
- 1解决问题:vscode远程服务器,总是因网络中断、锁屏等导致程序中断_visualstudiocode 远程登录断开 程序中断
- 2今天看到一个不错的漫画网站(E文)_e-hentai
- 3Visual Studio Code 如何编写运行 C、C++ 程序?_visual studio code怎么运行代码
- 4javaScript产生随机数的几个用法_function generatemixed(n) {
- 5Linux基础—网络设置_linux网络配置
- 6CrossOver虚拟机软件2023最新版Mac运行切换Windows_crossover for mac
- 7SpringMVC的工作原理及底层剖析,你值得一看_springmvc底层原理
- 8蓝桥杯学习记录||BASIC-24 龟兔赛跑预测
- 9【Java】如何搭建java环境一整套详情步骤_java开发环境的搭建步骤
- 10C++ 错误 MSB3073: :VCEnd 已退出 C#
【多模态】14、Segment Anything | Meta 推出超强悍可分割一切的模型 SAM_meta segment-anything 模型有多大
赞
踩

文章目录
官网:https://segment-anything.com/
代码:https://github.com/facebookresearch/segment-anything
出处:Meta、FAIR
时间:2023.04.05
贡献点:
- 首次提出基于提示的分割任务,并开源了可以分割一切的模型 SAM
- 开源了一个包含 1100 万张图像(约包含 10 亿 masks)的数据集 SA-1B,是目前最大的分割数据集,数据集的标注经过三个阶段——手动标注、半自动标注、全自动标注,最终提供的 mask 都是全自动标注的 mask
- SAM 具有很强的零样本迁移能力,在未经训练过的数据集上的边缘检测、proposal 生成、instance segmentation 的效果都很强
- 开源了三种不同大小的模型,模型大小分别为 375M、1.25G、2.56G,能够适合不同场景的使用
一、Intruduction
1、背景:
前有经过预训练的大语言模型被证明有很强的 zero-shot 和 few-shot 泛化能力,这些基础模型能够泛化到其没有见过的任务和数据上去。
究其原因就在于 prompt engineering,提示机制能够根据的提示文本来提示模型来生成更好的反馈。
所以 prompt engineering 和基础模型(在大数据集上预训练)的风很快吹到了 CV 领域
如 CLIP[82] 和 ALIGN[55],使用对比学习来训练 text 和 image 的 encoder,让这两种模态对齐
一旦经过训练,text prompt 就能够零样本泛化到新的视觉概念和数据分布上
这样的 encoder 也可以很高效的和其他模型结合,来实现下游的任务,如图像生成
虽然在视觉和语言编码器方面已经取得了很大的进展,但计算机视觉中有超出这个范围的很多问题,比如不存在非常丰富的训练数据
所以,本文的目标是构建一个图像分割的基础模型,将 prompt 引入,且在非常丰富的数据集上进行预训练,让模型有更好的泛化能力,基于这个基础模型来更好的解决分割的下游问题。
2、什么是 zero-shot learning 零样本学习:
- 从原理上来说,zero-shot learning 就是让计算机具备人类的推理能力,来识别出一个从未见过的新事物。
- 举个例子,我们告诉一个从没见过斑马的小朋友:“斑马是一种长得像马,身上有黑白色条纹的动物”,他就可以很轻松地在动物园里找出来哪个是斑马。
- 可是,在传统的图像识别算法中,要想让机器认出“斑马”,往往需要给机器投喂足够规模的“斑马”样本才有可能。而且,利用“斑马”训练出来的分类器,就无法识别其他物种。
- 但是 zero-shot learning 就可以做到,一次学习都没有,只凭特征描述就识别出新事物,这无疑离人类智力又近了一步。
zero-shot learning 是如何工作的:
-
利用高维语义特征代替样本的低维特征,使得训练出来的模型具有迁移性。
-
比如斑马的高维语义就是“马的外形,熊猫的颜色,老虎的斑纹”,尽管缺乏更多细节,但这些高维语义信息已经足够对“斑马”进行分类,从而让机器成功预测出来。
-
这就解决了图像识别长久以来的问题:如果一个事物从来没有在现有数据集中出现过,机器应该如何学习和识别它。
3、SA 模型简介:
本文提出的 Segment Anything(SA):
- 提出了一个新任务:基于提示的分割任务
- 提出了一个新模型:SAM, 可以分割一切
- 开源了一个新的用于图像分割的数据集(SA-1B,1 Billion masks,11M images),是当前最大的分割数据集,包含 1100 万张图像,约 10 亿标注 masks
SA model 的特性:
- 模型是使用 promptable 的模式训练的,故可以迁移 zero-shot 到新的数据和任务
- 作者在多种不同的任务中进行了性能测试,发现其 zero-shot 性能很厉害,可以匹敌或超过一些监督训练的结果
本文的目标:
- 构建一个适用于图像分割的基础 promptable 模型
- 有足够强的泛化能力
- 能够使用 prompt 功能来实现对下游新数据的分割问题
要实现该目标就有三个重要的元素:
- task:什么任务能够提高 zero-shot 的泛化能力
- model:使用什么样的模型
- data:什么样的数据能够支撑上面的 task 和 model
① Task:promptable segmentation task
在自然语言处理和最近的计算机视觉方法中,基础模型很火,它可以通过使用 “提示” 技术对新的数据集和任务进行 zero-shot 和 few-shot learning。
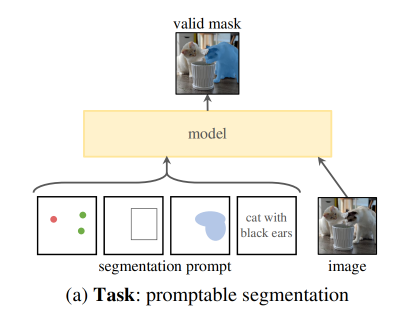
故此,本文提出了【可提示的分割任务】,其目的是在给定任何分割提示下返回一个有效的分割掩码,如图 1a 所示,可以根据使用者的提示(point、box、mask、text)来返回分割结果。
-
prompt 能够指定要在图像中分割的内容,如一些能够标识目标的空间信息或文本信息。
-
一个有效的 mask 输出就意味着,即使当一个 prompt 是模糊的或指向多个目标(比如一件衬衫上的像素点可能表示衬衫或穿它的人),mask 的输出应该是合理且可解释的,至少会包含一个所指向的目标
-
作者使用提示分割任务作为预训练的目标,并通过 prompt 过程来解决一般的下游分割任务
② Model:
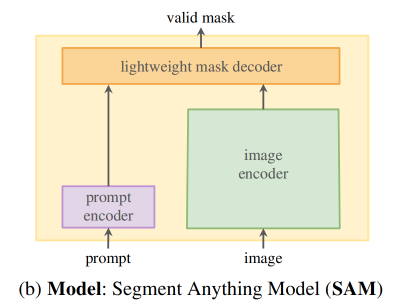
基于提示的分割任务和现实中的可用性就给 model 施加了一些约束
- model 必须支持足够灵活的提示
- model 必须能够支持实时交互使用
- model 必须是模糊感知的,可以对一个模糊 prompt 输出多个 masks,从而允许模型能够自然地处理模糊的目标,如 shirt 和 person
基于上述约束,作者发现了一个简单的结构能够同时满足上述三种约束:
- 一个强大的 image encoder,来计算 image embedding
- 一个 prompt encoder 来编码 prompts
- 一个能够将上面两个 embedding 结合起来的轻量级 mask decoder,预测分割 mask
Segment Anything Model,SAM,见图 1b,由三部分组成:
- image encoder:图像特征提取
- prompt encoder:主要使用点、框、mask 、text 作为提示
- mask decoder:通过对上面两个编码结果进行一定的 cross-attention,得到 mask 结果
3、Data engine
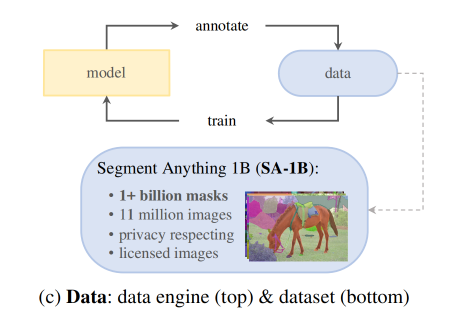
为了实现在新数据集的强大的泛化能力,非常有必要在大量且丰富的 mask 上训练 SAM,而非使用现有的分割数据集来训练。
有一些基础模型方法[82] 使用在线获取数据,但 mask 并不丰富
本文作者建立了一种 ‘data engine’ (数据引擎)的方法, 如图 1c 所示,作者使用 model-in-the-loop 数据集标注和 SAM 模型来共同开发,有三个阶段:
- assisted-manual:SAM 辅助标注工具来标注 masks,类似于传统的分割标注步骤
- semi-automatic:SAM 能够根据提示目标的位置来为一些目标生成 mask,标注工具会对其他剩余的目标进行标注
- fully automatic:用规则的前景网格点来提示 SAM,为每个 image 生成约 100 个高质量的 masks
4、Dataset
最终得到的 dataset 是 SA-1B,包括 1B mask(10亿),11M imgs(1100万),如图 2 所示:
- SA-1B 使用的由 data engine 的最后一个阶段标注结果
- 是现有的分割数据集 mask 数量的 400x 之多,且 mask 的质量都较高且更丰富
5、Responsible AI
作者研究且说明了在使用 SA-1B 和 SAM 时潜在的公平问题和偏差。
SA-1B的图像跨越了地理和经济上不同的国家,我们发现 SAM 表现在不同的人群中也是同样的。
6、Experiments
- 使用 23 个分割数据集,我们发现 SAM 从单个前景点产生高质量的掩模,通常只略低于手动标注的 gt
- 其次,在使用提示引擎的 zeor-shot 时,各种下游任务的定量和定性都获得了较好的结果(包括边缘检测、目标建议生成、实例分割以及 text-to-mask 等)
图 2 展示了数据集中的一些标注样本,标注的 mask 都是最后一个阶段 SAM 自动标注的,每个图像中平均包含约 100 个 masks
可以看出标注非常的细致,有边界区分的图像区域(尽管可能同属于一个 person 或者 car)都被进行了很细粒度的分割,每个土豆都被分割成了一个区域,这和我们通常意义上的实例分割或语义分割的标注 label 有很大的差异。

二、Segment Anything Task
1、Task
首先将 prompt 的概念从 NLP 转换到分割
prompt:
- 可以是一组前景/背景点,如图 3,绿色的点就是 point prompt,模型会给出这个点所在的目标的 mask
- 一个粗糙的框或 mask
- 自由形式的文本
- 或者能够表示在图像中要分割的内容的任何形式
promptable segmentation task 的目标:
- 给定任何 prompt,返回有效的分割 mask(如图 3 所示,任何模糊的提示都要有一个有效的 mask),输出至少要是一个目标

2、Pre-training
可提示的分割任务提出了一种预训练方法,能够为每个训练样本模拟一系列提示(如 points、box、mask),并且和真实的 gt mask 做对比。
3、zero-shot transfer
pre-training 任务赋予了模型在推理时对任何提示做出适当反应的能力,因此下游任务可以通过设计合适的 prompt 方法来解决。
- 假设有一个猫的 box,可以通过提供检测器的 box 输出作为模型的 prompt,来获得猫的实例分割结果
- 一般来说,实际的分割任务都可以被视为 prompting。除了自动数据集标记,第七章中探索了 5 个不同的示例任务。
4、related tasks
分割任务有很多子任务,例如:
- interactive segmentation [57, 109]
- edge detection [3]
- super pixelization [85]
- object proposal generation [2]
- foreground segmentation [94]
- semantic segmentation [90]
- instance segmentation [66]
- panoptic segmentation [59]
提示性的分割模型能支持尽可能多的场景,但不是全部场景
5、discussion
提示和组合能够使单个模型能够以可扩展的方式使用,并有可能完成在模型设计时未知的任务。
这种方法类似如何使用其他基础模型,例如,CLIP [82] 是 图像生成系统 DALL·E[83] 的文本-图像对齐组件。
由 prompt 技术驱动的可组合的系统设计,将会比专门为一组固定的任务训练的应用更加广泛。
三、Segment Anything Model
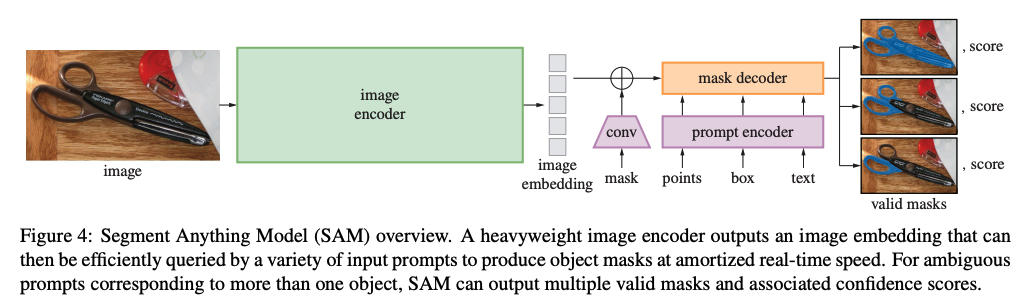
SAM 有三个部分,如图 4 所示:
-
image encoder:
使用 MAE pre-trained Vision Transformer(ViT)来处理高分辨率的输入,image encoder 会对每张图像都运行一次,且可以在使用提示之前应用。
image encoder 的输出是经过 16x 下采样的结果,输入大小为 1024x1024,所以经过 image embedding 后的结果是 64x64 大小,为了降低通道数量,使用了 1x1 卷积将通道降为 256。
-
flexible prompt encoder:有两种 prompts
- sparse(points、boxes、text):通过位置编码来表示 points 和 box,通过 CLIP 的 off-the-shelf text encoder 来表示 text。sparse prompts 都是 256-d 的向量。point 表示位置编码和该点是前景还是背景;box 表示左上角学习到的编码和右下角学习到的编码。text 是从 CLIP 中得到的编码。
- dense(masks):使用卷积来进行编码,并对编码结果进行 element-wise 求和。mask 是将图像下采样 4x 后输入的,然后是 1x1 卷积将通道变为 256,然后将 image embedding 和 mask 进行逐点相加,如果没有 mask prompt,则不加即可
-
fast/lightweight mask decoder
- decoder 能够高效地对 image embedding 和 prompt embedding 进行映射,得到输出的 mask,如图 14 所示。
- 共有两层 decoder layer,通过 cross-attention 来更新 image embedding 和 prompt token

每个 decoder layer 有 4 个步骤:
- 首先,对 prompt token 上进行 self-attention
- 然后,对 token(as queries)到 image embedding 进行 cross-attention
- 接着,使用逐点的 MLP 来更新每个 token
- 最后,对 image embedding(as queries)到 token 进行 cross-attention,使用 prompt 信息更新 image embedding
这里的 token 是什么:
- 我们知道在图像分类 ViT 中,在 49 个 patch embedding 后面又添加了一个 cls token,变成了 50 维的特征输入到了 Transformer 中进行特征提取,最后使用 cls token 经过 MLP 后得到类别,这里的 cls token 就是最终用于分类的特征
- 所以在本文中,在 prompt embedding 中也添加了一个 token,在 decoder 的输出中会用到
如何进行 cross-attention:
- 将 image embedding 看做一系列 64x64x256 的向量
- 每个 self、cross-attention、MLP 在训练中都有残差链接、layer norm、dropout
- 作者使用两层 decoder,下一个 decoder layer 的输入是上一层更新后的 token 和更新后的 image embedding
decoder 运行完之后,使用两个反卷积将特征扩大 4x,相比于原图是 4x 下采样大小
token 再次被用到 image embedding 上,并且将更新后的输出 token embedding 经过一个小的 3 层 MLP,输出的通道和上面经过反卷积的 image embedding 保持一致。最后使用 MLP 的输出和反卷积后的 image embedding 进行逐点相乘来预测 mask
如何解决 prompt 的模糊性:
- 如果给出一个模糊的提示,则模型一般会平均多个有效的 mask 来得到一个输出
- 为了解决这个问题,作者修改了模型,如果只给了一个 prompt,也会输出多个匹配到的 masks(如图 3)
- 作者发现 3 个 mask 输出通常能够解决大多数常见的情况(嵌套 mask 通常最多有三个深度:整体、部分、子部分)
如何训练:
- 在训练过程中,仅仅回传 mask 中最小的 loss
- 模型会给每个 mask 预测一个 confidence score (estimated IoU)来进行排序
高效性:
- prompt encoder 和 mask decoder 都运行在 web browser 上,在 CPU 上大概为 50ms
Loss:
- 使用 focal loss 和 dice loss 的线性组合来监督 mask prediction,且 focal loss 和 dice loss 的权重比为 20:1
- 此外,作者证明在每个 decoder layer 后面使用辅助 loss 也有效果,所有使用 MSE loss 来监督 IoU head
Training:
- 使用混合 geometric promps 来训练 promptable segmentation task
- 对每个 mask 都会进行 11 轮随机采样 prompt 来模拟交互,允许 SAM 和 data engine 无缝衔接
四、Segment Anything Data Engine
由于现有大分割数据集并不丰富,所以作者搭建了一个数据引擎来持续收集数据
数据引擎分为三个阶段:
- 模型辅助手动标注阶段
- 包含自动预测 mask 和模型辅助标注的半自动阶段
- 全自动阶段,模型生成 mask 且没有标注器
1、手动标注阶段
类似于传统的交互式分割,标注人员使用标注工具进行 mask 的标注
没有对标记对象施加语义约束,标注人员可以自由的标注 ‘stuff’ 和 ‘things’
作者会建议标注人员标注其自己认为可以命名或描述的对象,但并不需要类别来对这些被 mask 的对象进行描述
标注人员会按图像中物体的突出程度来按顺序标注物体
在这个阶段,SAM 使用常见的公共分割数据集进行训练,在进行足够的数据标注后,只使用新的标注 mask 来重新训练。
随着标注 mask 的增多,image encoder 从 ViT-B 扩展到 ViT-H,其他结构不变
共进行了 6 次训练
随着模型效果的提升,每个 mask 的平均标注时间从 34s 降到了 14s
14s 比 COCO 的 mask annotation 快 6.5x,比 box annotation 慢 2x
随着 SAM 的提升,每个图像中的 mask 的平均数量从 20 提升到了 44
在这个阶段从 120k 数据中得到了 4.3M masks
2、半自动标注阶段
在这个阶段,目标是增加 mask 的多样性,以提高模型分割任何东西的能力
为了将标注器集中到不太突出的目标上,首先,自动检测到很有信心的 mask,然后对这些 mask 的地方进行填充,然后让标注器去关注其他未标注的地方。
如何得到有信心的 mask:
- 为了检测有信息的 masks,训练了一个 bbox 检测器[84] ,使用的是通用的 ‘object’ category。
在这个阶段,在 180k 数据中得到了 5.9M masks(和前面的一共 10.2M mask)
通过进行 5 次训练,每个 mask 的标注时间又变成了 34s,因为这些 mask 的标注比较难,每个图像中的 mask 从 44 扩充到了 72 个
3、全自动标注阶段
在最后一个阶段,是进行全自动的标注,这也是可行的
- 其一,因为在这个阶段的开始,已经收集到了足够的 mask,包括前两个阶段收集到的多种多样的 mask
- 其二,在这个阶段,开发了感知模糊模型,运行对模糊的 prompt 进行输出
具体方法:
- 使用 32x32 的网格 point prompt 模型,为每个 point 预测一系列可能对应于有效目标的 mask
- 对于感知模糊模型,如果一个 point 位于一个 part 或 subpart 上,则模型会返回该 part、shupart、whole 的目标
- 使用 IoU 预测模块来选择 confident mask
- 此外,作者只选择 stable masks
- 选择到 confident 和 stable 的 mask 后,使用 NMS 进行过滤
- 为了进一步提升小 mask 的质量,还使用了多种重叠的 zoom-in 的方式
经过最后一阶段的全自动标注,共在 11M 图像上得到了 1.1B 的高质量 mask
五、Segment Anything Dataset
1、Images
这些 11M 图像都是经过授权的,都是高分辨率图像(平均 3300x4950 pixels),该量级的数据大小对访问和存储都是挑战。
因此,作者发布了最短边长为 1500 px 的降采样图像,这样也高于一些常用的图像(如 COCO 大约为 480x640 px 左右)
2、Masks
共包含 1.1B 个 mask,其中 99.1% 都是自动生成的,因此 mask 的质量至关重要
作者会将生成的 mask 和专业标注的结果进行比较,并且在第 7 章证明了本文的数据集标注 mask 是高质量的
3、Mask quality
为了估计 mask 的质量,作者随机抽取了 500 张图像,约 50k masks,并要求标注人员提高这些 mask 的质量。
这样一来就能产生成对的预测 mask 和矫正后的 mask
通过计算 IoU 发现:
- 有 94% 的 mask pair 的 IoU > 90%
- 有 97% 的 mask pair 的 IoU > 75%
4、Mask properties
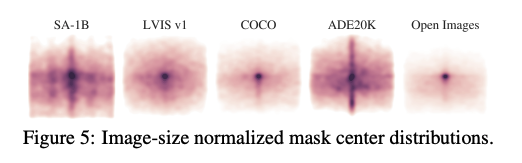
如图 5,绘制了 SA-1B 的所有 mask center(mask 中心店)和现有流行分割数据集的 mask center 的空间分布对比
在所有的数据集中,都存在摄影师偏差
-
SA-1B 相比于 LVIS v1 和 ADE20K,具有更大的 mask 覆盖范围,即 mask center 的分布很广泛,没有明显的集中到图像中心的位置,mask 的位置的分布较为均衡
-
COCO 和 Open Images V5 有更突出的中心偏差。可以明显的看出 COCO 中心点颜色很深,说明 coco 的很大部分的 mask 的中心点集中在图像的中心点
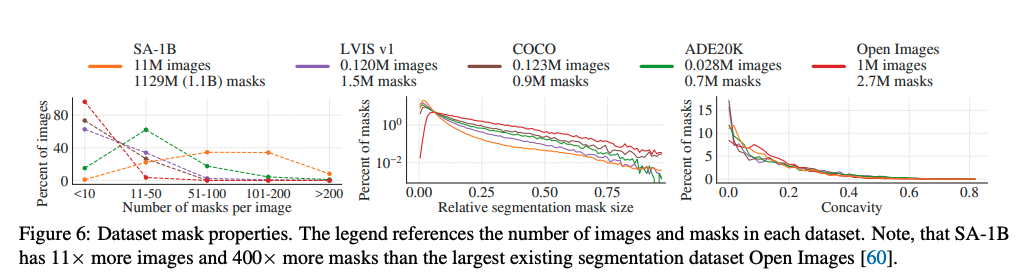
在图 6 中,按大小对比了这些数据集
SA-1B 比第二大开放图像数据集多 11x 图像 和 400x mask,平均每幅图像比开放图像多 36x mask
如图 6 中间,SA-1B 的每个图中有更多的 mask,故包含了更多中小目标
六、Segment Anything RAI Analysis


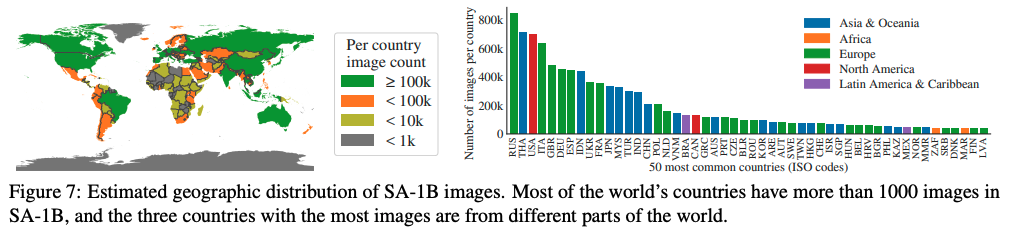
这里将台湾和香港被列为 Country,有严重的问题,已经有网友给作者发邮件敦促修改,这里静等结果!
七、Zero-shot Transfer Experiments
本节主要介绍使用 SAM 进行 zero-shot transfer 实验,包括了 5 个任务:
- 实验测试的是 SAM 在没见过的数据集和任务上的效果(和 CLIP 的使用类似)
- 数据集中包括新的数据分布,如水下或俯视图(如图8)
实验的核心目标:
- 测试是否能够从任何提示中生成一个有效的 mask
使用一系列从低到中再到高水平的图像理解来证明效果:
- 边缘检测
- 分割所有内容,即生成 object proposal
- 对检测到的目标进行分割,即实例分割
- 作为一个概念,从 free-form text 的提示中来分割对象。
实验设置:
- SAM 使用基于 MAE 预训练的 ViT-H[33] 作为 image encoder
- SAM 在 SA-1B 上训练,该数据集的标注 mask 只有自动标注的结果
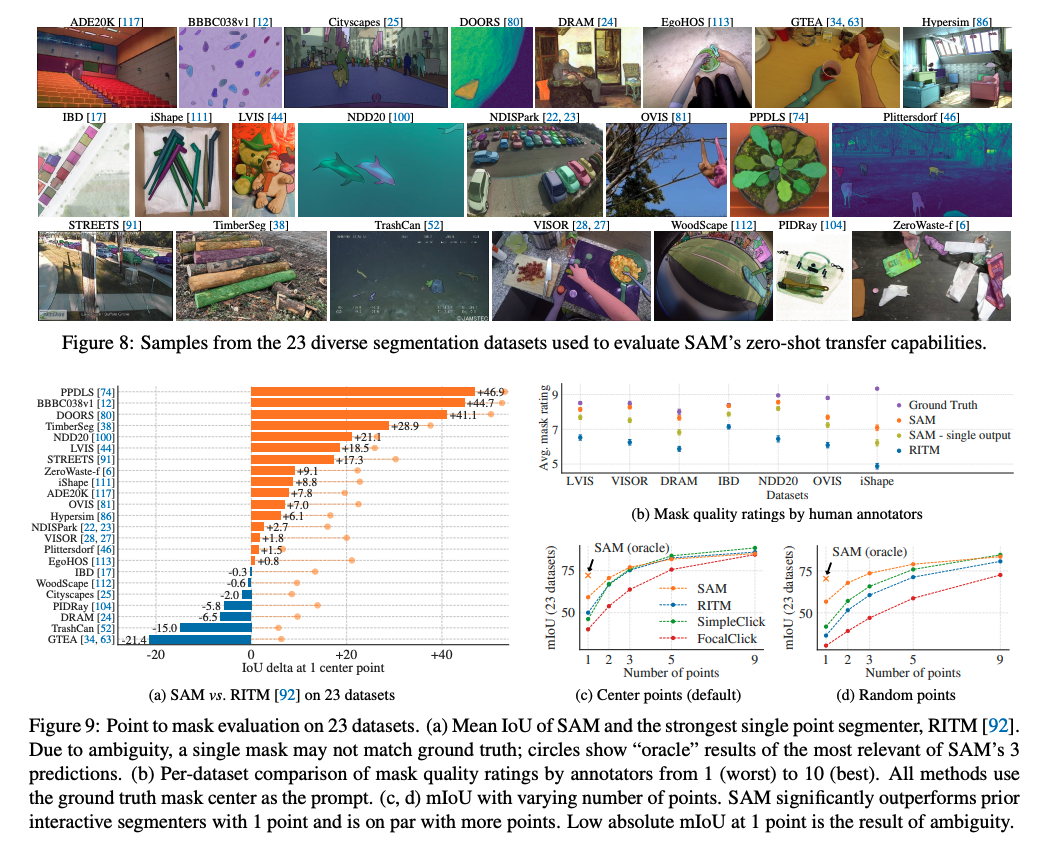
图 8 展示了作者使用的 23 个测试开源数据集
7.1 zero-shot single point valid mask evaluation
1、Task
作者测试了从单个前景 point 出发来进行一个目标的分割
2、Datasets
作者使用由不同的 23 个数据集组成的数据,如图 8 展示了 dataset 并且展示了每个数据集的样本(表 7 更详细)
使用 mIoU 作为评估标准:
- 对于 human study:使用如图 9b 的 subset
3、Results
如图 9a,SAM 和 RITM 对比了每个数据集的结果
- SAM 取得了 16 个数据集的更好的结果
- 此外,还展示了 oracle 结果,抽出 SAM 的 3 个 mask 和 gt 对比,而非使用所有的 confident mask,SAM 在所有数据集上都超越了 RITM
human study 的结果见图 9b
7.2 zero-shot edge detection
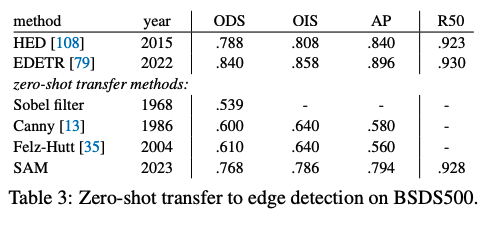
作者在 BSDS500 数据集上测试了 SAM 边缘检测的效果
使用 16x16 的规则前景点 grid 作为 prompt,得到 768 个预测 mask(每个点预测 3 个),多余的 mask 使用 NMS 剔除掉
然后使用 sobel 滤波和后处理,得到最终的边缘 maps
结果:
如图 10 (图 15 更多)所示:
- 定性来看,尽管 SAM 没有训练过边缘检测的任务,但也能得到理想的边缘检测结果
- 和 gt 相比,SAM 预测了更多的边缘,包括 BSDS500 中没有标注的一些边缘


7.3 zero-shot object detection
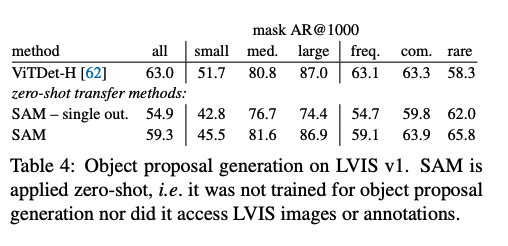
作者在 object proposal generation 任务上也测试了 SAM 的性能
这项任务在目标检测任务上很重要
作者将 mask 自动生成的 pipeline 进行了一些修改,用于生成 proposal,输出的 mask 作为 proposals
average recall (AR) 作为评判标准
表 4 展示了结果
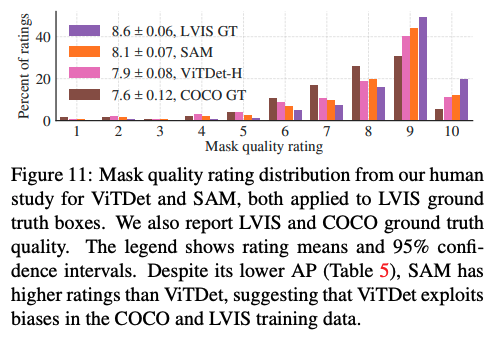
7.4 zero-shot instance segmentation
作者也使用了 instance segmentation 来评判了 SAM 的效果
- 首先运行一个目标检测网络
- 将检测结果作为 SAM 的 prompt
结果:



7.5 zero-shot text-to-mask
作者在根据 free-form text 来进行目标分割的任务上也进行了实验
- 对每个面积大于 10 0 2 100^2 1002 像素的 mask,都抽取 CLIP image embedding
- 在训练阶段,使用 CLIP image embedding 作为 SAM 的 prompt,在推理阶段,使用 text embedding 就可以了。因为 CLIP 的 image embedding 是和 text embedding 对齐的
- 所以,在推理阶段,通过 CLIP 的文本编码器对文本编码,然后将生成的文本编码作为提示符提供给 SAM
结果:
如图 12 所示,SAM 可以在给定文本提示符的情况下来分割对应的目标

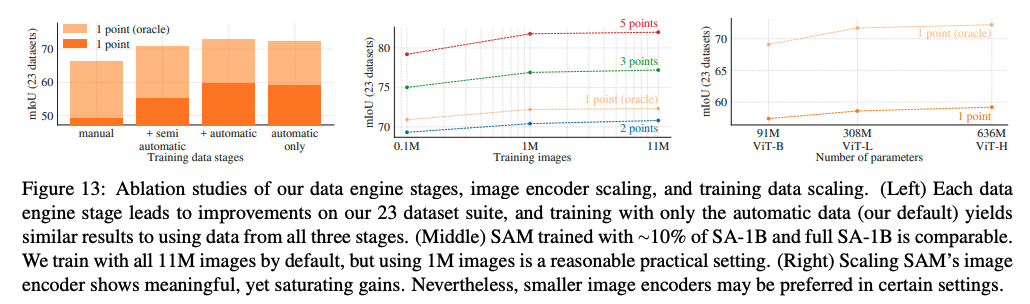
八、总结
SAM 能够实现非常细粒度的图像分割,分割粒度之细让人望而生畏,突破了以前实例分割和语义分割的标注上限。能达到这样的细粒度标注的一个关键原因就在于没有给标注过程设置 “类别” 的界限,只要标注人员(第一阶段)认为这个区域是能够抽象描述的,就可以将这个区域 mask 出来,而无需给定一个类别描述或语言描述。
如上所述,SAM 分割的结果是不含类别信息的(因为训练数据的 label 也是没有类别信息的,只有像素是否是否属于一个 mask 的信息),使用 text 作为 prompt 的时候可以输入类别信息,如 ‘cat’,就可以输出一张图中的所有 cat,这个 cat 是基于图文编码匹配的,而分割的结果中原本是没有任何类别信息的。
SAM 作为首个图像分割的大基础模型,为未来 CV 方向提供了更多的可能,为自动标注也提供了很好的范本。
九、在线体验
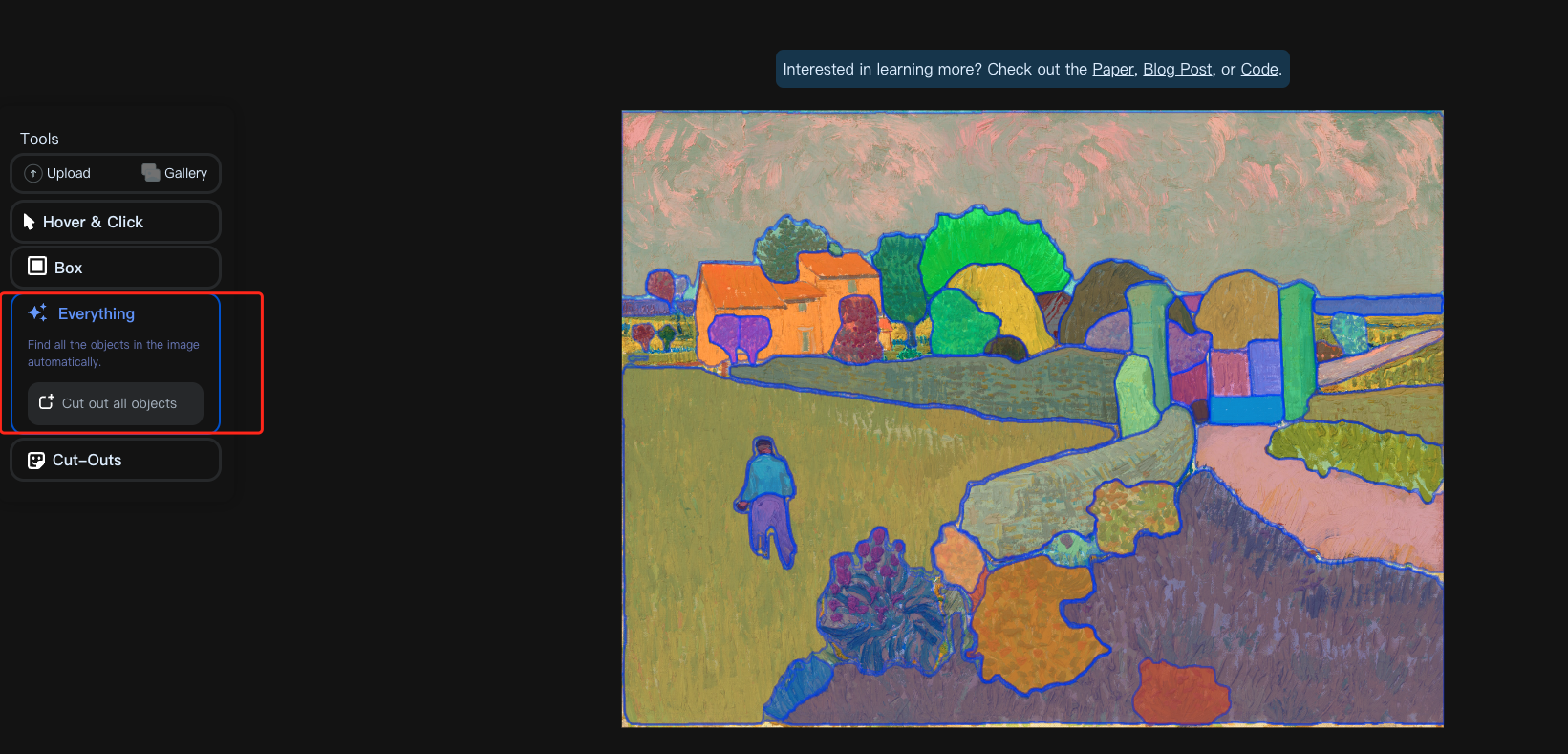
点击右上角的 demo 即可体验,可以使用网站上的图,也可以点击 Upload an image 上传自己的图

点击左侧 Everything 即可对图中所有目标进行分割:
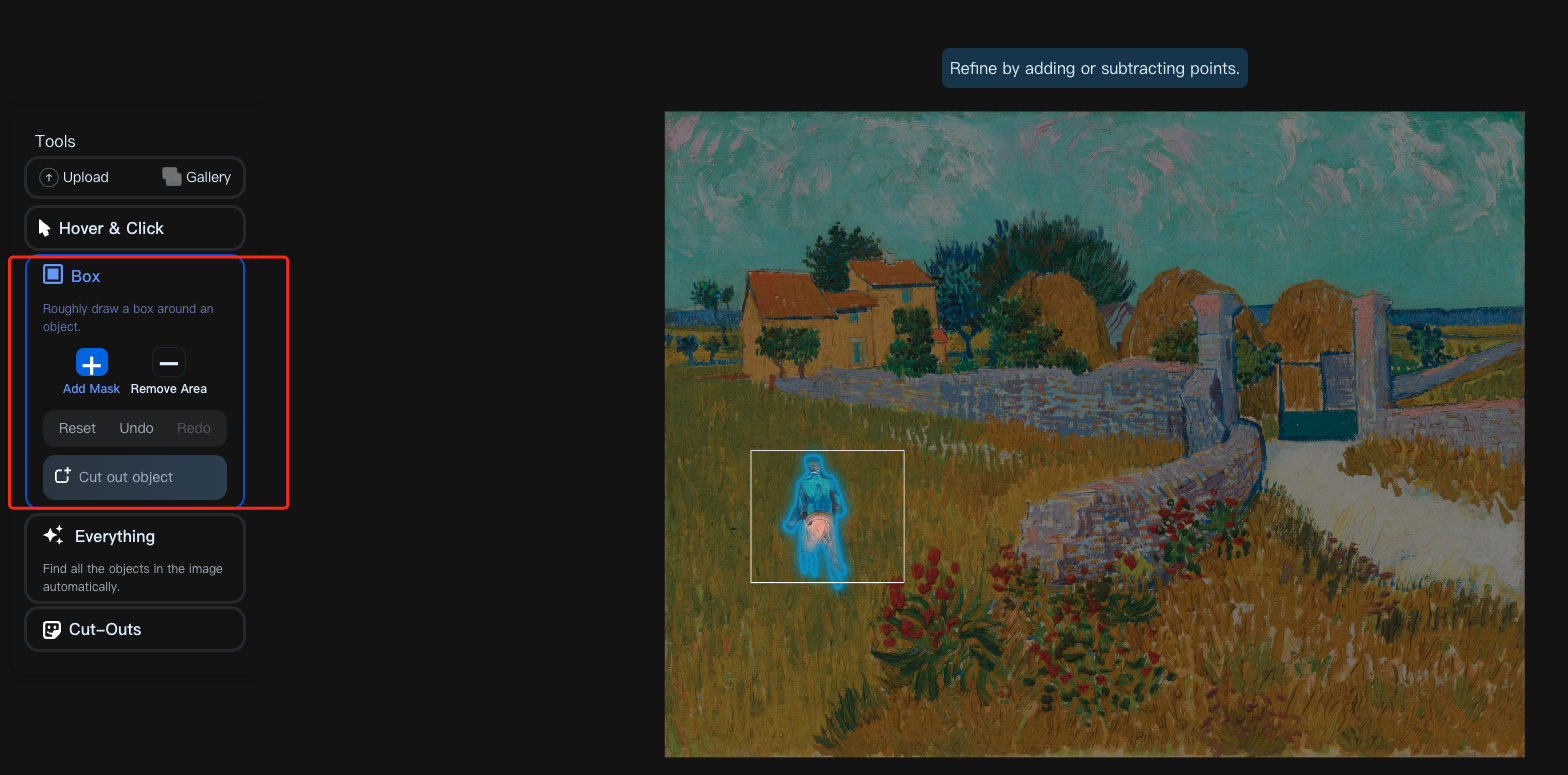
点击 Box 就可以使用 box prompt 来提示模型输出 box 内的分割 mask:
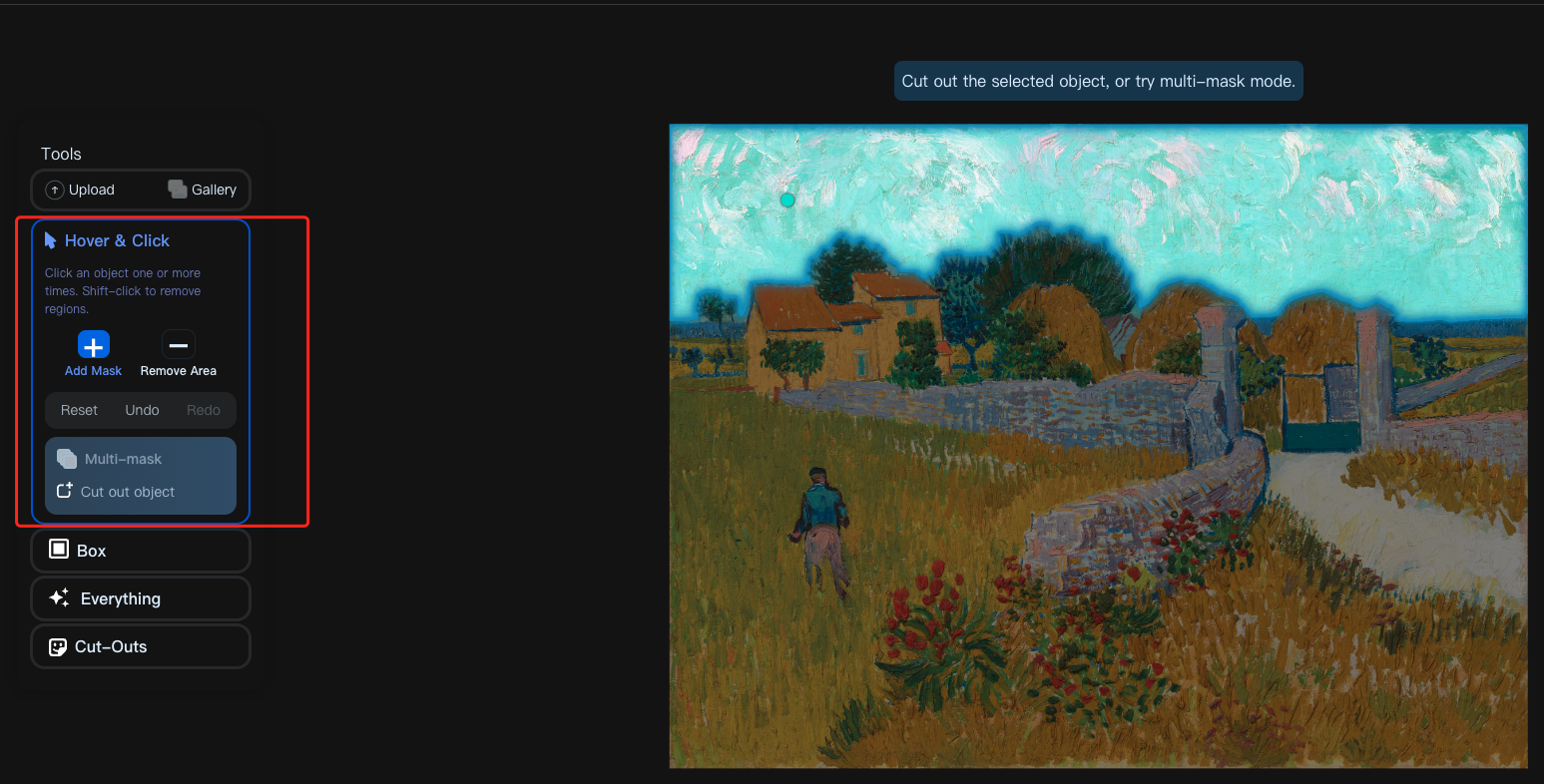
点击 Hover&Click 就可以在页面上点击,会输出该点所在的 mask 的结果:
十、代码
只能做推理
1、环境安装
conda create -n seg_any python=3.8 pytorch=1.10 torchvision cudatoolkit=11.7 -c pytorch -c conda-forge
git clone https://github.com/facebookresearch/segment-anything.git
cd segment-anything
pip install -e .
pip install opencv-python pycocotools matplotlib onnxruntime onnx -i http://pypi.douban.com/simple/
- 1
- 2
- 3
- 4
- 5
2、模型下载
在 github 项目中有模型下载地址:

3、简单使用
# 根据 prompt 生成 mask
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
- 1
- 2
- 3
- 4
- 5
- 6
# 获取图中所有的 mask
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>") # model type: ['default', 'vit_l', 'vit_b']
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
- 1
- 2
- 3
- 4
- 5
# 也可以使用单行命令实现
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
- 1
- 2
4、image encoder
- 输入:1024x1024x3
- 第一步:patch embedding:patch 大小为 16x16(使用 16x16,步长为 16 的二维卷积实现),得到 16x16x768 维的特征,输出为 [N, 16, 16, 768]
- 第二步:给图像编码加上位置编码
- 第三步:输入 Transformer Encoder 中,进行多级 MHSA 和 MLP,ViT 深度为 12,多头自注意力的 head 数为 12
- 第四步:经过 Neck(1x1 conv + LN + 3x3 conv + LN)
- 输出:64x64x256 大小
5、prompt encoder
- 对 points 编码
- 对 box 编码
- 对 mask 编码
6、mask decoder
- 对 image encoder 和 prompt encoder 的结果做 cross-attention

