
- 1UbuntuServer22.04安装docker
- 2Linux服务器(一)时间相关详解_服务器 系统时间 rtc
- 3小红书电商运营实战课,从0打造全程实操(65节视频课)
- 4Vue2.0 配置代理_方式二_vue2配置代理
- 5Flask-SQLAlchemy的安装使用 一对多 多对多join查询_sqlalchemy join 多条件
- 6Uptime Kuma – 网站、服务、端口监控 – 自定义监控页
- 7yolov5-5.0训练完整步骤
- 8FPGA实现AD9361数据接口逻辑_fpga芯片与ad9361接口
- 9HarmonyOS Next 实现登录注册页面(ARKTS) 并使用Springboot作为后端提供接口_arkts登录注册界面
- 10Vue打包扫描存在中危风险过期的YUI版本_yui 2.9.0
fine tune chatgpt_finetune embed chatgpt
赞
踩
介绍
可以从API提供的模型中获得信息:
- 比 prompt 设计更高质量的结果
- 能够在超过 prompt 范围的示例上进行训练
- 更短的 prompt 节省了token
- 更低的延迟请求
fine tune包括以下步骤:
- 准备并上传训练数据
- 训练一个新的微调模型
- 使用经过微调的模型
定价页面,价格单位是1000个token,相当于750个英文单词。

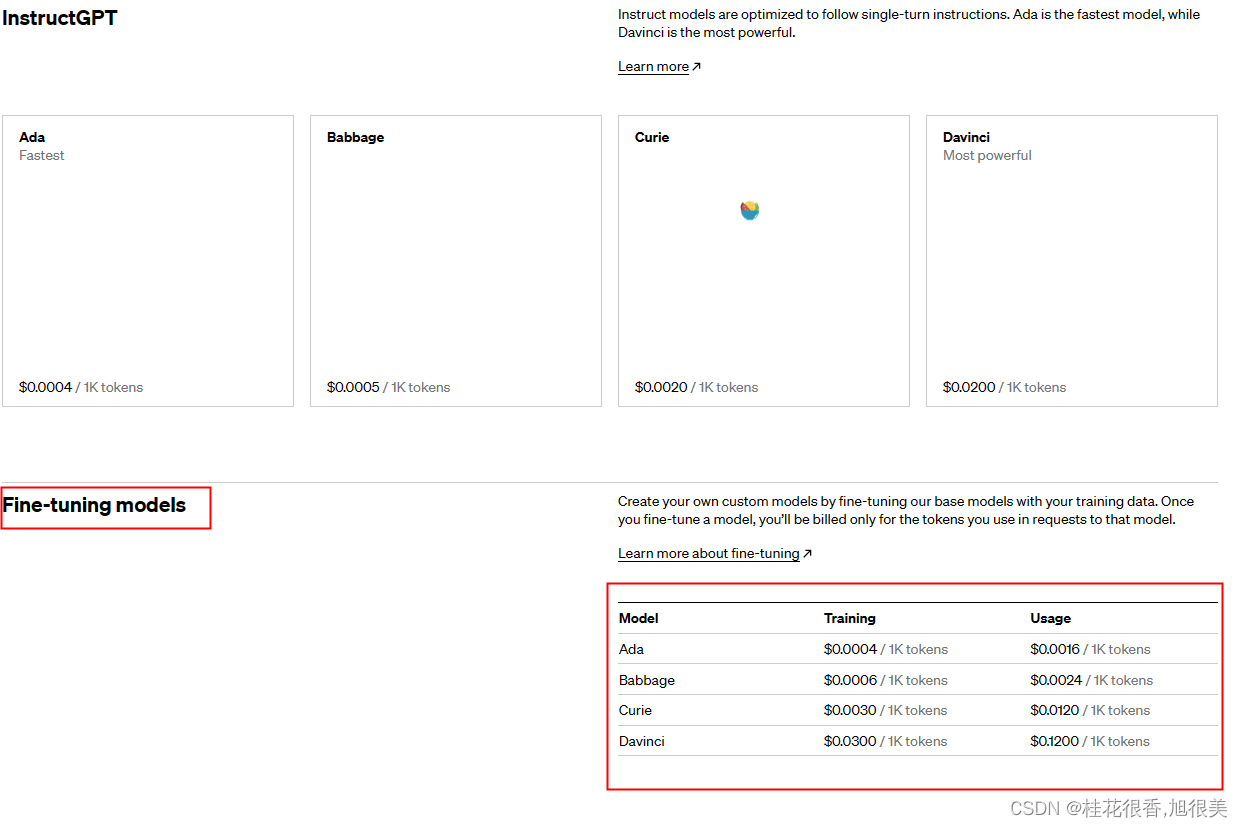
模型可以微调的有:davinci、curie、babbage和ada这些是原始模型,instruction following训练(例如text-davinci-003)可以添加数据微调一些微调过的模型。
安装
pip install --upgrade openai
- 1
以下适用于0.9.4及更高版本。OpenAI CLI需要python 3。
设置OPENAI_API_KEY环境变量
export OPENAI_API_KEY="<OPENAI_API_KEY>"
- 1
准备数据
训练数据是你教GPT-3让它说什么的方式。
数据必须是一个JSONL文档,每一行都是与训练示例相对应的 prompt-completion对。可以用CLI数据准备工具将数据转换为此文件格式。
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
- 1
- 2
- 3
- 4
设计用于微调的 prompts和 completions与设计用于基本模型(Davinci、Curie、Babbage、Ada)的 prompts不同。基本模型的提示通常由多个示例组成(“few-shot learning”),但为了进行微调,每个训练示例通常由单个输入示例及其相关输出组成,而不需要给出详细instructions或在同一prompt中包括多个示例。
训练实例越多越好。建议至少有几百个例子。数据集大小的每增加一倍都会导致模型质量的线性增加。
CLI数据准备工具
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
- 1
该工具接受不同的格式,唯一的要求是它们包含一个prompt和一个 completion 列/键。可以传递一个CSV、TSV、XLSX、JSON或JSONL文件,在指导完成建议的更改过程后,它会将输出保存到一个JSONL文档中,以便进行微调。
创建fine tune模型
接下来用OpenAI CLI 开始微调任务:
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
- 1
BASE_MODEL是开始使用的基本模型的名称(ada、babbage、curie或davinci), 默认为curie。可以使用后缀(suffix)参数自定义经过微调的模型的名称。
上述命令可以完成以下操作:
- 使用文件API上传文件(或使用已上传的文件)
- 创建微调任务
- 流式处理事件,直到任务完成(通常需要几分钟,但如果队列中有很多任务在排队或数据集很大,则可能需要几个小时)
微调任务开始后,开始在系统上排队,根据模型大小和数据集大小,训练时间不等。如果中断,可以用以下命令回复:
openai api fine_tunes.follow -i <YOUR_FINE_TUNE_JOB_ID>
- 1
完成后,应该会显示微调模型的名称。除了创建微调任务外,还可以列出现有任务、检索任务的状态或取消任务。
# List all created fine-tunes 列出现有任务
openai api fine_tunes.list
# Retrieve the state of a fine-tune. The resulting object includes
# job status (which can be one of pending, running, succeeded, or failed)
# and other information 检索任务的状态
openai api fine_tunes.get -i <YOUR_FINE_TUNE_JOB_ID>
# Cancel a job 取消任务
openai api fine_tunes.cancel -i <YOUR_FINE_TUNE_JOB_ID>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
调用微调后的模型
可以通过传递模型名称作为完成请求的模型参数来开始发出请求:
OpenAI CLI:
openai api completions.create -m <FINE_TUNED_MODEL> -p <YOUR_PROMPT>
- 1
cURL:
curl https://api.openai.com/v1/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{"prompt": YOUR_PROMPT, "model": FINE_TUNED_MODEL}'
- 1
- 2
- 3
- 4
Python:
import openai
openai.Completion.create(
model=FINE_TUNED_MODEL,
prompt=YOUR_PROMPT)
- 1
- 2
- 3
- 4
Node.js:
const response = await openai.createCompletion({
model: FINE_TUNED_MODEL
prompt: YOUR_PROMPT,
});
- 1
- 2
- 3
- 4
也可以使用其他的 Completions 参数:调用ChatGPT API
删除一个微调过的模型
OpenAI CLI:
openai api models.delete -i <FINE_TUNED_MODEL>
- 1
cURL:
curl -X "DELETE" https://api.openai.com/v1/models/<FINE_TUNED_MODEL> \
-H "Authorization: Bearer $OPENAI_API_KEY"
- 1
- 2
Python:
import openai
openai.Model.delete(FINE_TUNED_MODEL)
- 1
- 2
准备数据集
数据格式
要微调模型,需要一组训练示例,每个示例都由单个输入(“prompt”)及其相关输出(“completion”)组成。这与直接使用基本模型明显不同,在基本模型中,可以在一个prompt中输入详细的instructions (说明)或多个示例。
- 每个prompt都应该以一个固定的分隔符结束,以便在prompt结束和completion开始时通知模型。一个通常工作良好的简单分隔符是
\n\n###\n\n。分隔符不应出现在任何prompt的其他位置。 - 由于 tokenization,每个completion 都应该以一个空白(whitespace )开始,这会用前面的 空白 tokenizes大多数单词。
- 每个completion都应该以一个固定的停止序列结束,以便在完成结束时通知模型。停止序列可以是
\n, ###,或任何其他未出现在任何completion中的token 。 - 对于推理,应该以与创建训练数据集时相同的方式格式化 prompts ,包括相同的分隔符。还要指定相同的停止序列以正确截断 completion。
实践建议
- 要微调一个比在基本模型中使用高质量提示性能更好的模型,应该提供至少几百个高质量的示例,最好由人类专家进行审查。性能往往会随着示例数量的每增加一倍而线性增加。增加示例的数量通常是提高性能的最佳和最可靠的方法。
- 分类器(Classifiers)是最容易上手的模型。对于分类问题,建议使用ada,一旦进行微调,它的性能通常只比功能更强的模型差一点点,同时速度更快、更便宜。
- 如果正在对预先存在的数据集进行微调,而不是从头开始编写提示,请确保尽可能手动检查数据中是否有冒犯性或不准确的内容,或者如果数据集很大,请检查尽可能多的随机样本。
具体准则
1 分类
在分类问题中,提示中的每个输入都应该被分类到预定义的类中。对于这类问题建议:
- 在提示的末尾使用分隔符,例如
\n\n###\n\n。当您最终向模型发出请求时,请记住还要附加此分隔符。 - 选择映射到单个token的类。在推断时,指定max_tokens=1,因为您只需要第一个token进行分类。
- 确保prompt + completion不超过2048个token,包括分隔符
- 目标是每个类别至少有100个例子
- 要获得类日志概率,您可以在使用模型时指定logprobs=5(对于5个类)
- 确保用于微调的数据集在结构和任务类型上与模型的用途非常相似
案例研究:模型是否做出了不真实的陈述?
比方说,你想确保你网站上的广告文本提到了正确的产品和公司。换言之,您希望确保模型不会捏造事实。你可能想微调一个分类器,它可以过滤掉不正确的广告。
数据集可能如下所示:
{"prompt":"Company: BHFF insurance\nProduct: allround insurance\nAd:One stop shop for all your insurance needs!\nSupported:", "completion":" yes"}
{"prompt":"Company: Loft conversion specialists\nProduct: -\nAd:Straight teeth in weeks!\nSupported:", "completion":" no"}
- 1
- 2
在上面的例子中,我们使用了一个包含公司名称、产品和相关广告的结构化输入。作为分隔符,我们使用\nSupported:它将prompt 和completion清楚地分隔开。有了足够数量的例子,只要分隔符不出现在提示或完成中,它就不会有太大的区别(通常小于0.4%)。
对于这个用例,我们对ada模型进行了微调,因为它将更快、更便宜,并且性能将与更大的模型相当,因为这是一项分类任务。
现在我们可以通过发出Completion请求来查询我们的模型。
curl https://api.openai.com/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"prompt": "Company: Reliable accountants Ltd\nProduct: Personal Tax help\nAd:Best advice in town!\nSupported:",
"max_tokens": 1,
"model": "YOUR_FINE_TUNED_MODEL_NAME"
}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Which will return either yes or no
案例研究:情绪分析
比方说,你想获得一条特定推文的积极或消极程度。数据集可能如下所示:
{"prompt":"Overjoyed with the new iPhone! ->", "completion":" positive"}
{"prompt":"@lakers disappoint for a third straight night https://t.co/38EFe43 ->", "completion":" negative"}
- 1
- 2
一旦对模型进行了微调,就可以通过在completion 请求上设置logprobs=2来返回第一个completion token的日志概率。积极类的概率越高,相对情绪就越高。
现在我们可以通过发出Completion请求来查询我们的模型。
curl https://api.openai.com/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"prompt": "https://t.co/f93xEd2 Excited to share my latest blog post! ->",
"max_tokens": 1,
"model": "YOUR_FINE_TUNED_MODEL_NAME"
}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
返回:
{
"id": "cmpl-COMPLETION_ID",
"object": "text_completion",
"created": 1589498378,
"model": "YOUR_FINE_TUNED_MODEL_NAME",
"choices": [
{
"logprobs": {
"text_offset": [
19
],
"token_logprobs": [
-0.03597255
],
"tokens": [
" positive"
],
"top_logprobs": [
{
" negative": -4.9785037,
" positive": -0.03597255
}
]
},
"text": " positive",
"index": 0,
"finish_reason": "length"
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
案例研究:电子邮件分类
假设你想将收到的电子邮件分类为大量预定义类别中的一个。对于分类为大量类别的情况,我们建议您将这些类别转换为数字,这将很好地适用于大约500个类别。我们已经观察到,由于tokenization,在数字之前添加一个空格有时会稍微有助于提高性能。您可能需要按以下方式构建培训数据:
{"prompt":"Subject: <email_subject>\nFrom:<customer_name>\nDate:<date>\nContent:<email_body>\n\n###\n\n", "completion":" <numerical_category>"}
- 1
例子:
{"prompt":"Subject: Update my address\nFrom:Joe Doe\nTo:support@ourcompany.com\nDate:2021-06-03\nContent:Hi,\nI would like to update my billing address to match my delivery address.\n\nPlease let me know once done.\n\nThanks,\nJoe\n\n###\n\n", "completion":" 4"}
- 1
在上面的例子中,我们使用了一封上限为2043个tokens 的传入电子邮件作为输入。(这允许使用4个tokens分隔符和一个令牌completion,总计2048。)作为分隔符,我们使用了\n\n###\n\n,并删除了电子邮件中出现的###。
2 条件生成
条件生成是一个需要在给定某种输入的情况下生成内容的问题。这包括转述、总结、实体提取、给定规格的产品描述写作、聊天机器人和许多其他内容。对于这种类型的问题,我们建议:
- 在提示的末尾使用分隔符,例如
\n \n###\n \n。当最终向模型发出请求时,请记住还要附加此分隔符。 - 在completion时使用结束token ,例如
END - 记住在推理过程中添加结束标记作为停止序列,例如stop=[“END”]
- 至少500个示例
- 确保 prompt + completion不超过2048个tokens,包括分隔符
- 确保示例具有高质量,并遵循相同的所需格式
- 确保用于微调的数据集在结构和任务类型上与模型的用途非常相似
- 使用较低的学习率和仅1-2个epochs 往往更适合这些用例
案例研究:根据维基百科的一篇文章写一则引人入胜的广告
这是一个生成用例,确保提供的样本具有最高质量,因为微调后的模型将试图模仿给定示例的风格(和错误)。一个好的起点是大约500个例子。示例数据集可能如下所示:
{"prompt":"<Product Name>\n<Wikipedia description>\n\n###\n\n", "completion":" <engaging ad> END"}
- 1
例子:
{"prompt":"Samsung Galaxy Feel\nThe Samsung Galaxy Feel is an Android smartphone developed by Samsung Electronics exclusively for the Japanese market. The phone was released in June 2017 and was sold by NTT Docomo. It runs on Android 7.0 (Nougat), has a 4.7 inch display, and a 3000 mAh battery.\nSoftware\nSamsung Galaxy Feel runs on Android 7.0 (Nougat), but can be later updated to Android 8.0 (Oreo).\nHardware\nSamsung Galaxy Feel has a 4.7 inch Super AMOLED HD display, 16 MP back facing and 5 MP front facing cameras. It has a 3000 mAh battery, a 1.6 GHz Octa-Core ARM Cortex-A53 CPU, and an ARM Mali-T830 MP1 700 MHz GPU. It comes with 32GB of internal storage, expandable to 256GB via microSD. Aside from its software and hardware specifications, Samsung also introduced a unique a hole in the phone's shell to accommodate the Japanese perceived penchant for personalizing their mobile phones. The Galaxy Feel's battery was also touted as a major selling point since the market favors handsets with longer battery life. The device is also waterproof and supports 1seg digital broadcasts using an antenna that is sold separately.\n\n###\n\n", "completion":"Looking for a smartphone that can do it all? Look no further than Samsung Galaxy Feel! With a slim and sleek design, our latest smartphone features high-quality picture and video capabilities, as well as an award winning battery life. END"}
- 1
这里我们使用了多行分隔符,因为维基百科的文章包含多个段落和标题。我们还使用了一个简单的结束token,以确保模型知道何时应该完成。
案例研究:实体提取
这类似于语言转换任务。为了提高性能,最好按照字母顺序或与原始文本中出现的实体相同的顺序对不同的提取实体进行排序。这将有助于模型跟踪所有需要按顺序生成的实体。数据集可能如下所示:
{"prompt":"<any text, for example news article>\n\n###\n\n", "completion":" <list of entities, separated by a newline> END"}
- 1
例子:
{"prompt":"Portugal will be removed from the UK's green travel list from Tuesday, amid rising coronavirus cases and concern over a \"Nepal mutation of the so-called Indian variant\". It will join the amber list, meaning holidaymakers should not visit and returnees must isolate for 10 days...\n\n###\n\n", "completion":" Portugal\nUK\nNepal mutation\nIndian variant END"}
- 1
多行分隔符效果最好,因为文本可能包含多行。理想情况下,输入prompts的类型(新闻文章、维基百科页面、推文、法律文件)将高度多样,这些prompts反映了提取实体时可能遇到的文本。
案例研究:客户支持聊天机器人
聊天机器人通常会包含有关对话的相关上下文(订单详细信息)、迄今为止的对话摘要(Summary)以及最新几轮消息。对于这个用例,相同的过去对话可以在数据集中生成多行,每次都有一个稍微不同的上下文,每次生成代理(chatgpt)作为一个 completion。这个用例需要几千个示例,因为它可能会处理不同类型的请求和客户问题。为了确保性能高质量,我们建议检查会话样本,以确保代理消息的质量。摘要(Summary)可以使用单独的文本转换微调模型生成。数据集可能如下所示:
{"prompt":"Summary: <summary of the interaction so far>\n\nSpecific information:<for example order details in natural language>\n\n###\n\nCustomer: <message1>\nAgent: <response1>\nCustomer: <message2>\nAgent:",
"completion":" <response2>\n"}
{"prompt":"Summary: <summary of the interaction so far>\n\nSpecific information:<for example order details in natural language>\n\n###\n\nCustomer: <message1>\nAgent: <response1>\nCustomer: <message2>\nAgent: <response2>\nCustomer: <message3>\nAgent:",
"completion":" <response3>\n"}
- 1
- 2
- 3
- 4
在这里,我们有目的地分离不同类型的输入信息,但在prompt 和completion之间以相同的格式维护“客户代理”对话框( Customer Agent dialog)。所有的completions 都应该只由代理(agent)完成,并且我们可以在进行推理时使用\n作为停止序列。(上一轮的completions 作为下一轮对话的最后一个Agent)
案例研究:基于性能技术列表的产品描述
在这里,将输入数据转换为自然语言是很重要的,这可能会带来卓越的性能。例如,以下格式:
{"prompt":"Item=handbag, Color=army_green, price=$99, size=S->", "completion":" This stylish small green handbag will add a unique touch to your look, without costing you a fortune."}
- 1
效果不如下面的:
{"prompt":"Item is a handbag. Colour is army green. Price is midrange. Size is small.->", "completion":" This stylish small green handbag will add a unique touch to your look, without costing you a fortune."}
- 1
为了获得高性能,请确保completions 基于所提供的描述。如果经常咨询外部内容,那么以自动方式添加此类内容将提高性能。如果描述是基于图像的,那么使用算法来提取图像的文本描述可能会有所帮助。由于completions 只有一个句子长,我们可以使用.作为推理期间的停止序列。
高级用法
自定义模型名称
您可以使用后缀( suffix)参数为微调后的模型名称添加最多40个字符的后缀。
OpenAI CLI:
openai api fine_tunes.create -t test.jsonl -m ada --suffix "custom model name"
- 1
由此产生的名称为:
ada:ft-your-org:custom-model-name-2023-05-10-19-21-04
- 1
分析微调模型
我们在每个任务完成后都会附上一个结果文件。检索微调时,以及查看微调中的事件时,都会列出此结果文件ID。可以下载以下文件:
OpenAI CLI:
openai api fine_tunes.results -i <YOUR_FINE_TUNE_JOB_ID>
- 1
CURL:
curl https://api.openai.com/v1/files/$RESULTS_FILE_ID/content \
-H "Authorization: Bearer $OPENAI_API_KEY" > results.csv
- 1
- 2
_results.csv文件包含每个训练步骤(step)的一行,其中一个步骤指的是对一批(batch)数据进行一次正向和反向传递( forward and backward pass)。除了步骤编号外,每行还包含与该步骤对应的以下字段:
- elapsed_tokens:模型到目前为止看到的tokens数量(包括重复)
- elapsed_examples:到目前为止,模型看到的示例数量(包括重复),其中一个示例是批处理中的一个元素。例如,如果batch_size=4,则每个步骤都会将elapsed_examples增加4。
- training_loss: loss on the training batch
- training_sequence_precision:训练批次中模型的预测 tokens 与真实completion tokens 完全匹配的completions 百分比。例如,在batch_size为3的情况下,如果数据包含 completions [[1,2],[0,5],[4,2]]和预测的模型[[1,1],[0,5],[4,2]],则此精度将为2/3=0.67
- training_token_accuracy:模型正确预测的训练批次中token 的百分比。例如,在batch_size为3的情况下,如果您的数据包含completions [[1,2],[0,5],[4,2]]和预测的模型[[1,1],[0,5],[4,2]],则此精度将为5/6=0.83
分类特定指标
我们还提供了在结果文件中生成额外的分类特定指标(generating additional classification-specific metrics)的选项,例如accuracy和weighted F1 score。这些度量是根据完整的验证集定期计算的,并在微调结束时进行计算。您将在结果文件中看到它们作为附加列。
要启用此功能,请设置参数**–compute_classification_metrics**。此外,您必须提供一个验证文件(validation file),并为多分类设置classification_n_classes参数,或为binary classification设置classfication_ppositive_class参数。
OpenAI CLI:
# For multiclass classification
openai api fine_tunes.create \
-t <TRAIN_FILE_ID_OR_PATH> \
-v <VALIDATION_FILE_OR_PATH> \
-m <MODEL> \
--compute_classification_metrics \
--classification_n_classes <N_CLASSES>
# For binary classification
openai api fine_tunes.create \
-t <TRAIN_FILE_ID_OR_PATH> \
-v <VALIDATION_FILE_OR_PATH> \
-m <MODEL> \
--compute_classification_metrics \
--classification_n_classes 2 \
--classification_positive_class <POSITIVE_CLASS_FROM_DATASET>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
如果设置了--compute_classification_metrics:
对于多类别分类
- classification/accuracy: accuracy
- classification/weighted_f1_score: weighted F-1 score
二分类
以下度量基于0.5的分类阈值(即,当概率>0.5时,示例被分类为属于正类。)
- classification/accuracy
- classification/precision
- classification/recall
- classification/f{beta}
- classification/auroc - AUROC
- classification/auprc - AUPRC
请注意,这些评估假设前提是tokenize 文本标签为单个token的类,如上所述。如果这些条件不成立,你得到的数字很可能是错误的。
验证
您可以保留一些数据以供验证。验证文件的格式与训练文件的格式完全相同,训练和验证数据应该独立。
如果在创建微调任务时包含验证文件,则生成的结果文件将包含对微调模型在培训期间定期对照验证数据执行的评估
OpenAI CLI:
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> \
-v <VALIDATION_FILE_ID_OR_PATH> \
-m <MODEL>
- 1
- 2
- 3
如果提供了验证文件,训练期间定期计算验证数据批次的指标。将在结果文件中看到以下附加指标:
- validation_loss:loss on the validation batch
- validation_sequence_precision:验证批次中模型的预测tokens 与真实completions tokens 完全匹配的completions百分比。例如,在batch_size为3的情况下,如果您的数据包含完成[[1,2],[0,5],[4,2]]和预测的模型[[1,1],[0,5],[4,2]],则此精度将为2/3=0.67
- validation_token_accuracy:验证批次中由模型正确预测的tokens 的百分比。例如,在batch_size为3的情况下,如果您的数据包含完成[[1,2],[0,5],[4,2]]和预测的模型[[1,1],[0,5],[4,2]],则此精度将为5/6=0.83
超参数
我们选择了在一系列用例中都能很好地工作的默认超参数。唯一需要的参数是 training file。
也就是说,调整用于微调的超参数通常可以产生更高质量输出的模型。特别是,可能需要配置以下内容:
- model:要微调的基本模型的名称。可以选择“ada”、“babbage”、“curie”或“davinci”中的一个。要了解有关这些模型的更多信息,请参阅 模型文档。
- n_epochs-默认为4。要为其训练模型的epochs数。
- batch_size-默认为训练集中示例数的0.2%,上限为256。批量大小是用于训练单个前向和后向传播的训练示例的数量。通常,我们发现较大的批量大小往往对较大的数据集更有效。
- learning_rate_multiplier-默认值为0.05、0.1或0.2,具体取决于最终批次大小。微调学习率是用于预训练的原始学习率乘以该乘数。建议使用0.02到0.2范围内的值进行实验,看看什么能产生最佳结果。根据经验,batch size 大时,学习率越大效果越好。
- compute_classification_metrics-默认为False。如果为True,则为了对分类任务进行微调,在每个epoch结束时计算验证集上的分类特定指标(accuracy, F-1 score, etc)。
要配置这些额外的超参数,请通过OpenAI CLI上的命令行标志将其传入,例如:
openai api fine_tunes.create \
-t file-JD89ePi5KMsB3Tayeli5ovfW \
-m ada \
--n_epochs 1
- 1
- 2
- 3
- 4
从微调过的模型继续微调
如果已经针对任务对模型进行了微调,并且现在有了要合并的其他训练数据,则可以继续从模型进行微调。这创建了一个从所有训练数据中学习的模型,而不必从头开始重新训练。
要做到这一点,在创建新的微调任务时传入微调模型名称(例如-m curie:ft-<org>-<date>)。其他训练参数不必更改,但是,如果新的训练数据比以前的训练数据小得多,您可能会发现将learning_rate_multiplier 减少2到4倍是很有用的。
Weights & Biases
可以将微调与Weights & Biases同步,以跟踪实验、模型和数据集。
需要一个Weights&Biases帐户和一个付费的OpenAI plan。要确保使用的是openai和wandb的最新版本,请运行:
pip install --upgrade openai wandb
- 1
同步 fine-tunes 和Weights & Biases, 运行:
openai wandb sync
- 1
Weights & Biases documentation


