
- 1qemu-system-x86_64(1)-Linux手册页_qemu-system-x86_64手册
- 22001-2021,一文读懂NLP发展简史_回顾 nlp 的主要发展历程
- 3QT5.14 QTextEdit的内容保存到文件的方法_qt中保存文本框内容
- 4【Leetcode刷题篇】- Leetcode092反转链表II_ds单链表反转链表,给定一个链表,以及输入两个整数left和right
- 5Android基础知识(二十):Notification、提醒式通知(横幅)踩坑与通知界面设置跳转_setfullscreenintent会使通知停留?
- 6C/C++生态工具链——gcc/g++编译器使用指南
- 7Mac版2024 CleanMyMac X 4.14.6 核心功能详解以及永久下载和激活入口
- 8批量归一化(Batch normalization)
- 9鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Stack容器组件
- 10黑苹果 映泰h170gtn+i3 7100+RX460
Python编程实验五:文件的读写操作
赞
踩
目录
一、实验目的与要求
(1)通过本次实验,学生应掌握与文件打开、关闭相关的函数,以及与读写操作相关的常用方法的使用;
(2)理解基于文件的词频统计以及数据分析的基本思路,能根据问题需要灵活选择合适的数据结构;
(3)综合应用所学知识实现对问题的编程求解;
(4)按照实验题目要求独立正确地完成实验内容(编写、调试算法程序,提交程序清单及及相关实验数据与运行结果)
二、实验内容
请使用Python语言在Jupyter Notebook环境下编程,完成下列题目的要求:
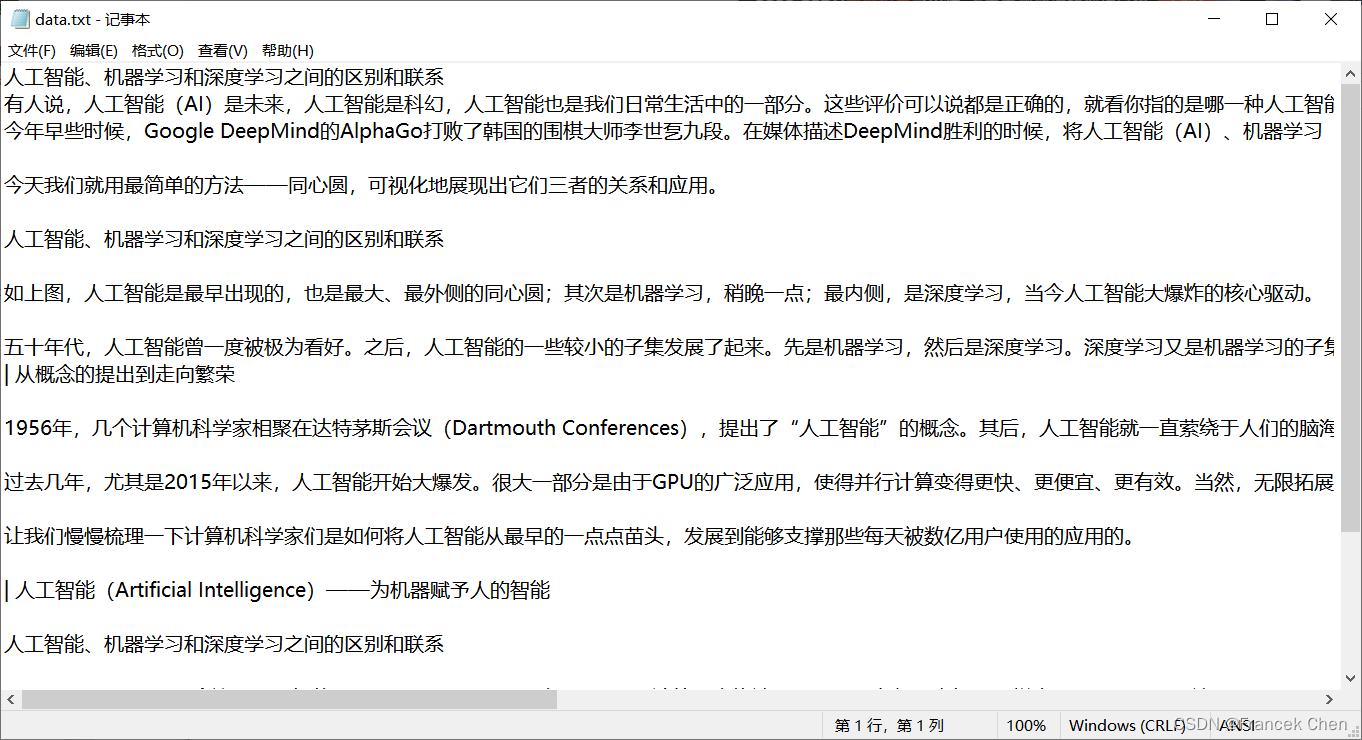
1、实验5素材文件夹下的文件 data.txt 是一个来源于网上的技术信息资料。
问题1:用 Python 语言中文分词第三方库 jieba 对文件 data.txt 进行分词,并选择长度大于等于3个字符的关键词,写入文件 out1.txt , 每行一个关键词,各行的关键词不重复,输出顺序不做要求,例如:
人工智能
科幻小说
……
问题2:对实验5素材文件夹下的文件 data.txt 进行分词,对长度不少于3个字符的关键词,统计出现的次数,按照出现次数由大到小的顺序输出到文件 out2.txt ,每行一个关键词及其出现次数,例如:
科学家:2
达特茅斯:1
……
2、某班学生评选一等奖学金,学生的10门主干课成绩存在于实验5素材文件夹下文件 score.txt 中, 每行为一个学生的信息,分别记录了学生学号、姓名以及10门课成绩,格式如下:
1820161043 郑珉镐 68 66 83 77 56 73 61 69 66 78
1820161044 沈红伟 91 70 81 91 96 80 78 91 89 94
……
从这些学生中选出奖学金候选人,条件是:①总成绩排名在前10名;②全部课程及格(成绩大于等于60)。
问题1:给出按总成绩从高到低排序的前10名学生名单,并写入文件 candid1.txt ,每行记录一个学生的信息,分别为学生学号、姓名以及10门课成绩。
问题2:读取文件 candid1.txt ,从中选出候选人,并将学号和姓名写入文件 candid2.txt 格式如下:
1010112161722张三
1010112161728李四
......

实验素材下载地址:https://download.csdn.net/download/Morse_Chen/88887343?spm=1001.2014.3001.5503
三、主要程序清单和程序运行结果
第1题
1、实验5素材文件夹下的文件 data.txt 是一个来源于网上的技术信息资料。
问题1:用 Python 语言中文分词第三方库 jieba 对文件 data.txt 进行分词,并选择长度大于等于3个字符的关键词,写入文件 out1.txt , 每行一个关键词,各行的关键词不重复,输出顺序不做要求,例如:
人工智能
科幻小说
……问题2:对实验5素材文件夹下的文件 data.txt 进行分词,对长度不少于3个字符的关键词,统计出现的次数,按照出现次数由大到小的顺序输出到文件 out2.txt ,每行一个关键词及其出现次数,例如:
科学家:2
达特茅斯:1
……
- import jieba
-
- with open("data.txt", "r") as f:
- content = f.read()
- words = set()
- seg_list = jieba.cut(content)
- for word in seg_list:
- if len(word) >= 3:
- words.add(word)
- with open("out1.txt", "w") as f:
- for word in words:
- f.write(word + "\n")
-
- from collections import Counter
-
- with open("data.txt", "r") as f:
- content = f.read()
- words = []
- seg_list = jieba.cut(content)
- for word in seg_list:
- if len(word) >= 3:
- words.append(word)
- word_count = Counter(words)
- sorted_word_count = sorted(word_count.items(), key=lambda x: x[1], reverse=True)
- with open("out2.txt", "w") as f:
- for word, count in sorted_word_count:
- f.write(f"{word}:{count}\n")

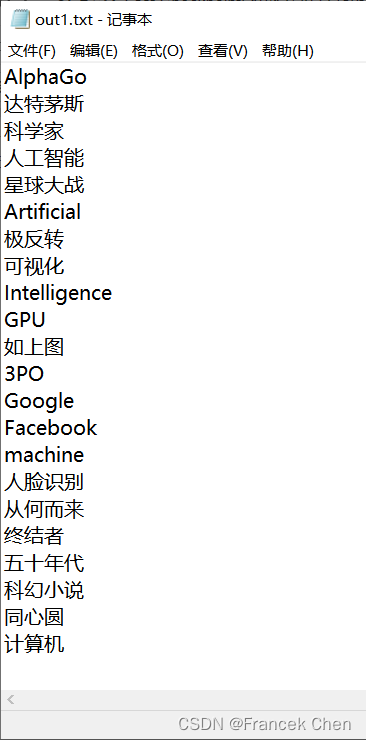
使用了jieba库来进行文本处理,并将处理结果写入文件。
首先,打开一个名为 "data.txt" 的文件,并读取文件内容。然后使用 jieba.cut() 方法对文本进行分词,得到分词结果。接着,它遍历分词结果,并将长度大于等于3的词添加到一个名为 "words" 的集合中,并将这些词写入名为 "out1.txt" 的文件中。
接下来,它再次打开 "data.txt" 文件并读取内容,然后使用 jieba.cut() 方法对文本进行分词,得到分词结果。同样地,它筛选出长度大于等于3的词并将它们添加到名为 "words" 的列表中。然后使用 collections.Counter() 方法统计每个词出现的次数,将统计结果按词频排序,并将排序后的结果写入名为 "out2.txt" 的文件中。
运行结果:
 ……
…… 
 ……
…… 
第2题
2、某班学生评选一等奖学金,学生的10门主干课成绩存在于实验5素材文件夹下文件 score.txt 中, 每行为一个学生的信息,分别记录了学生学号、姓名以及10门课成绩,格式如下:
1820161043 郑珉镐 68 66 83 77 56 73 61 69 66 78
1820161044 沈红伟 91 70 81 91 96 80 78 91 89 94
……从这些学生中选出奖学金候选人,条件是:①总成绩排名在前10名;②全部课程及格(成绩大于等于60)。
问题1:给出按总成绩从高到低排序的前10名学生名单,并写入文件 candid1.txt ,每行记录一个学生的信息,分别为学生学号、姓名以及10门课成绩。
问题2:读取文件 candid1.txt ,从中选出候选人,并将学号和姓名写入文件 candid2.txt 格式如下:
1010112161722张三
1010112161728李四
......
- with open("score.txt", "r") as f:
- content = f.readlines()
- students = []
- for line in content:
- info = line.split()
- student_id = info[0]
- student_name = info[1]
- scores = list(map(int, info[2:]))
- total_score = sum(scores)
- students.append((student_id, student_name, scores, total_score))
-
- sorted_students = sorted(students, key=lambda x: x[3], reverse=True)
-
- with open("candid1.txt", "w") as f:
- for student in sorted_students[:10]:
- student_id, student_name, scores, _ = student
- f.write(f"{student_id} {student_name} {' '.join(map(str, scores))}\n")
-
- with open("candid1.txt", "r") as f:
- content = f.readlines()
- selected_students = []
- for line in content:
- info = line.split()
- student_id = info[0]
- student_name = info[1]
- scores = list(map(int, info[2:]))
- if all(score >= 60 for score in scores):
- selected_students.append((student_id, student_name))
-
- with open("candid2.txt", "w") as f:
- for student in selected_students:
- student_id, student_name = student
- f.write(f"{student_id} {student_name}\n")
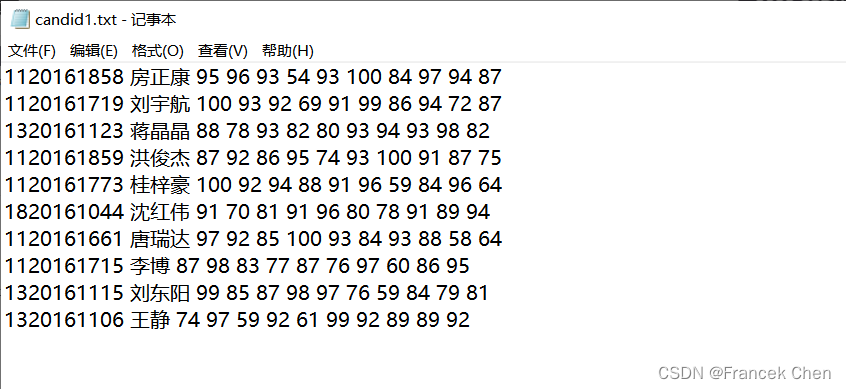
这段代码首先打开名为 "score.txt" 的文件,读取文件内容并按行存储在列表 content 中。然后,它遍历 content 列表中的每一行,将每行按空格分割成一组信息,包括学生ID、学生姓名和各科成绩。成绩部分被转换为整数类型并计算总成绩,然后将学生的信息以元组形式存储在 students 列表中。
接着,代码对 students 列表中的学生信息根据总成绩进行降序排序,得到了 sorted_students 列表。
然后,代码打开名为 "candid1.txt" 的文件,将排名前10的学生信息写入文件中,每行包括学生ID、学生姓名和各科成绩。
接着,代码再次打开 "candid1.txt" 文件,读取文件内容并按行存储在列表 content 中。然后,它遍历 content 列表中的每一行,将每行按空格分割成一组信息,包括学生ID、学生姓名和各科成绩。然后判断该学生各科成绩是否都大于等于60分,如果是,则将该学生的学生ID和学生姓名以元组形式存储在 selected_students 列表中。
最后,代码将符合条件的学生信息写入名为 "candid2.txt" 的文件中,每行包括学生ID和学生姓名。
运行结果:

四、实验结果分析与体会
通过本次实验,掌握了与文件打开、关闭相关的函数,以及与读写操作相关的常用方法的使用;理解基于文件的词频统计以及数据分析的基本思路。在进行文件读写操作时,及时打开和关闭文件是非常重要的,特别是在写操作完成后,一定要确保文件被正确关闭,以避免数据丢失或损坏。在文件操作过程中,可能会遇到各种异常情况,比如文件不存在、权限问题等。因此,对于文件操作,充分的异常处理是必不可少的,这可以通过 try-except 语句来实现。
Python 提供了多种文件读写模式,包括 "r"(只读)、"w"(只写)、"a"(追加)、"r+"(读写)等。在选择文件模式时,需要根据具体的需求来决定使用哪种模式,以确保操作的正确性和安全性。在文件读写操作中,尤其是处理文本文件时,需要注意文件的编码格式。在打开文件时可以指定编码方式,以便正确地读取和写入文件内容。文件读写过程中,文件指针的位置是非常重要的。在读取文件内容或者进行写入操作时,需要注意文件指针的位置,以确保读写操作的准确性。


