
- 1机器学习算法应用场景实例六十则_机器学习 算法示例
- 2在Linux中安装pycharm_pycharm for linux
- 3【已解决】Android Studio下,gradle project sync failed 错误_android studio报错gradle project sync failed basic f
- 4Androidstudio配置本地Gradle_android studio在gradle目录下添加新本地gradle
- 5实测鸿蒙比安卓快六倍,实测比安卓快60% 华为鸿蒙OS性能这么强?
- 6微信小程序出现miniprogram/app.json: [“usingComponents“][“van-button“]:““@vant/weapp/button/index”未找到_miniprogram/app.json: ["usingcomponents"]["van-but
- 7Python 语言 - 函数的可变参数_python中可变参数在函数中是什么数据类型
- 8Leetcode688: 骑士在棋盘上的概率(medium, 基于概率转移矩阵的解法)_骑士棋盘概率转移矩阵
- 9MySQL多表查询表结构设计01_mysql表中查看各表之间的架构设计
- 10Android USB摄像头插拔监听_android usb 摄像头怎么测试
Unifying Voxel-based Representation with Transformer for 3D Object Detection (UVTR)论文笔记
赞
踩
原文链接:https://arxiv.org/abs/2206.00630
1.引言
统一表达对多模态的知识迁移和特征融合是必不可少的。
目前的统一表达可大致分为输入级和特征级的。输入级方法在网络开始处对齐多模态数据,如通过估计深度将图像转化为伪点云或将激光雷达点云转化为range图像,但前者的深度信息不准确,后者压缩了3D几何信息,数据的空间结构被破坏,导致较差的性能。特征级方法将图像特征转换为棱台(通过估计深度分布),并压缩为BEV特征;但高度压缩聚合了不同物体的特征,会导致语义模糊性。
本文提出UVTR,将图像和点云特征都显式地在体素空间中表达和交互。对于图像,根据预测的深度分数和几何约束采样图像特征以建立体素。然后使用体素编码器进行相邻特征之间的交互,从而进行跨模态特征交互。对于物体级别的交互,使用可变形transformer作为编码器,在统一的体素空间中为每个物体查询采样特征。引入的3D查询位置有效地减轻了BEV高度压缩带来的语义模糊性。
本文的方法有如下优点:
- 显式的体素表达支持3D空间和多帧场景的空间交互;
- 统一表达促进跨模态学习,可用于知识迁移和特征融合以进一步提高性能;
- 在体素空间中,多模态数据增广可直接同步,而无需复杂的对齐过程。
3 UVTR框架
如下图所示,UVTR包含3部分:独立模态空间(用于统一输入表达)、跨模态交互(用于跨空间特征学习)和transformer解码器(用于物体级交互和最终预测)。
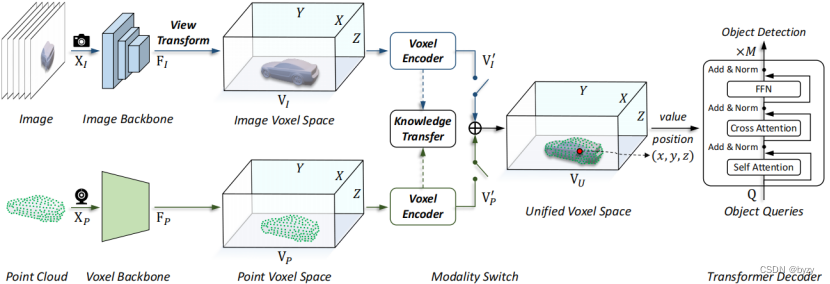
3.1 独立模态空间
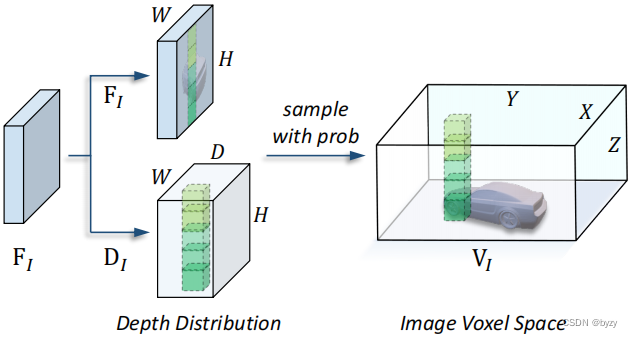
图像体素空间:使用共享的主干提取多视图图像的特征。使用FPN进行多尺度特征聚合,得到图像特征
;然后将各视图图像特征转换到3D空间,如上图所示。首先估计每个图像的深度分布
:
设体素空间的某体素中心为
,使用校准矩阵
求出图像的相应像素
,然后按下式得到体素特征:
对多视图图像分别生成体素空间,其中所有的校准矩阵与当前帧自车坐标系对齐。使用多帧输入时,从初始帧的相对时间偏移被附加在通道维度并用卷积融合。然后将所有视图的体素空间拼接,并用卷积进行空间融合。这样,沿时间维度的特征被整合到统一的空间,从而带来性能提升。
本文未将体素压缩到BEV,以避免高度压缩带来的语义模糊性,
点云体素空间:直接将点云离散化为体素,再使用基于稀疏卷积的主干处理。为得到多尺度特征,使用并行的、不同步长的头从输出中提取特征
(即使用2D卷积聚合每个高度的空间线索)。再将多尺度特征上采样到相同分辨率,求和得到体素空间
。对于多帧输入,将所有点云与相对时间偏移连接在一起,得到输入
。
虽然点云体素空间的高度压缩不会带来语义模糊性,为方便后续的跨模态交互,本文也保留了体素表达。
体素编码器:中不同视图得到的相邻体素之间没有交互,故引入体素编码器进行相邻特征的聚合。
也使用了另一体素编码器。
3.2 跨模态交互
主要是两方面:将点云的几何知识迁移到图像中,以及将图像的上下文感知特征与点云融合。
知识迁移:若在推断阶段仅有单一模态输入,则在训练设计知识迁移以使用教师指导学生优化特征。使用体素编码器最后一层ReLU前的特征作为几何丰富的教师,记为
;同一位置的
作为几何欠缺的学生,记为
。设3.3节中的物体查询位置为
,则该处的知识迁移特征距离定义为
其中是部分
距离。知识迁移的优化目标是使所有物体查询的特征距离均值
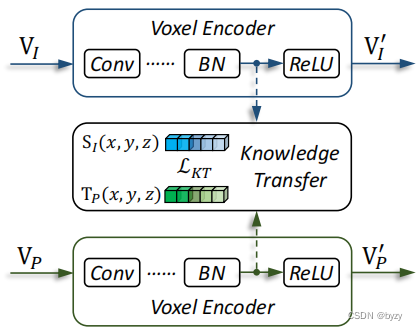
模态融合:目的是在训练和推断时能更好的利用多模态信息。给定体素特征
3.3 Transformer解码器
如图1右端,首先初始化
这样可以实现查询与体素特征的交互。通过多个transformer解码块后,使用一个共享的MLP根据每个块的输出预测结果。最后,使用迭代框细化,基于这些预测细化3D边界框。
3.4 优化目标
通常在基于transformer的模型中,训练时使用匈牙利算法进行一对一匹配目标。
使用集合到集合的损失
若使用知识迁移,加上以减小跨模态特征距离(小权重)。
4.实验
4.2 逐部件分析
体素空间高度的影响:对于的图像体素空间,其性能随着高度
增大而大幅提升;而点云体素空间仅有少量提升,因为点云有更精确的位置信息。
体素编码器中的操作:基于相机的网络在没有空间交互的情况下不能收敛;而对于激光雷达网络而言,无体素编码器就能取得较好的结果,添加其能略微提升性能。
多帧输入的影响:引入多帧输入可以大幅提高单一模态方法的性能。
体素空间网络:生成体素空间的网络越深、体素空间越大,性能越好;但对于激光雷达分支而言,增加体素分辨率只有为性能带来很小的提升。因此,图像分支需要强大的特征提取器,而激光雷达分支对特征提取器的依赖较小。
知识迁移:使用多帧图像、激光雷达或多模态体素特征作为教师、图像体素特征作为学生时,均能带来明显的性能提升;使用激光雷达体素特征作为学生时,多模态体素特征作为教师带来的性能提升很小。
跨模态融合:融合相比于单一模态能带来巨大的性能提升。其中激光雷达表达起主导作用,这是因为激光雷达有精确的几何信息。
4.3 主要结果
不同模态的结果:在单一模态以及多模态下,UVTR均能达到最优。
鲁棒性:多模态方法对丢失视图的情况有较强的鲁棒性;对基于相机的方法,虽然性能有所下降,但网络仍能在视野内预测较好的结果。对于传感器抖动,模型性能较为稳定,特别是多模态方法。
附录
A.实验细节
一般来说,图像和点云的数据增广是不同的。为弥补模态间差距,本文使用统一采样器和统一数据增广。
统一采样器:通常的激光雷达方法使用GT采样(即复制粘贴数据增广)从数据库中得到更多样本,但图像因为存在物体重叠而很少使用。在UVTR的多模态训练中,同时采样点云和图像中的样本,并根据真实深度重新组织图像crop。
统一数据增广:激光雷达点云上通常进行全局旋转、缩放、翻转等数据增广操作;对于图像体素空间也进行相应的操作。
训练细节:使用CBGS采样器进行类别平衡优化;对于多模态方法,使用单一模态的网络作为预训练结果,然后联合微调。
B.定性结果
可视化单一模态和多模态结果,可知:
-
多模态方法能精确检测多数物体,但仍有远处物体或小物体未被检测;
-
激光雷达方法因为缺少分类所需的语义信息,可能会导致误检测;
-
图像方法的定位精度不够高,但其提供的语义信息对识别有帮助,能检测一些激光雷达检测不到的物体。

