
- 1one piece_娜美_01_one piece hentai
- 2CrossOver软件2023破解激活码_crossover-wine注册
- 3Spring Boot(四):Thymeleaf 使用详解_spring thymeleaf
- 4NX+Ubuntu18.04+ROS Realsense(RealSenseD435i )的安装与使用_realsense安装
- 5记录:rosdep update
- 6js通过a标签的方式下载文件并对其重命名的完整方案_a标签下载文件重命名
- 7JavaScript中的Array.prototype.forEach()方法(简介+重写)_js array.prototype.foreach
- 8leetcode 94 二叉树的中序遍历(java)_lecode中树的输入root = [1,null,3,2,4,null,5,6]是怎么转化成节点的
- 9R语言入门笔记2.1
- 10c#--正则表达式(项目常用)_c# 正则表达式 数字
LLM之RAG实战(二十二)| LlamaIndex高级检索(一)构建完整基本RAG框架(包括RAG评估)
赞
踩

在RAG(retrieval Augmented Generation,检索增强生成)系统中,检索到文本的质量对大型语言模型生成响应的质量是非常重要的。检索到的与回答用户查询相关的文本质量越高,你的答案就越有根据和相关性,也更容易防止LLM幻觉(产生错误或不基于特定领域文本的答案)。
在这系列文章中,我们分三篇文章来介绍,首先会介绍LlamaIndex构建基本RAG,然后深入研究一种从小到大的高级检索技术,包括:句子窗口检索和父文档检索。
本文将介绍基本的RAG流程,使用Triad评估RAG管道的性能,并构建一个仪表板来帮助跟踪所有这些不同的指标。
一、“从小到大”检索介绍
假设你想将构建RAG管道的特定领域文本分解成更小的块或片段,每个块或片段包含200个单词。假设一个用户问了一个问题,而这个问题只能用你200个单词中的一行句子来回答,而块中的其余文本可能会使检索器很难找到与回答用户问题最相关的一句话。考虑到有些人使用的单词块大小高达1000多个,发现一个相关的句子可能是一个挑战,这就像大海捞针。我们暂时不谈成本问题。
那么,有什么解决方案,或者可能的解决方法呢?这里介绍一种解决方案:“小到大检索”技术。在传统的RAG应用程序中,我们使用相同的数据块来执行搜索检索,并将相同的块传递给LLM,以使用它来合成或生成答案。如果我们将两者解耦,这不是更好吗?也就是说,我们有一段文本或块用于搜索,另一段块用于生成答案。用于搜索的块比用于合成或生成最终答案的块小得多,以避免出现幻觉问题。
让我们用一个例子来详细地解释一下这个概念。取一个100个单词的分块,对于这个分块,我们创建10个较小的块,每个块10个单词(大致为一个句子)。我们将使用这10个较小的块来进行搜索,以找到与回答用户问题最相关的句子。当用户提问时,我们可以很容易地从10个较小的句子块中找到最相关的句子。换言之,不要虚张声势,直接切入正题。基于嵌入的检索在较小的文本大小下效果最好。
块大小越小,嵌入后就越准确地反映其语义
那么在从10个较小的句子中找到最相关的句子后该怎么办?好问题!你可能会想得很好,让我们把它发送到LLM(大型语言模型),根据我们检索到的最相关的句子合成一个响应。这是可行的,但LLM只有一句话,没有足够的上下文。想象一下,我告诉你只用公司文件中的一句话来回答一个关于该公司的问题。这很难做到,不是吗?因此,仅仅将最相关的较小块输入给LLM,可能会使LLM(大型语言模型)开始产生幻觉来填补其知识空白和对整个数据的理解。
解决这一问题的一种方法是让较小的块与父块(本例中为原始的100字块)相关,这样LLM将有更多的上下文来作为答案的基础,而不是试图生成自己的幻觉信息。换言之,10个单词的每个较小组块将与100个单词的较大组块相关,并且当给定的较小组块(10个单词组块)被识别为与回答用户问题相关时,父组块(100个单词组组块)将被检索并被发送到LLM。
以上就是“从小到大”检索技术背后的全部思想,而且效果非常好。这里介绍两种类型的“小到大检索”。
二、“从小到大”检索类型
2.1 父文档检索
首先检索与查询最相关的较小数据段,然后将相关的较大的父数据块作为上下文传递给LLM(大型语言模型)。在LangChain中,可以使用ParentDocumentRetriever来完成。
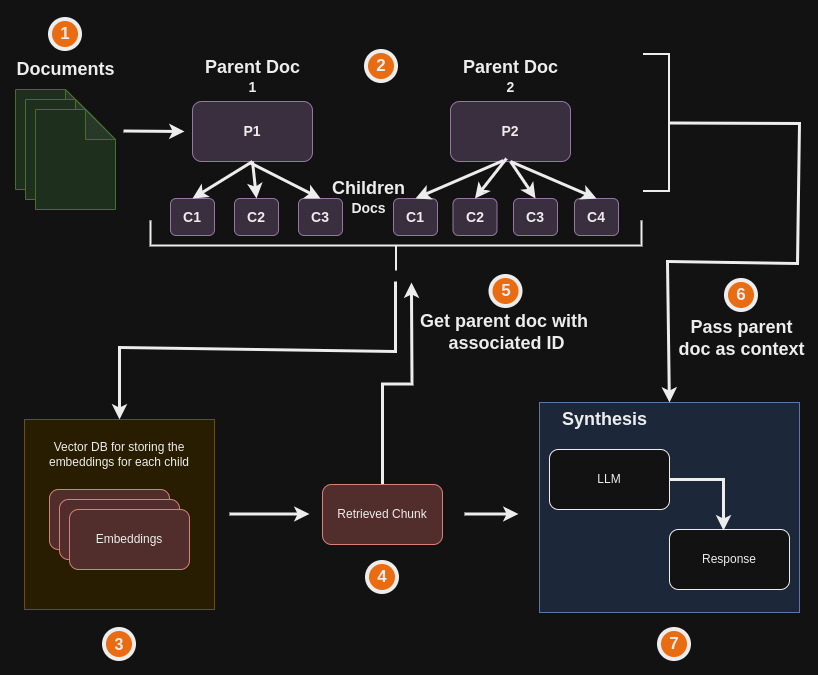
2.2 句子窗口检索
句子窗口检索首先检索与回答查询最相关的特定句子,然后返回该句子上下文几个句子来为LLM提供更多的上下文作为其响应的基础。


三、构建基本的RAG管道
关于使用LangChain构建基本的RAG管道,可以参考文档[1]。在本节中,我们将讨论如何在LlamaIndex中进行同样的操作,LlamaIndex是一个用于构建RAG应用程序的Python库。
下图展示了构建基本RAG的管道的步骤:

关于RAG管道更详细的图示说明,可以参考文档[2]。
3.1 项目结构
整个项目结构如下图所示:

继续创建一个项目文件夹,在此文件夹中确保您有以下文件。
3.2 下载数据文件
有了这个项目结构,你现在需要从[3]下载一个工会演讲的文本文件。下载完成后,您的项目文件夹应该如下所示:
3.3 OpenAI API密钥
我们还将使用OpenAI的嵌入模型和GPT-3.5 turbo。因此,需要确保您有OpenAI API Key,如果没有,可以在这里[4]申请。获得API密钥后,在项目文件夹的根目录中创建一个.env文件。创建完此文件后,按以下方式添加内容,确保替换实际的API密钥。
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
3.4 安装相关库和依赖
我们将使用许多Python库来实现RAG系统。
首先,让我们继续创建一个虚拟环境,这是您在项目结构中看到的venv文件。如果你已经创建了一个venv文件,请先删除它。完成后,在导航到项目目录的根目录时运行此命令。
python3 -m venv venv要激活虚拟环境,对于Linux和MacOS用户,请使用以下命令。如果你在Windows机器上,可以参考这里[5]。
source venv/bin/activate您会注意到venv文件夹的名称出现在终端中终端内行的开头

激活虚拟环境后,请使用以下命令安装我们将使用的库:
pip install llama-index python-decouple trulens-eval如果您缺少任何库,只需通过阅读错误并安装该库即可。
完成了所有的设置,让我们最后写一些代码。在basicRAG文件夹中,创建一个main.py文件。

3.5 加载文档
第一步是加载我们想要创建RAG系统的文档。以下是如何在LlamaIndex中加载文档。
from llama_index import ( VectorStoreIndex, SimpleDirectoryReader)# for loading environment variablesfrom decouple import configimport os# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# load documentdocuments = SimpleDirectoryReader( input_dir="../dataFiles").load_data(show_progress=True)# check documentprint(len(documents))print(documents[0])
如果您不想显示加载程序,可以在SimpleDirectoryReader对象中将.load_data方法中的show_loading设置为False。
3.6 将文档拆分为块
可以注意到的一件事是,文档在一个块中,让我们将其拆分为多个块。LlamaIndex中的块称为“Nodes”。
from llama_index import ( VectorStoreIndex, SimpleDirectoryReader)from llama_index.node_parser import SimpleNodeParser# for loading environment variablesfrom decouple import configimport os# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# load documentdocuments = SimpleDirectoryReader( input_dir="../dataFiles").load_data(show_progress=True)# create nodes parsernode_parser = SimpleNodeParser.from_defaults(chunk_size=1024)# split into nodesbase_nodes = node_parser.get_nodes_from_documents(documents=documents)# examine base nodesprint(len(base_nodes))print(base_nodes[0])现在,我们已经将较大的文档拆分为块,也称为节点,具体来说是11个节点。

3.7 添加嵌入模型和LLM
我们将在LlamaIndex中使用gpt-3.5-turbo大模型,嵌入模型将使用OpenAI的text-davinci-003模型。
from llama_index import ( VectorStoreIndex, SimpleDirectoryReader, ServiceContext)from llama_index.node_parser import SimpleNodeParserfrom llama_index.embeddings import OpenAIEmbeddingfrom llama_index.llms import OpenAI# for loading environment variablesfrom decouple import configimport os# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# load documentdocuments = SimpleDirectoryReader( input_dir="../dataFiles").load_data(show_progress=True)# create nodes parsernode_parser = SimpleNodeParser.from_defaults(chunk_size=1024)# split into nodesbase_nodes = node_parser.get_nodes_from_documents(documents=documents)# create LLM and Embedding Modelembed_model = OpenAIEmbedding()llm = OpenAI(model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults( embed_model=embed_model, llm=llm)3.8 创建索引
我们将创建一个索引,通常会使用向量存储来存储嵌入,并对该文档执行查询以获得相关或类似的文档。
from llama_index import ( VectorStoreIndex, SimpleDirectoryReader, ServiceContext)from llama_index.node_parser import SimpleNodeParserfrom llama_index.embeddings import OpenAIEmbeddingfrom llama_index.llms import OpenAI# for loading environment variablesfrom decouple import configimport os# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# load documentdocuments = SimpleDirectoryReader( input_dir="../dataFiles").load_data(show_progress=True)# create nodes parsernode_parser = SimpleNodeParser.from_defaults(chunk_size=1024)# split into nodesbase_nodes = node_parser.get_nodes_from_documents(documents=documents)# create LLM and Embedding Modelembed_model = OpenAIEmbedding()llm = OpenAI(model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults( embed_model=embed_model, llm=llm)# creating indexindex = VectorStoreIndex(nodes=base_nodes, service_context=service_context)# create retrieverretriever = index.as_retriever(similarity_top_k=2)# test retrieverretrieved_nodes = retriever.retrieve("What did the president say about covid-19")print(retrieved_nodes)print("\n\n\n=============================================================")print("Node Texts")for node in retrieved_nodes: print(node.text) # get word count for each doc print(len(node.text.split())) print("==" * 10)3.9 将检索器插入查询引擎
现在让我们在查询引擎中使用我们上面创建的检索器。
from llama_index import ( VectorStoreIndex, SimpleDirectoryReader, ServiceContext)from llama_index.node_parser import SimpleNodeParserfrom llama_index.embeddings import OpenAIEmbeddingfrom llama_index.llms import OpenAIfrom llama_index.query_engine import RetrieverQueryEngine# for loading environment variablesfrom decouple import configimport os# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# load documentdocuments = SimpleDirectoryReader( input_dir="../dataFiles").load_data(show_progress=True)# create nodes parsernode_parser = SimpleNodeParser.from_defaults(chunk_size=1024)# split into nodesbase_nodes = node_parser.get_nodes_from_documents(documents=documents)# create LLM and Embedding Modelembed_model = OpenAIEmbedding()llm = OpenAI(model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults( embed_model=embed_model, llm=llm)# creating indexindex = VectorStoreIndex(nodes=base_nodes, service_context=service_context)# create retrieverretriever = index.as_retriever(similarity_top_k=2)# query retriever enginequery_engine = RetrieverQueryEngine.from_args( retriever=retriever, service_context=service_context)# test responseresponse = query_engine.query("What did the president say about covid-19")print(response)
3.10 持久化向量存储
每次我们运行代码时,都会创建新的嵌入,因为到目前为止,嵌入只存储在内存中,这可能很昂贵,而且不是最好的策略。我们最好把它存储在文件或磁盘上的存储中,这样每次程序都可以很方便地加载,代码如下。
from llama_index import ( StorageContext, VectorStoreIndex, SimpleDirectoryReader, ServiceContext, load_index_from_storage)from llama_index.node_parser import SimpleNodeParserfrom llama_index.embeddings import OpenAIEmbeddingfrom llama_index.llms import OpenAIfrom llama_index.query_engine import RetrieverQueryEngine# for loading environment variablesfrom decouple import configimport os# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# create LLM and Embedding Modelembed_model = OpenAIEmbedding()llm = OpenAI(model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults( embed_model=embed_model, llm=llm)# check if data indexes already existsif not os.path.exists("./storage"): # load data documents = SimpleDirectoryReader( input_dir="../dataFiles").load_data(show_progress=True) # create nodes parser node_parser = SimpleNodeParser.from_defaults(chunk_size=1024) # split into nodes base_nodes = node_parser.get_nodes_from_documents(documents=documents) # creating index index = VectorStoreIndex(nodes=base_nodes, service_context=service_context) # store index index.storage_context.persist()else: # load existing index storage_context = StorageContext.from_defaults(persist_dir="./storage") index = load_index_from_storage(storage_context=storage_context)# create retrieverretriever = index.as_retriever(similarity_top_k=2)# query retriever enginequery_engine = RetrieverQueryEngine.from_args( retriever=retriever, service_context=service_context)# test responseresponse = query_engine.query("What did the president say about covid-19")print(response)运行完这段代码后,您应该注意到项目目录中有一个名为storage的文件夹,该文件夹存储了所有的嵌入,这意味着您不必每次运行代码时都创建它们。它不仅更快,而且更便宜。
四、RAG管道评估
为了真正了解RAG管道的性能,可以对其进行评估,并确保您的RAG应用程序免受黑客攻击和其他您不希望在生产中发生的事情。
为了评估我们刚刚创建的基本RAG管道,我们将使用RAG Triad。
4.1 RAG Triad介绍
RAG Triad由训练主要指标组成,我们可以使用这些指标来评估模型并量化其性能。
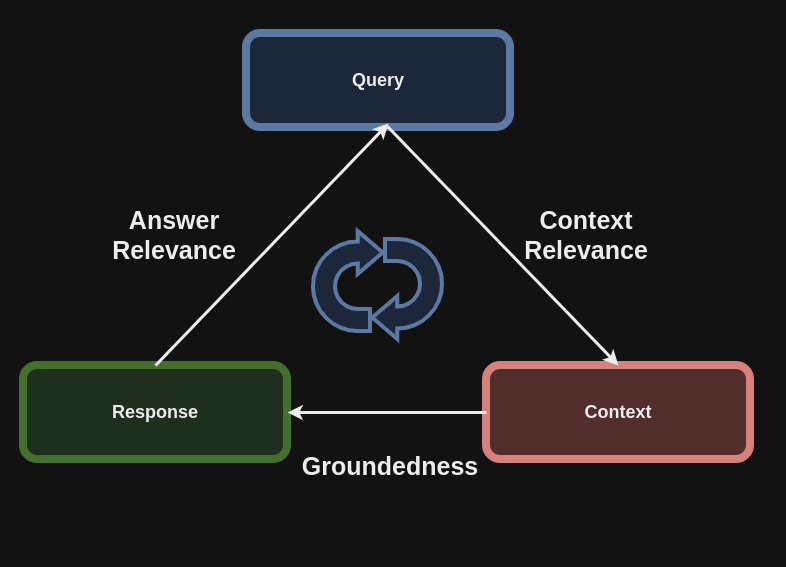
Answer Relevance:答案与查询或用户问题的相关性如何?
Context Relevance:检索到的上下文与回答用户问题的相关性如何?
Groundedness:检索到的上下文在多大程度上支持响应?
以下是TruEra官网评估RAG管道的代码,其他更多评估指标,可以参考[6]。
from llama_index import ( StorageContext, VectorStoreIndex, SimpleDirectoryReader, ServiceContext, load_index_from_storage)from llama_index.node_parser import SimpleNodeParserfrom llama_index.embeddings import OpenAIEmbeddingfrom llama_index.llms import OpenAIfrom llama_index.query_engine import RetrieverQueryEnginefrom trulens_eval import Feedback, Tru, TruLlamafrom trulens_eval.feedback import Groundednessfrom trulens_eval.feedback.provider.openai import OpenAI as OpenAITruLensimport numpy as np# for loading environment variablesfrom decouple import configimport os# set env variablesos.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")# create LLM and Embedding Modelembed_model = OpenAIEmbedding()llm = OpenAI(model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults( embed_model=embed_model, llm=llm)# check if data indexes already existsif not os.path.exists("./storage"): # load data documents = SimpleDirectoryReader( input_dir="../dataFiles").load_data(show_progress=True) # create nodes parser node_parser = SimpleNodeParser.from_defaults(chunk_size=1024) # split into nodes base_nodes = node_parser.get_nodes_from_documents(documents=documents) # creating index index = VectorStoreIndex(nodes=base_nodes, service_context=service_context) # store index index.storage_context.persist()else: # load existing index storage_context = StorageContext.from_defaults(persist_dir="./storage") index = load_index_from_storage(storage_context=storage_context)# create retrieverretriever = index.as_retriever(similarity_top_k=2)# query retriever enginequery_engine = RetrieverQueryEngine.from_args( retriever=retriever, service_context=service_context)# RAG pipeline evalstru = Tru()openai = OpenAITruLens()grounded = Groundedness(groundedness_provider=OpenAITruLens())# Define a groundedness feedback functionf_groundedness = Feedback(grounded.groundedness_measure_with_cot_reasons).on( TruLlama.select_source_nodes().node.text ).on_output( ).aggregate(grounded.grounded_statements_aggregator)# Question/answer relevance between overall question and answer.f_qa_relevance = Feedback(openai.relevance).on_input_output()# Question/statement relevance between question and each context chunk.f_qs_relevance = Feedback(openai.qs_relevance).on_input().on( TruLlama.select_source_nodes().node.text ).aggregate(np.mean)tru_query_engine_recorder = TruLlama(query_engine, app_id='LlamaIndex_App1', feedbacks=[f_groundedness, f_qa_relevance, f_qs_relevance])# eval using context windowwith tru_query_engine_recorder as recording: query_engine.query("What did the president say about covid-19")# run dashboardtru.run_dashboard()这应该会打开一个web应用程序,您可以访问该应用程序以查看模型性能指标:
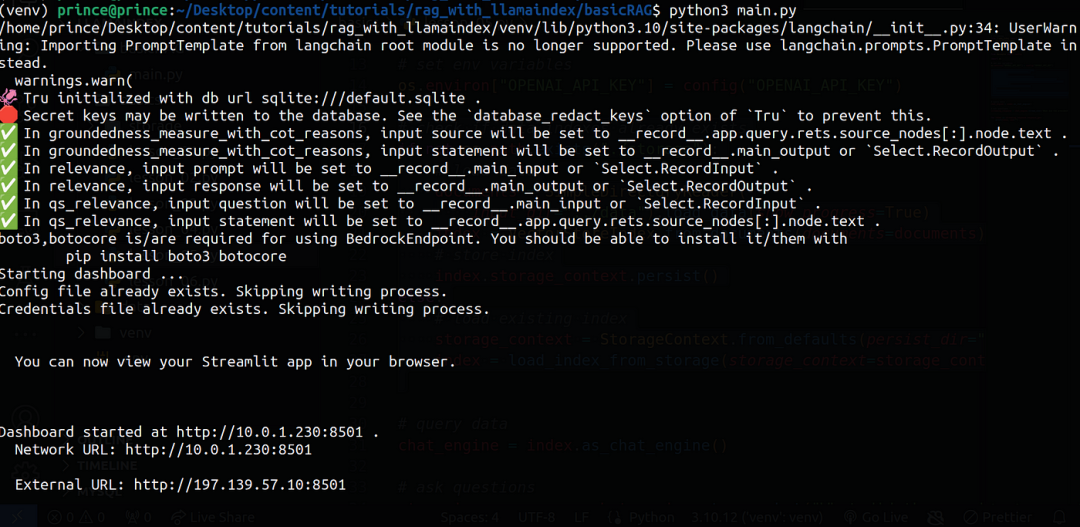
以下是仪表板的一些屏幕截图:
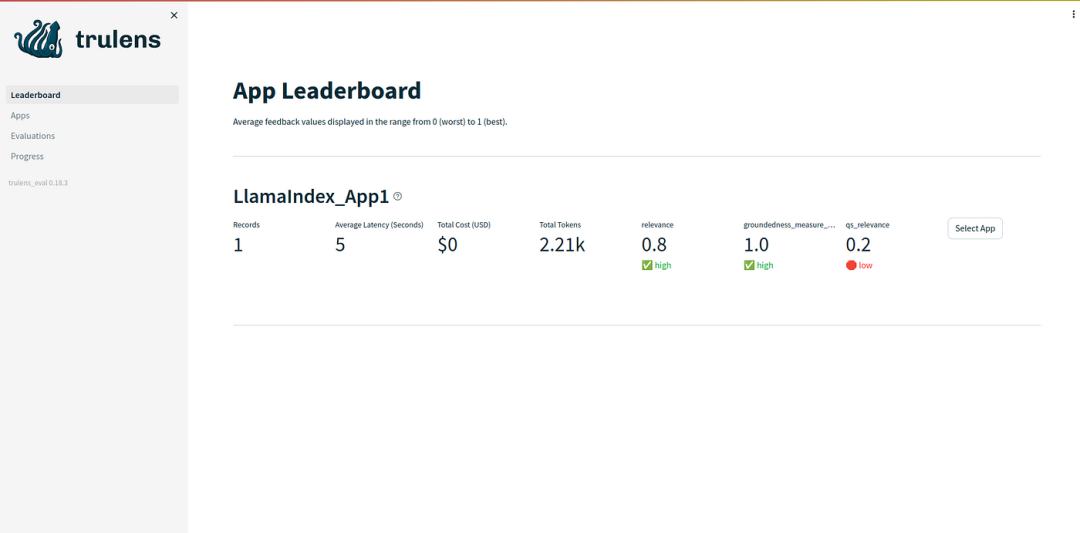
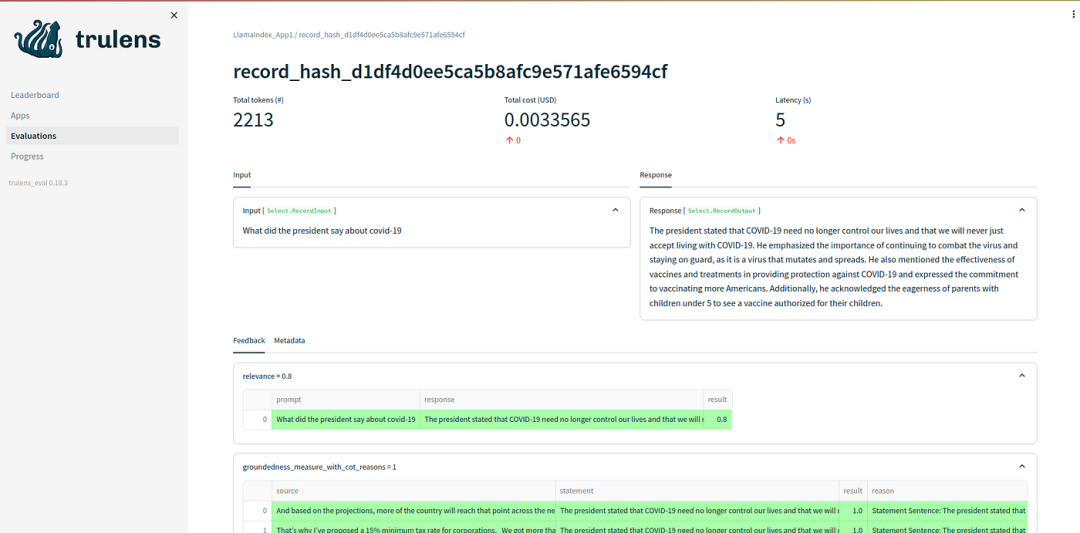
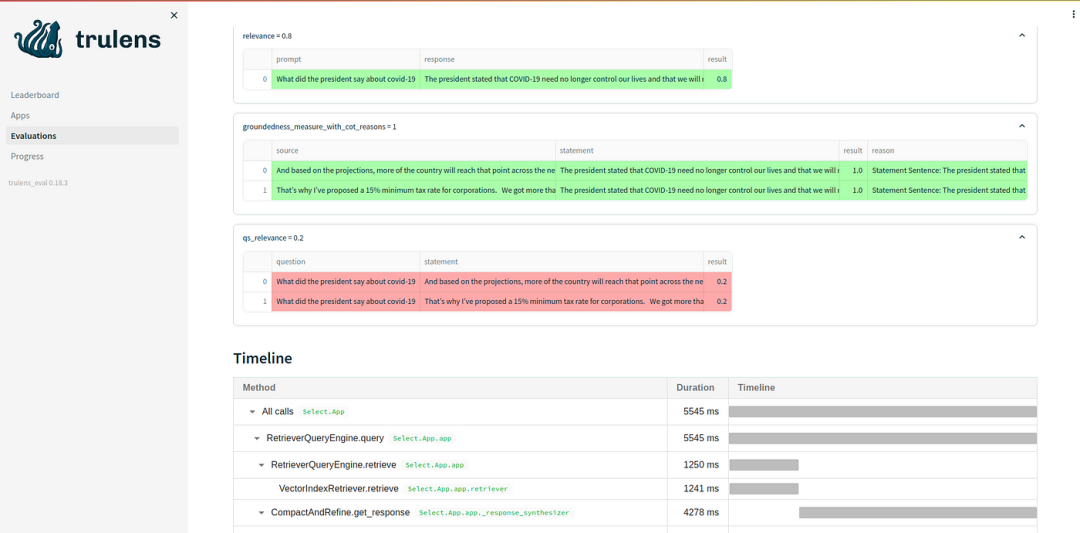
4.2 评估结果的解释
Context Relevance:RAG应用程序在检索最相关的文档方面似乎表现不佳。问题的相关性是0.2。有一些方法可以改进,比如使用不同的嵌入模型、更改块大小等等。
Groundedness and Answer Relevance:Groundedness和Answer相关性相当好和高。如果需要的话,我们也可以通过一些方法来获得更好的结果,比如句子窗口检索器和父文档检索器。
参考文献:
[1] https://medium.com/aimonks/chatting-with-your-data-ultimate-guide-a4e909591436
[2] https://medium.com/aimonks/chatting-with-your-data-ultimate-guide-a4e909591436
[3] https://github.com/Princekrampah/AdvancedRAGTechniques_LlamaIndex
[4] https://platform.openai.com/api-keys
[5] https://docs.python.org/3/library/venv.html
[6] https://truera.com/
[7] https://ai.gopubby.com/advance-retrieval-techniques-in-rag-5fdda9cc304b

