
- 1深度学习 - 张量的广播机制和复杂运算
- 2各个版本的tensorflow和python, cuda,cudnn对应的版本_tensorflow历史版本
- 3git分支打tag_gitlab 给分支设置 tag操作
- 4base64 前端显示 data:image/jpg;base64_base64 jpg
- 5AI大模型应用开发实践:3.使用 tiktoken 计算 token 数量_tiktoken 统计token
- 6CNN中的卷积的作用及原理通俗理解_添加卷积cnn的作用是什么?
- 7使用git将本地代码上传到gitee远程仓库_git上传本地代码到指定的仓库
- 8Python の TypeError 及解决方案(一)_typeerror: argument of type 'int' is not iterable
- 9【软件安装】结合树莓派4B(4G)和Ubuntu20.04的GitLab服务器搭建和使用_烧录ubuntu20系统树莓派需要更新的软件
- 10OpenCV 教程_machine learning classes
ICRA 2023 | CurveFormer:基于Transformer的3D车道线检测新网络
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:erkang | (源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/601458793
过年休息,有时间做一下 3d 车道线检测工作的小记,讲讲我们为什么做这个工作。

CurveFormer: 3D Lane Detection by Curve Propagation with Curve Queries and Attention, ICRA 2023
https://arxiv.org/abs/2209.07989
这篇文章的主要工作可以概括为以下3点:
C1: BEV/3D 车道线检测;
C2: 车道线参数曲线输出;
C3: 最重要的:不显式构建bev,而是从图像feature直接求解3d车道线;
1: BEV视角的车道线参数曲线
首先关于C1&C2,在自动驾驶/辅助驾驶产品中,车道线检测的下游模块是planning,往往需要本车坐标系下的车道线参数曲线,一般情况下,本车坐标系原点为车辆的后轮中心,车道线被formulate为多项式曲线,为下游服务。例如,在mobileye的EyeQ系列产品里面,车道线一般表示为2维(BEV视角)的4次多项式曲线;另外Tesla从2019年起,在auto-pilot产品中,定义的车道线为3d车道线。因此,车道线检测的输出为BEV视角下的2d或者3d的车道线参数曲线,为下游模块服务。
但是,除此之外,在计算机视觉中,深度学习大规模应用以来,开源出来的数据集和工作大多以图像平面(UV-space)上的车道线检测为主,典型的数据集包括,tusimple的车道线数据集[1], 港中文开源的车道线数据集CULane Dataset [2]。
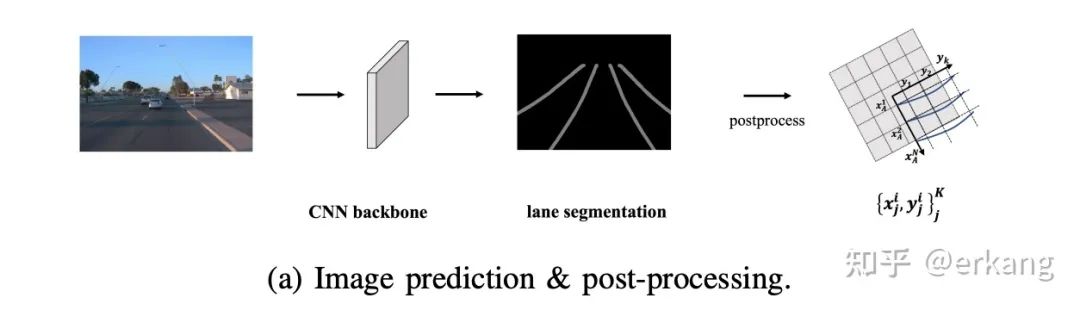
如图1所示,在图像(UV-space)上做车道线检测的缺陷是,得到的车道线是在图像空间,需要后处理才能转换到BEV空间。往往在工程实践中,这个UV-space to BEV-space的转换需要大量的后处理代码,另外,把图像上的中间结果,例如分割等,转换到BEV-space之后,往往也需要复杂的后处理才能得到下游所需的参数曲线。总结:在图像UV-space计算的车道线,一般需要大量复杂的后处理,才能转换到BEV视角下的参数曲线。
在learning为主的算法设计角度,需要把上面描述的后处理转化为learning的模块,这也符合原Tesla AI 总监Andrej Karpathy倡导的software 2.0机制 [4]。通过问题的重新定义,让learning的方法在整个工程模块中的比重越来越大。
那么对于车道线检测来说,重新定义问题就比较直接:输入图像(单目或者多目,或者再加上激光),输出BEV视角下的车道线参数曲线;
注1: BEV视角一般在此为摄像头坐标系,摄像头坐标系和车辆后轮中心的坐标系,两个坐标系的转换(平移和旋转)一般在车辆下线时标定;
注2: 车道线可以描述为2D或者3D,一般由下游的需求决定;
3D 车道线检测
随着新的、更面向自动驾驶/辅助驾驶任务的数据集的出现,3D车道线检测变成新的研究方向和热点。例如百度开源的Apollo 3D Lane Synthetic Dataset [5],商汤等基于Waymo dataset发布的OpenLane Dataset [6], 华为诺亚实验室开源的ONCE-3DLanes [3,7] 的出现,吸引了不少研究者跟进这一实际工作。我们的curveformer工作也是直接输出bev视角3d车道线的参数曲线,而不是聚焦在图像空间做输出。
那么图像空间的车道线检测or理解是否还有意义?有两个角度可以思考:
1: 从获得GT得角度,如果图像空间的车道线标注比较便捷或者廉价,那么图像空间的标注信息同样值得关注;
例如在ONCE-3DLanes [3,7] 中,使用几乎零成本的图像空间车道线预标注,去实现3d车道线GT提取。
2: 在图像空间车道线的标注信息,如何帮助更好的完成bev视角的车道线检测or更广义的local map,也是一个很好的出发点。
例如我们在curveformer中使用的图像空间车道线分割作为额外监督信号,还有[8]中提出的,在loss端加入图像空间车道线和BEV视角车道线的几何约束。类似的设计,这里统称为deep-supervision;
下面转入curveformer最想探索的话题,能不能不去显示构建BEV,而直接从图像特征空间求解BEV视角的3d车道线参数曲线。
2: 为什么不显式构建bev?(简单回答:一切为了加速)
为了回答这个问题,我们首先简单回顾下最近非常热的BEV + Transformer。从研究角度,BEV视角的研究首先从机器人角度开始,例如Zhou Bolei老师从室内移动机器人角度,研究multi-view (or corss-view)如何直接得到BEV视角的语义信息[9],随着Tesla的AI day的推广而变得炙手可热,也成为各家自动驾驶相关公司的工程落地重点。
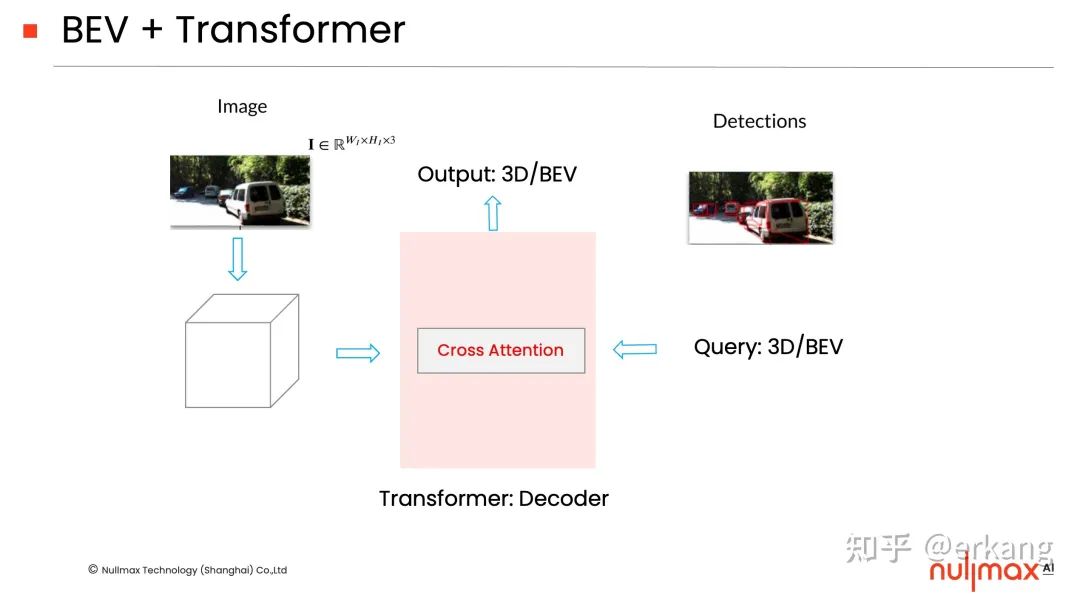
如图2所示,简单总结,BEV + Transformer的架构设计,通过利用
(1)cross attention机制
(2)Nx decoder机制
完成输入(图像空间)和输出(BEV视角的感知结果)的mapping。后面会简介在curveformer中如何利用这两个机制完成BEV视角下的3d车道线检测。
注:图2-5取自之前分享过 BEV + Transformer的总结。
Cross attention一般把图像特征当作K/V,计算query(如目标检测中的一个目标)和KV之间的attention,利用多次decoder解析query对应的输出。这里面一个query需要和dense的KV里面的所有元素计算attention,计算量很大。为了节约计算量,deformable detr[11]提出可以通过query先预测一个reference point,然后仅计算和这个reference point相关的几个位置,大大减少计算量。这个attention简记为deformable attention。至此deformable detr还是在图像空间做的目标检测。
Deformable detr带来2个核心观点:
1: query在cross attention中的reference point的设计,可以粗略关联到目标框;
2: 通过N个decoder逐渐细化目标,这里记作iterative refinement;
这两点也是上面总结 BEV + Transformer技术架构的核心机制。
Deformable detr中的1,实现的是图像空间中的query和图像中的目标之间的关联,那么,能否实现BEV空间中的query和图像中的信息之间的关联呢?这也是我们做BEVSegFormer[12]的出发点:利用deformable attention机制中的cross attention,完成BEV空间的query和图像feature之间的关联。这种设计带来的好处:
1: 相比后面提出的BEVFormer[13], BEVSegFormer不依赖相机参数(内参和外参),可以完成BEV空间和图像空间的转化;
2: query和图像特征之间的attention计算量小;
注:BEVSegFormer不依赖相机参数(内参和外参),可以完成BEV空间和图像空间的转化,后续被扩展至目标检测、时序等多个工作。
但是这里面BEVSegFormer,还是后面出来的BEVFormer,都需要显式构建这个dense的BEV空间(例如BEV grid的大小为100x100),然后在此基础上完成具体感知任务的输出。Tesla AI Day介绍的雏形也是类似的设计,也就是two-stage的设计,首先构建BEV feature map,然后计算相应的感知结果。我们知道在现实的三维空间,大量感知是sparse形式的,比如障碍物检测,视野范围内可能就几个目标;车道线也类似,视野范围内就几根车道线;这些数目远小于BEV的grid的个数(ex:5条车道线 < 100x100 BEV grid)。其实对于local map也是,local map的组成也是sparse的元素。
关于dense和sparse的输出总结,参考之前的总结:
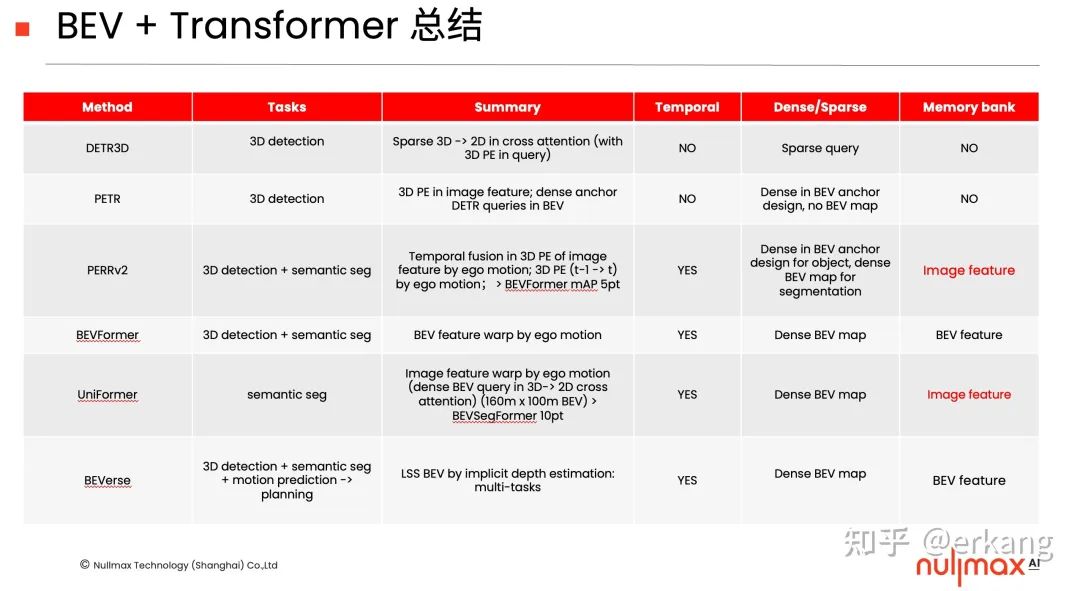
那么有没有方法可以不显式构建BEV,one-stage的直接计算感知结果呢?DETR3D[10]带给了我们一些思路:
DETR3D首先引入类似deformable detr中reference point的概念,3D空间的一个障碍物query 产生一个reference point,然后利用相机参数投影到图像空间,完成cross attention的计算。那么这里面cross attention的计算是一个代表3D空间的query和图像空间中的一个点计算,计算复杂度远小于和KV中所有点计算attention (1 << HxW)。在障碍物检测中,不通过显式构建BEV,直接输出BEV视角下的sparse的3D障碍物,算是curveformer最初形态的一个motivation。
车道线检测其实和障碍物检测类似,都是在BEV视角下的感知输出,而且输出也是sparse的,能否把类似的机制借鉴到车道线检测里面来呢?应该怎么formulate这个过程呢?一个最简单粗暴的做法是,由BEV视角下的一个车道线query生成N个3D reference points,然后通过然后利用相机参数投影到图像空间,完成cross attention的计算。这种做法和其它transformer的方法类似,把query当作黑盒子,无法准确理解query和输出之间的关系,或者无法根据输出的特性,完成query的设计,同时也会加大模型的训练时间。
DAB-DETR [14]给出了对query的解析,针对目标检测任务,把query描述成(x,y,w,h),然后针对性的设计cross attention,可以完成对目标的位置(x,y)以及大小(w,h)的可解释性学习,加速transformer-based目标检测的训练,更重要的是,给出了query在transformer中的含义。
注:这种物理含义的query设计其实在Deformable detr中也有体现。
这一做法可以天然的借鉴到3d车道线检测而来,我们只需要把3d车道线query描述成点集即可。也就是在三维空间,车道线由N个ordered的3D点组成,称之为curve query。然后在cross-attention中根据N个3D点,设计curve attention,即可完成车道线的解析。
idea也简单,为了加速计算,根据3d车道线的特性设计了curve query (N个有序三维点),在cross-attention中使用curve attention,完成图像空间和BEV/3D空间的转化,同时也不需要构建dense的BEV,one-stage直接计算车道线的参数方程。
关于BEV+Transformer架构的第二个特性:Nx decoder机制;如果采取了具备物理含义的query设计,那么就可以利用这个N个decoder完成iterative的refinement。对于车道线检测一样适用,可以在多个decoder中逐渐逼近真值。相比CNN的decoder,transformer中通过query的设计,更能发挥decoder对输出的解析。
总结:BEV + Transformer技术架构,可以利用机制(1)cross attention 完成图像空间和BEV空间的转化(显式or非显式);更能利用机制(2)Nx decoder带来的iterative refinement得到更准确的感知结果。
那么是不是CNN的方式完成不了上面2个工作(1: 图像空间和BEV输出的转换;2: iterative refinement机制)?不是的,下面举2个例子。
1: 基于CNN的 图像空间和BEV空间的转化;
1.1 利用相机参数的BEV-CNN架构
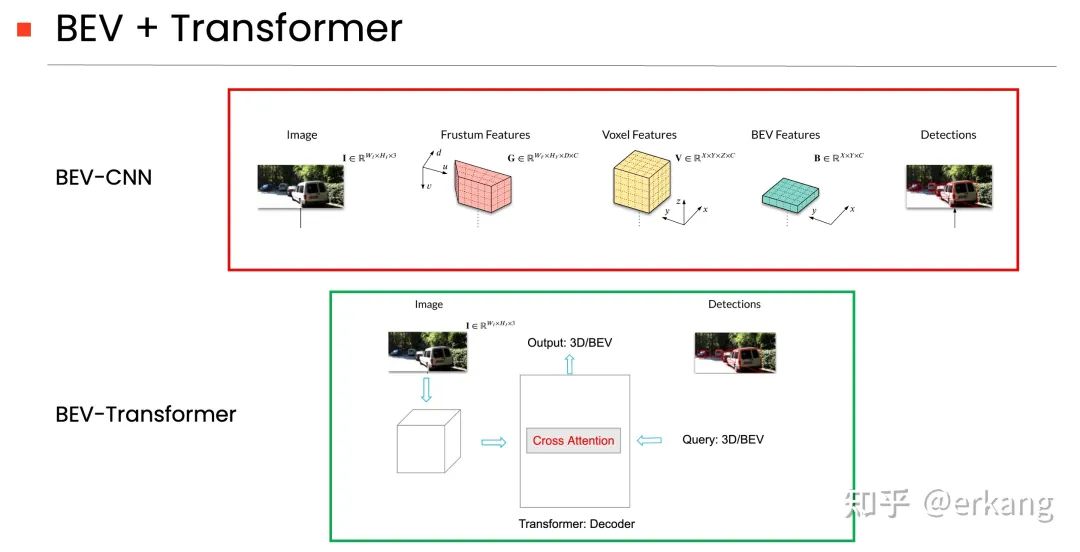
图4的上图,就是CNN-based的利用相机参数完成图像空间和BEV空间的转换,代表性工作为OFT[15]。
1.2 不利用相机参数的BEV-CNN架构
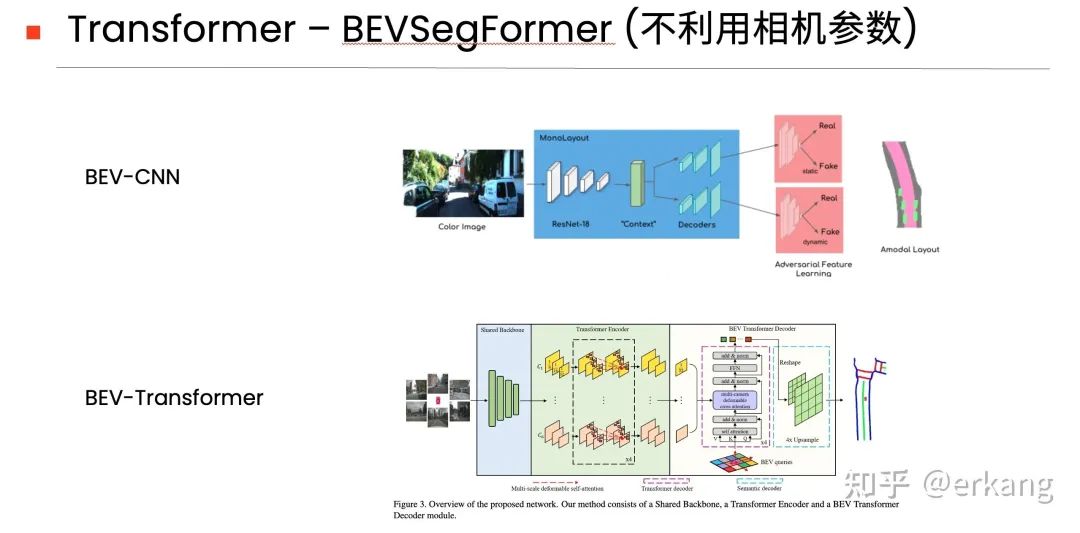
如图5的上图所示,CNN-based的不利用相机参数的方法,代表性工作为MonoLayout[16].
2: iterative refinement机制:
那么除了Transformer中的设计,CNN中是否有类似的设计,比如可以用到车道线检测中?
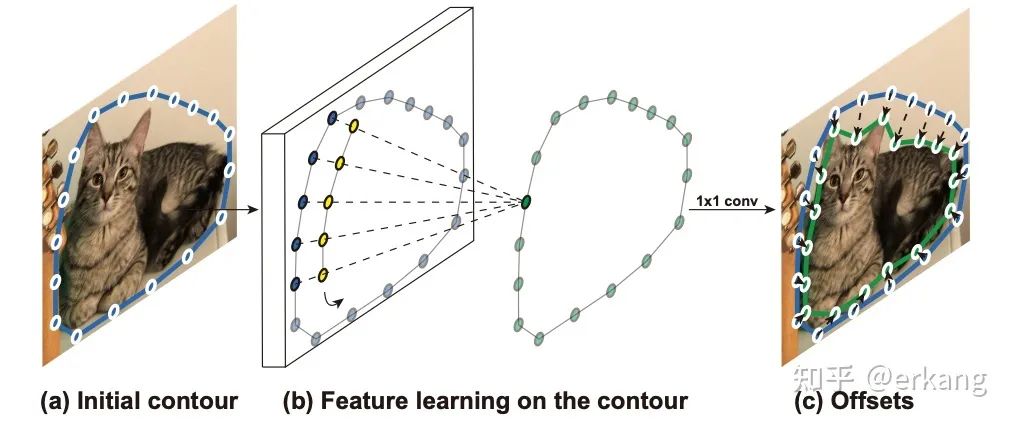
如图6所示,DeepSnake[17] 通过把instance segmentation描述为轮廓,且轮廓的定义为点集,通过Graph CNN的方式完成轮廓点的逐渐逼近真值(即iterative refinement)。点集?是不是很熟悉,把车道线定义为点集的检测,也可以利用类似的机制完成车道线检测的iterative refinement。
最后车道线的参数化输出:
在CNN中也有直接输出车道线参数曲线的工作。例如在[18], 图像中的车道线检测被描述为多项式曲线,CNN用来估计多项式参数的系数。Transformer的目标检测方法DETR出来之后,立即被扩展到了图像空间的车道线检测上面LSTR[19],以及后续的3d车道线检测[8],都是直接输出参数曲线。
最后的最后,从software2.0的角度,可不可以丢掉车道线检测?如果下游的planning为learning为主,那么local map的输出更为直接,这也就是局部地图是最近新的热点,各家自动驾驶公司都在争抢的,不依赖HDMAP的局部地图感知,提供更高阶的自动驾驶/辅助驾驶产品形态。
[1] github.com/TuSimple/tusimple-benchmark
[2] https://xingangpan.github.io/projects/CULane.html
[3] https://once-3dlanes.github.io/
[4] https://www.youtube.com/watch?v=y57wwucbXR8
[5] Y. Guo, et al. “Gen-lanenet: A generalized and scalable approach for 3d lane detection”, ECCV 2020
[6] L. Chen, et al. “Persformer: 3d lane detection via perspective transformer and the openlane benchmark”, ECCV 2022
[7] Y. Fan, et al. "Once-3dlanes: Building monocular 3d lane detection”, CVPR 2022
[8] R. Liu, et al. “Learning to Predict 3D Lane Shape and Camera Pose from a Single Image via Geometry Constraints”, AAAI 2022
[9] B. Pan, et al. “Cross-view Semantic Segmentation for Sensing Surroundings”, RAL 2020
[10] W. Yue, et al. "Detr3d: 3d object detection from multi-view images via 3d-to-2d queries”, PMLR, 2022
[11] X. Zhu, et al. “Deformable DETR: Deformable Transformers for End-to-End Object Detection”, ICLR 2021
[12] P. Lang, et al. “BEVSegFormer: Bird’s Eye View Semantic Segmentation From Arbitrary Camera Rigs”, WACV 2023
[13] Z. Li, et al. “BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers”, ECCV 2022
[14] S. Liu, et al. “DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR”, ICLR 2022
[15] Thomas Roddick et al. “Orthographic Feature Transform for Monocular 3D Object Detection”, BMVC 2019
[16] K. Mani, et al. “MonoLayout: Amodal Scene Layout from a single image”, WACV 2020
[17] S. Peng, et al. “Deep Snake for Real-Time Instance Segmentation”, CVPR 2020
[18] W. Gansbeke, et al. “End-to-end Lane Detection through Differentiable Least-Squares Fitting”, ICCVW 2019
[19] R. Liu, et al. “End-to-end Lane Shape Prediction with Transformers”, WACV 2021
CVPR/ECCV 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:ECCV2022,即可下载ECCV 2022论文和代码开源的论文合集后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
- 车道线检测交流群成立
- 扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-车道线检测 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如车道线检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
-
- ▲扫码或加微信号: CVer222,进交流群
- CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
-
- ▲扫码进群
- ▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
