
热门标签
热门文章
- 1阿里云X森马 AIGC T恤设计大赛;SD新手入门完全指南;揭秘LLM训练中的数学;LLM高质量阅读清单 | ShowMeAI日报_巨量引擎 ai混剪
- 2Pycharm上运行pyspark报错_为什么在下载了pyspark,在pycharm里还是用不了
- 3解决idea中无法下载源码问题_sources not found for: org.springframework.boot:sp
- 4学习用 Keras 搭建 CNN RNN 等常用神经网络
- 5【前端Vue】——初识Vue.js
- 6uml活动图 各个功能的操作流程和分支_基于UML产品设计
- 7程序员的身体素质真的有这么差么?_程序员身体 虚弱
- 8谷歌aab包在Android 14闪退而apk没问题(targetsdk 34)_targetsdk 34 闪退
- 9Oracle时间戳(timestamp)格式转换_oracle 时间戳
- 10希尔伯特第 13 问题,Kolmogorov–Arnold representation theorem 和通用近似定理(Universal approximation theorem)_kolmogorov-arnold representation theorem
当前位置: article > 正文
【Hive】Hive在调用执行MapReduce进程时报错:FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql._execution执行器玉mapreduce
作者:知新_RL | 2024-05-20 10:45:22
赞
踩
execution执行器玉mapreduce
今天,在测试Hive时,碰到了以下错误:
- hive (default)> INSERT INTO test VALUES ('kuroneko359',20);
- Query ID = root_20231207144941_56661aca-5d0c-40c5-83b3-1631434f25a5
- Total jobs = 3
- Launching Job 1 out of 3
- Number of reduce tasks determined at compile time: 1
- In order to change the average load for a reducer (in bytes):
- set hive.exec.reducers.bytes.per.reducer=<number>
- In order to limit the maximum number of reducers:
- set hive.exec.reducers.max=<number>
- In order to set a constant number of reducers:
- set mapreduce.job.reduces=<number>
- 2023-12-07 14:49:43,919 INFO [bf528afe-a11e-4444-98a7-aad77cef2125 main] client.RMProxy: Connecting to ResourceManager at bigdata1/192.168.72.101:8032
- 2023-12-07 14:49:44,095 INFO [bf528afe-a11e-4444-98a7-aad77cef2125 main] client.RMProxy: Connecting to ResourceManager at bigdata1/192.168.72.101:8032
- Starting Job = job_1701931585546_0001, Tracking URL = http://bigdata1:8088/proxy/application_1701931585546_0001/
- Kill Command = /opt/module/hadoop/bin/mapred job -kill job_1701931585546_0001
- Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
- 2023-12-07 14:49:50,949 Stage-1 map = 0%, reduce = 0%
- Ended Job = job_1701931585546_0001 with errors
- Error during job, obtaining debugging information...
- FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
- MapReduce Jobs Launched:
- Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
- Total MapReduce CPU Time Spent: 0 msec
- hive (default)>

从报错的内容上看,应该是调用MapReduce时出现了错误。
尽管查看日志,也没有明确的指出出现错误的原因: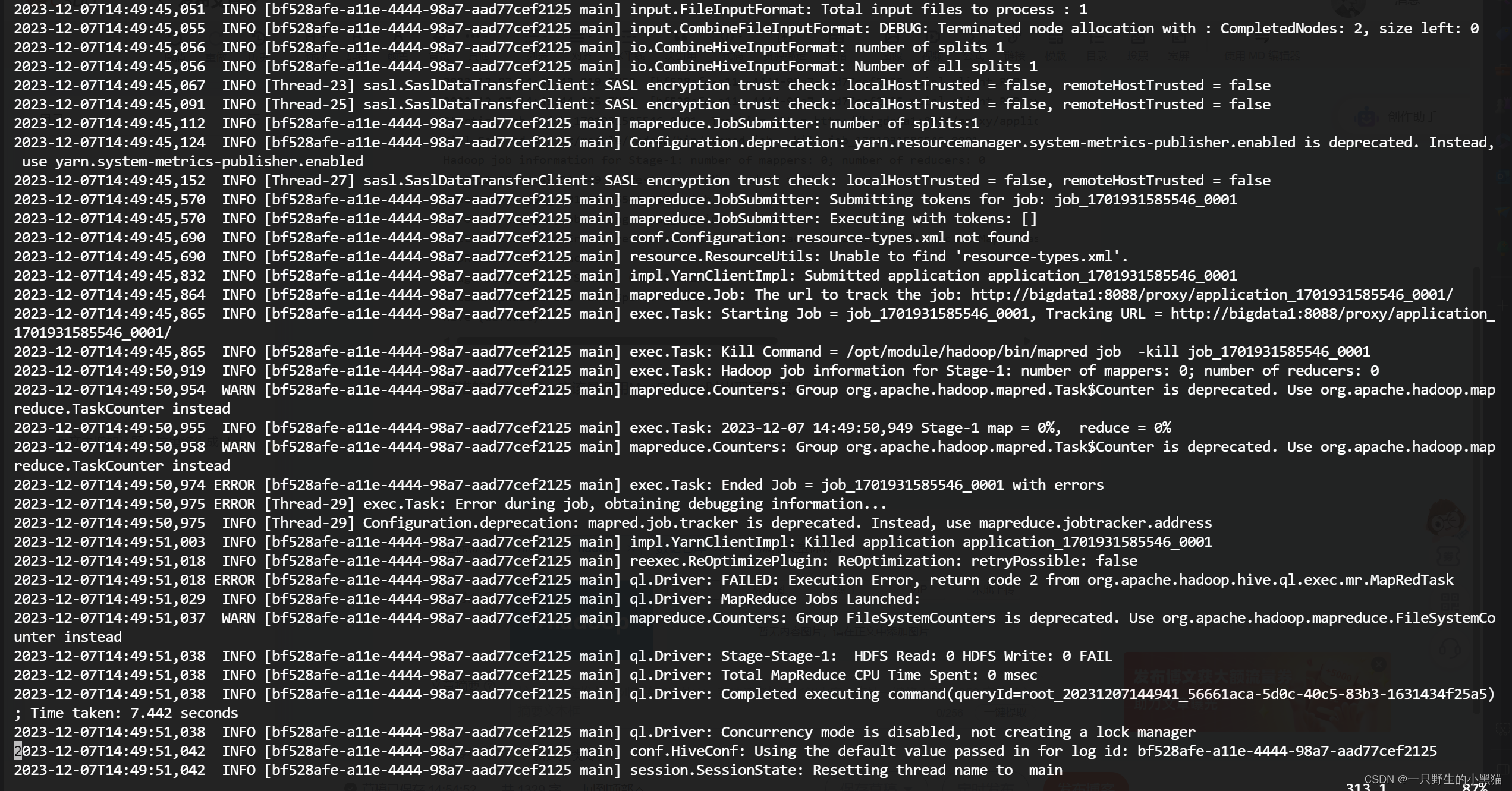
于是,我便想到了用Hadoop来执行MapReduce来测试MapReduce的功能是否正常:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 3 10执行以上命令,发现调用MapReduce时确实出现了问题:
根据程序提供的错误,我们可以得知,是MapReduce找不到Java的位置,导致程序无法正常执行。
解决方法:
在Hadoop的yarn-site.xml中添加JAVA_HOME,添加完之后别忘了分发到其他节点。
再次执行原来的命令,发现又出现了一个新的错误:
解决方法:
在终端中输入:
echo $(hadoop classpath)获取到hadoop classpath,将结果添加到yarn-site.xml中:
- <property>
- <name>yarn.application.classpath</name>
- <value>/opt/module/hadoop/etc/hadoop:/opt/module/hadoop/share/hadoop/common/lib/*:/opt/module/hadoop/share/hadoop/common/*:/opt/module/hadoop/share/hadoop/hdfs:/opt/module/hadoop/share/hadoop/hdfs/lib/*:/opt/module/hadoop/share/hadoop/hdfs/*:/opt/module/hadoop/share/hadoop/mapreduce/lib/*:/opt/module/hadoop/share/hadoop/mapreduce/*:/opt/module/hadoop/share/hadoop/yarn:/opt/module/hadoop/share/hadoop/yarn/lib/*:/opt/module/hadoop/share/hadoop/yarn/*</value>
- </property>
保存并分发yarn-site.xml,之后重启yarn。
再次执行先前使用Hadoop运行MapReduce的程序,发现可以正常执行:
之后进入Hive运行刚才的语句,问题成功解决。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/597358
推荐阅读
相关标签

