
热门标签
热门文章
- 1Intel RealSense D435i:简介、安装与使用(ROS、Python)
- 2两个升序有序Java_【Java面试题】——— 合并两个有序链表(递归法、迭代法)...
- 3Vue3 学习笔记 —— Teleport、keep-alive_invalid teleport target on mount: null
- 4Spring Bean生命周期、Bean实例化过程_spring bean 的实例化过程和生命周期
- 5【python】python爱心代码【附源码】
- 6顺序表oj--移除元素&&删除重复项&&合并两个有序数组_合并数组并删除相同项
- 7数字图像处理Malab/C++(三)傅里叶变换及频谱图、频域滤波_图像处理fft
- 8STM32涉及到的汇编基础知识_stm32汇编
- 9【工具使用】浏览器控制台,network面板上传/下载请求日志文件,方便调试_网页控制台日志下载
- 10工作中使用到的单词(软件开发)_210.40.50.66/student/#/login
当前位置: article > 正文
【从零开始玩量化5】Python程序获取同花顺问财数据_pywencai
作者:我家自动化 | 2024-02-12 21:05:56
赞
踩
pywencai
2022年9月25日更新
最近好几个兄弟反馈问财做了最大分页数的限制,无法查询所有数据了,我最近抽空处理了一下,现在把结果写在这里。
处理分页用到的代码较多,我就不全部贴了,我把功能封装成了一个python包pywencai,放到Github上了,感兴趣的可以去获取。
Github地址:https://github.com/zsrl/pywencai
PyPI地址:https://pypi.org/project/pywencai/
详细用法可以去上边的地址看,我这里写下示例
安装
由于包中执行了js代码,所以需要先保证你的计算机里有js运行环境,所以先安装一下node.js
之后安装包。
pip install pywencai
- 1
注:支持python3.8+版本,低版本环境请升级python后使用。
用法
import pywencai
res = pywencai.get(question='退市股票', loop=True)
print(res)
- 1
- 2
- 3
- 4
loop参数
loop参数即可以解决分页限制的问题,默认不传时为False,最多只能返回100条数据,传True,程序会循环分页,请求所有数据,返回全部结果。另外,你也可以将loop设置为一个数字,指定循环分页的次数。
若使用此参数,会循环请求多次,会增加程序执行的时间,不过目前也只能做到这样了,我尝试了一下,还算可以接受。
使用时若遇到问题,可以留言或私信。
以下为旧版方法,无法处理分页问题(已作废)
代码
直接上代码
import os import execjs import json import requests as rq import pandas as pd def getToken(): with open(os.path.join(__file__, os.pardir, './hexin-v.js'), 'r') as f: jscontent = f.read() context= execjs.compile(jscontent) return context.call("v") def getWencai(**kwargs): data = { 'perpage': 10000, 'page': 1, 'secondary_intent': 'stock', 'iwcpro': '1', 'source': 'Ths_iwencai_Xuangu', **kwargs } res = rq.request( method='POST', url='http://www.iwencai.com/unifiedwap/unified-wap/v2/result/get-robot-data', data=data, headers={ 'hexin-v': getToken(), 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36' } ) result = json.loads(res.text) list = result['data']['answer'][0]['txt'][0]['content']['components'][0]['data']['datas'] return pd.DataFrame.from_dict(list)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
hexin-v.js这个文件我放到我的网站上了,可以直接打开链接下载https://beima.xyz/hexin-v.js- 这个方法我之前用
node.js写过,现在移植到python程序,区别在于这里必须要改掉requests发送请求时的默认User-Agent,而且不可以设置为None,应该是问财官方做了一些反爬的过滤,解决方法就是直接把你浏览器里的User-Agent复制过来就好了,老法师应该都能懂。
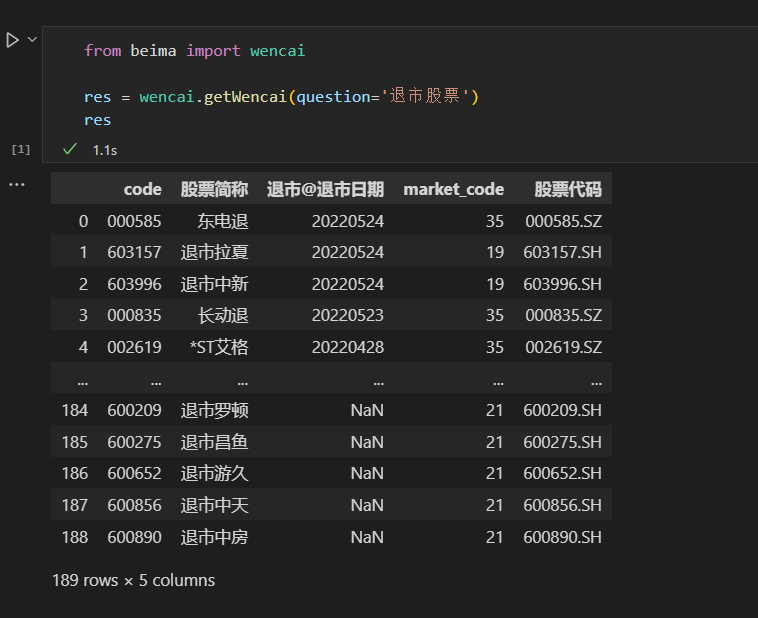
效果展示
简单封装一下,非常实用。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/78660
推荐阅读
相关标签

