
- 1建设卓越班组的几个建议
- 2YOLOX-部署与测试_usage: yolox demo! [-h] [-expn experiment_name] [-
- 3Leetcode刷题笔记:二分查找算法_二分查找 leetcode
- 4Flutter WebView 性能优化,让 h5 像原生页面一样优秀_flutter webview缓存
- 5Oracle 查询两表中不同的记录_oraclc表a查到500条数据,表b查询到500表数据,两表不同的数据有那些
- 6使用AsyncTask实现图片加载进度监听_监听async await 接口进度
- 7Hudi 在 vivo 湖仓一体的落地实践
- 8HTTP协议报文的结构的补充和from表单以及ajax表单
- 9幂等校验是什么意思_什么是接口的幂等性,如何实现接口幂等性?一文搞定
- 10001-小于n的所有素数输出
Flink on Yarn安装配置_flink on yarn 安装配置
赞
踩
前言
Apache Flink,作为一个开源的分布式处理引擎,近年来在大数据处理领域崭露头角,其独特的流处理和批处理一体化模型,使得它能够在处理无界和有界数据流时展现出卓越的性能。本文旨在对Flink进行简要的前言性介绍,以及他的安装配置
初了解Flink
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,用于对无界和有界数据流进行有状态计算。Flink是一个流数据与批数据一体化处理的模型,既可以处理有界数据流(批处理),也可以处理无界数据流(实时流处理)。它更擅长流数据处理,这在实时分析场景中特别有用。Flink设计的目标是在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。Flink的核心是用Java和Scala编写的一个流式的数据流执行引擎,为数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。它提供了严格的精确一次性语义保证,这意味着每个记录都只会被处理一次,从而保证了数据处理的准确性。此外,Flink的窗口API更加灵活、语义更丰富,提供了事件时间语义,可以正确处理延迟数据。与其他大数据处理框架相比,如Spark,Flink在实时流处理方面有着显著的优势。Flink的延迟是毫秒级别,而Spark Streaming的延迟是秒级延迟。这使得Flink在处理需要高实时性的应用时更具竞争力。
Flink on yarn
Flink on Yarn是指Apache Flink与Apache Yarn的结合使用,使得Flink任务能够在Yarn集群上进行调度和执行。这种结合使用充分利用了Yarn作为分布式集群资源管理框架的优势,提高了集群资源的利用率和任务的执行效率。
Flink on Yarn主要分为两种模式:Session-Cluster模式和Per-Job-Cluster模式。
-
Session-Cluster模式(会话模式):
在这种模式下,首先需要在Yarn集群中初始化一个Flink集群(称为Flink yarn-session),并为其开辟指定的资源。这个Flink集群会常驻在Yarn集群中,除非手动停止。一旦Flink集群初始化完成,后续的Flink任务都可以提交到这个集群上执行。然而,这种模式下创建的Flink集群会独占资源,即使在没有Flink任务执行时,这些资源也无法被Yarn上的其他任务使用,这可能导致资源的浪费。 -
Per-Job-Cluster模式(job分离模式):
在这种模式下,每次提交一个Flink任务时,都会根据任务的需求向Yarn申请资源并创建一个新的Flink集群。每个Flink任务都在其独立的集群上执行,任务之间互不影响。当任务执行完成后,创建的Flink集群也会自动销毁,释放资源。这种模式使得资源能够按需使用,提高了资源的利用率。
Flink与Yarn的交互主要体现在资源申请、任务调度和容错处理等方面。Flink通过Yarn的ResourceManager申请资源,并在获得资源后启动JobManager和TaskManager进程。JobManager负责任务的调度和协调,而TaskManager负责执行具体的计算任务。如果JobManager或TaskManager进程异常退出,Yarn会负责重新调度和启动这些进程,确保任务的容错性。
总的来说,Flink on Yarn模式使得Flink能够充分利用Yarn集群的资源,提高任务的执行效率和资源的利用率。同时,通过Yarn的调度和容错机制,Flink任务的稳定性和可靠性也得到了保障。
安装部署
解压缩文件
tar -zxvf flink-1.14.0-bin-scala_2.12.tgz -C /opt/module/添加环境变量
- #FLINK_HOME
- export FLINK_HOME=/opt/module/flink-1.14.0
- export PATH=$PATH:$FLINK_HOME/bin
- export HADOOP_CLASSPATH=`hadoop classpath`
- export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
刷新环境变量,使其生效
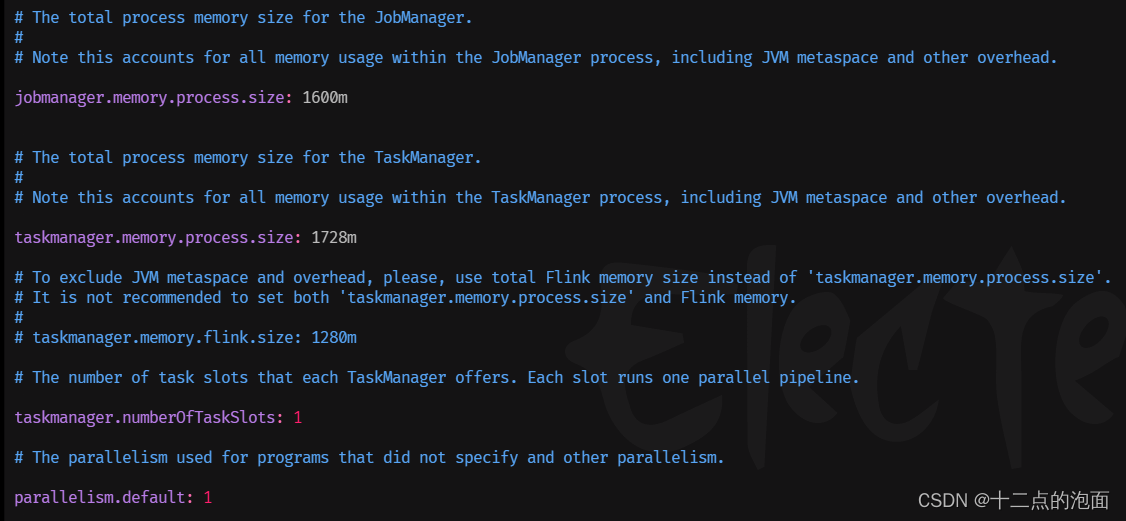
source /etc/profile进入 conf 目录,修改 flink-conf.yaml 文件(可以使用默认值)
- jobmanager.memory.process.size: 1600m
- taskmanager.memory.process.size: 1728m
- taskmanager.numberOfTaskSlots: 1
- parallelism.default: 1
以per job 运行文件
flink run -m yarn-cluster -p 2 -yjm 2G -ytm 2G $FLINK_HOME/examples/batch/WordCount.jar报错信息一:
- The program finished with the following exception:
-
- java.lang.IllegalStateException: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment" section of the official Apache Flink documentation.
- at org.apache.flink.yarn.cli.FallbackYarnSessionCli.isActive(FallbackYarnSessionCli.java:41)
- at org.apache.flink.client.cli.CliFrontend.validateAndGetActiveCommandLine(CliFrontend.java:1236)
- at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:234)
- at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1054)
- at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1132)
- at org.apache.flink.runtime.security.contexts.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:28)
- at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1132)
原因就是没有在bigdata_env.sh文件中添加
export HADOOP_CLASSPATH=`hadoop classpath`报错信息二:
- Exception in thread "Thread-5" java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'.
- at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.ensureInner(FlinkUserCodeClassLoaders.java:164)
- at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.getResource(FlinkUserCodeClassLoaders.java:183)
- at org.apache.hadoop.conf.Configuration.getResource(Configuration.java:2780)
- at org.apache.hadoop.conf.Configuration.getStreamReader(Configuration.java:3036)
- at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:2995)
- at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:2968)
- at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2848)
- at org.apache.hadoop.conf.Configuration.get(Configuration.java:1200)
- at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1812)
- at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1789)
- at org.apache.hadoop.util.ShutdownHookManager.getShutdownTimeout(ShutdownHookManager.java:183)
- at org.apache.hadoop.util.ShutdownHookManager.shutdownExecutor(ShutdownHookManager.java:145)
- at org.apache.hadoop.util.ShutdownHookManager.access$300(ShutdownHookManager.java:65)
- at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:102)
原因是:试图访问关闭的类加载器
堆内存 和 栈内存 出现争用
这时候我们可以配置“classloader.check leaked classloader”禁用此检查。
在flink的conf目录下,修改 flink-conf.yaml 文件
添加的内容如下
classloader.check leaked classloader: false再次运行即可

