
- 1正则表达式收集
- 2【Wi-Fi】802.11/802.11b/802.11g/802.11n/802.11a/802.11ac/802.11ax/802.11be_wifi速率对照表
- 3Effective Modern C++读书笔记_effective modern c++笔记
- 4后端返回url实现预览和下载文件(目前只支持图片和pdf文档)_excel 下载url变预览
- 5Go主流框架对比_go日志框架对比
- 6Java8的主要新特性_java8 新特性总结
- 7C语言:对称二叉树_对称二叉树c语言
- 8实体类监听器EntityListeners
- 9SQL使用大全
- 10Dockerfile优化技巧_前端项目优化dockerfile 构建速度
Elasticsearch深度分页问题
赞
踩
目录
什么是深度分页
分页问题是Elasticsearch中最常见的查询场景之一,正常情况下分页代码如实下面这样的:
- # 查询第一页5条数据
- GET /user/_search
- {
- "query": {
- "match_all": {}
- },
- "from": 0,
- "size": 5
- }
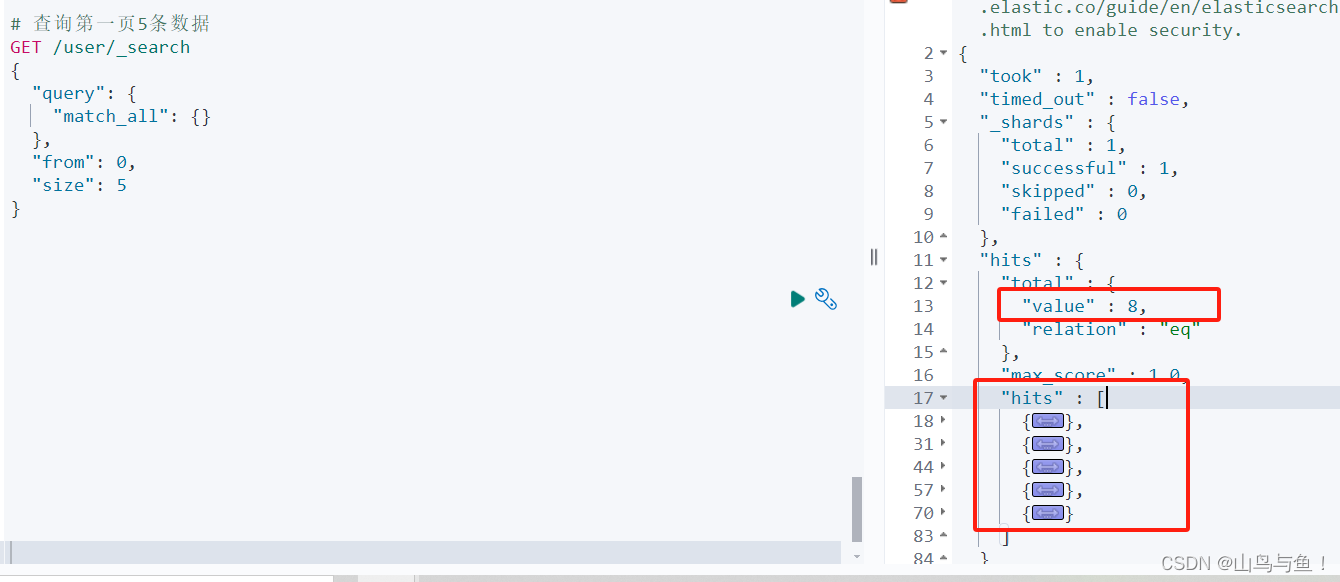
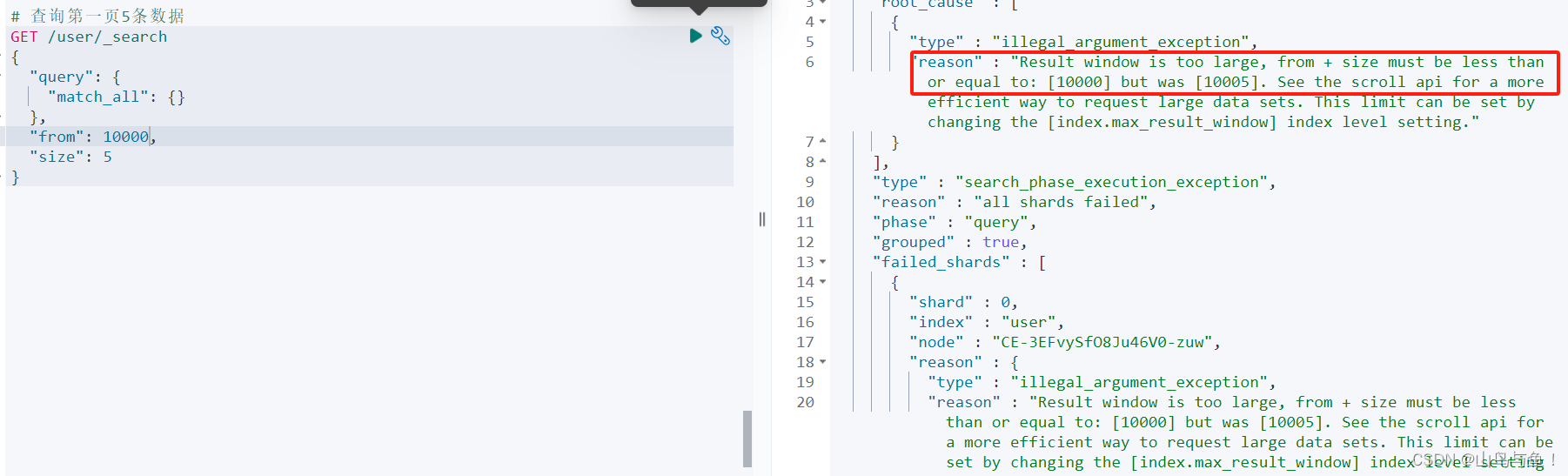
但是如果我们查询的数据页数特别大,当from + size大于10000的时候,就会出现问题,如下图报错信息所示:
ES通过参数index.max_result_window用来限制单次查询满足查询条件的结果窗口的大小,其默认值为10000。
深度分页会带来什么问题
ES分页查询流程大致如下:
1. 数据存储在各个分片中,协调节点将查询请求转发给各个节点,当各个节点执行搜索后,将排序后的前N条数据返回给协调节点。
2. 协调节点汇总各个分片返回的数据,再次排序,最终返回前N条数据给客户端。
3. 这个流程会导致一个深度分页的问题,也就是翻页越多,性能越差,甚至导致ES出现OOM。
在分布式系统中,对结果排序的成本随分页的深度成指数上升。
从10万名高考生中查询成绩为的10001-10100位的100名考生的信息。

可以看出,每次有序的查询都会在每个分片中执行单独的查询,然后进行数据的二次排序,而这个二次排序的过程是发生在heap中的,也就是说当你单次查询的数量越大,那么堆内存中汇总的数据也就越多,对内存的压力也就越大。这里的单次查询的数据量取决于你查询的是第几条数据而不是查询了几条数据,比如你希望查询的是第10001-10100这一百条数据,但是ES必须将前10100全部取出进行二次查询。因此,如果查询的数据排序越靠后,就越容易导致OOM(Out Of Memory)情况的发生,频繁的深分页查询会导致频繁的FGC。
ES为了避免用户在不了解其内部原理的情况下而做出错误的操作,设置了一个阈值,即max_result_window,其默认值为10000,其作用是为了保护堆内存不被错误操作导致溢出。
深度分页问题的常见解决方案
尝试避免使用深度分页
解决深度分页问题最好的办法就是避免使用深度分页。谷歌、百度目前作为全球和国内做大的搜索引擎不约而同的在分页条中删除了“跳页”功能,其目的就是为了避免用户使用深度分页检索。
淘宝虽然没有删除“跳页”功能,但不管我们搜索什么内容,只要商品结果足够多,返回的商品列表都是仅展示前100页的数据,其本质和ES中的max_result_window作用是一样的,都是限制你去搜索更深页数的数据。手机端APP就更不用说了,直接是下拉加载更多,连分页条都没有,相当于你只能点击“下一页”。
滚动查询:Scroll Search
scroll滚动搜索是先搜索一批数据,然后下次再搜索下一批数据,以此类推,直到搜索出全部的数据来。
scroll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该视图快照搜索数据,如果在搜索期间数据发生了变更,用户是看不到变更的数据的。因此,滚动查询不适合实时性要求高的搜索场景。
官方已不推荐使用滚动查询进行深度分页查询,因为无法保存索引状态。
适合场景
单个滚动搜索请求中检索大量结果,即非“C端业务”场景
使用
第一次进行scroll查询:
- #查询命令中新增scroll=1m,说明采用游标查询,保持游标查询窗口1分钟,也就是本次快照的结果缓存起来的有效时间是1分钟。
- GET /user/_search?scroll=1m
- {
- "query": { "match_all": {}},
- "size": 2
- }
查询结果:除了返回前2条记录,还返回了一个游标ID值_scroll_id。

从第二次查询开始,每次查询都要指定_scroll_id参数:

多次根据scroll_id游标查询,直到没有数据返回则结束查询。采用游标查询索引全量数据,更安全高效,限制了单次对内存的消耗。
删除游标scroll
scroll超过超时后,搜索上下文会自动删除。然而,保持scroll打开是有代价的,因此一旦不再使用,就应明确清除scroll上下文。
- DELETE /_search/scroll
- {
- "scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFk9COHR0V19kU3plamJEWWhEbTF3V0EAAAAAAACvYRZDRS0zRUZ2eVNmTzhKdTQ2VjAtenV3"
- }
注意事项
1. scroll滚动查询不适合实时性要求高的查询场景,比较适合数据迁移的场景。
2. scroll查询完毕后,要手动清理掉 scroll_id。虽然ES有自动清理机制,但是 srcoll_id 的存在会耗费大量的资源来保存一份当前查询结果集映像,并且会占用文件描述符。
官方建议:ES7之后,不再建议使用scroll API进行深度分页。如果要分页检索超过 Top 10,000+ 结果时,推荐使用:PIT + search_after。
search_after
scroll API适用于高效的深度滚动,但滚动上下文成本高昂,不建议将其用于实时用户请求。而search_after参数通过提供一个活动光标来规避这个问题。这样可以使用上一页的结果来帮助检索下一页。
search_after 分页查询可以简单概括为如下几个步骤:
1. 获取索引的pit
使用 search_after 需要具有相同查询和排序值的多个搜索请求。如果在这些请求之间发生刷新,结果的顺序可能会发生变化,从而导致跨页面的结果不一致。为防止出现这种情况,可以创建一个时间点 (PIT) 以保留搜索中的当前索引状态。Point In Time(PIT)是 Elasticsearch 7.10 版本之后才有的新特性。
- # 创建一个时间点(PIT)来保存搜索期间的当前索引状态
- POST /user/_pit?keep_alive=1m
- #返回结果,会返回一个PID的值
- {
- "id" : "39K1AwEEdXNlchY5anUxTHFxelJJLURrR0xMb2RtTFBnABZDRS0zRUZ2eVNmTzhKdTQ2VjAtenV3AAAAAAAAALGMFk9COHR0V19kU3plamJEWWhEbTF3V0EAARY5anUxTHFxelJJLURrR0xMb2RtTFBnAAA"
- }
2. 根据pit首次查询
根据pit查询的时候,不用指定索引的名词。
- GET /_search
- {
- "query": {
- "match_all": {}
- },
- "pit": {
- "id": "39K1AwEEdXNlchY5anUxTHFxelJJLURrR0xMb2RtTFBnABZDRS0zRUZ2eVNmTzhKdTQ2VjAtenV3AAAAAAAAALGMFk9COHR0V19kU3plamJEWWhEbTF3V0EAARY5anUxTHFxelJJLURrR0xMb2RtTFBnAAA",
- "keep_alive": "1m"
- },
- "size": 2,
- "sort": [
- {"_id": "asc"}
- ]
- }
返回结果:

根据search_after和pit进行翻页查询
要获得下一页结果,请使用最后一次命中的排序值(包括 tiebreaker)作为 search_after 参数重新运行先前的搜索。如果使用 PIT,请在 pit.id 参数中使用最新的 PIT ID。搜索的查询和排序参数必须保持不变。
- #search_after指定为上一次查询返回的sort值。
- GET /_search
- {
- "query": {
- "match_all": {}
- },
- "pit": {
- "id": "39K1AwEEdXNlchY5anUxTHFxelJJLURrR0xMb2RtTFBnABZDRS0zRUZ2eVNmTzhKdTQ2VjAtenV3AAAAAAAAALGMFk9COHR0V19kU3plamJEWWhEbTF3V0EAARY5anUxTHFxelJJLURrR0xMb2RtTFBnAAA",
- "keep_alive": "1m"
- },
- "size": 2,
- "sort": [
- {"_id": "asc"}
- ],
- "search_after": [
- 3
- ]
- }

总结
| 分页方式 | 性能 | 优点 | 缺点 | 适用场景 |
| from + size | 低 | 灵活性好,实现简单,支持随机翻页 | 受制于max_result_window设置,不能无限制翻页; 存在深度翻译问题,越往后翻译越慢。 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | scroll查询的相应数据是非实时的,如果遍历过程中插入新的数据,是查询不到的; 保留上下文需要足够的堆内存空间。 | 海量数据的导出,需要查询海量结果集的数据 |
| search_after | 高 | 性能最好,不存在深度分页问题,能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果,它不适用于大幅度跳页查询 | 海量数据的分页 |

