
热门标签
热门文章
- 1JMeter WebSocket 接口测试详解_jmeter连接websocket接口
- 2傻傻的分不清Redis Stack和Redis关系,全新体验:全文搜索、向量数据库、文档数据库,真的很香。_redis-stack和redis
- 3iOS object-c 常用API汇总
- 4Java 最常见的 208 道面试题:第十六模块答案 Zookeeper
- 5macOS安装sql server_mac安装sqlserber
- 6HTML5 Canvas 绘图教程一
- 7C# PaddleInference OCR 表格识别_sdcb.paddleinference
- 8Merge branch ‘master‘ of_merge branch master of
- 9华为设备动态路由OSPF(单区域+多区域)实验_华为单区域ospf配置
- 10Go Module 私有仓库:fatal: could not read Username for ‘https://xxx.com‘: terminal prompts disabled_invalid version: git ls-remote -q origin
当前位置: article > 正文
ChatGLM系列三:Freeze微调
作者:我家自动化 | 2024-06-06 12:09:29
赞
踩
freeze微调
目前主流对大模型进行微调方法有三种:Freeze方法、P-Tuning方法和Lora方法。
Freeze: 即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或不进行TP或PP操作,就可以对大模型进行训练。
Freeze仅训练模型后五层的全连接层参数
训练、评估也是基于ChatGLM-Efficient-Tuning框架
下载代码
git clone https://github.com/liucongg/ChatGLM-Finetuning
- 1
环境配置
cpm_kernels==1.0.11
deepspeed==0.9.0
numpy==1.24.2
peft==0.3.0
sentencepiece==0.1.96
tensorboard==2.11.0
tensorflow==2.13.0
torch==1.13.1+cu116
tqdm==4.64.1
transformers==4.27.1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
模型微调时,如果遇到显存不够的情况,可以开启gradient_checkpointing、zero3、offload等参数来节省显存。下面model_name_or_path参数为模型路径,请根据可根据自己实际模型保存地址进行修改。
修改train_type=freeze及其freeze_module_name参数
(1)、ChatGLM单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type freeze \
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24." \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(2)、ChatGLM四卡训练:设置CUDA_VISIBLE_DEVICES参数
通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type freeze \
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24." \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(3)、ChatGLM2单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type freeze \
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24." \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(4)、ChatGLM2四卡训练:设置CUDA_VISIBLE_DEVICES参数
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B/ \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type freeze \
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24." \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
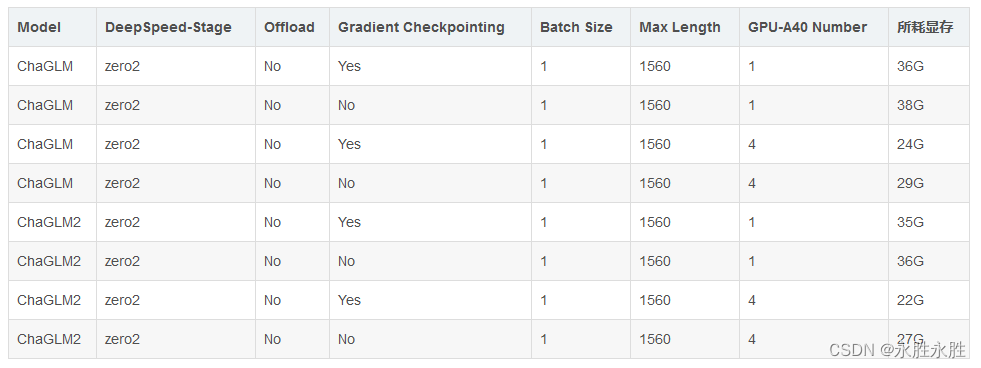
(5)、耗费显存资源占用对比—Freeze方法:对比ChaGLM和ChaGLM2
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/680859
推荐阅读
相关标签

