
- 1CentOS7 firewall-cmd 防火墙 加入端口允许
- 2Android Studio 制作简易计算器,Android面试题中高级_android studio简易计算器代码
- 3Elasticsearch的搜索优化:搜索策略和优化方法
- 4经验模态分解和各种进化及变种 EMD,EEMD,CEEMD,CEEMDAN,ESMD等简要介绍_经验模态分解和变分模态分解
- 5Redis面试题(2023)
- 6【云计算与数据中心规划】【期末复习题】【2022秋】_虚拟基础架构的灾难恢复一般在哪个组件中
- 7【Spark】Spark的机器学习算法库——Spark MLilb_spark 算法库
- 8产品设计团队,你应该这样远程办公
- 9探索常见经典目标检测算法:从YOLO到Faster R-CNN
- 10Spring从入门到精通 | 动力节点老杜_卒获有所闻的博客
Hive on Spark
赞
踩
简介
本文主要记录如何安装配置Hive on Spark,在执行以下步骤之前,请先确保已经安装Hadoop集群,Hive,MySQL,JDK,Scala,具体安装步骤不再赘述。
背景
Hive默认使用MapReduce作为执行引擎,即Hive on mr。实际上,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark。由于MapReduce中间计算均需要写入磁盘,而Spark是放在内存中,所以总体来讲Spark比MapReduce快很多。因此,Hive on Spark也会比Hive on mr快。为了对比Hive on Spark和Hive on mr的速度,需要在已经安装了Hadoop集群的机器上安装Spark集群(Spark集群是建立在Hadoop集群之上的,也就是需要先装Hadoop集群,再装Spark集群,因为Spark用了Hadoop的HDFS、YARN等),然后把Hive的执行引擎设置为Spark。
Spark运行模式分为三种1、Spark on YARN 2、Standalone Mode 3、Spark on Mesos。
Hive on Spark默认支持Spark on YARN模式,因此我们选择Spark on YARN模式。Spark on YARN就是使用YARN作为Spark的资源管理器。分为Cluster和Client两种模式。
一、环境说明
本教程Hadoop相关软件全部基于CDH5.5.1,用yum安装,系统环境如下:
- 操作系统:CentOS 7.2
- Hadoop 2.6.0
- Hive1.1.0
- Spark1.5.0
- MySQL 5.6
- JDK 1.8
- Maven 3.3.3
- Scala 2.10
各节点规划如下:
-
192.168.117.51 Goblin01 nn1 jn1 rm1 worker master hive metastore mysql -
192.168.117.52 Goblin02 zk2 nn2 jn2 rm2 worker hive -
192.168.117.53 Goblin03 zk3 dn1 jn3 worker hive -
192.168.117.54 Goblin04 zk4 dn2 worker hive
说明:Goblin01~04是每台机器的hostname,zk代表zookeeper,nn代表hadoop的namenode,dn代表datanode,jn代表journalnode,rm代表resourcemanager,worker代表Spark的slaves,master代表Spark的master
二、编译和安装Spark(Spark on YARN)
2.1 编译Spark源码
要使用Hive on Spark,所用的Spark版本必须不包含Hive的相关jar包,hive on spark 的官网上说“Note that you must have a version of Spark which does not include the Hive jars”。在spark官网下载的编译的Spark都是有集成Hive的,因此需要自己下载源码来编译,并且编译的时候不指定Hive。
我们这里用的Spark源码是spark-1.5.0-cdh5.5.1版本,下载地址如下:
http://archive.cloudera.com/cdh5/cdh/5/spark-1.5.0-cdh5.5.1-src.tar.gz
下载完后用 tar xzvf 命令解压,进入解压完的文件夹,准备编译。
注意:编译前请确保已经安装JDK、Maven和Scala,maven为3.3.3及以上版本,并在/etc/profile里配置环境变量。
命令行进入在源码根目录下,执行
./make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.6,parquet-provided"若编译过程出现内存不足的情况,需要在运行编译命令之前先运行:
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"来设置Maven的内存。
编译过程由于要下载很多Maven依赖的jar包,需要时间较长(大概一两个小时),要保证网络状况良好,不然很容易编译失败。若出现以下结果,则编译成功:
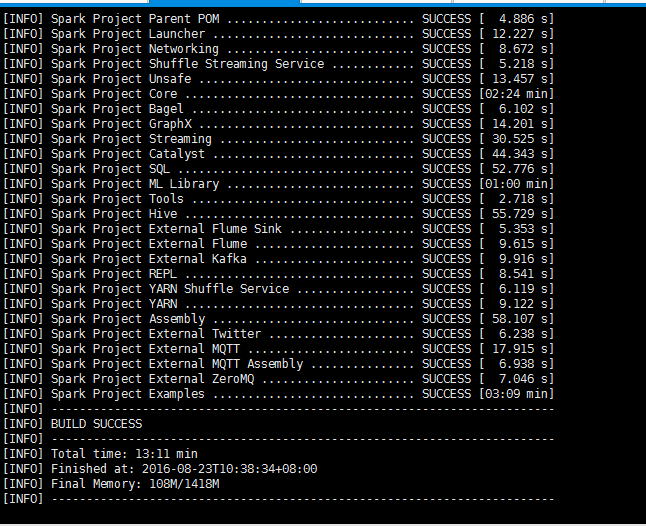
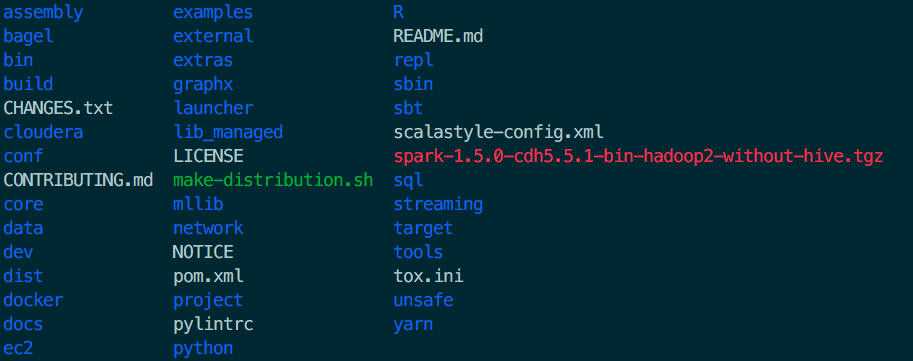
编译成功后,会在源码根目录下多出一个文件(红色部分):
spark-1.5.0-cdh5.5.1-bin-hadoop2-without-hive.tgz
2.2 安装Spark
-
将编译完生成的spark-1.5.0-cdh5.5.1-bin-hadoop2-without-hive.tgz拷贝到Spark的安装路径,并用 tar -xzvf 命令解压
-
配置环境变量
-
$vim /etc/profile -
export SPARK_HOME=spark安装路径 -
$source /etc/profile
-
2.3 配置Spark
配置spark-env.sh、slaves和spark-defaults.conf三个文件
- spark-env.sh
主要配置JAVA_HOME、SCALA_HOME、HADOOP_HOME、HADOOP_CONF_DIR、SPARK_MASTER_IP等
-
export JAVA_HOME=/usr/lib/jvm/java -
export SCALA_HOME=/root/scala -
export HADOOP_HOME=/usr/lib/hadoop -
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop -
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop -
export SPARK_LAUNCH_WITH_SCALA=0 -
export SPARK_WORKER_MEMORY=1g -
export SPARK_DRIVER_MEMORY=1g -
export SPARK_MASTER_IP=192.168.117.51 -
export SPARK_LIBRARY_PATH=/root/spark-without-hive/lib -
export SPARK_MASTER_WEBUI_PORT=18080 -
export SPARK_WORKER_DIR=/root/spark-without-hive/work -
export SPARK_MASTER_PORT=7077 -
export SPARK_WORKER_PORT=7078 -
export SPARK_LOG_DIR=/root/spark-without-hive/log -
export SPARK_PID_DIR='/root/spark-without-hive/run'
- slaves(将所有节点都加入,master节点同时也是worker节点)
-
Goblin01 -
Goblin02 -
Goblin03 -
Goblin04
- spark-defaults.conf
-
spark.master yarn-cluster -
spark.home /root/spark-without-hive -
spark.eventLog.enabled true -
spark.eventLog.dir hdfs://Goblin01:8020/spark-log -
spark.serializer org.apache.spark.serializer.KryoSerializer -
spark.executor.memory 1g -
spark.driver.memory 1g -
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.master指定Spark运行模式,可以是yarn-client、yarn-cluster...
spark.home指定SPARK_HOME路径
spark.eventLog.enabled需要设为true
spark.eventLog.dir指定路径,放在master节点的hdfs中,端口要跟hdfs设置的端口一致(默认为8020),否则会报错
spark.executor.memory和spark.driver.memory指定executor和dirver的内存,512m或1g,既不能太大也不能太小,因为太小运行不了,太大又会影响其他服务
三、配置YARN
配置yarn-site.xml,跟hdfs-site.xml在同一个路径下($HADOOP_HOME/etc/hadoop)
- <property>
- <name>yarn.resourcemanager.scheduler.class</name>
- <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
- </property>
四、配置Hive
- 添加spark依赖到hive(将spark-assembly-1.5.0-cdh5.5.1-hadoop2.6.0.jar拷贝到$HIVE_HOME/lib目录下)
进入SPARK_HOME
cp spark-assembly-1.5.0-cdh5.5.1-hadoop2.6.0.jar /usr/lib/hive/lib- 配置hive-site.xml
配置的内容与spark-defaults.conf相同,只是形式不一样,以下内容是追加到hive-site.xml文件中的,并且注意前两个配置,如果不设置hive的spark引擎用不了,在后面会有详细的错误说明。
-
- <property>
- <name>hive.execution.engine</name>
- <value>spark</value>
- </property>
-
- <property>
- <name>hive.enable.spark.execution.engine</name>
- <value>true</value>
- </property>
-
- <property>
- <name>spark.home</name>
- <value>/root/spark-without-hive</value>
- </property>
- <property>
- <name>spark.master</name>
- <value>yarn-client</value>
- </property>
- <property>
- <name>spark.enentLog.enabled</name>
- <value>true</value>
- </property>
- <property>
- <name>spark.enentLog.dir</name>
- <value>hdfs://Goblin01:8020/spark-log</value>
- </property>
- <property>
- <name>spark.serializer</name>
- <value>org.apache.spark.serializer.KryoSerializer</value>
- </property>
- <property>
- <name>spark.executor.memeory</name>
- <value>1g</value>
- </property>
- <property>
- <name>spark.driver.memeory</name>
- <value>1g</value>
- </property>
- <property>
- <name>spark.executor.extraJavaOptions</name>
- <value>-XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"</value>
- </property>

五、验证是否安装配置成功
1.验证Spark集群
注意:在启动Spark集群之前,要确保Hadoop集群和YARN均已启动
- 进入$SPARK_HOME目录,执行:
./sbin/start-all.sh用jps命令查看51节点上的master和worker,52、53、54节点上的worker是否都启动了
- 同样在$SPARK_HOME目录下,提交计算Pi的任务,验证Spark集群是否能正常工作,运行如下命令
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client lib/spark-examples-1.5.0-cdh5.5.1-hadoop2.6.0.jar 10若无报错,并且算出Pi的值,说明Spark集群能正常工作
2.验证Hive on Spark是否可用
- 命令行输入 hive,进入hive CLI
- set hive.execution.engine=spark; (将执行引擎设为Spark,默认是mr,退出hive CLI后,回到默认设置。若想让引擎默认为Spark,需要在hive-site.xml里设置)
- create table test(ts BIGINT,line STRING); (创建表)
- select count(*) from test;
- 若整个过程没有报错,并出现正确结果,则Hive on Spark配置成功。
六、遇到的问题
0 编译spark基于maven有两种方式
- 用mvn 命令编译
./build/mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0 -DskipTests clean package 编译到倒数MQTT模块一直报错,而且编译出的文件比较大,不适合安装集群,因此不推荐。使用Intellij IDEA maven 插件报错如下:
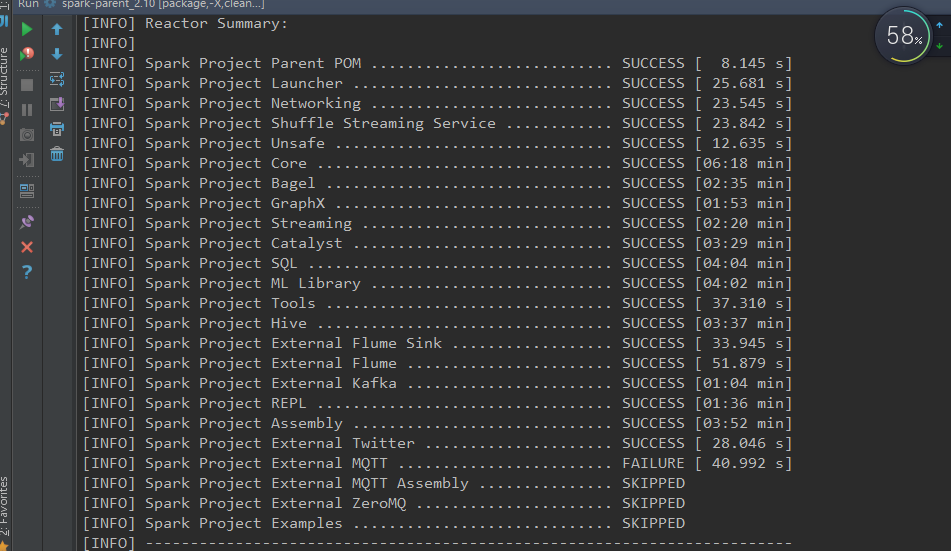
- 使用spark提供的预编译脚本,网络状况稳定,会编译出需要的安装版本,推荐。命令
./make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.6,parquet-provided"结果如上文所述。
1 运行:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn lib/spark-examples-1.5.0-cdh5.5.1-hadoop2.6.0.jar 10报错:
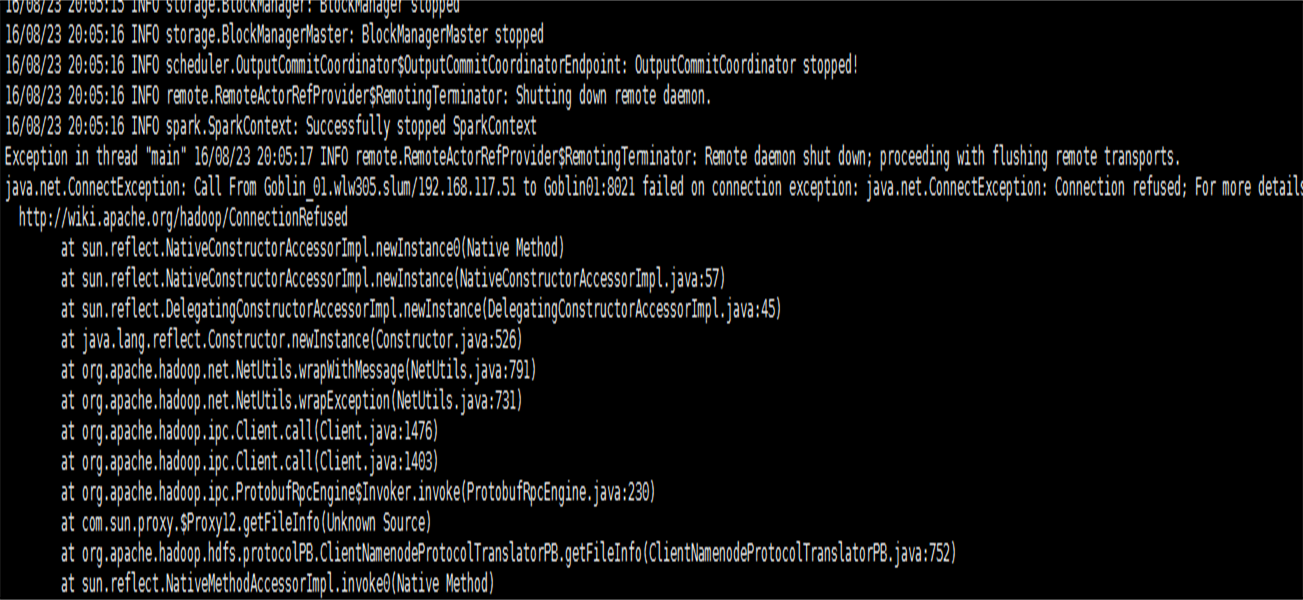
原因:
hdfs的默认端口为8020 ,而我们在spark-default.conf中配置成了8021端口,导致连接不上HDFS报错
-
spark.eventLog.enabled true -
spark.eventLog.dir hdfs://Goblin01:8021/spark-log
解决:
配置spark-default.conf中的spark.eventLog.dir 为本地路径,也就是不持久化日志到hdfs上,也就没有和hdfs的通行
or
spark-default.conf 注释掉 spark.eventLog.enabled true
or
在spark-default.conf里配置的eventLog端口跟hdfs的默认端口(8020)一致
or
由于配置的hdfs是高可用的,51,52都可以作为namenode,我们的spark集群的主节点在51上,当51上的namenode变成standby,导致无法访问hdfs的8020端口(hdfs默认端口),也就是说在51上读不出hdfs上spark-log的内容,在spark-default.conf中配置为spark.eventLog.dir hdfs://Goblin01:8021/spark-log,如果发生这种情况,直接kill掉52,让namenode只在51上运行。(这个后面要搭建spark的高可用模式解决)
2 运行:
在hive里设置引擎为spark,执行select count(*) from a;
报错:
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Unsupported execution engine: Spark. Please set hive.execution.engine=mr)'解决:
这是因为CDH版的Hive默认运行支持Hive on Spark(By default, Hive on Spark is not enabled).
需要用cloudera manager(cloudera官网给的的方法,但是要装cloudera manager,比较麻烦,不建议)
-
Go to the Hive service. -
Click the Configuration tab. -
Enter Enable Hive on Sparkin the Search field. -
Check the box for Enable Hive on Spark (Unsupported). -
Locate the Spark On YARN Service and click SPARK_ON_YARN. -
Click Save Changes to commit the changes.
或者
在hive-site.xml添加配置(简单、推荐)
-
<property> -
<name>hive.enable.spark.execution.engine</name> -
<value>true</value> -
</property>
3 终端输入hive无法启动hive CLI
原因:namenode挂了
解决:重启namenode
4 运行:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client lib/spark-examples-1.5.0-cdh5.5.1-hadoop2.6.0.jar 10问题:
没有报错,但是出现以下情况,停不下来

原因:
- ResourceManager或者NodeManager挂掉,一直没有NodeManager响应,任务无法执行,所有停不下来。
- 还有一种情况是spark有别的application在运行,导致本次spark任务的等待或者失败
解决:
- 对于原因1,重启ResourceManager和NodeManager。
-
service hadoop-yarn-resourcemanager start; -
service hadoop-yarn-nodemanager start;
- 对于原因2,解决办法是在hadoop配置文件中设置yarn的并行度,在
/etc/hadoop/conf/capacity-scheduler.xml文件中配置yarn.scheduler.capacity.maximum-am-resource-percent from 0.1 to 0.5
- <property>
- <name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
- <value>0.5</value>
- <description>
- Maximum percent of resources in the cluster which can be used to run
- application masters i.e. controls number of concurrent running
- applications.
- </description>
- </property>

