
- 1【路径规划】蚁群算法机器人大规模栅格地图最短路径规划【含Matlab源码 1860期】
- 215个值得探索的AI赚钱方法_如何用ai赚钱
- 3【MYSQL】基础的增删查改_mysql增删改查
- 4通义灵码×西安交通大学携手打造“云工开物-高校训练营”,解锁 AI 时代编程学习与实战
- 5MySQL调优方法总结的真全
- 6神经网络电子书,神经网络入门书_神经网络 电子书
- 7Generative Adversarial Text to Image Synthesis 学习笔记_knowledge-driven generative adversarial network fo
- 8linux下载/解压ImageNet-1k数据集_imagenet1k下载
- 9如何用Python构建一个生产级别的电影推荐系统 - 机器学习手册
- 10基于微信小程序的个人计划时间管理系统设计与实现_wx小程序开发一个时间管理
ElasticSearch技术方案(一)——应用场景分析_es的使用场景
赞
踩
ElasticSearch技术方案
ElasticSearch简介
Elasticsearch,简称 ES 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件。
Lucene本身就可以被认为迄今为止性能最好的一款开源搜索引擎工具包,但是lucene的API相对复杂,需要深厚的搜索理论。很难集成到实际的应用中去。但是ES是采用java语言编写,提供了简单易用的RestFul API,开发者可以使用其简单的RestFul API,开发相关的搜索功能,从而避免lucene的复杂性。
Lucene与ES关系
-
Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
-
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ElasticSearch的特点
-
可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上*,服务小公司*
-
Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;lucene(全文检索),商用的数据分析软件(也是有的),分布式数据库(mycat)
-
对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES,就可以作为生产环境的系统来使用了,数据量不大,操作不是太复杂
-
数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch作为传统数据库的一个扩展
ElasticSearch适用场景概述
使用案例
(1)维基百科,类似百度百科,全文检索,高亮,搜索推荐
(2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
(3)Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
(4)GitHub(开源代码管理),搜索上千亿行代码
(5)电商网站,检索商品
(6)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
(7)商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
(8)BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化
(9)国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
常用场景
Elasticsearch的核心特征是数据搜索与分析。与这两个特征相关的需求都可以考虑使用Elasticsearch,其本身是单纯的,复杂的是具体业务。在不同的业务中,Elasticsearch扮演着不同的角色,也有着不同的实践和优化方法。结合当前的场景,归纳起来主要有三类常见的业务场景(当然ELasticSearch不仅仅只能做这些,只是这些目前比较符合我们的业务场景和需求),分别是ELK日志系统、站内(业务)搜索、数据聚合分析。
站内(业务)搜索
现如今,搜索功能几乎是互联网产品的标配,用于帮助用户快速在产品中找到所需的信息。
实际项目开发实战中,几乎每个系统都会有一个搜索的功能,当搜索做到一定程度时,维护和扩展起来难度就会慢慢变大,所以很多公司都会把搜索单独独立出一个模块,用ElasticSearch等来实现。
基于Elasticsearch,可以快速构建这样的搜索功能。通常是采用DB+Elasticsearch配合的方案,DB负责数据存储,Elasticsearch负责关键词检索。Elasticsearch可以在多维度上检索与关键词相关的数据,并为每个匹配结果生成一个相关度分数。当服务收到搜索请求时,首先根据关键词到Elasticsearch中进行检索,然后根据检索结果去DB中查询信息,并在应用层进行数据整理和排序。
搜索精度的调优是重点,也是最难的一部分。比如,如何建立业务内容的词库,如何进行合理分词建立索引,如何调整搜索权重等等。
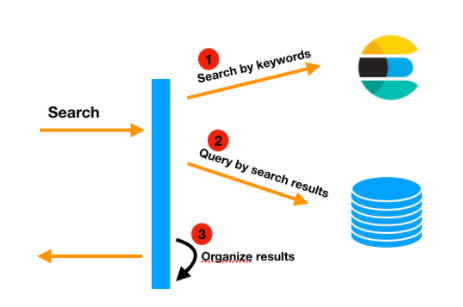
数据聚合分析
海量数据,快速查询
数据的维度统计查询,是当前数据业务的一个主要需求。其配合相应的可视化UI可以帮助用户直观的获取信息、做出决策等。比如,针对网络流量数据,查看上班时间段,员工访问视频类网站的流量占比。
这样的统计查询基本可以归纳为:按照某些条件过滤 --> 针对某个维度分组 --> 统计数据(Sum/Count)。在海量数据下,如何实现快速查询?(亿级以上数据量,秒级查询)
数据库的弊端
首先,诸如MySQL这类关系型数据基本是无法胜任的,其无法突破单机的存储和处理能力限制,而引入分片又会带来应用层面的复杂度。其次,面对这样的海量数据,通常有两个思路:一个是根据需求,制定相应的预计算方案,通过ETL来提前算好相关的统计数据,但是不能很好的应对未知的维度数据。另一个就是不做预计算,Elasticsearch便是其中一个选择,其他方案还有Presto/Spark SQL这样基于内存的Map/Reduce计算框架等。
Elasticsearch强大的搜索与分析聚合能力使其可以很好的适用于这一业务场景。以笔者当前的项目来看,百亿级数据可以做到秒级查询。另外,Elasticsearch的一些特性,诸如alias等可以很好的帮助我们完成一些业务逻辑。
当然,任何事情都不是完美的,选择Elasticsearch得有两个前提:第一,受限于其工作机制,聚合结果可能存在较小的偏差的;第二,数据需要规划好,保持扁平结构,不能有JOIN的需求。
日志分析(ELK)
ELK用来解决Log的集中式管理问题,这样的需求来自于互联网的快速发展,出现越来越多的集群部署与分布式系统,导致服务产生的Log信息分散在不同的机器上,无法有效的检索与统计。
应用服务集群,为了做集中式Log管理,需要有一个Agent负责从每台机器收集信息,送到一个存储系统集中存储(该系统需要具备快速的文本搜索功能),然后通过一个可视化UI来查看和分析信息。
ELK以全家桶的形式为这一问题提供了解决方案,Logstash负责收集、解析数据,Elasticsearch负责存储、检索数据,Kibana提供可视化功能。
当然,这并不意味着ELK必须捆绑使用。一方面,Logstash是基于JRuby编写,在部署和性能上的表现并不能满足所有需求,所以很多人会将其替换为自己编写的数据采集工具。同时Elastic官方也有提供Beats相关轻量级组件,可与Logstash组合使用。另一方面,也有很多人在Kibana的基础上做二次开发,来增强相应的查询功能,集成开源的告警功能等。但是Elasticsearch始终是核心组件,很少有人将其替换掉,源于其强大的搜索功能恰好满足Log的检索需求。有一点建议是,ELK本身已经很好使用,除非有强烈的业务需求,否则没有必要刻意去替换,先考虑用对、用好它。
Elasticsearch在后端的使用分析
场景一:单独使用ElasticSearch作为数据存储
传统项目中,搜索引擎是部署在成熟的数据存储的顶部,以提供快速且相关的搜索能力。这是因为早期的搜索引擎不能提供耐用的存储或其他经常需要的功能,如统计。但Elasticsearch是提供持久存储、统计等多项功能的现代搜索引擎。
所以如果是一个新项目,可以考虑使用Elasticsearch作为唯一的数据存储。
这样的设计优点是足够简单,但是这种场景并不支持包含频繁更新、事务(transaction)的操作。
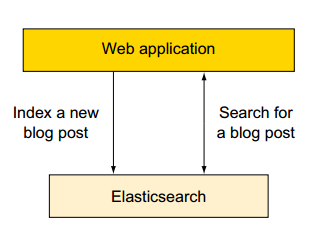
举例如下:新建一个博客系统使用es作为存储。
1)我们可以向ES提交新的博文;
2)使用ES检索、搜索、统计数据。
ES作为存储的优势:
如果一台服务器出现故障时会发生什么?你可以通过复制 数据到不同的服务器以达到容错的目的。
注意:
整体架构设计时,需要我们权衡是否有必要增加额外的存储。
场景二:使用数据库进行存储,ElasticSearch进行搜索和分析
由于ES不能提供存储的所有功能,很多场景下需要和数据库配合使用。
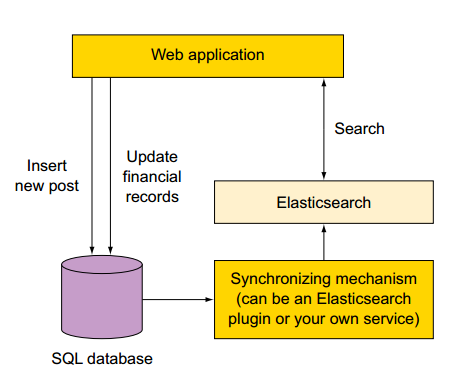
何种情况下可以考虑将ES作为独立的模块集成到原有系统当中?
-
ES对事物和复杂的数据关系支持并不够友好,如果系统中需要上述特征的支持,需要考虑在原有架构、原有存储的基础上的新增ES的支持。
-
如果已经有一个在运行的复杂的系统,需求之一是在现有系统中添加检索服务。一种非常冒险的方式是重构系统以支持ES。而相对安全的方式是:将ES作为新的组件添加到现有系统中。
当然,如果数据库做数据存储,ES做搜索和数据分析,那么不可避免地需要解决一个问题——数据库和ES的数据同步问题。
分析
当然,ES在后端的使用不止是以上两种情况,不同的业务需求可以搭配不同的技术,比如可以使用redis做数据的中间缓存。虽然ES可以实现数据存储,但一般业务需求都比较复杂,事务是不可避免的话题之一,所以更倾向于场景二,也就是使用数据库做数据存储,ES进行搜索和数据分析。
下一篇文章将讲述一下:ElasticSearch如何实现站内搜索的功能?

