
- 1C# 利用 UI 自动化框架与应用程序的用户界面进行交互来模拟点击按钮_c# ui自动化
- 2python爬取携程旅行网景点评论_携程评论爬取
- 3AIGC基于文本生成音乐,现在压力来到配乐行业这边|Github
- 4写一个判素数的函数,在主函数输入一个整数,输出是否为素数的信息_编写一个判定素数的函数,在主函数输入一个整数
- 55G移动通信网络整体架构_5g网络架构
- 6ZA303学习笔记九部署和管理Azure计算资源 Azure AD/配置MFA_微信小程序跟azure ad mfa
- 7文本数据清洗:去除噪声,提升模型性能_给文本去噪
- 8C语言 基本数据类型及大小
- 9Stable Diffusion WebUI 中文提示词插件 sd-webui-prompt-all-in-one
- 10python爬虫豆瓣读书top250+数据清洗+数据库+Java后端开发+Echarts数据可视化(一)_基于爬虫,数据清洗,echars数据可视化的项目
『AI办公 x 财务』第一期 workshop 任务一打卡
赞
踩
活动链接
活动目标
- 周末1+6 AI交流学习小活动,通过几个简单的小案例(小作业),带大家上手如何用一些AI办公软件,探索AI工具的赋能提效方式,争做新时代的AI Superman!
选择作业1
- 作业1: 数据处理
- 假设您拿到了最近四年的数据,需要您汇总2018至2021年的数据,计算湖南地区办公用品的总销售额、总数量和总利润
作业1 参考
参考 AI 工具
作业1 实践
月之暗面
- 首先按照参考教材,使用月之暗面 kimi,按照示例prompt生成vba代码
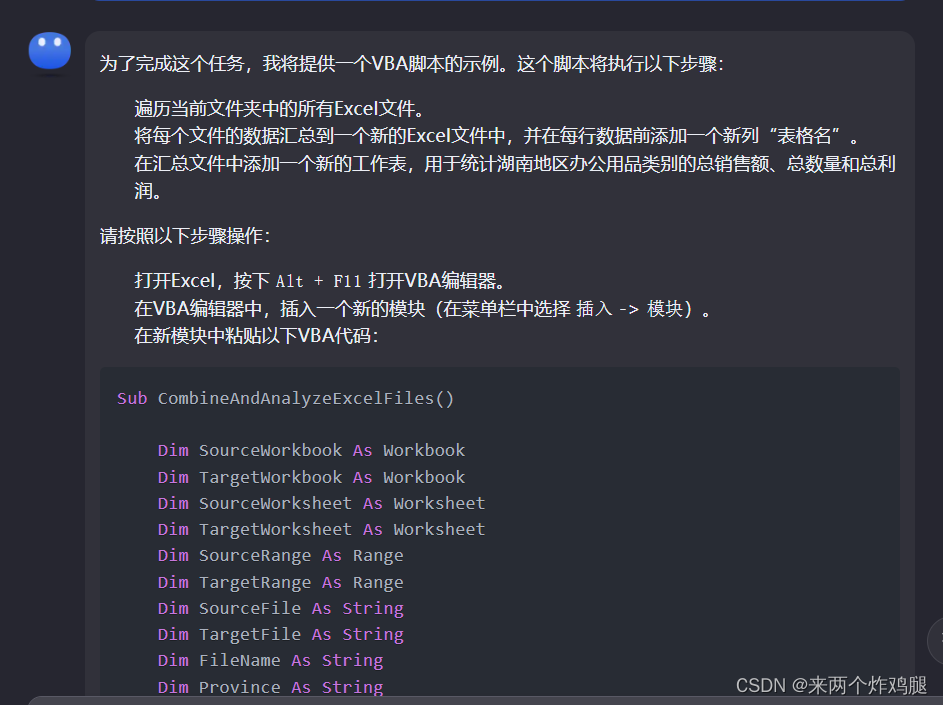
- 可惜尝试了很多次,在WPS中运行宏都是报 Unexpected identifier ,实在是搞不动,换了。
智谱清言
-
换成智谱清言来生成python
-
prompt 采用教材示例
假设你是最懂数据处理的专家,take the breath,let’s think step by step。帮我写一个python脚本来执行以下两个任务:
1.汇总:脚本应该遍历当前文件夹中的所有Excel文件,并将它们的内容汇总到一个新的Excel文件中。第一行需要在汇总的表格中,每行数据需要添加一个新列“表格名”,以标识该数据来自哪个原始表格。完成后,请将这个新的Excel文件保存在当前目录下,并命名为“汇总”。
2.统计:在“汇总”文件中,除了上述汇总内容,还请添加一个新的工作表。在这个新工作表中,我需要统计湖南地区办公用品类别的总销售额、总数量和总利润。为您参考,我上传了一个示例表格,其中包含了类似的数据格式和内容。
当前文件夹中其中一个表格数据如下所示:
行 ID 订单 ID 订单日期 发货日期 邮寄方式 客户 ID 客户名称 细分 城市 省/自治区 国家/地区 地区 产品 ID 类别 子类别 产品名称 销售额 数量 折扣 利润
11 CN-2018-4195213 2018/12/22 2018/12/24 二级 谢雯-21700 谢雯 小型企业 榆林 陕西 中国 西北 技术-设备-10000001 技术 设备 爱普生 计算器, 耐用 434.28 2 0 4.2
44 CN-2018-2932548 2018/5/17 2018/5/22 二级 唐婉-21385 唐婉 小型企业 南昌 江西 中国 华东 办公用-收纳-10004212 办公用品 收纳具 Fellowes 锁柜, 蓝色 1935.08 2 0 0
- 详细代码如下:
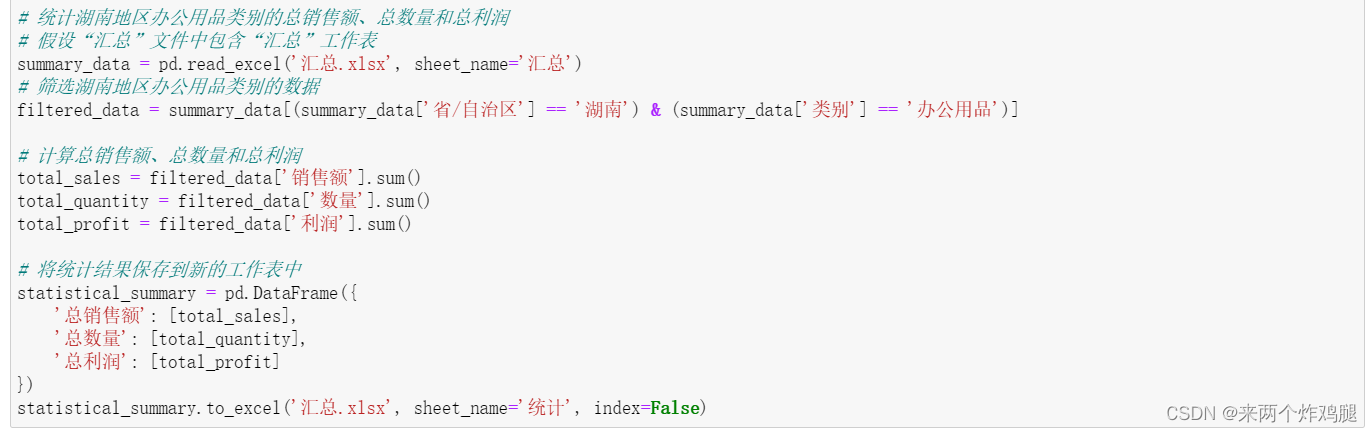
import os import pandas as pd # 设置工作目录为当前文件夹 os.chdir('./作业1/') # 请替换为实际文件夹的路径 # 存储所有Excel文件的路径 excel_files = [file for file in os.listdir() if file.endswith('.xlsx')] # 汇总所有Excel文件的数据 all_data = pd.DataFrame() for file in excel_files: df = pd.read_excel(file) # 为每行数据添加“表格名”列 df['表格名'] = file all_data = all_data.append(df, ignore_index=True) # 将汇总后的数据保存到新的Excel文件中 all_data.to_excel('汇总.xlsx', index=False) # 统计湖南地区办公用品类别的总销售额、总数量和总利润 # 假设“汇总”文件中包含“汇总”工作表 summary_data = pd.read_excel('汇总.xlsx', sheet_name='汇总') # 筛选湖南地区办公用品类别的数据 filtered_data = summary_data[(summary_data['省/自治区'] == '湖南') & (summary_data['类别'] == '办公用品')] # 计算总销售额、总数量和总利润 total_sales = filtered_data['销售额'].sum() total_quantity = filtered_data['数量'].sum() total_profit = filtered_data['利润'].sum() # 将统计结果保存到新的工作表中 statistical_summary = pd.DataFrame({ '总销售额': total_sales, '总数量': total_quantity, '总利润': total_profit }) statistical_summary.to_excel('汇总.xlsx', sheet_name='统计', index=False)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
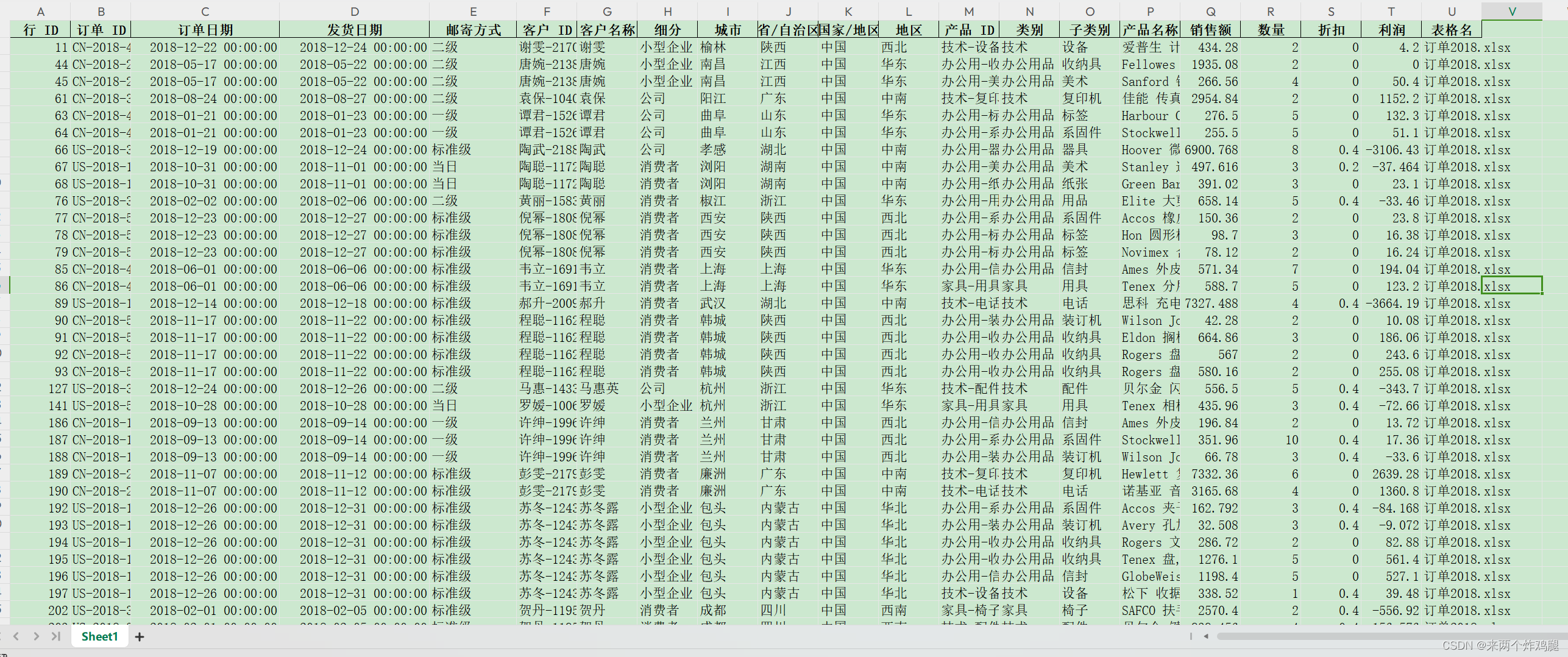
- 运行代码结果如图,看起来还可以:
-
但是:它并没有按照要求,把sheet名字改为汇总。
-
下一步,统计湖南地区统计信息时会报错,因为找不到 ‘汇总’ 这个sheet

-
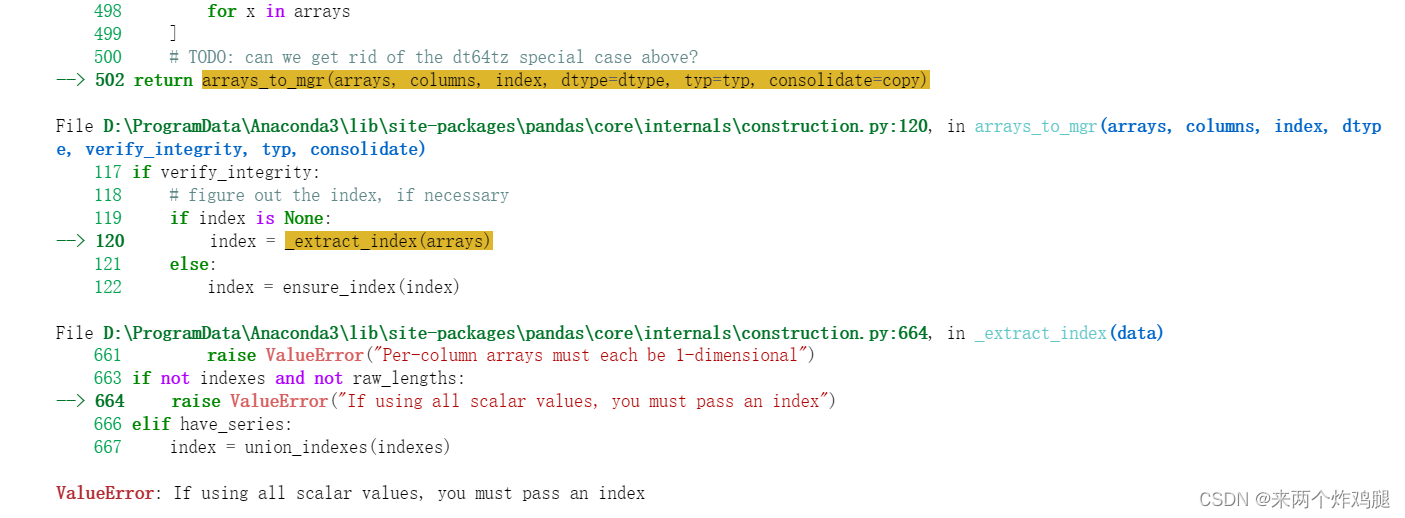
在这里,我很不争气的手动改了sheet名,没想到又报了新的错误:
-
这是 DataFrame 创建的错误,所以又把value修改为list类型。
- 但是又出现了新的风暴,它将原来的sheet覆盖了,o(╥﹏╥)o
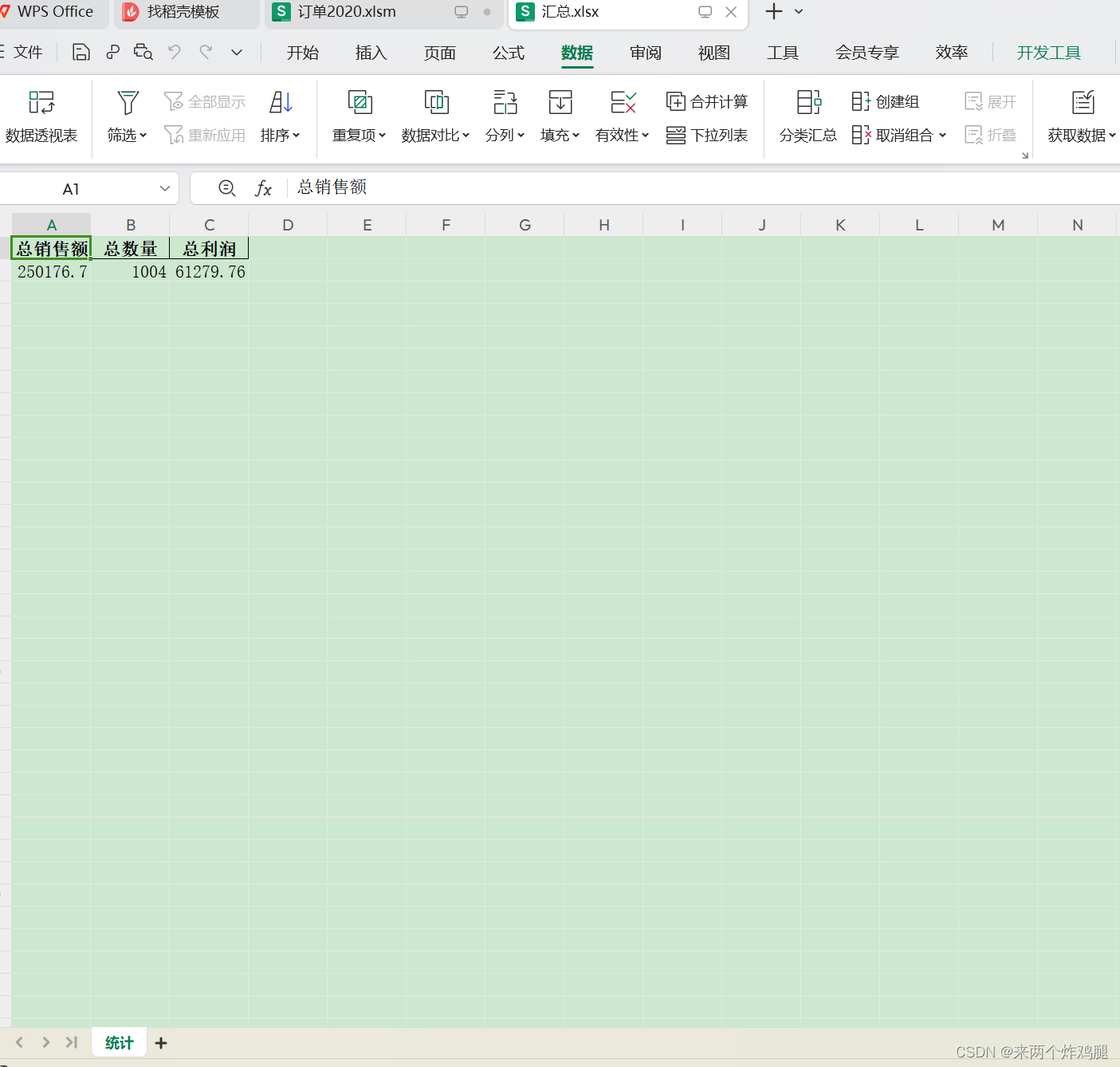
- 看来还是需要有一定的编程功底…

