Validation accuracy: 0.8936
3 Validation accuracy: 0.912
4 Validation accuracy: 0.9234
5 Validation accuracy: 0.9278
6 Validation accuracy: 0.9362
7 Validation accuracy: 0.9392
8 Validation accuracy: 0.9436
9 Validation accuracy: 0.9454
10 Validation accuracy: 0.9502
11 Validation accuracy: 0.9508
12 Validation accuracy: 0.9496
13 Validation accuracy: 0.9574
14 Validation accuracy: 0.9572
15 Validation accuracy: 0.9588
16 Validation accuracy: 0.961
17 Validation accuracy: 0.9612
18 Validation accuracy: 0.9636
19 Validation accuracy: 0.961

