
- 1IntelliJ IDEA 4 新特性 之 On-the-Fly Code Analysis(动态代码分析)_on-the-fly code analysis怎么用
- 2深度学习系列56:使用whisper进行语音转文字_faster-whisper加速
- 3华为桌面云解决方案概述_解决方案概述和数据安全建议
- 4cmd命令之Xcopy介绍_复制文件夹里所有文件到另一个文件夹操作方式
- 5C++学习笔记——Eigen模块(用于矩阵运算)_c++ eigen
- 6基于vue-simple-uploader的文件分片上传_vue-simple-uploader配置categorymap
- 7洛谷B2095 白细胞计数
- 82021年中国企业直播行业发展回顾及未来预测分析[图]_直播间前五年收入预测
- 9Hive映射Hbase_hive hbase 映射表
- 10DOS 字符和符号_dos 通配符
数据分析---pandas---DataFrame的常用操作_对单列数据的访问
赞
踩
1 查看 DataFrame 的常用属性

2 查改增删 DataFrame 数据
-
对单列数据的访问:DataFrame 的单列数据为一个 Series。根据 DataFrame 的定义可以知晓 DataFrame 是一个带有标签的二维数组,每个标签相当每一列的列名。
有以下两种方式来实现对单列数据的访问。 -
以字典访问某一个 key 的值的方式使用对应的列名,实现单列数据的访问。
-
以属性的方式访问,实现单列数据的访问。(不建议使用,易引起混淆)
-
对某一列的某几行访问:访问 DataFrame 中某一列的某几行时,单独一列的 DataFrame可以视为一个 Series(另一种 pandas 提供的类,可以看作是只有一列的 DataFrame),而访问一个 Series 基本和访问一个一维的 ndarray 相同。
-
对多列数据访问:访问 DataFrame 多列数据可以将多个列索引名称视为一个列表,同时访问 DataFrame 多列数据中的多行数据和访问单列数据的多行数据方法基本相同。
-
head 和 tail 也可以得到多行数据,但是用这两种方法得到的数据都是从开始或者末尾获取的连续数据。默认参数为访问 5 行,只要在方法后方的“()”中填入访问行数即可实现目标行数的查看。
3.查看访问 DataFrame 中的数据——loc,iloc 访问方式:
- loc 方法是针对 DataFrame 索引名称的切片方法,如果传入的不是索引名称,那么切片操作将无法执行。利用 loc 方法,能够实现所有单层索引切片操作。loc 方法使用方法如下。
DataFrame.loc[行索引名称或条件, 列索引名称]
- iloc 和 loc 区别是 iloc 接收的必须是行索引和列索引的位置。iloc 方法的使用方法如下。
DataFrame.iloc[行索引位置, 列索引位置]
- 使用 loc 方法和 iloc 实现多列切片,其原理的通俗解释就是将多列的列名或者位置作为一个列表或者数据传入。
- 使用 loc,iloc 方法可以取出 DataFrame 中的任意数据。
- 在 loc 使用的时候内部传入的行索引名称如果为一个区间,则前后均为闭区间;iloc 方法使用时内部传入的行索引位置或列索引位置为区间时,则为前闭后开区间。
- loc 内部还可以传入表达式,结果会返回满足表达式的所有值。
Example:
以菜品订单为例,利用 loc 获取 order_id='458’的所有菜名名称:
#loc 内部传入表达式
print(‘detail 中 order_id 为 458 的 dishes_name 为:\n’, detail.loc[detail[‘order_id’]==458, [‘order_id’,‘dishes_name’]])

若使用 detail.iloc[detail[‘order_id’]==‘458’,[1,5]]读取数据,则会报错,原因在于此处条件返回的为一个布尔值 Series,而 iloc 可以接收的数据类型并不包括 Series。根据 Series的 构 成 只 要 取 出 该 Series 的 values 就 可 以 了 。 需 改 为:
detail.iloc[(detail[‘order_id’]==‘458’).values,[1,5]])
- loc 更加灵活多变,代码的可读性更高,iloc 的代码简洁,但可读性不高。具体在数据分析工作中使用哪一种方法,根据情况而定,大多数时候建议使用 loc 方法
Example:
import pandas as pd import numpy as np detail = pd.read_excel('meal_order_detail.xlsx') # loc result = detail.loc[detail['order_id']==137,['dishes_name','amounts']] print(result.head()) ''' dishes_name amounts 385 西瓜胡萝卜沙拉 26 386 麻辣小龙虾 99 387 农夫山泉NFC果汁100%橙汁 6 388 番茄炖牛腩\r\n 35 390 白饭/小碗 1 ''' result = detail.loc[detail['amounts']>100,['dishes_name']] print('菜品单价大于100元的数据:\n',result.head()) ''' 菜品单价大于100元的数据: dishes_name 11 芝士烩波士顿龙虾 12 葱姜炒蟹 53 红酒炖羊肉 65 倒立蒸梭子蟹 74 53度茅台 ''' # iloc # 格式:DataFrame.iloc[行索引位置, 列索引位置] print(detail.iloc[1,1])#417 print(detail.iloc[0:6,1:6]) ''' order_id dishes_id logicprn_name parent_class_name dishes_name 0 417 610062 NaN NaN 蒜蓉生蚝 1 417 609957 NaN NaN 蒙古烤羊腿 2 417 609950 NaN NaN 大蒜苋菜 3 417 610038 NaN NaN 芝麻烤紫菜 4 417 610003 NaN NaN 蒜香包 5 301 610019 NaN NaN 白斩鸡 '''

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
4更新修改 DataFrame 中的数据:
更改 DataFrame 中的数据,原理是将这部分数据提取出来,重新赋值为新的数据。需要注意的是,数据更改直接针对 DataFrame 原数据更改,操作无法撤销,如果做出更改,需要对更改条件做确认或对数据进行备份。
Example:
将 order_id 为 458 的,变换为 45800:

5增添删除数据:
- DataFrame 添加一列的方法非常简单,只需要新建一个列索引。并对该索引下的数据进行赋值操作即可。
- 新增的一列值是相同的则直接赋值一个常量即可。
- 删除某列或某行数据需要用到 pandas 提供的方法 drop,drop 方法的用法如下
- axis 为 0 时表示删除行,axis 为 1 时表示删除列:
drop(labels, axis=0, level=None, inplace=False, errors=‘raise’)
常用参数如下所示:

6描述分析 DataFrame 数据
1.数值型特征的描述性统计——NumPy 中的描述性统计函数:
- [ ]数值型数据的描述性统计主要包括了计算数值型数据的完整情况、最小值、均值、中位数、最大值、四分位数、极差、标准差、方差、协方差和变异系数等。pandas 库基于 NumPy,自然也可以用这些函数对数据框进行描述性统计。
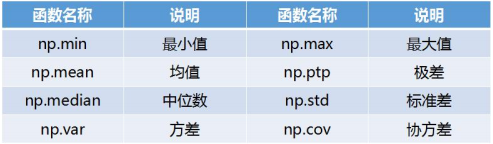
2.数值型特征的描述性统计—— pandas 描述性统计方法
- pandas 还提供了更加便利的方法来计算均值 ,如 detail[‘amounts’].mean()
- pandas 还提供了一个方法叫作 describe,能够一次性得出数据框所有数值型特征的非空
值数目、均值、四分位数、标准差。
detail[[‘counts’,‘amounts’]].describe()


3.类别型特征的描述性统计:
-
描述类别型特征的分布状况,可以使用频数统计表。pandas 库中实现频数统计的方法为
value_counts。 -
pandas 提供了 categories 类,可以使用 astype 方法将目标特征的数据类型转换为 category类别。
-
describe 方法除了支持传统数值型以外,还能够支持对 category 类型的数据进行描述性统计,四个统计量分别为列非空元素的数目,类别的数目,数目最多的类别,数目最多类别的数目。

