
- 1win10下安装QT5步骤_qt5下载
- 2交叉编译并移植qt_qmake.conf
- 3【TCN时序预测】基于双向时间卷积神经网络结合多头注意力机制BiTCN-Multihead-atention实现数据回归预测附matlab代码_双向tcn
- 4鸿蒙第一讲笔记_鸿蒙开发写超链接
- 5加快app的启动速度_加快应用启动速度的模块 site:blog.csdn.net
- 6pyannote 语音活动检测/说话者变化检测/语音重叠检测
- 7 实现滑动菜单(富文本版本)
- 8JAVA中 map list Stream流_java map里面存放list
- 9dubbo yml配置_SpringBoot2.0完美整合Dubbo
- 10java7 3dm下载_我的世界 1.7.10最新forge极简整合包
集智书童 | YOLOPoint开源 | 新年YOLO依然坚挺,通过结合YOLOv5&SuperPoint,成就多任务SOTA
赞
踩
本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:YOLOPoint开源 | 新年YOLO依然坚挺,通过结合YOLOv5&SuperPoint,成就多任务SOTA

未来的智能车辆必须能够理解和安全地导航周围环境。基于摄像头的车辆系统可以利用关键点和物体作为Low-Level 和High-Level Landmark,进行独立于GNSS的SLAM和视觉测程。
为此,作者提出了YOLOPoint模型,这是一个卷积神经网络模型,它是通过结合YOLOv5和SuperPoint,在单一前向传递网络中同时检测图像中的关键点和物体,该网络既具备实时性又准确。通过使用共享的Backbone网络和轻量级的网络结构,YOLOPoint能够在HPatches和KITTI基准测试上都具有竞争力。
代码:https://github.com/unibwtas/yolopoint
1 Introduction
关键点通常是指 Low-Level 的Landmark,如点、角点或边缘,它们可以从不同的视角轻松检索。这使得移动车辆能够估计其相对于周围环境的位置和方向,甚至可以使用一个或多个相机执行闭环(即同时定位与地图构建,SLAM)。在历史上,这项任务是通过手工设计的特征描述子来完成的,如ORB,SURF,HOG,SIFT。然而,这些方法要么不支持实时处理,要么在光照变化、运动模糊等干扰下表现不佳,或者检测到的关键点是聚集成簇而不是在图像中分散,这降低了姿态估计的准确性。学习到的特征描述子旨在解决这些问题,通常通过以随机亮度、模糊和对比度的形式进行数据增强。
此外,学习到的关键点描述子已经显示出优于传统描述子的性能。SuperPoint就是这样一种关键点描述子,它是一个卷积神经网络(CNN),作者将其作为一个基础网络来改进。
SuperPoint是一个多任务网络,它能在一个前向传播过程中联合预测关键点和它们各自的特征描述符。它通过在关键点检测器和描述符 Head 之间共享一个 Backbone 网的特征输出来实现这一点。这使得它在计算上效率高,因此非常适合实时应用。

此外,在对SuperPoint架构进行各种调整之后,作者将其与YOLOv5——一个实时目标检测网络融合。因此,整个网络对这三项任务使用了一个共享的Backbone网络。而且,在使用YOLOv5框架的基础上,作者训练了四个不同大小的模型:nano、small、middle 和 large。作者将这个组合网络称为YOLOPoint。
作者的动机是将关键点检测器与目标检测器融合如下:
-
首先,为了更准确的SLAM和更好的了解周围场景,使用一套多方向摄像头是有益的。但是,并行处理多个视频流意味着需要依赖高效的卷积神经网络(CNN)。在计算效率方面,特征提取部分承担了大部分重担。这就是为什么多个不同任务共享一个基础网络已成为常见做法。SuperPoint的架构已经设置为用于关键点检测和描述的共享基础网络,因此它与其他模型的融合是恰当的选择。
-
其次,视觉SLAM工作在静态环境的假设下。如果移动目标上检测到关键点,会导致定位错误和不需要的Landmark映射。然而,通过分类的物体边界框,作者只需过滤掉动态类别(例如,行人、汽车、自行车)框内的所有关键点。最后,尽管关键点检测和目标检测看似差异太大而无法联合学习,但它们在传统方法中已经被联合使用(例如,基于关键点描述子的目标检测与支持向量机分类器)。
作者的贡献可以总结如下:
-
提出了YOLOPoint,这是一个快速且高效的关键点检测与描述网络,特别适合用于执行视觉里程计。
-
展示了目标检测和关键点检测并不是相互排斥的,并提出了一个可以在单次前向传播中同时完成这两项任务的网络。
-
展示了在点描述和检测任务中使用CSP Block的有效性。
2 Related Work
经典关键点描述子使用的是手工设计的算法,旨在克服如尺度变化和光照变化等挑战,并且已经被彻底评估。尽管它们的主要用途是关键点描述,但它们也已被结合支持向量机用于目标检测。
自那时起,基于深度学习的方法已经在目标检测(即目标定位和分类)和其他计算机视觉任务的基准测试中占据主导地位。因此,研究越来越多地致力于寻找它们也可以用于点描述的方法。同时使用基于CNN的转换模型COTR和LoFTR在多个图像匹配基准测试中取得了最先进的结果。COTR通过将两幅图像的特征图 ConCat 在一起,并在 Transformer 模块中使用位置编码来处理它们,从而在两幅图像之间找到密集的对应关系。然而,它们的方法侧重于匹配精度而非速度,并对同一图像的多个缩放 Level 进行推理。LoFTR的方法与之类似,主要区别在于他们的“从粗到细”模块首先预测粗略的对应关系,然后使用来自更高级特征图的裁剪来细化它们。这两种方法都不需要检测器,尽管在匹配精度方面取得了优异的结果,但它们都不适合实时应用。
那些既能产生关键点检测又能产生描述子(descriptor)的方法通常更快,因为它们只匹配稀疏的点集,包括R2D2、D2-Net和SuperPoint。R2D2通过引入一个可靠性预测头,解决了重复纹理的匹配问题,该预测头指示给定像素处描述子的判别性。D2-Net有一种独特的方法,即使用输出特征图既进行点检测也进行描述,因此两个任务之间共享网络的全部权重。相比之下,SuperPoint有一个共享的Backbone网络,但分别为检测和描述任务设置了独立的头。使其与其他所有项目区别开来的是其自监督训练框架。
当其他作者从通过运动结构获得的深度图像中获取真实点对应关系,即使用视频时,SuperPoint框架可以创建单个图像的标签。它首先生成一系列描绘随机形状的标记灰度图像,然后在合成数据上训练一个中间模型。中间模型随后在一个大型数据集(这里指MS COCO)上进行点预测,并使用他们的“单应性适应”方法进行优化。最终的模型在优化后的点标签上进行训练。
尽管已经存在几种同时预测关键点和描述符的模型,但据作者所知,没有一种模型还能在同一个网络中检测物体。Maji等人[15]的研究成果与作者的工作最为接近。他们使用YOLOv5在一个前向传播中联合预测用于人体姿态估计的关键点以及边界框。主要的区别在于,关键点检测训练使用了手工标记的 GT 点,目标检测器仅在一个类别(人)上进行训练,并且这两个任务都依赖于类似特征。
3 Model Architecture
作者的关键点检测模型是基于SuperPoint,并融入了CSPDarknet的元素。SuperPoint使用了一个类似VGG的编码器,将尺寸为 H x W x 1 的灰度图像分解为一个尺寸为 H/8 x W/8 x 128 的特征向量。在每个解码器 Head ,特征向量进一步被处理并 Reshape 为原始图像大小。因此,关键点解码分支生成一个 Heatmap ,表示像素级的“点状”概率,这通过非最大值抑制方法生成最终的关键点。描述符分支的输出是一个规范化的描述符向量,线性放大到 H x W x 256 。这两个输出组合成一个关键点列表及其对应的描述符向量,利用它们可以从一帧到另一帧匹配关键点。
作者的SuperPoint版本用CSPDarknet的一部分替换了类似于VGG的Backbone网络,并在每个 Head 增加了CSP瓶颈和额外的卷积。CSP瓶颈是YOLO的基石,为各种不同的计算机视觉任务提供了良好的速度与准确度权衡,但迄今为止尚未用于视觉Landmark的关键点检测。作者保留了与SuperPoint相同的最后几层,即在检测Head中使用softmax和 Reshape ,在描述符头中使用2D卷积。
采用YOLOv5的缩放方法,作者创建了四个网络,每个网络在宽度、深度和描述符长度上各不相同。描述符的大小分别为256、196、128和64,对应于模型YOLOPointL、-M、-S和-N。较短的描述符减少了匹配的计算成本,但代价是准确度降低。作为比较:SIFT的描述符向量有128个元素,而ORB的只有32个。由于减小向量大小会带来准确度的权衡,最小的向量被设定为64。
此外,为了让描述符能够匹配并区分其他关键点,它需要一个大的感受野[24]。然而,这会导致输入图像的下采样,并在过程中丢失细节。为了保留细节,作者在执行进一步卷积之前,将低分辨率特征图通过最近邻插值放大,并将其与Backbone网络中更高层次的特征图连接起来。与YOLOv5融合的完整模型如图2所示。

4 Training
为了生成伪 GT 点标签,作者遵循SuperPoint的方法,首先在合成形状数据集上训练YOLOPoint的点检测器,然后使用它通过单应性适应来在COCO数据集上生成精细的输出以进行预训练。在COCO上进行预训练并非严格必要,然而它可以在较小数据集上进行微调时改善结果,同时也可以减少训练时间。因此,这些预训练权重后来在KITTI数据集上进行微调。
为了训练完整的模型,由已知单应性变换扭曲的成对RGB图像分别通过独立的正向传递进行处理。模型随后预测“点性” Heatmap 、描述符向量和目标边界框。在可变图像大小的数据集(例如,MS COCO)上进行训练时,必须将图像适配到固定大小,以便作为批量处理。一个常见的解决方案是在图像的两侧填充,使得W = H,这也被称为信箱式处理。然而,作者发现这会导致在填充区域附近预测出假阳性关键点,这是由于黑色填充与图像之间的强烈对比,这对训练产生了负面影响。
因此,在COCO上进行预训练时,作者使用马赛克增强方法,将四张图像并排拼接,以填充整个图像画布,从而无需图像填充。所有的训练都是使用批量大小为64的Adam优化器,预训练的学习率为10^-3,微调的学习率为10^-4。
对于在KITTI数据集上的微调,作者将数据划分为6481张训练图像和1000张验证图像,尺寸调整为。为了适应新的目标类别,作者替换了最后的目标检测层,并在冻结所有权重除了检测层权重的情况下训练了20个周期。最后,作者解冻所有层,并再训练整个网络50个周期。
4.1 Loss Functions
模型对扭曲图像和非扭曲图像的输出被用于计算关键点检测器和描述子损失。然而,只有非扭曲图像的输出被用于目标检测损失,以避免教导强烈的物体扭曲表示。


5 Evaluation
在以下各节中,作者将展示在HPatches 上关键点检测和描述的评价结果,以及在使用三个任务头进行视觉里程计(VO)估计的KITTI基准上的结果。对于HPatches上的评估,使用了在MS COCO上训练了100个周期的模型;对于VO,这些模型是在KITTI数据上进行了微调。
5.1 Repeatability and Matching on HPatches
HPatches数据集总共包含116个场景,每个场景包含6张图像。其中57个场景展现大的光照变化,59个场景展现大的视点变化。用于评估关键点任务的两个主要指标是可重复性,它量化了关键点检测器在光照和/或视点变化下,一致性地在相同位置定位关键点的能力,以及单应性估计,它测试检测器和描述子的可重复性和辨识能力。作者的评估协议在与SuperPoint可能保持一致的前提下进行。
5.1.1 Repeatability
可重复性在256 x 320的分辨率下计算,每张图像可检测多达300个点,使用8像素的非最大值抑制。如果在一个关键点在两帧中都在像素范围内被检测到,那么这个关键点被视为可重复的。可重复性得分决定了重复关键点的数量与总体检测到的关键点数量的比例。
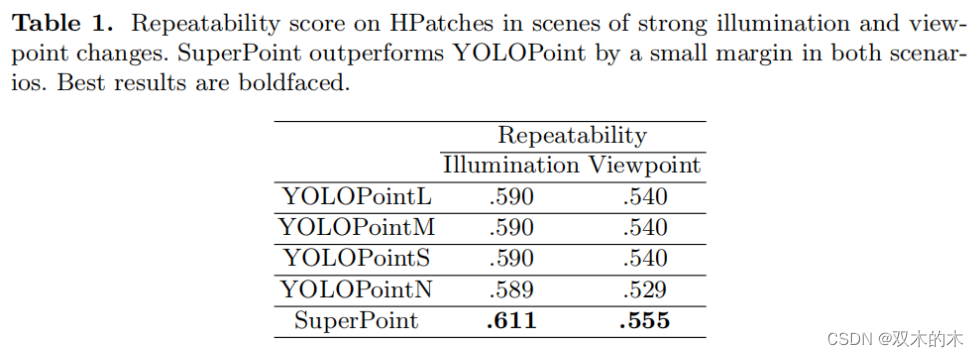
表1概述了在不同视角和光照变化下的可重复性得分。SuperPoint在光照和视角变化方面都略优于YOLOPoint。令人惊讶的是,尽管参数数量差异很大,YOLOPoint的所有四个版本的表现几乎相同。一个可能的解释是,关键点检测分支相对于任务的简单性实际上拥有过多的参数。
5.1.2 Homography Estimation
单应性估计是在的分辨率下计算的,每张图像可检测多达1000个点,采用8像素的非最大值抑制。通过使用两帧之间的匹配点(见图3),估计了一个描述两帧之间点变换的单应性矩阵。然后使用估计的单应性将一个图像的角点变换到另一个图像上。如果角点的距离的l2范数在边际范围内,则认为单应性是正确的。

表2展示了在不同视角变化场景下单应性估计的结果。总体而言,两个模型的表现大致相当,尽管SuperPoint在更大的误差边际内略微取得了更好的结果。SuperPoint的描述子具有显著更高的最近邻平均精度(NN mAP),表明其具有很好的区分能力,但是与YOLOPoint相比,匹配得分较低。匹配得分是衡量检测器和描述子的一项指标,因为它测量的是在共享视角区域内,真实对应关系与提出特征数量之间的比率。

5.2 Visual Odometry Estimation on KITTI
KITTI测距基准包含11个交通场景的图像序列,这些序列具有从移动车辆的第一人称视角捕获的、公开可用的真实相机轨迹。
里程计是通过仅使用帧到帧的关键点跟踪来估计的(即没有闭环检测、捆绑调整等),以获得对关键点检测器/描述子的无失真评估。在作者的测试中,作者评估了不同版本的YOLOPoint,并通过使用目标边界框过滤掉动态目标上的关键点与SuperPoint和其他实时经典方法进行比较。
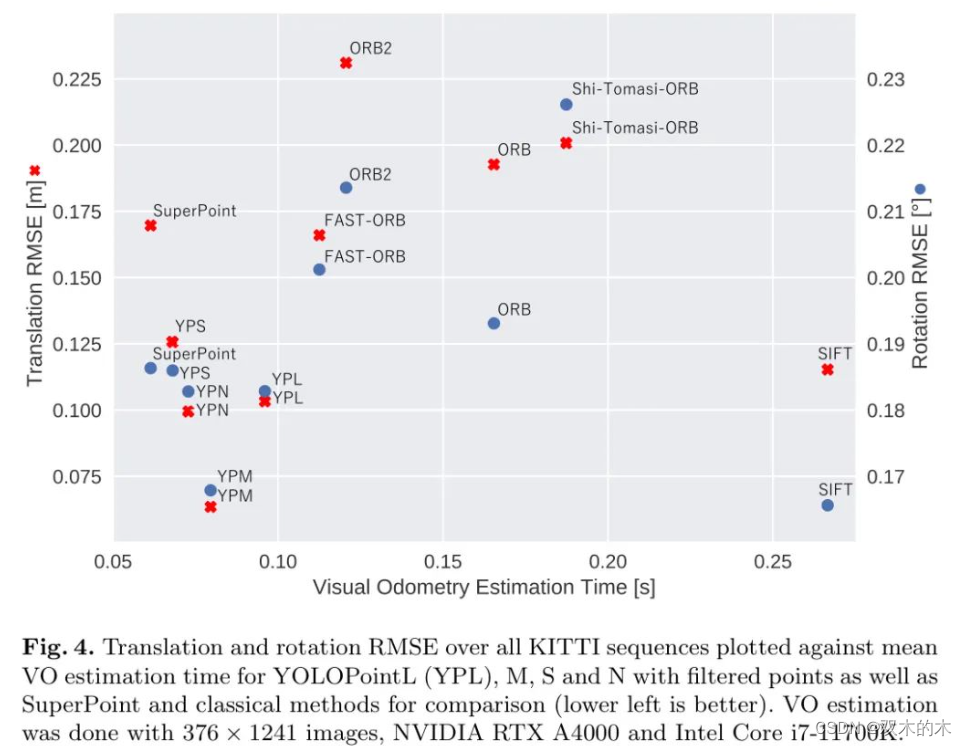
图4针对几个模型,绘制了所有序列的平均VO估计时间(即关键点检测、匹配和姿态估计)的均方根误差(RMSE)。尽管检测目标的负担增加了,但YOLOPoint在速度和准确性之间提供了良好的权衡,一个完整的迭代所需时间不到100毫秒。YOLOPoint的纯粹推理时间(即不包括姿态估计)分别为L、M、S和N的49、36、27和25毫秒。
需要注意的是,尽管使用YOLOPointN的推理时间更快,但它的关键点有更多的异常值和更嘈杂的对应关系,导致VO时间更长。因此,姿态估计算法需要更多的迭代步骤才能收敛,从而造成VO速度变慢。

动态关键点的过滤效果最好可以在序列01中得到证明,因为该序列显示的是在一条高速公路上的行驶,其中的特征点稀疏且重复,即难以进行匹配。因此,在经过的车辆上检测到的点不再被静态点所淹没(图5),这导致了显著的姿态估计误差。
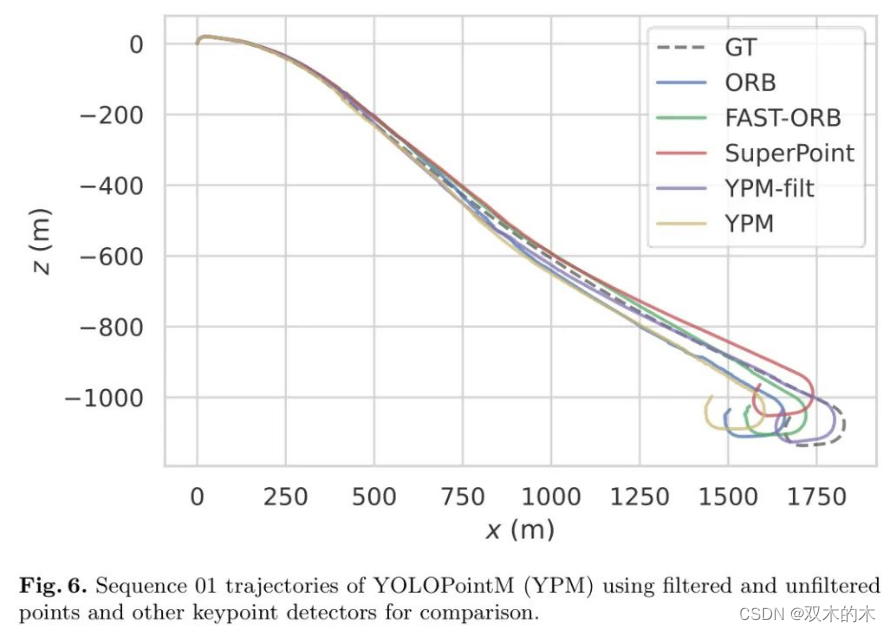
图6展示了一些轨迹,包括有和没有过滤点的YOLOPointM。在没有过滤的情况下,由于在经过的车辆上检测到许多点,YOLOPoint在这个序列上的表现相对较差。最后,尽管移除了所有车辆上的点,无论它们是否在运动,但作者发现这并没有对在包含许多停泊车辆的场景中的姿态估计精度产生显著的负面影响。
6 Conclusion and Future Work
在这项工作中,作者提出了YOLOPoint,一个卷积神经网络,它能快速且高效地在单个前向传播中共同预测关键点、它们各自的特征描述符和目标边界框,使其特别适合于自动驾驶等实时应用。作者的测试表明,使用类似Darknet架构的关键点检测Head在匹配和重复性任务中的表现与SuperPoint相当,这些任务具有强烈的视角和光照变化。
在KITTI视觉测距数据集上,作者将作者模型的姿态估计性能与SuperPoint和一些经典方法进行了比较。利用预测的边界框过滤掉非静态关键点,YOLOPoint在所有测试方法中展示了最佳的准确性与速度折衷。
未来的工作将集中在将YOLOPoint整合到作者的SLAM框架中,通过使用关键点和静态物体作为Landmark,并通过匹配关键点来提高物体跟踪的鲁棒性。
7 参考
[1].YOLOPoint: Joint Keypoint and Object Detection+.
THE END!
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


