
- 1人工智能大模型原理与应用实战:自动驾驶技术的飞跃
- 2普通二重积分计算的难点、易错点_二重积分圆开根号正负
- 3行业模板|DataEase教育行业大屏模板推荐
- 4计算机职称分类汇总,全国职称分类汇总表.doc
- 5Banana Pi BPI-M7 迷你尺寸开源硬件开发板采用瑞芯微RK3588芯片设计
- 6十、Linux多进程编程
- 7windows上连接MYSQL_windows 本地如何连接mysql服务端
- 8PY32F002/PY32F003/PY32F030入门笔记(1)
- 9git使用.gitignore失效_git 没有.gitignore
- 10一步步带你看SpringBoot(2.3.3版本)自动装配原理_spring boot 2.3.3.release 版本对应的依赖
C语言数据结构-第五章 数组与广义表 -电大同步进度_c语言以列序为主什么意思
赞
踩
第五章 数组与广义表
数组(Array)和广义表(Generalized List),可看成是一种扩展的线性数据结构,其特殊性不像栈和队列那样表现在对数据元素的操作受限制,而是反映在数据元素的构成上。
在组成线性表的元素方面
l 数组可看成是由具有某种结构的数据构成,
l 广义表可以是由单个元素或子表构成。
因此数组和广义表中的数据元素可以是单个元素也可以再是一个线性结构。从这个意义上讲,数组和广义表是线性表的推广。
第1讲数组的定义与顺序存储——内容简介
数组的定义:从逻辑结构上,数组可以看成是一般线性表的扩充。一维数组即为线性表,而二维数组可以定义为“其数据元素为一维数组(线性表)”的线性表。
数组的ADT
数组的顺序存储结构
一维数组地址计算
二维数组地址计算
三维数组地址计算
多维数组地址计算
1 讲 数组的定义与顺序存储
1、数组的定义和运算
数组是我们十分熟悉的结构,高级语言一般都支持数组这种数据类型。在程序设计中,已学习了数组的使用,本节重点介绍数组在计算机内部如何处理(存取、地址计算)。
( 1 )数组的定义
从逻辑结构上,数组可以看成是一般线性表的扩充。
一维数组即为线性表,而二维数组可以定义为“其数据元素为一维数组(线性表)”的线性表。依此类推,即可得到多维数组的定义。以二维数组为例,如下图所示。

可以把二维数组看成是一个线性表: A =(α1 ,α2 ,…,αn),其中αj( 1 ≤ j≤ n)本身也是一个线性表,称为列向量,即αj=(a1j,a2j,… ,amj),如下图( a)所示。 A 是由 n 个列向量组成的。
二维数组 Am × n 可以看成是由 n 个元素组成的线性表,表中的元素αi 即( a1 ia2 i… ai i am i)如下图 ( b)所示,表中的每个数据元素是由 m 个数组元素组成的线性表。

同样,还可以将数组 Am × n 看成另外一个线性表: B=(β1 ,β2 ,…,β m),其中βi( 1 ≤ i≤ m)本身也是一个线性表,称为行向量,即:β i =( ai1 ,ai2 ,a ij,…,ai n),如下图所示

如上图所示,在二维数组中,元素 ai j 处在第 i 行和第 j 列的交叉处,
即元素aij 同时有两个线性关系约束,ai j 既是同行元素 ai j - 1 的“行后继”,又是同列元素 ai - 1 j 的“列后继”。
同理三维数组可以看成是这样的一个线性表,其中每个数据元素均是一个二维数组,
即三维数组是“数据元素为二维数组”的线性表。
数组中的每个元素同时有三个线性关系约束,
推广之,N 维数组是“数据元素为 N-1维数组”的线性表。
由数组结构可以看出,数组中的每一个元素由一个值和一组下标来描述。
“值”代表数组中元素的数据信息,一组下标用来描述该元素在数组中的相对位置信息。
数组的维数不同,描述其相对位置的下标的个数也不同。
例如,在二维数组中,元素 ai j 由两个下标值 i、 j 来描述。其中 i 表示该元素所在的行号,j 表示该元素所在的列号。
同样可以将这个特性推广到多维数组,对于 n 维数而言,其元素由 n 个下标值来描述其在 n 维数组中的相对位置。
( 2 )数组的运算
数组是一组有固定个数的元素的集合。
即,一旦定义了数组的维数和每一维的上、下限,数组中元素的的个数就固定了。
例如二维数组 A3 × 4 ,它有 3 行、 4列,即由 12 个元素组成。
由于这个性质,使得对数组的操作不像对线性表的操作那样可以在表中任意一个合法的位置插入或删除一个元素。
对于数组的操作一般只有两类:
①获得特定位置的元素值;
②修改特定位置的元素值。
因此数组的操作主要是数据元素的定位,即给定元素的下标,得到该元素在计算机中的存放位置。其本质上就是地址计算问题。
( 3 )数组的抽象数据类型定义
数组的抽象数据类型定义如下:

基本操作:
(1) InitArray(A,n,bound1,…,boundn): 若维数 n 和各维的长度合法,则构造相应的数组 A,并返回 TRUE;
(2)DestroyArray(A): 销毁数组 A;
(3)GetValue(A,e, index1, …,indexn):若下标合法,则用 e 返回数组 A 中由 index1, …,indexn 所指定的元素的值。
(4)SetValue(A,e,index1, …,indexn):若下标合法,则将数组 A 中由index1, …,indexn 所指定的元素的值置为 e。
}ADT Array
注意:这里定义的数组与 C 语言的数组略有不同,下标统一从 1 开始。
2、数组的顺序存储
数组是一种特殊的数据结构,一旦给定数组的维数 n 及各维长度 bi( 1 ≤ i≤ n),则该数组中元素的个数是固定的,数组的基本操作中不涉及数组结构的变化,因此对于数组而言,采用顺序存储表示比较适合。
在计算机中,内存储器的结构是一维的。
对于一维数组可直接采用顺序存储,用一维的内存存储表示多维数组,就必须按某种次序将数组中元素排成一个线性序列,
然后将这个线性序列存放在一维的内存储器中,这就是数组的顺序存储结构。
数组的顺序存储结构有两种:一种是按行序存储,如高级语言 BASIC、 COBOL、Pascal和 C 语言都是以行序为主。
另一种是按列序存储,如高级语言中的 FORTRAN 语言就是以列序为主。
显然,二维数组 Am × n 以行为主的存储序列为:
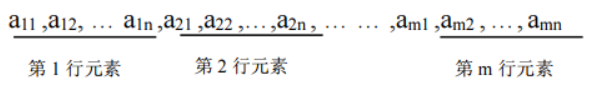
而以列为主存储序列为

假设有一个 3 ×4 ×2 的三维数组 A,共有 24 个元素。其逻辑结构如下图所示。

三维数组元素的标号由三个数字表示,即行、列、纵三个方向。 a142 表示第 1 行,第 4 列,第 2 纵的元素。如果对 A3 × 4 × 2 (下标从 1 开始)采用以行为主序的方法存放,
即行下标变化最慢,纵下标变化最快,则顺序为:
a111,a112,a121,a122,…,a331,a332,a341,a342
采用以纵为主序的方法存放,即纵下标变化最慢,行下标变化最快,则顺序为:
a111,a211,a311,a121,a221,a321,…,a132,a232,a332,a142,a242,a342
以上的存放规则可推广到多维数组的情况。
总之,知道了多维数组的维数,以及每维的上下界,就可以方便地将多维数组按顺序存储结构存放在计算机中了。
同时,根据数组的下标,可以计算出其在存储器中的位置。因此,数组的顺序存储是一种随机存取的结构。
( 1 )一维数组的地址计算
一维数组中的元素只需要一个下标,其实质是线性表,存储方法与普通线性表存储方法完全相同,
即将数组元素按它们的逻辑次序存储在一片连续的存储区域内。设一维数组为:A = ( a1 ,a2 ,…, ai,…, an)
数组中每个元素占 size 个存储单元,则元素 ai 的存储地址为:Loc( A[ i])= Loc( A[ 1 ])+( i-1 )× size
( 2 )二维数组的地址计算
以二维数组 Am × n 为例,假设每个元素只占一个存储单元,“以行为主”存放数组,下标从 1 开始,首元素 a11 的地址为 Loc( A[ 1 ][ 1 ]),求任意元素 aij 的地址。
aij 是排在第 i,第 j列,并且前面的 i-1 行有 n×( i-1 )个元素,第 i 行第 j 个元素前面还有 j-1 个元素。如果每个元素占 1 个存储单元,由此得到如下地址计算公式:
Loc( A[ i][ j])= Loc( A[ 1 ][ 1 ])+ n ×( i-1 )+( j -1 )
根据计算公式,可以方便地求得 aij 的地址是 Loc( A[ i][ j])。如果每个元素占 size 个存储单元,
则任意元素 aij 的地址计算公式为:
Loc( A[ i][ j])= Loc( A[ 1 ][ 1 ])+ ( n ×( i-1 )+ j-1 )× size
例 5 -1 已知二维数组 a[ 5 ][ 4 ]按行序为主序存放,每个元素占 4 个字节空间,计算:
①计算数组 a 中元素的个数;
②若数组 a 的首元素 a[ 1 ][ 1 ]地址为 2000 ,计算 a[ 3 ][ 2 ]的内存地址。
解:
( 1 )数组 a 中元素个数为: 4 ×5 =20
( 2 ) Loc( a[ 3 ][ 2 ])= 2000 +( 4 ×( 3 -1 )+( 2 -1 ))× 4 =2036
( 3 )三维数组的地址计算
三维数组 A( 1 ..r,1 ..m,1 ..n)可以看成是 r 个 m ×n 的二维数组,如下图所示。

假定每个元素占 size 个存储单元,采用以行为主序的方法存放,即行下标 r 变化最慢,纵下标 n 变化最快。
首元素 a111 的地址为 Loc( A[ 1 ][ 1 ][ 1 ]),求任意元素 aijk 的地址。
显然,ai11 的地址为 Loc( A[ i][ 1 ][ 1 ])= Loc( A[ 1 ][ 1 ][ 1 ])+( i-1 )× m×n,因为在该元素之前,有 i-1 个 m×n 的二维数组。
由 a i11 的地址和二维数组的地址计算公式,不难得到三维数组任意元素 aijk的地址:
Loc ( A[ i][ j][ k])= Loc( A[ 1 ][ 1 ][ 1 ])+(( i -1 )× m×n +( j-1 )× n+( k-1 ))× size
其中: 1 ≤ i≤ r,1 ≤ j≤ m,1 ≤ k≤ n。
如果将三维数组推广到一般情况,即:用 j1 ,j2 ,j3 代替数组下标 i,j,k,并且 j1 ,j2 ,j3 的下限分别为 c1 ,c2 ,c3 ,上限分别为 d1 ,d2 ,d3 ,每个元素占 size 个存储单元。
则三维数组中任意元素 aj1j2 j3 的地址为:
Loc ( A[ j1 ][ j2 ][ j3 ])= Loc ( A[ c1 ][ c2 ][ c3 ])+(( d2 - c2 +1 )×( d3 - c3 + 1 )×( j1 - c1 )+( d3 - c3 +1 )×( j2 - c2 )+( j3 - c3 ))× size
或记为:
Loc ( A[ j1 ][ j2 ][ j3 ])= Loc( A[ c1 ][ c2 ][ c3 ])+size ×( d2 - c2 + 1 )×( d3 - c3 +1 )×( j1 - c1 )+size ×( d3 - c3 + 1 )×( j2 - c2 )+size ×( j3 - c3 )
令:α1 = size×( d2 -c2 +1 )×( d3 -c3 +1 ),α2 = size×( d3 -c3 +1 ),α3 = size,则:
Loc( A[ j1 ][ j2 ][ j3 ]= Loc( A[ c1 ][ c2 ][ c3 ])+α 1 ×( j1 - c1 )+ α2 ×( j2 - c2 )+ α 3 ×( j3 - c3 )= Loc( A[ c1 ][ c2 ][ c3 ])+ ∑ αi ×( ji - ci), 1≤ i≤ 3
由公式可知 Loc( A[ j1 ][ j2 ][ j3 ])与 j1 ,j2 ,j3 呈线性关系。
( 4 ) n 维数组的地址计算
对于 n 维数组 A( c1 : d1 ,c2 : d2 ,…, cn: dn),只要把上式推广,就可以容易地得到 n 维数组中任意元素 aj 1 j2 … jn 的存储地址的计算公式:

在高级语言的应用层上,一般不会涉及到 Loc ( A[ j1 ][ j2 ]…[ jn])的计算公式,这一计算内存地址的任务是由高级语言的编译系统完成的。
在使用时,只需给出数组的下标范围,编译系统将根据用户提供的必要参数进行地址分配 , 用户则不必考虑其内存情况。
但是由Loc( A[ j1 ][ j2 ][ j3 ]计算公式可以看出,数组的维数越高,数组元素存储地址的计算量就越大,计算花费的时间就越多。
作业
数组的维数和维度一旦确定,数组中元素的个数就确定了,不能增加不能减少。( )
-
A.✓
-
B.×
数组的维数n决定了数组中的元素受n个线性关系的约束。( )
-
A.✓
-
B.×
数组如同一般的线性表,可以做的基本运算包括存取指定位置的元素,插入,删除等。( )
-
A.✓
-
B.×
假设有6行8列的二维数组A(下标从1开始),每个元素占用6个字节,存储器按字节编址。已知A的基地址为1000,数组A共占用 288 字节;
假设有6行8列的二维数组A(下标从1开始),每个元素占用6个字节,存储器按字节编址。已知A的基地址为1000 ,计算数组A的最后一个元素的地址是 1282 。
假设有6行8列的二维数组A(下标从1开始),每个元素占用6个字节,存储器按字节编址。已知A的基地址为1 000 ,计算按行存储时元素A36的地址是 1126 ;
假设有6行8列的二维数组A(下标从1开始),每个元素占用6个字节,存储器按字节编址。已知A的基地址为1 000 ,计算按列存储时元素A36的地址是 1192 。
第2讲规律分布特殊矩阵的压缩存储——内容简介
元素分布具有一定规律的矩阵称为规律分布的特殊矩阵,如三角矩阵(方阵的上或下三角全为零)和带状矩阵(若干条对角线含有非零元)。这类矩阵中元素分布的规律可以用数学公式来反映。
已知二维矩阵A中元素下标i和j,作为转换函数f的自变量,计算出到一维内存空间的地址值K,即A[ i][ j]=B[ K],实现了原二维矩阵到压缩存储后的一维数组的存储映射。
l 三角矩阵的特殊存储
l 带状矩阵的压缩存储
第 2 讲规律分布特殊矩阵的压缩存储
规律分布的特殊矩阵
元素分布具有一定规律的矩阵称为规律分布的特殊矩阵,如三角矩阵(方阵的上或下三角全为零)和带状矩阵(若干条对角线含有非零元)。这类矩阵中元素分布的规律可以用数学公
式来反映。已知二维矩阵 A 中元素下标 i 和 j,作为转换函数 f 的自变量,计算出到一维内存空间的地址值 K,即 A[ i][ j]=B[ K],实现了原二维矩阵到压缩存储后的一维数组的存储映射。
1 .三角矩阵
三角矩阵大体分为三类:下三角矩阵、上三角矩阵、对称矩阵。对于一个 n 阶矩阵 A 来说:若当 i <j 时,有 a ij =c(典型情况 c=0 ),则称此矩阵为下三角矩阵;若当 i>j 时,有 aij =c(典型情
况 c=0 ),则称此矩阵为上三角矩阵;若矩阵中的所有元素均满足 aij =aji,则称此矩阵为对称矩阵。
以图 1 所示的 n×n 下三角矩阵( c=0 )为例,讨论三角矩阵的压缩存储实现。
下三角矩阵的压缩存储原则是只存储下三角的非零元素,不存上三角的零元素。按“行序为主序”进行存储,得到的序列是 a11 ,a21 ,a2 2 ,a31 ,a32 ,a33 ,…, an1 ,an2 ,…, ann。
由于下三角矩阵 A 的元素个数为 n×( n +1 )/ 2 ,即:

可压缩存储到一个大小为 n ×( n+1 )/ 2 的一维数组 B 中。如图 所示

即只存下三角(或上三角)矩阵,从而将 n 个元素压缩到 n(n+1)/2 个空间中
下三角矩阵中元素 aij(i>j),在一维数组 B 中的存储地址为:Loc[ i ,j]=Loc[1,1]+(前 i-1 行非零元素个数+第 i 行中 aij 前非零元素个数)*size
其中,前 i-1 行元素个数=1+2+3+4+ … +(i-1)= i (i -1)/2,第 i 行中 aij 前非零元素个数=j-1,size 为每个元素所占字节数,
因此有:LOC[ i ,j]= LOC[1,1]+(i (i -1)/2+ j-1)*size
对于对称矩阵,因其元素满足 aij=aji,我们可以为每一对相等的元素分配一个存储空间,
实际应用中,如果将矩阵 A[][]压缩到一个一维数组 B[]中,我们更关心其下标的对应关系,
即如果将 A[i][j]存储到 B[k],那么如何通过 i 和 j,计算出 k 的值,进而获取 A[i][j]的值。下面以下三角为例(假设对角线以上全为 0):

思考题:类同按行为主序,请给出按列或按行为主序条件下上三角矩阵以及对称矩阵的相关推导。
2 .带状矩阵
( 1 )带状矩阵描述:在矩阵中的所有非零元素都集中在以主对角线为中心的带状区域中。其中最常见的是三对角带状矩阵,如图所示。

( 2 )三对角带状矩阵特点

( 3 )三对角带状矩阵压缩存储方法
三对角带状矩阵的压缩存储原则为:将带状区域上的非零元素按行序存储。其压缩存储方法如下。
①确定存储该矩阵所需的一维向量空间的大小
假设每个非零元素所占空间的大小为 size 个单元。从图 3 中观察得知,在三对角带状矩阵中,除了第一行和最后一行只有 2 个非零元素外,其余各行均有 3 个非零元素
由此得到:所需一维向量空间的大小为: 2 +2 +3 ×( n -2 )= 3 n-2 ,如图所示

②确定非零元素在一维数组空间中的地址
Loc ( A[ i][ j])= Loc ( A[ 1 ][ 1 ])+(前 i-1 行非零元素个数+第 i 行中 aij 前非零元素个数)*size
前 i-1 行元素个数=3 ×( i-1 )- 1 (因为第 1 行只有 2 个非零元素);
第 i 行中 ai j 前非零元素个数=j-i +1 ,其中
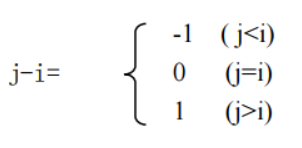
由此得到: Loc ( A[ i][ j])= Loc( A[ 1 ][ 1 ])+( 3 ( i-1 )- 1 +j-i +1)*size= Loc( A[ 1 ][ 1 ])+( 2 ( i-1 )+ j -1)*size
【本节要点】
1、 规律分布特殊矩阵的压缩存储原则:按规律存放非零元素;
2、 按规律找出地址计算公式
作业
已知一个n行n列的带状矩阵A,其中非零元素的个数是( )
-
A.3n
-
B.3n-2
-
C.3n+2
-
D.


若将n阶上三角矩阵A按列优先存放在一维数组B中,第一个非零元素存放在B[0]中,则非零元素aij存放在B[k]中,则k=( )
-
A.

-
B.

-
C.
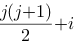
-
D.
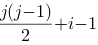

所谓的n阶下三角矩阵A是指当i<j时(i为元素的行标,j 为元素的列标)元素aij为0或常数C .( )
-
A.✓
-
B.×
所谓的n阶(n>3)三对角矩阵(带状矩阵)是指非零元素只出现在矩阵的两条对角线上。( )
-
A.✓
-
B.×
第3讲稀疏矩阵的压缩存储上——内容简介
本讲主要内容:
稀疏矩阵的压缩存储
- 三元组表表示法
- 三元组表表示法下矩阵的转置运算:“列序”递增转置法
第 3 讲 稀疏矩阵压缩存储上
稀疏矩阵是指矩阵中大多数元素为零的矩阵。从直观上讲,当非零元素个数低于总元素的 30 %时,这样的矩阵为稀疏矩阵。
如下图所示的矩阵 M、 N 中,非零元素个数均为 8 个,矩阵元素总数均为 6 ×7 =42 ,显然 8 /42 <30 %,所以 M、 N 都是稀疏矩阵。

1 稀疏矩阵的三元组表表示法
( 1 ) 稀疏矩阵的三元组存储表示
对于稀疏矩阵的压缩存储,采取只存储非零元素的方法。由于稀疏矩阵中非零元素 aij 的分布没有规律,
因此,要求在存储非零元素值的同时还必须存储该非零元素在矩阵中所处的行号和列号的位置信息,这就是稀疏矩阵的三元组表表示法。
每个非零元素在一维数组中的表示形式如下图所示。

说明:为处理方便,将稀疏矩阵中非零元素对应的三元组按“行序为主序”用一维结构体
数组进行存放,将矩阵的每一行(行由小到大)的全部非零元素的三元组按列号递增存放。由此
得到矩阵 M、 N 的三元组表 A 和 B。如下图所示。

( 2 )稀疏矩阵三元组表的类型定义
稀疏矩阵三元组表类型定义如下:
- #define MAXSIZE 1000 /*设非零元素的个数最多为 1000*/
- typedef struct
- {
- int row, col; /*该非零元素的行下标和列下标*/
- ElementType e; /*该非零元素的值*/
- }Triple;
- typedef struct
- {
- Triple data[MAXSIZE + 1]; /* 非零元素的三元组表。data[0]未用*/
- int m, n, len; /*矩阵的行数、列数和非零元素的个数*/
- }TSMatrix;
在稀疏矩阵情况下,采用三元组表表示法大量节约了存储空间,
以图 5.10 中的 M6*7 矩阵为例,需要 6*7=42 个存储单元,但 M 采用三元组表 A 存放,共有 8 个非零元素,每个非零元按占 3 个单元计算,需要 3*8=24 个单元,
显然比矩阵常规存储来讲还是大大节省存储。
( 3 )三元组表实现稀疏矩阵的转置运算
需要强调的是,矩阵常规存储是二维的,而三元组存储是一维的,由于矩阵存储结构的变化也带来了运算方法的不同,必需认真分析。
下面给出稀疏矩阵的转置运算问题,希望从中体会实现算法的处理思路和改进算法的技术。
矩阵转置指变换元素的位置,把位于( row,col)位置上的元素换到( col,row)位置上,把元素的行列互换。
如图 5 .10 的 6 ×7 矩阵 M,它的转置矩阵就是 7×6 的矩阵 N,并且 N( row,col)=M( col,row),其中,1 ≤ row≤ 7 ,1 ≤ col≤ 6 。
①矩阵转置的经典算法
采用矩阵的正常存储方式(二维数组)实现矩阵转置。
稀疏矩阵转置经典算法
- /*采用矩阵的正常存储方式(二维数组)实现矩阵转置:*/
- void TransMatrix(ElementType source[m][n],ElementType dest[n][m])
- {
- /*Source和dest分别为被转置的矩阵和转置以后的矩阵(用二维数组表示)*/
- int i,j;
- for(i=0;i<m;i++)
- for (j=0;j<n;j++)
- dest[j][i]=source[i][j];
- }
②三元组表实现稀疏矩阵的转置
假设 A 和 B 是稀疏矩阵 source 和 dest 的三元组表,实现转置的简单方法如下。
a.矩阵 source 的三元组表 A 的行、列互换就可以得到 B 中的元素,如下图所示。

b.如 a 操作,转置后矩阵的三元组表 B 中的三元组不是以“行序为主序”进行存放,
为保证转置后的矩阵的三元组表 B 也是以“行序为主序”进行存放,
则需要对行、列互换后的三元组 B 按 B 的行下标(即 A 的列下标)按递增有序进行重新排序,如下图所示。

由此可知,步骤 a 很容易实现,但步骤 b 重新排序势必会大量移动元素,从而影响算法的效率。
为了避免上述简单转置算法中行、列互换后重新排序引起的元素移动,可以采取以下两种处理方法。
方法一:“列序”递增转置法
【算法思想】采用按照“被转置矩阵”三元组表 A 的“列序”(即转置后三元组表 B 的行序)递增的顺序进行转置,并依次送入转置后矩阵的三元组表 B 中,这样一来,转置后矩阵的三元组表 B 恰好是以“行序为主序”。
【具体做法】如下图所示,找出第 1 行全部元素:第一遍从头至尾扫描三元组表 A,找出其中所有 col =1的三元组,转置后按顺序送到三元组表 B 中;

找出第 2 行全部元素:第二遍从头至尾扫描三元组表 A,找出其中所有 col =2 的三元组,转置后按顺序送到三元组表 B 中;
如此类推……
找出第 k 行全部元素:第 k 遍扫描三元组表 A,找出其中所有 col =k 的三元组,转置后按顺序送到三元组表 B 中。
k 的含义:每次扫描三元组表时,寻找的三元组的列值 col=k 的三元组;
k 的取值: 1 ≤ k≤ A.n。
为实现处理附设一个当前存放位置计数器 j,用于指向当前转置后元素应放入三元组表 B中的位置下标。 j 初值为 1 ,当处理完一个元素后,j 加 1 。
【算法描述】稀疏矩阵“列序”递增转置算法
- /*"列序"递增转置法*/
-
- void TransposeTSMatrix(TSMatrix A,TSMatrix *B)
- { /*把矩阵A转置到B所指向的矩阵中去。矩阵用三元组表表示*/
- int i,j,k;
- B->m=A.n;
- B->n=A.m;
- B->len=A.len;
- if(B->len>0)
- {
- j=1; /*j为辅助计数器,记录转置后的三元组在三元组表B中的下标值*/
- for(k=1; k<=A.n; k++) /*扫描三元组表A 共k次,每次寻找列值为k的三元组进行转置*/
- for(i=1; i<=A.len; i++)
- if(A.data[i].col==k)
- {
- B->data[j].row=A.data[i].col;/*从头至尾扫描三元组表A,寻找col值为k的三元组进行转置*/
- B->data[j].col=A.data[i].row;
- B->data[j].e=A.data[i].e;
- j++; /*计数器j自加,指向下一个存放转置后三元组的下标*/
- }/*内循环中if的结束*/
- }/* if(B->len>0)的结束*/
- }/* end of TransposeTSMatrix */

【算法分析】算法的时间耗费主要是在双重循环中,其时间复杂度为 O( A.n× A.len)。最坏情况为:当 A.len=A.m×A.n 时(即矩阵中全部是非零元素),时间复杂度为 O( A.m×A.n2 ),
若采用正常方式经典算法实现矩阵转置的算法时间复杂度为 O( A.m× A.n)。因此,三元组表示法仅适用于存储表示稀疏矩阵。
例 5-2 已知 A 矩阵 A.m=100 ,A.n=500 ,A.len=100 ,计算其采用三元组表存储空间和其上的“列序递增转置法”占用时间情况,并给出对比改进的思路分析。
此矩阵常规存储空间耗费为 A.m×A. n=50000,三元组表存储耗费为 A.len×3=300,节省存储。
采用矩阵转置的经典算法时间耗费为 A.m×A. n=50000 次;采用稀疏矩阵的“列序”递增转置算法,时间耗费为 A.n× A.len=50000 次,
虽然存储空间减少,但时间复杂度并未降低,原因是要多次(如 A.n=500 次)扫描稀疏矩阵三元组。
作业
对稀疏矩阵进行压缩存储的目的是( )
-
A.便于进行矩阵运算
-
B.便于输入和输出
-
C.节省存储空间
-
D.减低运算的时间复杂度
稀疏矩阵压缩存储后,不会失去( )功能
-
A.顺序存储
-
B.随机存取
-
C.输入输出
-
D.输入输出
第3讲稀疏矩阵压缩存储下——内容简介
稀疏矩阵的压缩存储
l 三元组表表示法下矩阵的转置运算:“一次定位”快速转置法
l 稀疏矩阵的十字链表表示法
第 4 讲稀疏矩阵压缩存储下
“列序”递增转置法的思考:采用稀疏矩阵存储方法,可否降低时间复杂度?(提示:通过降低对稀疏矩阵三元组的扫描次数实现)
方法二:“一次定位快速转置”法
【算法思想】在方法一中,为了使转置后矩阵的三元组表 B 仍按“行序递增”存放,必须多次扫描被转置矩阵的三元组表 A,以保证按被转置矩阵列序递增进行转置。
因此要通过双重循环来完成。改善算法的时间性能,必须去掉双重循环,使整个转置过程通过一重循环来完成,
即只对被转置矩阵的三元组表 A 扫描一次,就使 A 中所有非零元的三元组“一次定位”直接放到三元组表 B 的正确位置上。
为了能将被转置三元组表 A 中的元素一次定位到三元组表 B 的正确位置上,需要预先计算以下数据:
( 1 )待转置矩阵三元组表 A 每一列中非零元素的总个数(即转置后矩阵三元组表 B 的每一行中非零元素的总个数)。
( 2 )待转置矩阵每一列中第一个非零元素在三元组表 B 中的正确位置(即转置后矩阵每一行中第一个非零元素在三元组表 B 中的正确位置)。
为此,需要设两个数组分别为 num[]和 position[]。
num[ col]用来存放三元组表 A 第col 列中非零元素总个数(三元组表 B 第 col 行中非零元素的总个数)。
position[ col]用来存放转置前三元组表 A 中第 col 列(转置后三元组表 B 中第 col 行)中第一个非零元素在三元组表B 中的存储位置(下标值)。
num[ col]的计算方法:将三元组表 A 扫描一遍,对于其中列号为 col 的元素,给相应的 num数组中下标为 col 的元素加 1 。
说明:在 num[ col]的计算中,采用了“
数组下标计数法”。
position[ col]的计算方法:
① position[ 1 ]=1 ,表示三元组表 A 中,列值为 1 的第一个非零元素在三元组表 B 中的下标值;
② position[ col]=position[ col-1 ]+num[ col-1 ]。其中 2 ≤ col≤ A.n。
通过上述方法,可以得到 M 的 num[ col]和 position[ col]的值,如下图所示。


思考题:选票统计问题
由 10 位候选人参与选举,编号分别为 1 ,2 ,…, 10 。
现有 20 000张有效选票(选票上均标记 1 ~10 之间的数字表明所选候选人),统计各位候选人的得票数。说明方法,给出程序
【提示】一次扫描 2 万张选票,利用数组统计候选人得票数。
“一次定位快速转置”的具体做法:
position[ col]的初值为三元组表 A 中第 col 列(三元组表 B 的第 col 行)中第一个非零元素的正确位置,
当三元组表 A 中第 col 列有一个元素加入到三元组表 B 时,
则 position[ col]=position[ col]+1
即:使 position[ col]始终指向三元组表 A 中第 col 列中下一个非零元素在三元组表 B 中的正确存放位置(下标值)。
【算法描述】稀疏矩阵“一次定位快速转置”算法
- /*"按位快速转置"法*/
-
- void FastTransposeTSMatrix(TSMatrix A,TSMatrix *B)
- {
- /*基于矩阵的三元组表示,采用"按位快速转置"法,将矩阵A转置为矩阵B*/
- int col,t,p,q;
- int num[MAXSIZE], position[MAXSIZE];
- B->len=A.len;
- B->n=A.m;
- B->m=A.n;
- if(B->len)
- {
- for(col=1;col<=A.n;col++)
- num[col]=0;
- for(t=1;t<=A.len;t++)
- num[A.data[t].col]++; /*计算每一列的非零元素的个数*/
- position[1]=1;
- for(col=2;col<=A.n;col++) /*求col列中第一个非零元素在B.data[ ]中的正确位置*/
- position[col]=position[col-1]+num[col-1];
- for(p=1;p<=A.len;p++)/*将被转置矩阵的三元组表A从头至尾扫描一次,实现矩阵转置*/
- {
- col=A.data[p].col;
- q=position[col];
- B->data[q].row=A.data[p].col;
- B->data[q].col=A.data[p].row;
- B->data[q].e=A.data[p].e;
- position[col]++;/* position[col]加1,指向下一个列号为col的非零元素在三元组表B中的下标值*/
- }/*end of for*/
- }
- }
完整程序
- #include <malloc.h>
- #include <stdio.h>
- #define MAXSIZE 1000 /*非零元素的个数最多为1000*/
- #define ElementType int
- /*稀疏矩阵三元组表的类型定义*/
- typedef struct
- {
- int row, col; /*该非零元素的行下标和列下标*/
- ElementType e; /*该非零元素的值*/
- }Triple;
-
- typedef struct
- {
- Triple data[MAXSIZE + 1]; /* 非零元素的三元组表。data[0]未用*/
- int m, n, len; /*矩阵的行数、列数和非零元素的个数*/
- }TSMatrix;
-
- /*矩阵转置的经典算法*/
-
- /*"列序"递增转置法*/
-
- void TransposeTSMatrix(TSMatrix A, TSMatrix* B)
- { /*把矩阵A转置到B所指向的矩阵中去。矩阵用三元组表表示*/
- int i, j, k;
- B->m = A.n;
- B->n = A.m;
- B->len = A.len;
- if (B->len > 0)
- {
- j = 1; /*j为辅助计数器,记录转置后的三元组在三元组表B中的下标值*/
- for (k = 1; k <= A.n; k++) /*扫描三元组表A 共k次,每次寻找列值为k的三元组进行转置*/
- for (i = 1; i <= A.len; i++)
- if (A.data[i].col == k)
- {
- B->data[j].row = A.data[i].col;/*从头至尾扫描三元组表A,寻找col值为k的三元组进行转置*/
- B->data[j].col = A.data[i].row;
- B->data[j].e = A.data[i].e;
- j++; /*计数器j自加,指向下一个存放转置后三元组的下标*/
- }/*内循环中if的结束*/
- }/* if(B->len>0)的结束*/
- }/* end of TransposeTSMatrix */
-
- /*"按位快速转置"法*/
-
- void FastTransposeTSMatrix(TSMatrix A, TSMatrix* B)
- {
- /*基于矩阵的三元组表示,采用"按位快速转置"法,将矩阵A转置为矩阵B*/
- int col, t, p, q;
- int num[MAXSIZE], position[MAXSIZE];
- B->len = A.len;
- B->n = A.m;
- B->m = A.n;
- if (B->len)
- {
- for (col = 1; col <= A.n; col++)
- num[col] = 0;
- for (t = 1; t <= A.len; t++)
- num[A.data[t].col]++; /*计算每一列的非零元素的个数*/
- position[1] = 1;
- for (col = 2; col <= A.n; col++) /*求col列中第一个非零元素在B.data[ ]中的正确位置*/
- position[col] = position[col - 1] + num[col - 1];
- for (p = 1; p <= A.len; p++)/*将被转置矩阵的三元组表A从头至尾扫描一次,实现矩阵转置*/
- {
- col = A.data[p].col;
- q = position[col];
- B->data[q].row = A.data[p].col;
- B->data[q].col = A.data[p].row;
- B->data[q].e = A.data[p].e;
- position[col]++;/* position[col]加1,指向下一个列号为col的非零元素在三元组表B中的下标值*/
- }/*end of for*/
- }
- }
-
-
- void main()
- {
- int i;
- int a[8] = { 1,1,3,3,4,5,6,6 };
- int b[8] = { 2,3,1,6,3,2,1,4 };
- int c[8] = { 12,9,-3,14,24,18,15,-7 };
- TSMatrix A;
- TSMatrix* B;
- A.n = 8;
- A.m = 1;
- A.len = 8;
- B = (TSMatrix*)malloc(sizeof(TSMatrix));
- for (i = 0; i < 8; i++)
- {
- A.data[i + 1].row = a[i];
- A.data[i + 1].col = b[i];
- A.data[i + 1].e = c[i];
- }
- FastTransposeTSMatrix(A, B);
- for (i = 1; i <= 8; i++)
- {
- printf("%3d", B->data[i].row);
- }
- printf("\n");
- for (i = 1; i <= 8; i++)
- {
- printf("%3d", B->data[i].col);
- }
- printf("\n");
- for (i = 1; i <= 8; i++)
- {
- printf("%3d", B->data[i].e);
- }
- getchar();
- }
【算法分析】
“一次定位快速转置”算法的时间主要耗费在 4 个并列的单循环上,
这 4 个并列的单循环分别执行了 A.n,A.len,A.n-1,A.len 次,
因而总的时间复杂度为 O( A.n)+O( A.len)+O( A.n)+ O( A.len),
即为 O( A.n +A.len),
当待转置矩阵 M 中非零元素个数接近于 A.m ×A.n时,
其时间复杂度接近于经典算法的时间复杂度 O( A.m ×A.n)。
对例子给出的 A 矩阵 A.m=100 ,A.n=500 ,A.len=100 ,
采用 “列序“递增转置法的时间耗 费 为 A.n × A.len =50 000 次 。
而 采 用 一 次 定 位 快 速 转 置 法 的 时 间 耗 费 为A.n+A.len+A.n+A.len=1 200 次
显然,“一次定位快速转置”算法的时间效率要高得多。
在时间性能 上优于递增转置法 ,但在空间耗费上 增加了两个 辅助向量空间 ,
即 num[ 1 ..A.n],position[ 1 .. A.n](本例中为 1000),
由此可见,算法在时间上的节省是以更多的存储空间为代价的。
思考题:如何将计算 position[ col]的方法稍加改动,使算法只占用一个辅助向量空间?
2.稀疏矩阵的链式存储结构:十字链表
与用二维数组存储稀疏矩阵相比较,用三元组表表示法的稀疏矩阵不仅节约了空间,而且使得矩阵某些运算的时间效率优于经典算法。但是当需进行矩阵加法、减法和乘法等运算时,
有时矩阵中非零元素的位置和个数会发生很大的变化。如 A =A+B,将矩阵 B 加到矩阵 A 上,此时若用三元组表表示法,势必会为了保持三元组表“以行序为主序”而大量移动元素。
为了避免大量移动元素,介绍稀疏矩阵的链式存储法———十字链表,它能够灵活地插入因运算而产生的新的非零元素,删除因运算而产生的新的零元素,实现矩阵的各种运算。
( 1 )十字链表的存储表示
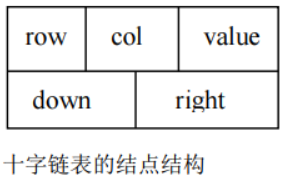
在十字链表中,矩阵的每一个非零元素用一个结点表示,该结点除了( row,col,value)以外,还要有以下两个链域:
right:用于链接同一行中的下一个非零元素
down:用于链接同一列中的下一个非零元素
在十字链表中,同一行的非零元素通过 right 域链接成一个单链表。
同一列的非零元素通过 down 域链接成一个单链表。
这样,矩阵中任一非零元素 M[ i][ j]所对应的结点既处在第 i行的行链表上,又处在第 j 列的列链表上,这好像是处在一个十字交叉路口上,所以称其为十字链表。
同时再附设一个存放所有行链表的头指针的一维数组和一个存放所有列链表的头指针的一维数组。整个十字链表的结构如图所示


( 2 )十字链表的类型定义
十字链表的结构类型定义如下:
- typedef struct OLNode
- {
- int row, col;/*非零元素的行和列下标*/
- ElementType value;
- struct OLNode* right, *down;/*非零元素所在行表、列表的后继链域*/
- }OLNode,*OLink;
-
- typedef struct
- {
- OLink* row_head,* col_head;/*行、列链表的头指针向量*/
- int m,n,len;/*稀疏矩阵的行数、列数、非零元素的个数*/
- }CrossList;
作业
对于一个m行n列的稀疏矩阵中有len个非零元素,则用十字链表存储时,需要(m+n )个头指针。
对于一个m行n列的稀疏矩阵中有len个非零元素,则用十字链表存储时,需要(len )个三元组结点。
第5讲 广义表及本章小结
本节主要内容:
- 广义表的概念
- 广义表的存储
- 头尾链表法
- 同层结点链法
本章小结
- 主要知识点
- 典型题例
第 5 讲 广义表及本章小结
广义表,也是线性表的一种推广。它被广泛的应用于人工智能等领域的表处理语言 LISP 语言中。
在 LISP 语言中,广义表是一种最基本的数据结构,LISP 语言编写的程序也表示为一系列的广义表。
一、 广义表的概念
在第 2 章中,线性表被定义为一个有限的序列( a1 ,a2 ,a3 ,…, an),其中 ai 被限定为是单个数据元素。
广义表也是 n 个数据元素( d1 ,d2 ,d3 ,…, dn)的有限序列,
但不同的是,广义表中的 di 既可以是单个元素,还可以是一个广义表,通常记做: GL=( d1 ,d2 ,d3 ,…, dn)。
GL 是广义表的名字,通常广义表的名字用大写字母表示。 n是广义表长度。
若其中 di 是一个广义表,则称 di 是广义表 GL 的子表。
在广义表GL 中,d1 是广义表表头,而广义表 GL 其余部分组成的表( d2 ,d3 ,…, dn)称为广义表表尾。
由此可见广义表的定义是递归定义的,因为在定义广义表时又使用了广义表的概念。
下面给出一些广义表的例子,以加深对广义表概念的理解。
D=() 空表;其长度为零。
A=(a,(b,c)) 表长度为 2 的广义表,其中第一个元素是单个数据 a,第二个元素是一个子表(b,c)。
B=(A,A,D) 长度为 3 的广义表,其前两个元素为表 A,第三个元素为空表 D。
C=(a,C) 长度为 2 递归定义的广义表,C 相当于无穷表 C=(a,(a,(a,(…))))。
其中,A、B、C、D 是广义表的名字。
下面以广义表 A 为例,说明求表头、表尾的操作。
head( A)= a;表 A 的表头是: a
tail( A)=(( b,c));表 A 的表尾是(( b,c))。广义表的表尾一定是一个表。
从上面的例子可以看出:
( 1 )广义表的元素可以是子表,而子表还可以是子表……,因此,广义表是一个多层的结构。
( 2 )广义表可以被其他广义表共享。如广义表 B 就共享表 A。在表 B 中不必列出表 A 的内容,只要通过子表的名称就可以引用该表。
( 3 )广义表具有递归性,如广义表 C。
二、 广义表的存储结构
由于广义表 GL=( d1 ,d2 ,d3 ,…, dn)中的数据元素既可以是单个元素,也可以是子表,因此对于广义表来说,难以用顺序存储结构来表示它,通常用链式存储结构来表示。
1 .广义表的头尾链表存储结构
广义表中的每个元素用一个结点来表示,表中有两类结点:一类是单个元素结点,另一类是子表结点。
任何一个非空的广义表都可以将其分解成表头和表尾两部分,反之,一对确定的表头和表尾可以惟一地确定一个广义表。
因此,一个表结点可由三个域构成:标志域、指向表头的指针域和指向表尾的指针域,而元素结点只需要两个域:标志域和值域,其结点结构如下图所示

广义表的头尾链表存储结构类型定义如下:
- typedef enum { ATOM, LIST } ElemTag; /* ATOM=0,表示原子;LIST=1,表示子表*/
- typedef struct GLNode
- {
- ElemTag tag; /*标志位 tag 用来区别原子结点和表结点*/
- union
- {
- AtomType atom; /*原子结点的值域 atom*/
- struct { struct GLNode* hp, * tp; } htp; /*表结点的指针域 htp, 包括
- 表头指针域 hp 和表尾指针
- 域 tp*/
- } atom_htp; /* atom_htp 是原子结点的值域 atom 和
- 表结点的指针域 htp 的联合体域*/
- } GLNode,* GList;
前面提到的广义表 A、B、C、D 的存储结构如下图所示:

在这种存储结构中,能够很清楚地分清单元素和子表所在的层次,在某种程度上给广义表的操作带来了方便
2 .广义表的同层结点链存储结构
在这种结构中,无论是单元素结点还是子表结点均由三个域构成。其结点结构如下图所示

广义表的同层结点链存储结构类型定义如下:
- typedef enum { ATOM, LIST } ElemTag; /* ATOM=0,表示原子;LIST=1,表示子表*/
- typedef struct GLNode
- {
- ElemTag tag;
- union
- {
- AtomType atom;
- struct GLNode* hp; /*表头指针域*/
- } atom_hp; /* atom_hp 是原子结点的值域 atom 和表结点的表头指针域 hp 的联合体域*/
- struct GLNode* tp; /*同层下一个结点的指针域*/
- } GLNode,* GList;
三、本章小结
主要知识点
( 1 )数组的基本知识点
① n 维数组可以看成是这样一个线性表,其中每个数据元素均是一个 n -1 维数组。
②数组是一组有固定个数的元素的集合。给出数组的维数和每一维的上下限,数组中的元素个数就固定。
③数组采用顺序存储结构,其主要操作是随机存取,即数据元素的定位,给定元素的下标,得到该元素在计算机中的存放位置。
( 2 )特殊矩阵的压缩存储
特殊矩阵的特殊性表现在:
①元素分布有规律(对称、带状)的矩阵,只需找到对应规律的数学函数,将二维矩阵 A 中元素 ai j 的下标作为转换函数 f 的自变量,
计算出到一维内存空间的地址值 K,即![]() 实现了原二维矩阵到压缩存储后的一维数组的存储映射。
实现了原二维矩阵到压缩存储后的一维数组的存储映射。
②非零元素很少的稀疏矩阵,只存非零元素所在的行号、列号、元素值来实现压缩存储。
压缩存储既可采用三元组表顺序存储结构,也可采用十字链表的链式存储结构。
( 3 )广义表
①广义表是 n 个数据元素( d1 ,d2 ,d3 ,…, dn)的有限序列,其中 di 既可以是单个元素,也可以是一个广义表。广义表的定义具有递归性,其常用操作通常采用递归实现。
②一个非空的广义表 GL 可以看成是由表头和表尾构成。表中的第一个元素称为 GL 的表头,而表中除表头以外的其余元素构成的表称为 GL 的表尾。
③广义表常用的存储方式有:头尾链表存储结构和同层结点链存储结构。
作业
任意一个广义表都可以表示为由表头和表尾构成( )。
-
A.✓
-
B.×
非空的广义表的表尾可能是单个元素也可能是表元素( )。
-
A.✓
-
B.×
已知广义表L=(( x,y,z), a,( u,t,w)),则head( head( tail( tail( L))))的结果是( u )。
已知数组M[ 1 ..10 ,-1 ..6 ,0 ..3 ], )若数组以行序为主序存储,起始地址为1 000 ,且每个数据元素占用3个存储单元,则M[ 2 ,4 ,2 ]的地址为( 1162 )
第五章 单元测验
1单选(5分)
对稀疏矩阵进行压缩存储目的是( )。
-
A.节省存储空间
-
B.降低运算的时间复杂度
-
C.便于输入和输出
-
D.便于进行矩阵运算
2单选(5分)
广义表A=(a,b,(c,d),(e,(f,g))),则Tail(Head(Tail(Tail(A))))的值为( )。
-
A.d
-
B.((f,g))
-
C.(d)
-
D.(e,(f,g))
3单选(5分)
三维数组a[1..4][1..5][1..6],每个元素的长度是2,则a[2][3][4]的地址是( )。
-
A.110
-
B.45
-
C.106
-
D.90

4单选(5分)
三维数组a[-1…3,0…4,1…5]中元素个数有( )个。
-
A.125
-
B.60
-
C.100
-
D.80

5单选(5分)
某n*n的矩阵A中,对角线以上的元素全为0。因此我们将对角线以下的元素 按行 存储在一个一维数组B中(下标均从1开始)。那么A[i][j]在一维数组B中的下标为( )。
-
A.i*(i-1)/2 + j
-
B.i*(i+1)/2 + j
-
C.i*(i+1)/2 + j - 1
-
D.i*(i-1)/2 + j - 1

6单选(5分)
某n*n的矩阵A中,对角线以下的元素全为0。因此我们将对角线以上的元素 按列 存储在一个一维数组B中(下标均从1开始)。那么A[i][j]在一维数组B中的下标为( )。
-
A.j*(j-1)/2 +i
-
B.j*(j-1)/2 +i - 1
-
C.i*(i-1)/2 + j - 1
-
D.i*(i-1)/2 + j

7判断(5分)
一个m*n的稀疏矩阵A采用三元组形式表示,则该稀疏矩阵的转置就是把三元组中的行与列下标互换即可。
-
A.✓
-
B.×
8判断(5分)
广义表的取表尾运算,其结果一定是个表。
-
A.✓
-
B.×
9判断(5分)
广义表的取表头运算是取表中第一个元素,因此其结果一定是单个元素。
-
A.✓
-
B.×
10判断(5分)
广义表的取表头操作是返回表中第一个元素,取表尾是返回广义表中最后一个元素。
-
A.✓
-
B.×
11判断(5分)
某n*n的三对角带状矩阵中,第1行和第n行有2个非零元素,其余每行均有3个非零元素。
-
A.✓
-
B.×


