
- 1STM32HAL(一)外设驱动框架与回调函数应用
- 2FPGA 高速数据采集传输毕业论文【附仿真】_fpga最新论文讲解
- 3一周通过Professional Scrum Master(PSM1)考试准备分享_the scrum guide下载
- 4云安全解决方案安全保障体系框架
- 5程序员的工作交接
- 6[思维模式-17]:《复盘》-5- “行”篇 - 操作复盘- 项目复盘_复盘第五章项目复盘
- 7每天一道C语言编程(4):字符串的逆序输出_c语言逆序输出字符串
- 8mysql-长事务详解
- 9C图书管理系统——(单项链表版本)_图书管理系统类链表
- 10Git常见错误(附解决办法),农民工看完都会了_committing is not possible because you have unmerg
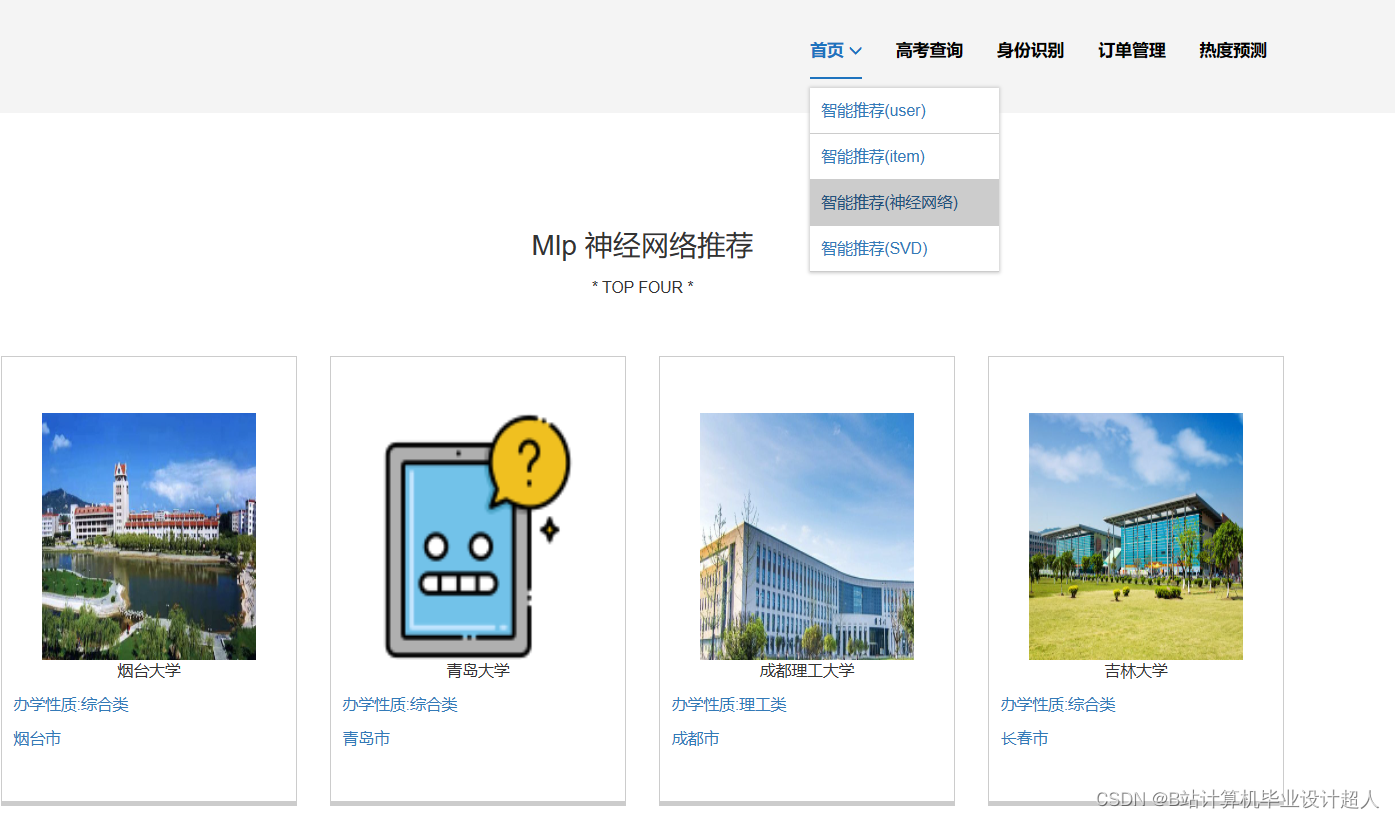
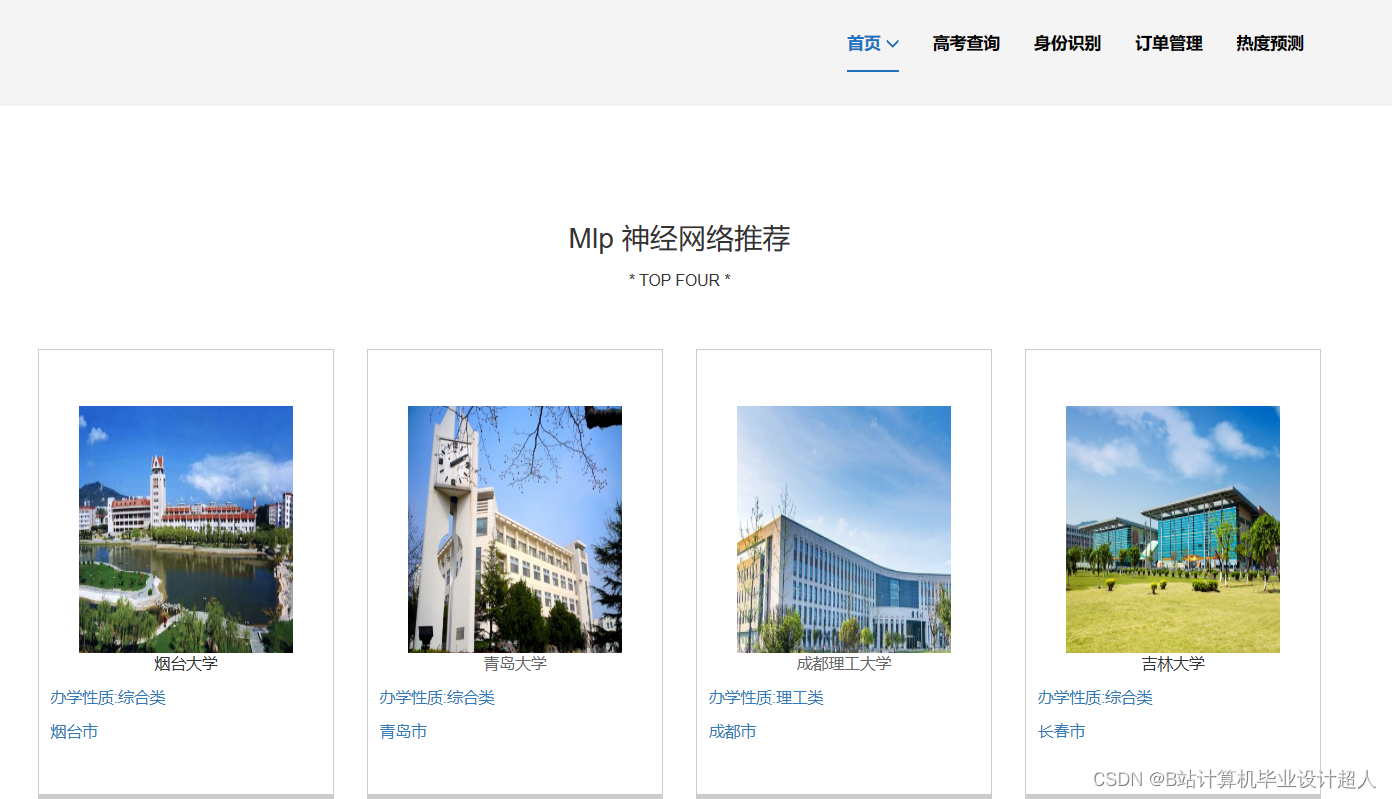
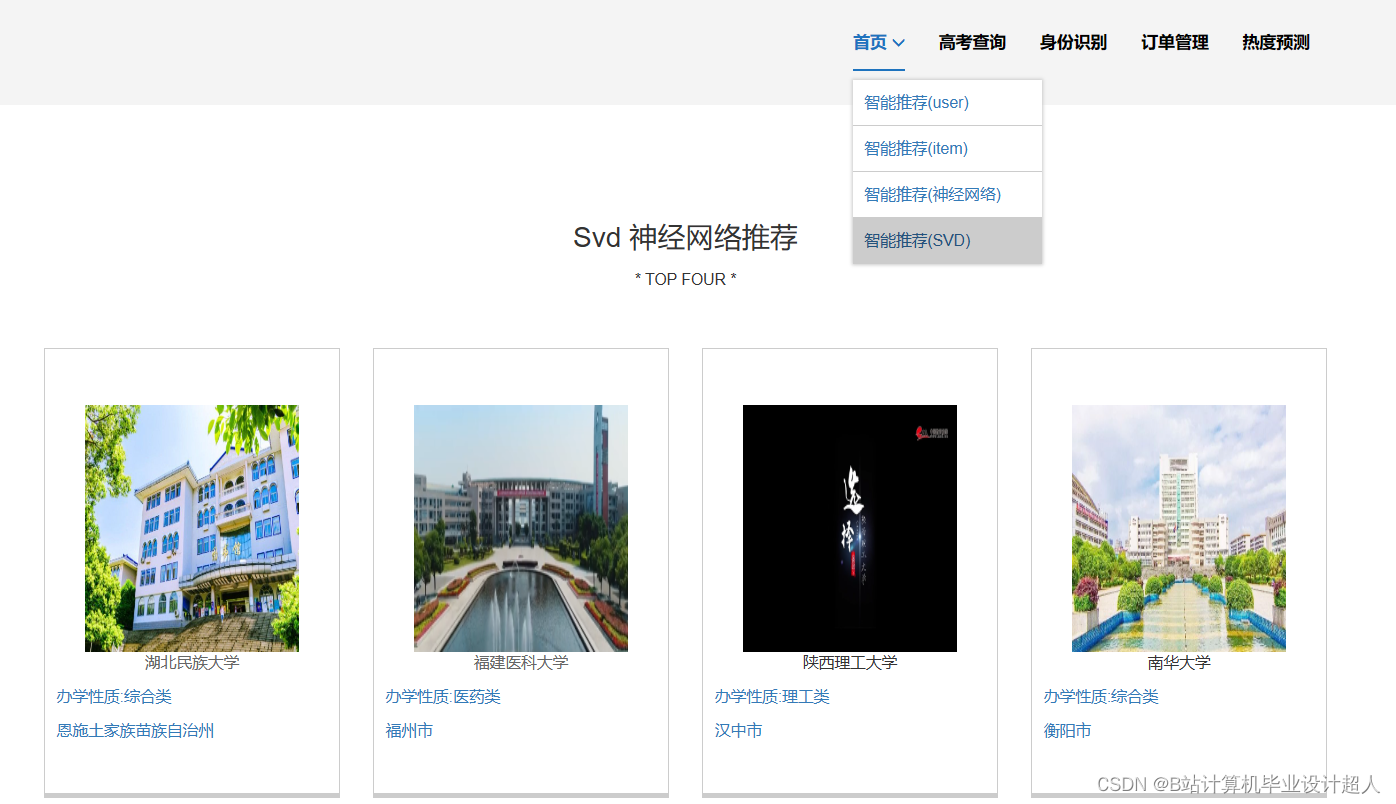
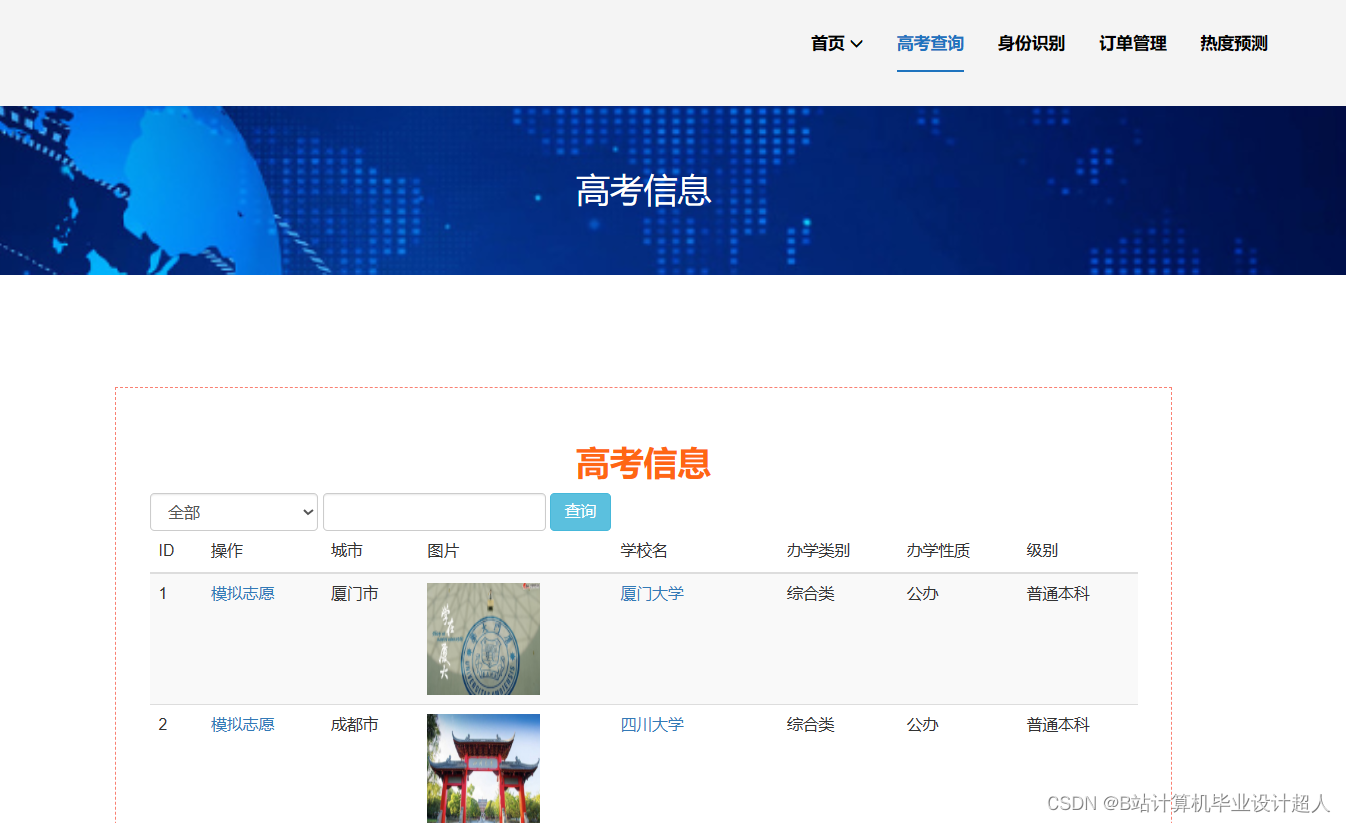
大数据毕业设计hadoop+spark高考志愿填报推荐系统 高考大数据 高考分数线预测系统 高考可视化 高考数据分析 高考爬虫 大数据毕业设计 机器学习 计算机毕业设计 知识图谱 深度学习 人工智能_基于spark的高考志愿推荐系统
赞
踩
| 学院 | xxx | 适用专业 | xxx | ||||
| 学生姓名 | xxx | 学号 | xxx | 学生班级 | xxx | ||
| 论文(设计)题目 | 高考志愿推荐系统的设计与实现 | ||||||
| 指导教师姓名 | xxx | 指导教师职称 | xxx | ||||
| 课题来源 | 生产或社会实际 | 课题类型 | 设计 | ||||
| 说明:1、若课题来源于教师的科研项目,请填写科研项目名称,来源; 2、若课题来源于生产或社会实际,请写明来源单位。 | |||||||
| 毕业论文(设计)地点 | 六盘水师范学院 | 预计完成课题周数 | 14周 | ||||
| 一、课题基本内容及要求 ㈠设计基本内容: 背景: 高考是中国的大学招生的学术资格考试,在目前看来,高考的考试类型有两种,一种是文理分科,另一种是新高考模式。传统的文理分科是将学生分成两个类型,一种是文科,除了语数外三门课以外需要学习政史地,理科相对应的就需要学习物化生。根据学生的高考成绩和每个大学在所对应省份的总体招生计划来分梯度划线,也就是我们常说的重本线,二本线和专科线。 高考填报志愿对每个考生都非常重要,每年全国有数百万家庭使用网络了解高考支援志愿信息并推荐填报志愿。对于很大一部分考生和家长来说,短时间了解全国数千所高等院校的招生标准、历史录取分数、专业要求等信息非常困难。往往由于信息的缺失或错误造成高考志愿与考生成绩之间的较大差异,对考生造成不可挽回的损失。 因此,我们使用软件工程面向对象的思想,开发一个高考志愿填报推荐系统,为高考结束的学生提供智能化推荐服务、往年报考信息可视化统计等,提高学生志愿填报的准确度,加深学生对往年报考信息的认识深度,有助于志愿的合理填报。 主要内容:
㈡设计基本要求:
㈢论文或设计说明书要求
以Java、Python、人工智能、软件工程等基础知识作为论述依据,使用专业术语描述高考志愿填报推荐系统开发所需要的背景、意义、需求分析、数据库设计等论文模块。 用UML建模语言对流程设计、ER图、实体图、数据库表设计等进行完整图表绘制,并且用专业知识撰写成流畅描述语言,整合到论文中增添技术支持。 查询知网同类系统参考文献,多引用丰富的文献素材,拓宽论文借鉴、创新的渠道。
提供关键部分代码的清晰讲解文字。 准确给出部署环境需要的机器配置、软件版本、操作命令、步骤、脚本等。 给出软件环境的下载链接如百度云、阿里云等。 提供完整源代码、数据库建表语句的下载路径。 提供演示地址、演示视频、操作所需要的测试账号、密码等。
| |||||||
| 二、课题特点(表现在符合专业培养目标上、表现在结合省情方面、表现在采用先进技术方面、表现在培养学生解决工程技术问题的能力上)
| |||||||
| 三、此课题往届是否做过?若已做过,写明做过几次,本届有何新的要求? 此类题目属于新题目,如果往届有重复的话,本项目相对往届项目有如下创新之处:
| |||||||
| 四、课题的难易程度、工作量(论文字数或说明书字数、图纸数量),以及对学生的知识、技能有何要求等 1.该课题属于算法仿真类的课题,课题需要实现4种深度学习推荐算法、一种机器学习预测算法、一个知识图谱关系图的设计、高考志愿填报业务等,难度适中。 2.需要查阅10-15篇中外高考推荐类系统的参考文献,理清中外同类系统设计的优势和劣势,分析深层次技术设计的原理,结合我省高考的特点进行个性化定制设计。需要设计约20个功能模块;编写5-10万行代码实现;测试部分需要用单元测试完成,设计100-200个单元测试用例,边开发边单元测试自测可以降低统一测试的难度和节约测试时间。 3.解决以上问题需要掌握springboot+vue.js开发框架、mysql数据库、深度学习算法知识、Python爬虫等。 | |||||||
| |||||||
| 六、教学系审核意见: 该题目符合专业培养目标和教学基本要求原则,能使学生受到全面的专业基本训练,选题紧密结合生产和社会实际,难度和工作量适当,具有学科性、专业性,能体现专业的主干学科方向。 同意作为毕业设计选题。 教学系主任(签字): 2023年 月 日 | |||||||
| 七、学院毕业论文(设计)工作领导小组审批意见: 经学院毕业论文(设计)工作领导小组审核,同意作为毕业设计选题。 组长(签字): 2023年 月 日 | |||||||







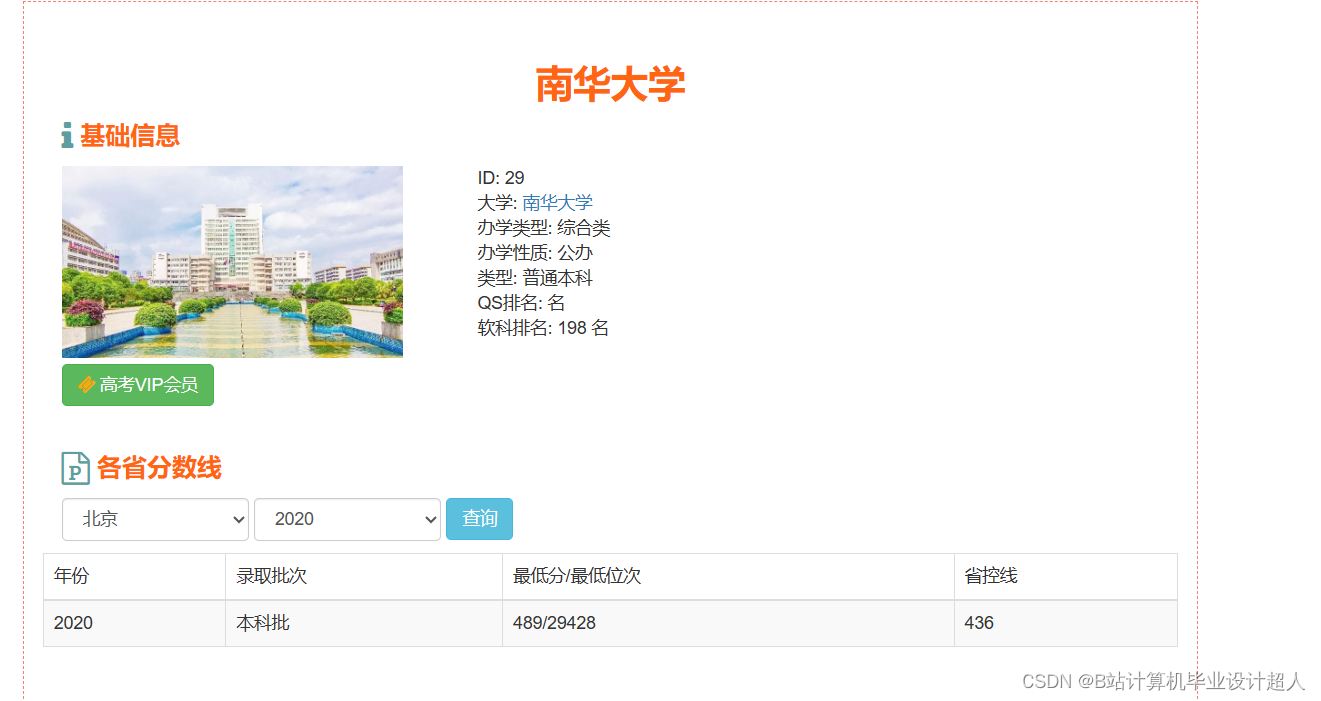
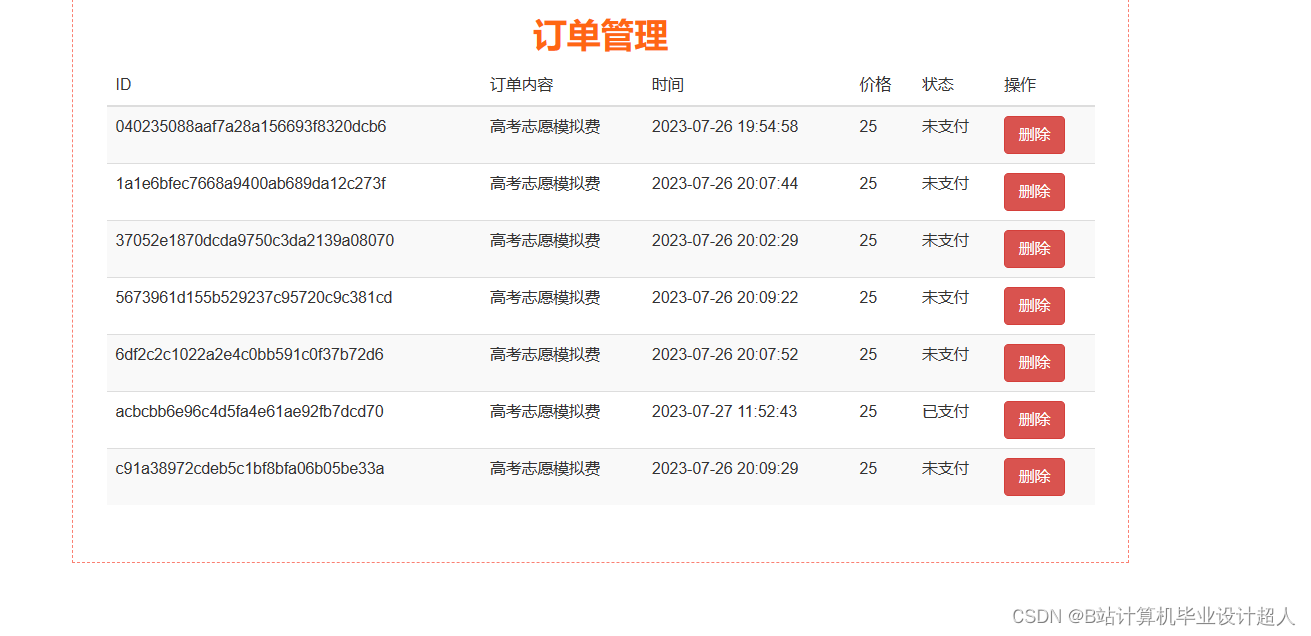
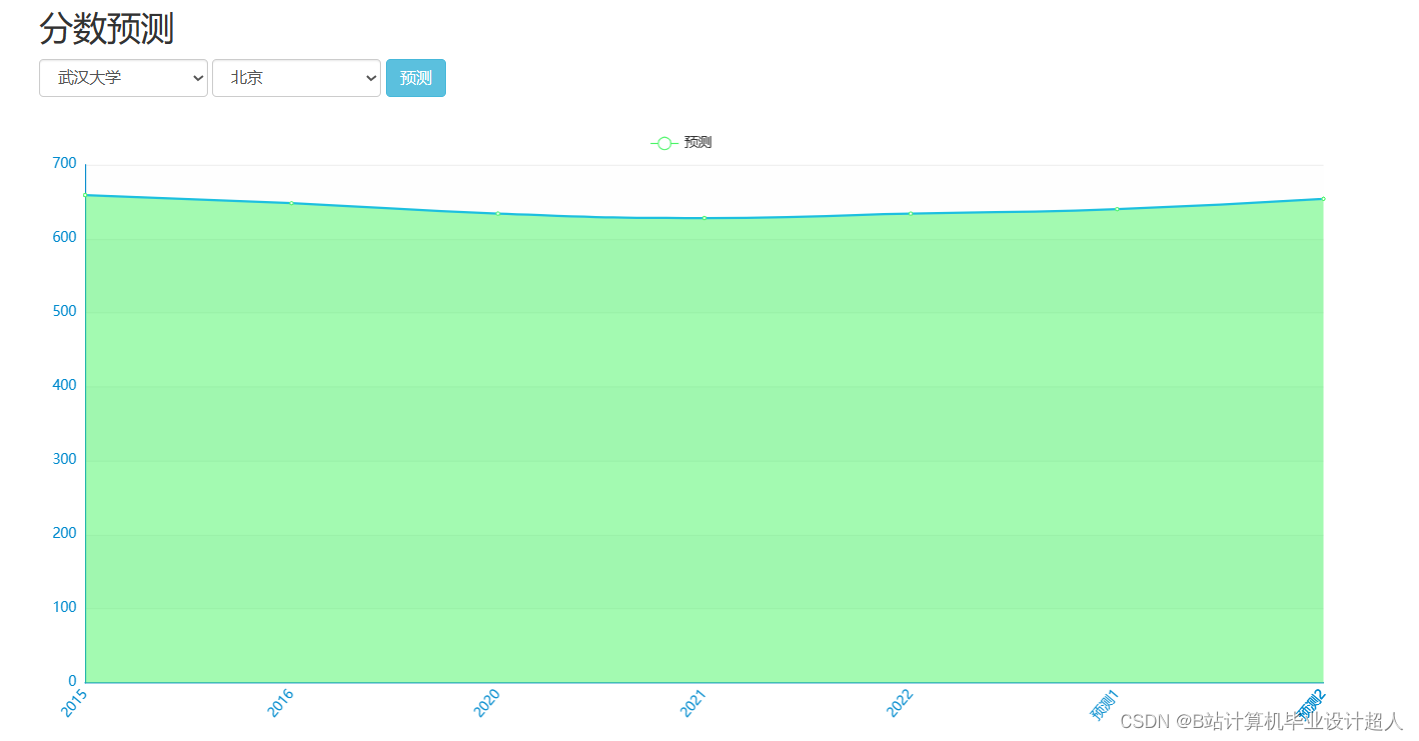
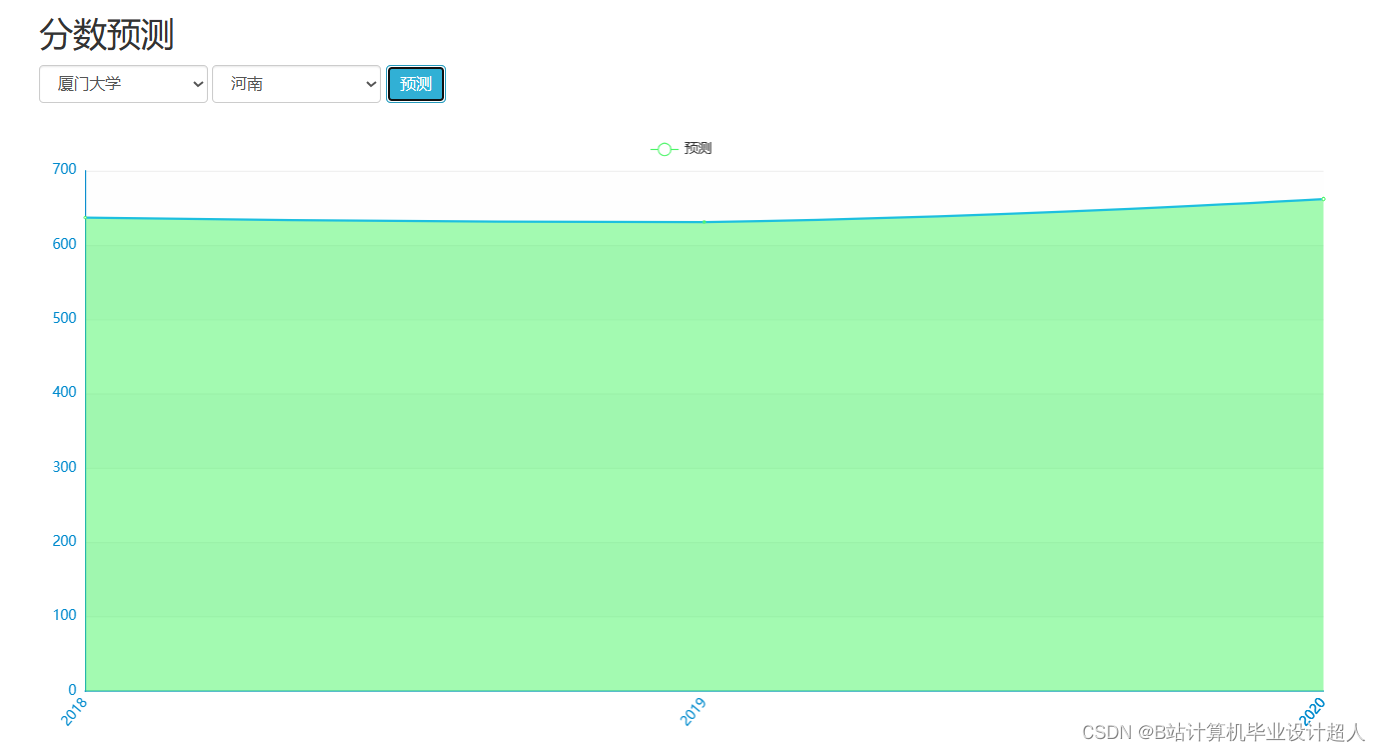






| 姓名 | 张三 | 学号 | 年级 | 班级 | ||||
| 设计(论文) 题目 | 基于Spark的高考智能推荐系统 | |||||||
| 指导教师姓名 | 职称 | |||||||
| 拟完成时间 | 2022年 1 月 15 日 | |||||||
| 设计(论文)类别
| þ项目设计制作类 ¨项目设计策划类 ¨实践操作类 ¨课堂教学与设计类 ¨学位论文类 | |||||||
| 命题来源 | þ教师命题 ¨学生自拟 ¨教师科研课题 | |||||||
| 是否在实验实训、实习、工程实践和社会调查等社会实践中完成 | þ是 ¨否 | |||||||
| 一、选题依据及意义(不少于300字) 依据 高考是中国的大学招生的学术资格考试,在目前看来,高考的考试类型有两种,一种是文理分科,另一种是新高考模式[1]。传统的文理分科是将学生分成两个类型,一种是文科,除了语数外三门课以外需要学习政史地,理科相对应的就需要学习物化生。根据学生的高考成绩和每个大学在所对应省份的总体招生计划来分梯度划线,也就是我们常说的重本线,二本线和专科线[2]。 高考填报志愿对每个考生都非常重要,每年全国有数百万家庭使用网络了解高考支援志愿信息并推荐填报志愿[3]。对于很大一部分考生和家长来说,短时间了解全国数千所高等院校的招生标准、历史录取分数、专业要求等信息非常困难。往往由于信息的缺失或错误造成高考志愿与考生成绩之间的较大差异,对考生造成不可挽回的损失。 意义 目前高考志愿填报,涌现很多没有结合自身实际、盲目跟风的不良现象,最常见的跟风是过度依赖智能系统,很多家长、考生缺乏高考志愿相关专业知识,又没有太多时间去研究,面对浩如烟海的数据产生焦虑情绪,希望找到一种性价比高的方式,解决填报志愿时遇到的各种难题,最好能省心省事直接生成填报方案[4]。在庞大用户需求量和高额利润诱惑下,高考志愿智能辅助系统软件的市场近年来变得非常火爆,有些商家抓住客户着急心理和对行情信息不了解的情况,做出虚假、过分夸大宣传。大部分家长不能从专业角度去甄别智能系统,盲目跟风缴费升级会员,过分迷信权威金牌专家、内部来源数据、人工智能一键生成方案等,很多考生三年备考、三分钟报考,录取去向满意度不高。 在当今时代,互联网的高度普及以及信息技术的飞速发展都使得数据呈现爆炸式增长,海量的数据然已成为一种“藏”[5]。与此同时,社会出现了大量的“据金者”在数据的海洋里挖掘、采集、提炼、分析,想要发掘有价值的信息。据了解,大数据目前主要应用于互联网、电商、视频门户网站等企业领域,对于教育领域则运用的较少高考是教育领域中最引人注目的大事件,中国作为高考大国,在高考招生的信息化建设中,积累了非常丰富的高考信息数据资源,包括历年的报名库、志愿库、录取库、成绩库等等,且数据大多为原始数据未经过处理。面对这些数据,考生在填报志愿时往往无所适从,导致高考数据没能充分体现其价值,面对大数据时代所带来的数据过载等问题,推荐系统列和搜索引应运而生,相比于后者的信息被动选择模式,推荐系统是基于机器学习+深度学习自动的帮助用户过滤掉一些无用或不喜欢的内容,直接替用户完成了自我筛选的过程[6]。其极大的缩短了用户在信息选择上的时间,同时也提高了用户相关行为数据的利用率。 | ||||||||
| 二、研究目的与主要内容(含设计(论文)提纲,不少于500字) 研究目的
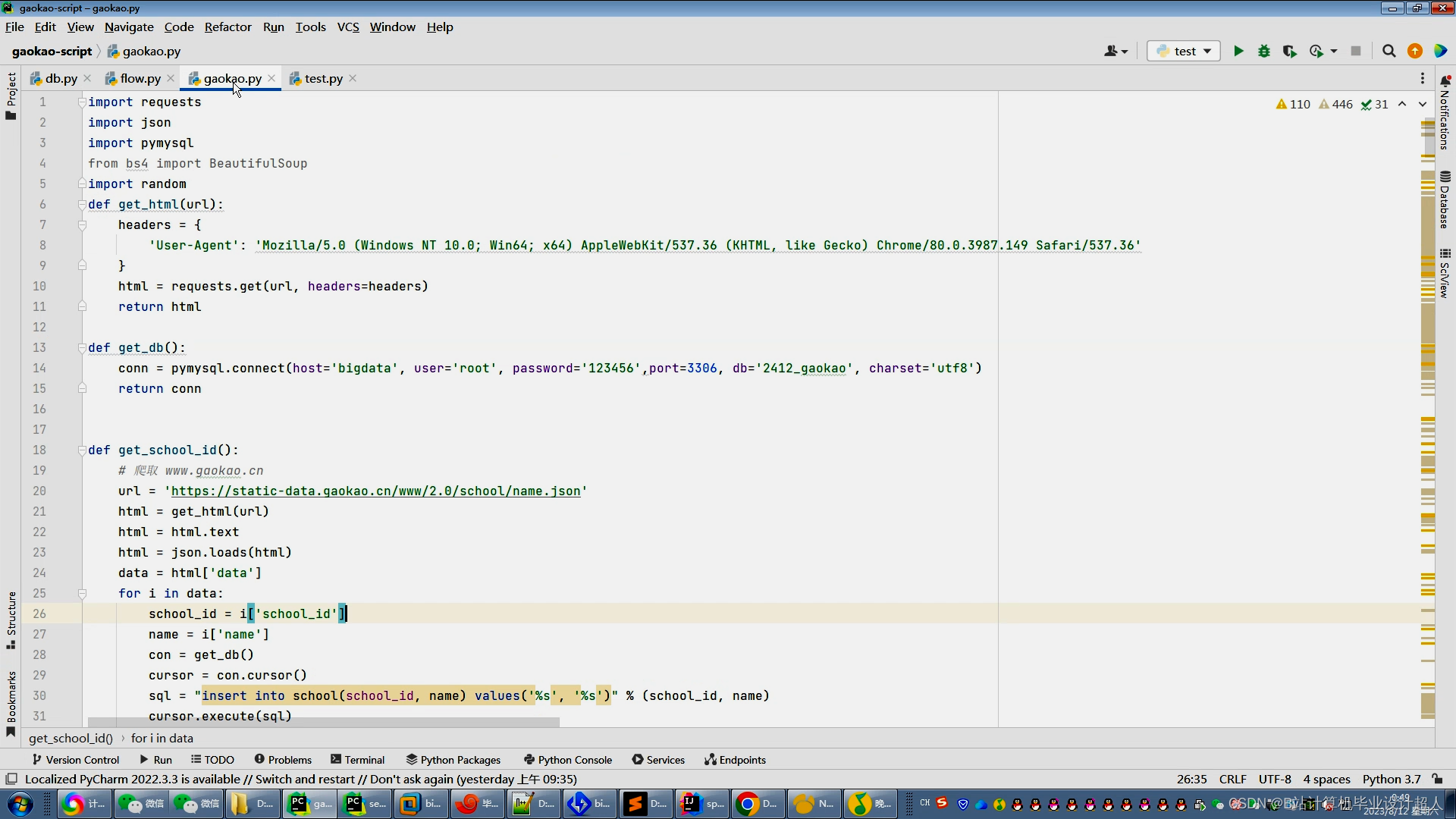
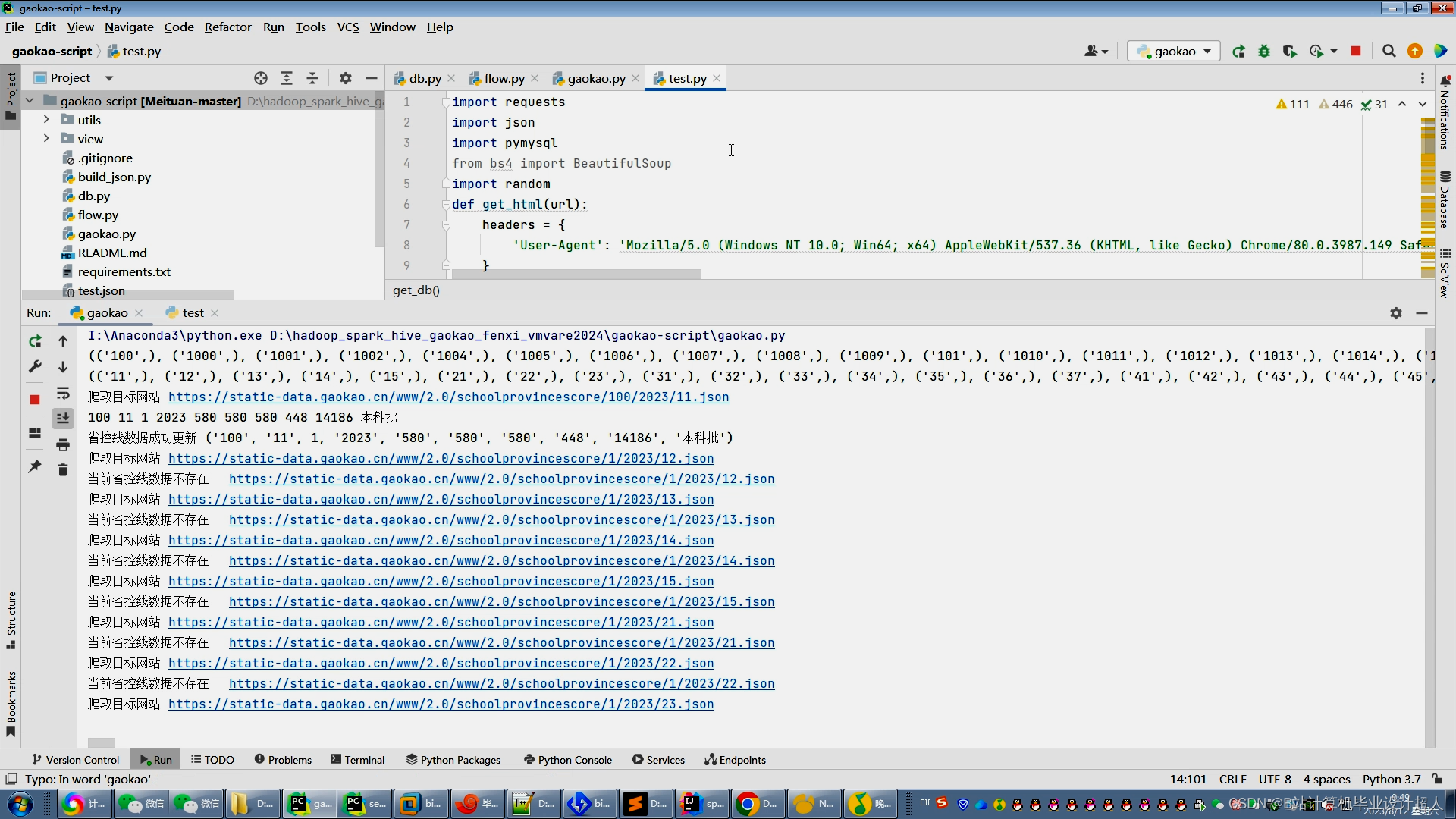
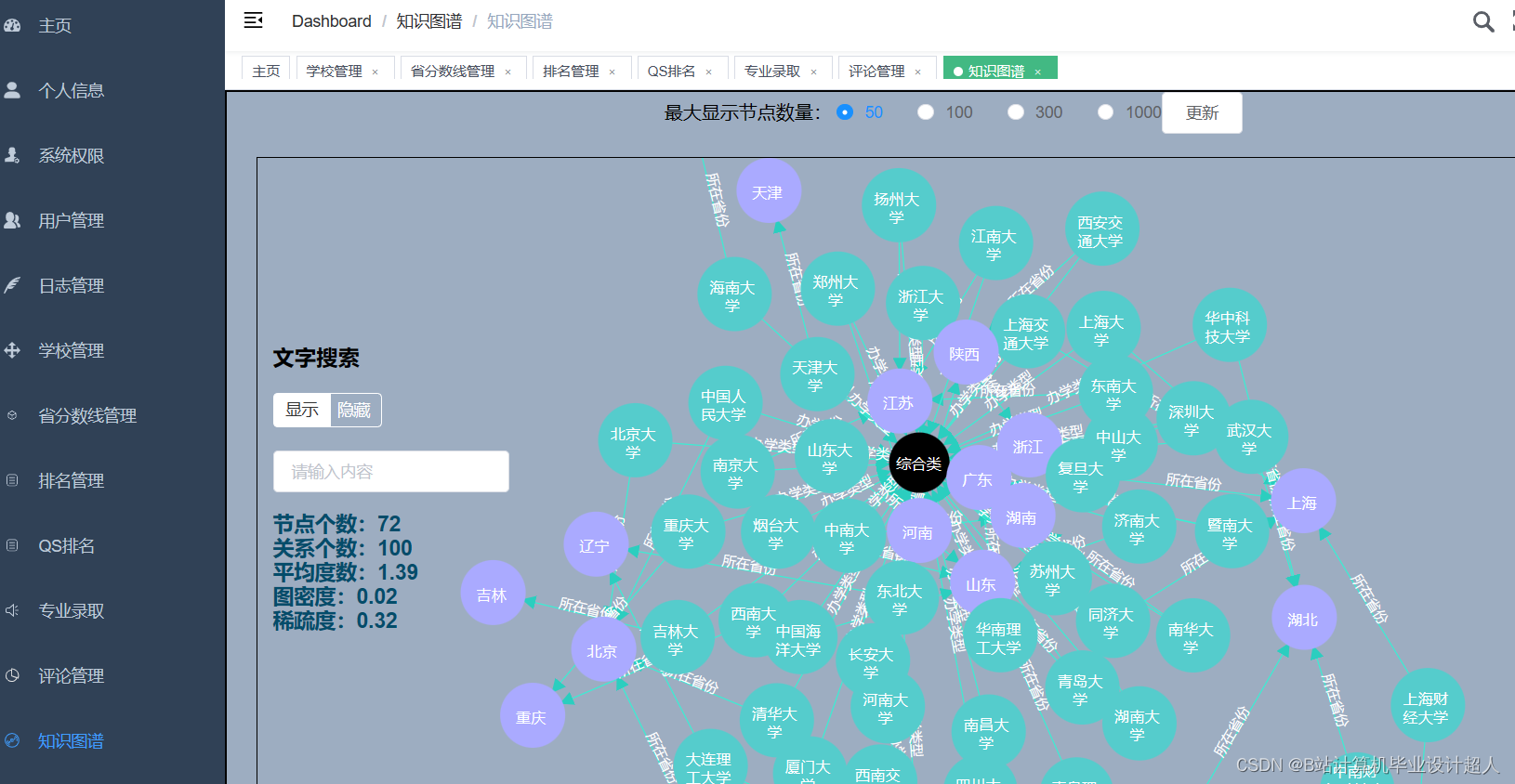
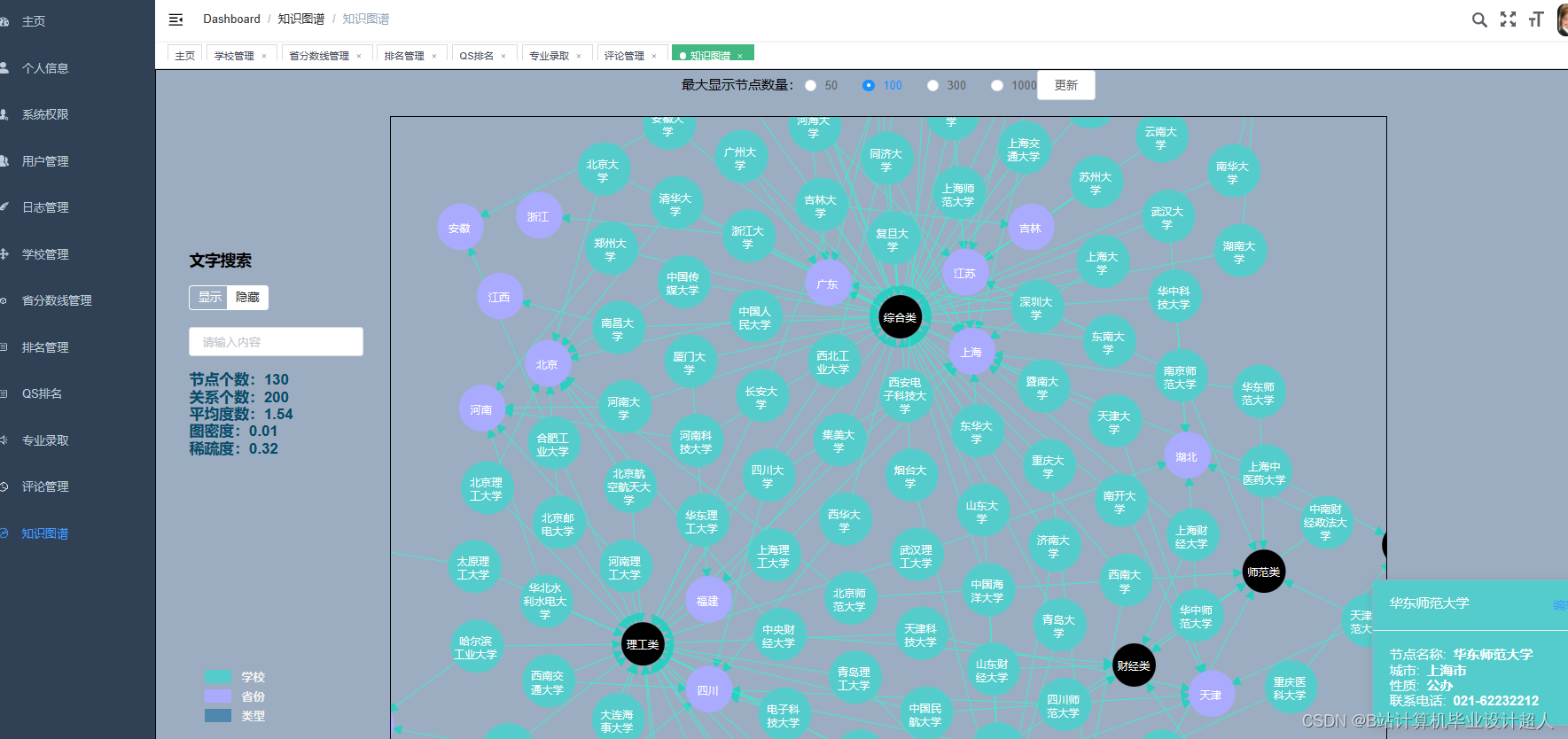
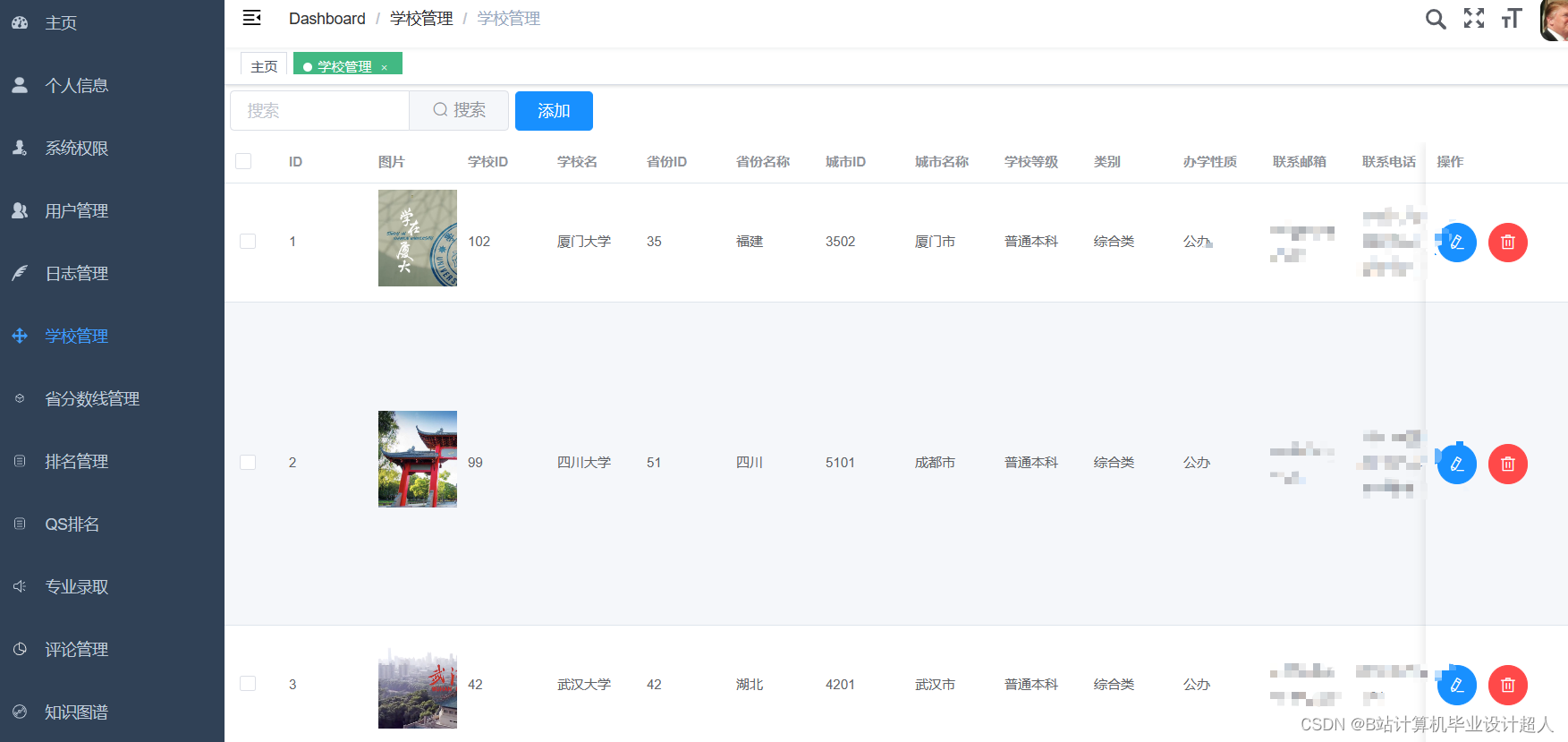
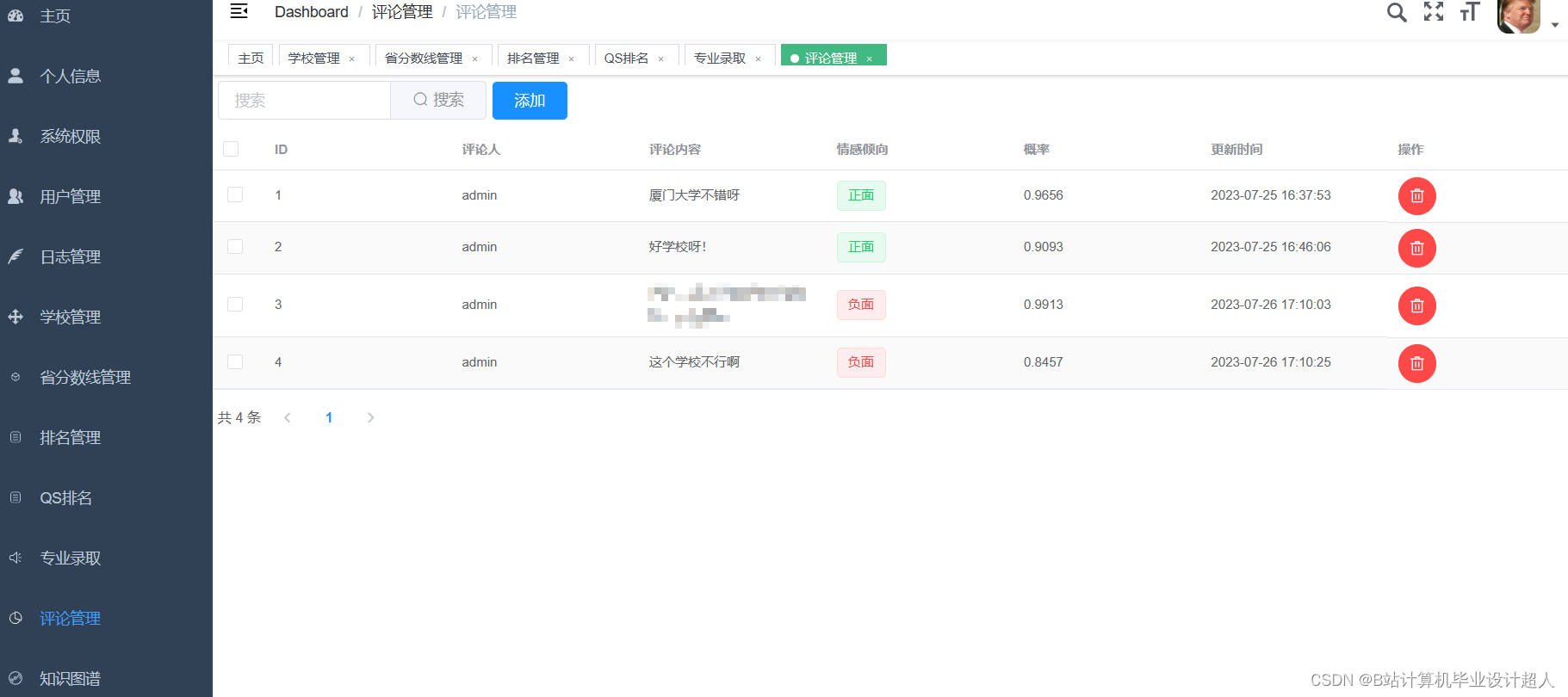
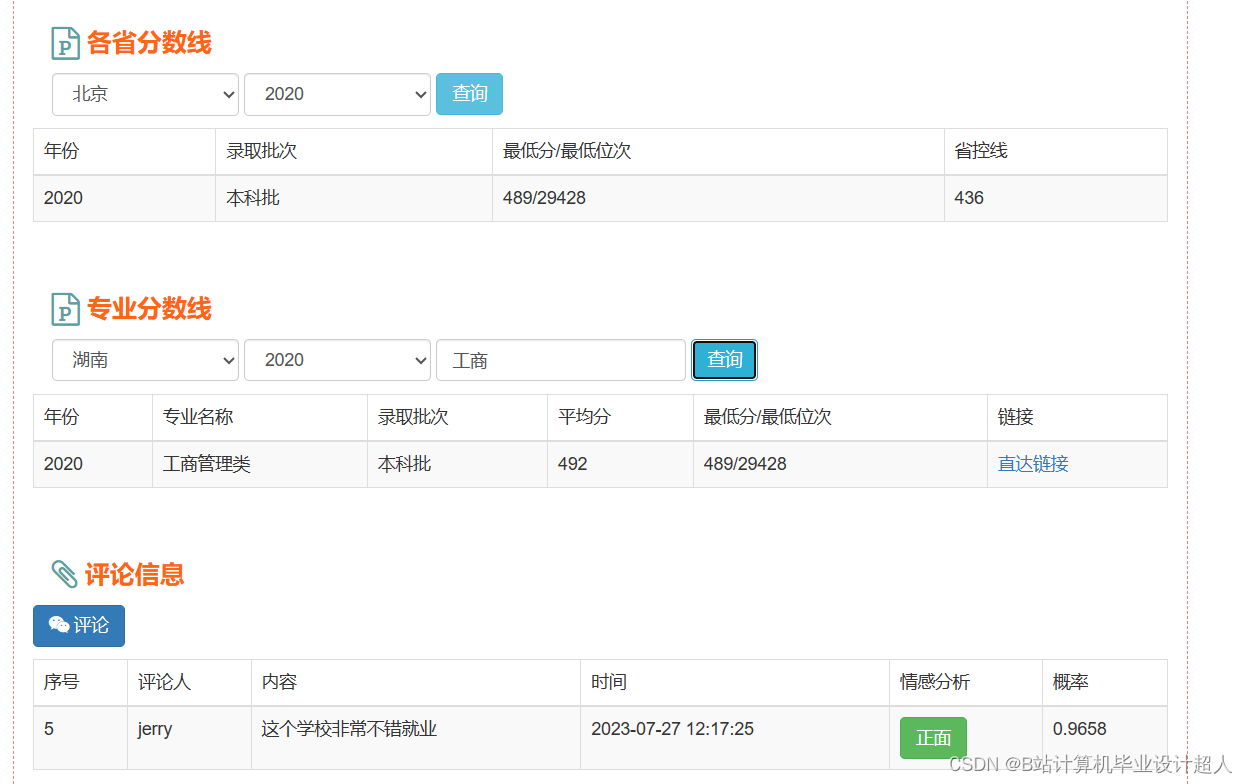
主要内容 1、推荐系统:包含协同过滤算法的两种实现(基于用户、基于物品)、基础业务功能; 2、后台管理系统:数据管理; 3、爬虫:爬取历年高考分数、高考院校信息,并可以实时更新; 4、数据大屏驾驶舱:使用Spark+Hadoop+Hive实时计算框架+离线数仓完成数据统计,以flask+echarts形式进行可视化显示; 设计(论文)提纲 1、论文提纲 摘要 英文摘要 1 引言
1.3 国内外研究现状 1.4 研究主要内容与技术 1.4.1研究内容 1.4.2研究技术 2 基于python爬虫的数据爬取和数据库的建立 2.1 高考信息表 2.5 数据库的建立 3 数据进行展示、科学分析和预测 3.1 基于spark+echarts进行可视化展示 3.2 推荐算法 3.4 情感分析 4 系统的建立和展示 4.1 基于springboot+mybatis后端开发 4.2 基于html、echarts、vue前端开发 4.3 系统的最终调试 5 结束语 参考文献 致谢 附录 | ||||||||
| 三、研究方法和手段 研究方法 1、按照设计题目要求设计毕业设计方案,配合指导教师进行设计; 2、明确数据的来源,查找数据的途径,确保数据的稳定性; 3、接受指导教师指导,定时汇报工作内容,并就相关问题进行讨论; 4、理论联系实际,培养正确的工作方法和严谨的科学态度; 5、按照进度计划完成毕业设计并书写毕业论文。 研究手段
| ||||||||
| 四、文献综述(在对选题涉及的研究领域的文献进行广泛阅读或调查的基础上,对该领域的研究现状、发展动态等内容进行综述,并提出自己的见解和研究思路。不少于700字) 1、传统填报方法效率低、效果差。 目前,全国大部分省(自治区、直辖市)都是高考成绩公布后开始填报志愿,大部分家长和考生仅仅利用招生考试机构公布志愿填报日程几天时间,从近2700所高校和500多个专业中做出选择,对很多毫无经验的家长和考生来说“难于上青天”。因为影响高考志愿因素太多,如考生职业生涯规划、个人和家庭情况、分数、院校、专业、城市、高考志愿政策规则、填报策略技巧、近3到5年录取数据、录取概率测算、就业情况等,如果仅在几天内通过传统手段,以手工查阅书籍材料,往往会因为资料难找、耗时长、易疲劳出错等原因,填报志愿和最终录取去向往往不尽如人意[9]。 2、填报方案不科学,录取不满意案例多。 《中国青年报》社会调查中心发起的一项10万人参加的抽样调查,超过71.2%的人后悔当年的高考志愿。我们可以在新闻媒体或网络上看到很多志愿填报不科学的典型案例,其中很多是高材生。 2008年周某以青海省第三名的成绩被北京大学生命科学学院录取,两年后周某选择转学到了北京工业技师学院。2017年李某从中国科学技术大学退学补习,2018年高考以云南省理科第8名的好成绩拒绝清华大学和北京大学发出的邀请,选择了四川大学口腔专业。2017年广西理科高考第3名考生,填错高考志愿批次,最后通过征集获得录取。2017年浙江省646高分考生竟报考独立学院,全省被独立学院录取的600分以上考生多达9人。 现实中,还有很多高考过来人默默承受着高考志愿填报失误带来的痛,比如对专业不满意、对院校不满意、填错批次、错过填报时间、被退档、毕业后从事与自己所学专业毫无关联的工作等。 在本项目中主要研究的是传统文理分科的高考模式,因为这种模式有着大量的数据支撑,提供训练,能够高精度地做出预测。而新考高模式刚刚施行,其数据是不足以支撑训练,从而做出预测。高考录取填报推荐志愿方式,梯度志愿和混合录取,经过不断优化,平行志愿已成为了高考录取的主流,大部分省份都采取平行志愿,所以本次项目也就平行志愿的录取方式来进行研究。即分数优先,满足偏好的方式,所以本项目着重对学生位次进行研究。针对高考这一热门话题,国内外都有着不少的专家学者对其进行研究,在过去的实践中,人们往往选用经典的时间序列方法来解决预测高校录取问题,即利用近5年高校录取的分数线,名次求平均值来预测当年的分数线,但是利用时间序列预测,就必须保证时间序列的过去值、当前值、和未来值之间存在着某种确定的函数关系。所以这养的预测是不够精确,不够完善的。除了基于时间序列的预测以外,还有人通过录取线差法来对高考录取进行研究,所谓录取线差是指考生意向院校当年平均录取分数与其所在招生批次录取控制分数线的差值。但是,每年高考试卷难度有别,造成了各个院校各年度的录取分数可能发生较大的变化。 综合来看,基于Spark的高考志愿推荐系统的相关研究在国内外都不多,未来的发展空间都很大。在未来的研究中可以结合数据分析、规划优化、机器学习和推荐算法等领域的相关方法,利用Spark的大数据处理能力,设计和实现一套可行的高考志愿推荐系统。这将为考生提供更好的填报建议,提升高考志愿填报的准确性和个性化程度。 | ||||||||
| 五、参考文献(作者、书名或设计(论文)题目、出版社或刊号、出版年月或出版期号) [1]孙浩然,武雪明,吉雪芸.高考志愿智能推荐系统的设计与实现[J].电脑知识与技术,2023,19(09):41-45.DOI:10.14004/j.cnki.ckt.2023.0427. [2]白俊杰. 基于混合推荐的高考志愿推荐系统的设计与实现[D].内蒙古大学,2022.DOI:10.27224/d.cnki.gnmdu.2022.001490. [3]孟真. 基于Spark的高考推荐系统设计与实现[D].山东师范大学,2017. [4]银虹宇. 基于大数据的高考志愿推荐系统的设计与实现[D].电子科技大学,2018. [5]谢雷,唐旭,钟立国. 基于Spark的高考志愿填报系统设计与实现[J]. 计算机工程与设计, 2017, 38(9): 2461-2465. [6]唐旭,钟立国,谢雷. 基于Spark的高考志愿填报系统设计与实现[J]. 现代计算机, 2019, 40(8): 129-132. [7]李坤,田田. 基于Spark的高考志愿填报系统设计与实现[J]. 电脑知识与技术, 2019, 15(3): 80-81. [8]陈娟,黄林伟. 基于Spark的高考志愿填报系统设计与实现[J]. 现代电子技术, 2020, 43(4): 181-184. [9]基于Spark的高考志愿填报系统设计与实现 作者:谢雷,唐旭,钟立国 出处:《计算机工程与设计》,2017年,第38卷,第9期 [10]Guo, M., Zhang, J., Zhang, J., & Li, J. (2020). Research on Design and Implementation of College Entrance Examination Volunteer Recommendation System Based on Spark. In 2020 International Conference on Artificial Intelligence and Big Data (ICAIBD) (pp. 104-107). [11]Wang, Y., Liu, W., Zhu, M., Li, H., & Li, J. (2019). Design and Implementation of College Entrance Examination Volunteer Recommendation System Based on Big Data Analysis. In 2019 2nd International Conference on Mathematics, Modeling, Simulation and Education Application (MMSEA) (pp. 1-4). [12]Wang, Z., & Guo, C. (2018). Design and Implementation of College Entrance Examination Volunteer Recommendation System Based on Big Data Analysis. In 2018 IEEE International Conference on Big Data (Big Data) (pp. 4494-4496). [13]Zhang, Y., & Li, S. (2018). Design and Implementation of College Entrance Examination Volunteer Recommendation System Based on Spark. In 2018 International Conference on Data Science and Advanced Analytics (DSAA) (pp. 535-539). [12] 王琴.基于Bootstrap技术的高校门户网站设计与实现[J].哈尔滨师范大学自然科学学报,2023,33(03):43-48 [13]周寅,张振方,周振涛,张杨,基于Java Web的智慧医疗问诊管理系统的设计与应用[J].中国医学装备,2022,18(8):132-135. [14]王福东,程亮.基于传统组态软件与Java相结合的水位监测分析系统[J].自动化技术与应用,2021,40(9):24-28. [15] 佘青.利用Apache Jmeter进行Web性能测试的研究[J].智能与应用,2021,2(02):55-57 | ||||||||
| 六、工作进度安排(时间、内容、步骤)
| ||||||||
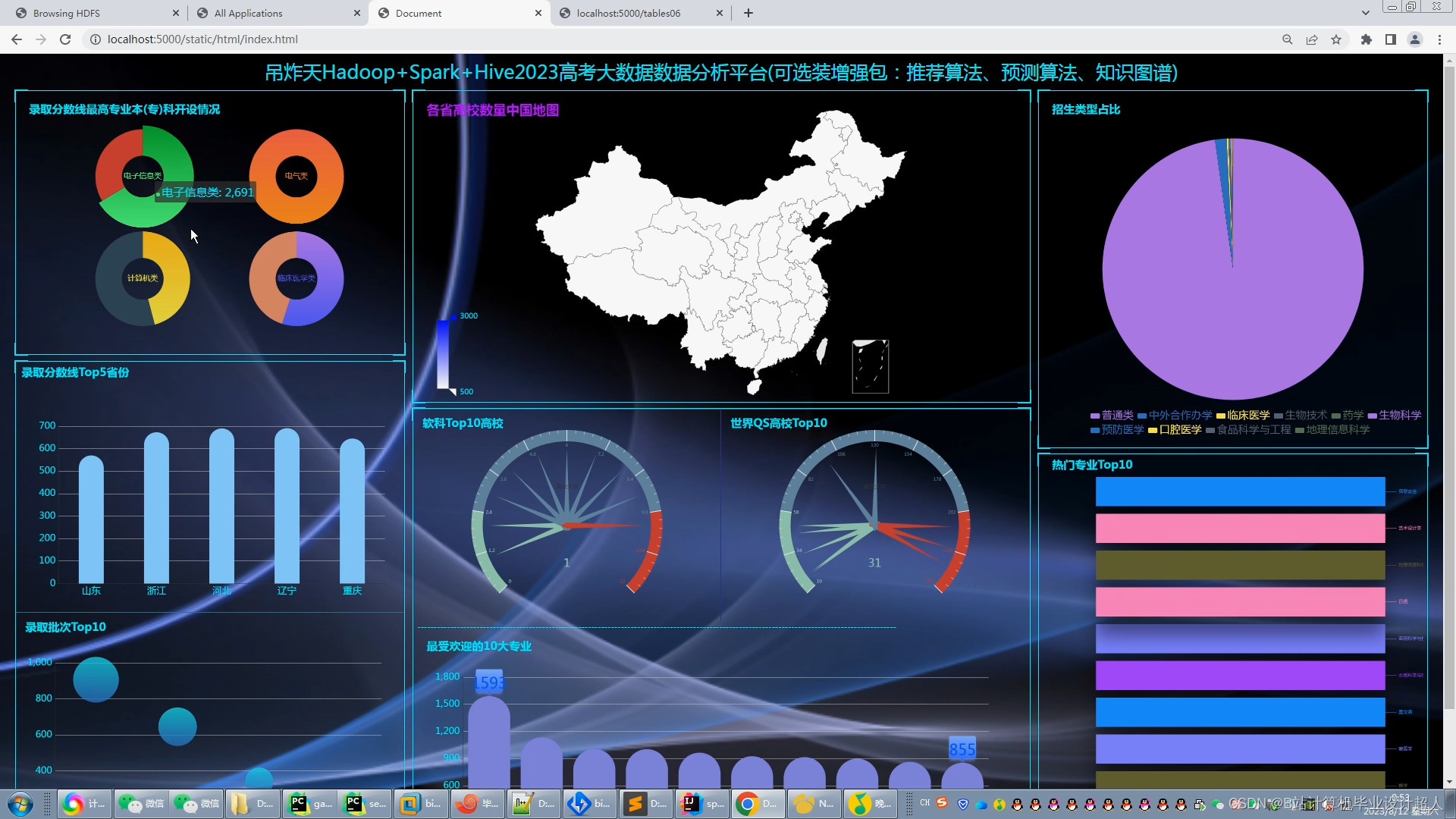
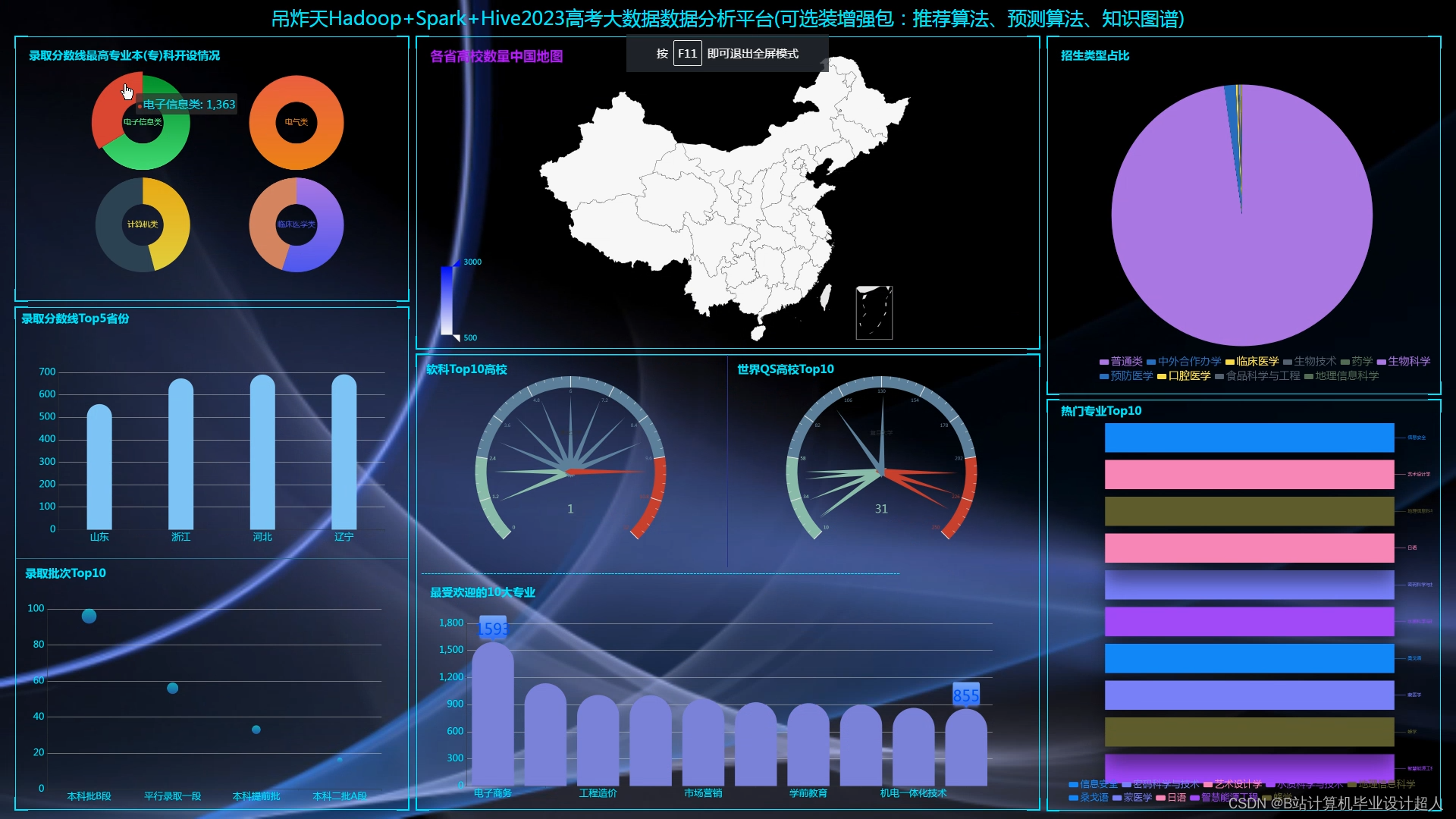
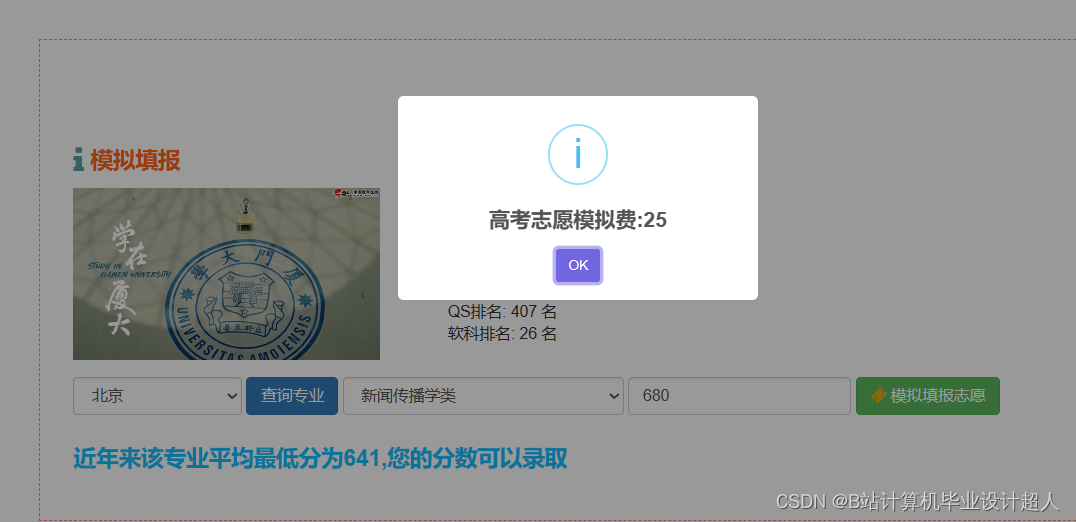
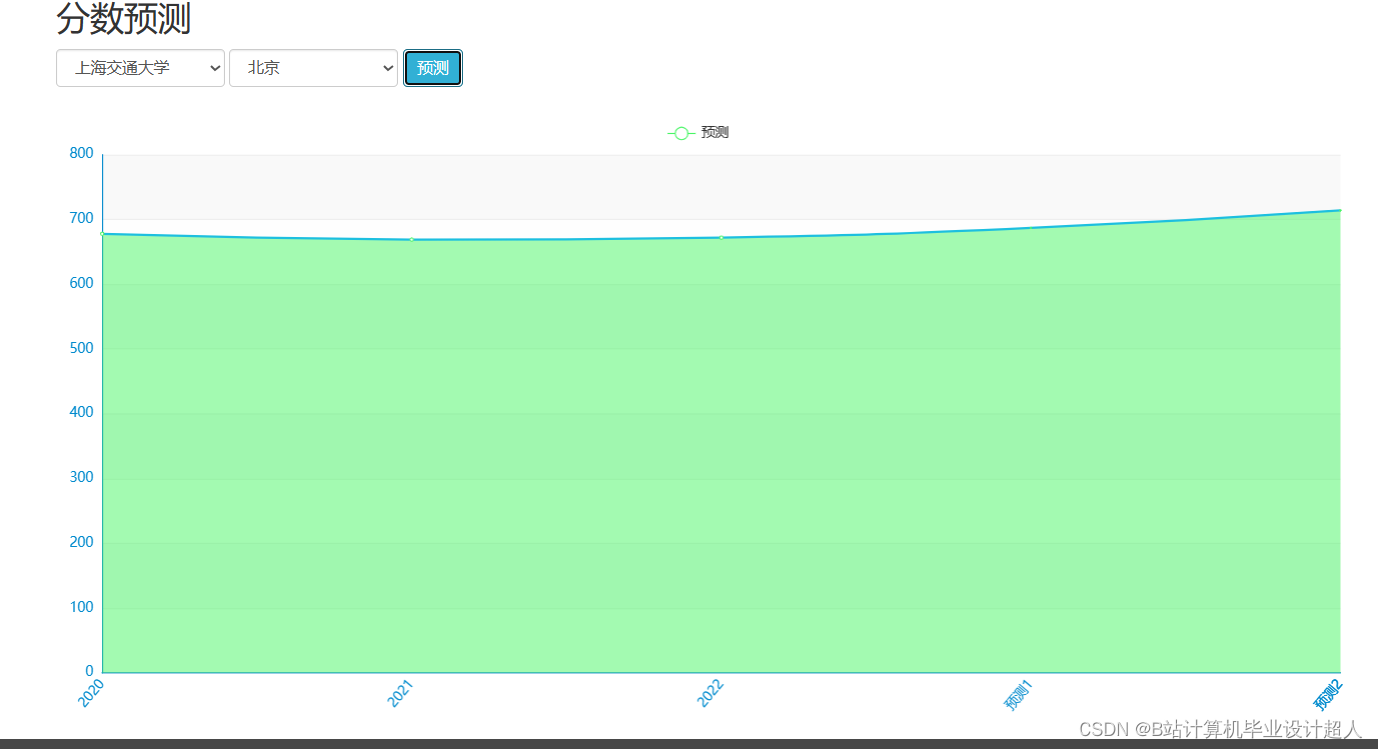
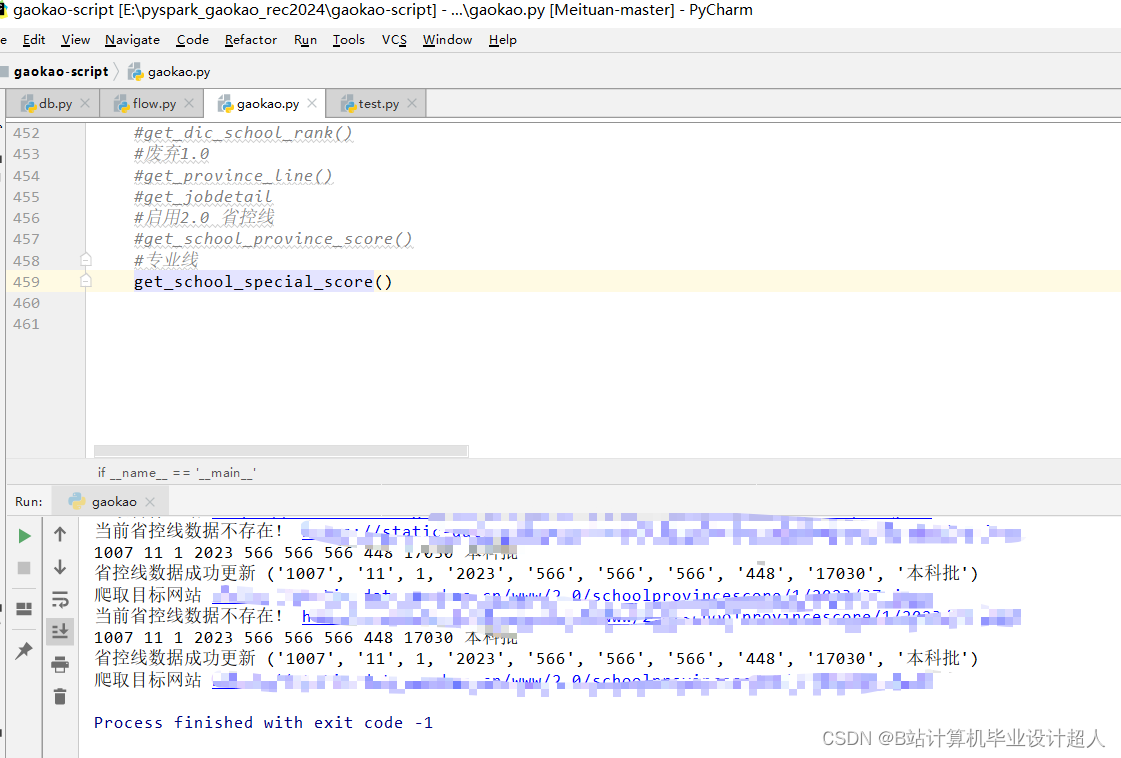
| 七、预期成果 完整的虚拟机文件含hadoop、spark、hive、mysql、sqoop等大数据环境; 有效的高考志愿推荐算法,可以进行个性化推荐。有4种机器学习实现方法; 可以使用线性回归算法进行高考分数预测; 使用hadoop+spark+hive进行离线、实时计算分析,呈现一张高考可视化大屏; Springboot+vue.js后台管理系统可以进行数据管理; Selenium采集大约10W+今年高考省控线、专业线、专业信息等数据集; | ||||||||
| (以上内容在教师指导下由学生填写) 学生签名: 年 月 日 | ||||||||
| 八、指导教师审核意见: 指导教师签名: 年 月 日
| ||||||||

高考志愿推荐通常涉及到多个因素,比如学生的兴趣爱好、成绩、特长、职业规划等。这里给出一个简单的示例,假设使用学生的成绩作为推荐的依据,基于 PyTorch 实现一个简单的推荐算法:
- import torch
- import torch.nn as nn
- import torch.optim as optim
-
- # 假设有5个学生和10个专业
- num_students = 5
- num_majors = 10
- input_dim = 3 # 假设输入特征为3维,比如语文、数学、英语成绩
-
- # 模拟学生的成绩数据(学生ID,语文成绩,数学成绩,英语成绩,专业ID)
- scores = torch.tensor([[0, 80, 75, 85, 1],
- [1, 85, 78, 80, 3],
- [2, 90, 82, 88, 5]], dtype=torch.float)
-
- # 创建学生和专业的嵌入矩阵
- student_embedding = nn.Embedding(num_students, input_dim)
- major_embedding = nn.Embedding(num_majors, input_dim)
-
- # 定义模型
- class MajorRecommendation(nn.Module):
- def __init__(self, num_students, num_majors, input_dim):
- super(MajorRecommendation, self).__init__()
- self.student_embedding = nn.Embedding(num_students, input_dim)
- self.major_embedding = nn.Embedding(num_majors, input_dim)
-
- def forward(self, student_ids, major_ids):
- student_emb = self.student_embedding(student_ids)
- major_emb = self.major_embedding(major_ids)
- # 计算学生和专业之间的内积作为预测分数
- preds = torch.sum(student_emb * major_emb, dim=1)
- return preds
-
- # 初始化模型和优化器
- model = MajorRecommendation(num_students, num_majors, input_dim)
- optimizer = optim.Adam(model.parameters(), lr=0.01)
-
- # 训练模型
- for epoch in range(100):
- optimizer.zero_grad()
- student_ids = scores[:, 0].long()
- major_ids = scores[:, -1].long()
- ratings = torch.sum(scores[:, 1:-1], dim=1) # 使用总分作为评分
-
- preds = model(student_ids, major_ids)
- loss = nn.MSELoss()(preds, ratings)
- loss.backward()
- optimizer.step()
-
- print(f'Epoch {epoch+1}, Loss: {loss.item()}')
-
- # 使用模型进行推荐
- student_id = torch.tensor([0])
- major_ids = torch.arange(num_majors)
- predicted_scores = model(student_id, major_ids)
-
- print('Predicted scores for student 0:')
- print(predicted_scores)

在这个示例中,我们假设每个学生的成绩是一个3维的向量(比如语文、数学、英语成绩),然后使用学生和专业的 Embedding 层来学习学生和专业的表示。在训练过程中,模型尝试预测学生与专业之间的匹配程度,并通过均方误差损失函数进行优化。最后,使用训练好的模型进行推荐时,可以输入学生ID,得到对所有专业的预测分数。
当然,实际的高考志愿推荐涉及到更多复杂的因素,比如学生的兴趣爱好、特长等,这个示例只是一个简单的起点。希望这个示例能对你有所帮助!如有任何问题,请随时提出。

