
- 1python try里面嵌套try_try catch里面try catch嵌套
- 2计算机经典书籍电子书合集_汇编语言基于linux环境电子版百度网盘
- 3二十三篇:未来数据库革新:AI与云原生的融合之旅
- 4C语言实现数据结构的堆(Heap)_heap伪代码 c
- 5SLAM导航机器人零基础实战系列:(二)ROS入门——9.熟练使用rviz
- 6大语言模型的预训练[3]之Prompt Learning:P_用题库训练大语言模型
- 7Windows下安装HBase_hbase windows安装
- 8java 获取指定日期的年、月、日(Date格式)_java 日期获取年月日
- 9LTP4.0 docker 安装使用说明;ltp工具包使用说明_ltp 4.0
- 10springboot访问请求404的原因_springboot 404
基于深度学习的水果检测与识别系统(Python界面版,YOLOv5实现)_yolo图片识别分类python_fruitdetection 水果识别
赞
踩
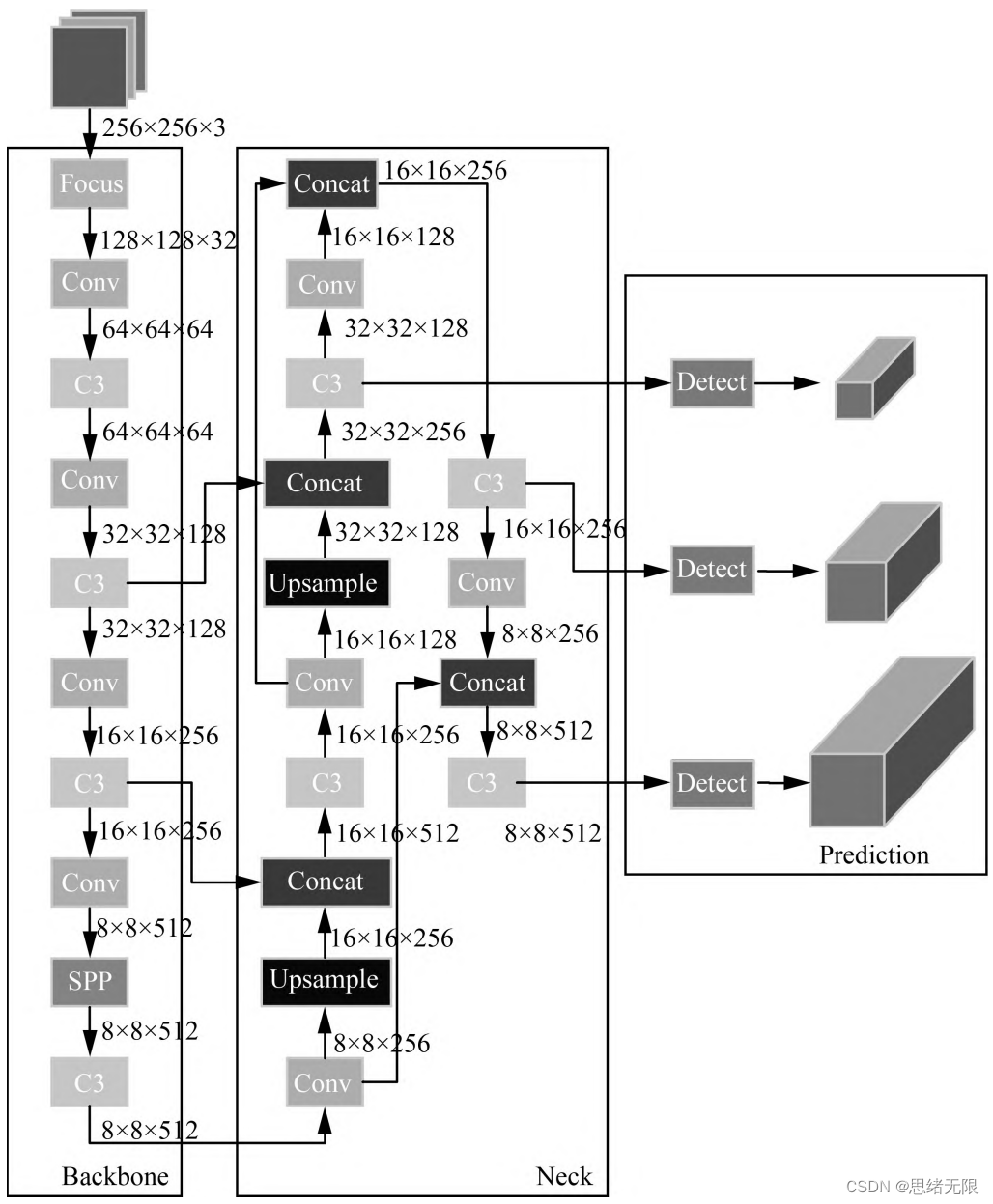
在YOLOv5中,首先将输入图像通过骨干网络进行特征提取,得到一系列特征图。然后,通过对这些特征图进行处理,将其转化为一组检测框和相应的类别概率分数,即每个检测框所属的物体类别以及该物体的置信度。YOLOv5中的特征提取网络使用CSPNet(Cross Stage Partial Network)结构,它将输入特征图分为两部分,一部分通过一系列卷积层进行处理,另一部分直接进行下采样,最后将这两部分特征图进行融合。这种设计使得网络具有更强的非线性表达能力,可以更好地处理目标检测任务中的复杂背景和多样化物体。

在YOLOv5中,每个检测框由其左上角坐标(x,y)、宽度(w)、高度(h)和置信度(confidence)组成。同时,每个检测框还会预测C个类别的概率得分,即分类得分(ci),每个类别的得分之和等于1。因此,每个检测框最终被表示为一个(C+5)维的向量。在训练阶段,YOLOv5使用交叉熵损失函数来优化模型。损失函数由定位损失、置信度损失和分类损失三部分组成,其中定位损失和置信度损失采用了Focal Loss和IoU Loss等优化方法,能够有效地缓解正负样本不平衡和目标尺寸变化等问题。</font
YOLOv5网络结构是由Input、Backbone、Neck、Prediction组成。Yolov5的Input部分是网络的输入端,采用Mosaic数据增强方式,对输入数据随机裁剪,然后进行拼接。Backbone是Yolov5提取特征的网络部分,特征提取能力直接影响整个网络性能。YOLOv5的Backbone相比于之前Yolov4提出了新的Focus结构。Focus结构是将图片进行切片操作,将W(宽)、H(高)信息转移到了通道空间中,使得在没有丢失任何信息的情况下,进行了2倍下采样操作。博主觉得YOLOv5不失为一种目标检测的高性能解决方案,能够以较高的准确率对海洋动物进行分类与定位。当然现在YOLOv6、YOLOv7、YOLOv8等算法也在不断提出和改进,等其代码版本成熟后博主也会再设计本系统的算法,敬请期待。
3. 数据集与预处理

还有Laboro Tomato数据集,也可参考这篇文章Real-time fruit detection using deep neural networks on CPU (RTFD): An edge AI application,包括介绍和算法都可以参考。

本系统使用的水果检测数据集Fruit Detection Dataset,手动标注了包含苹果、香蕉、火龙果、番石榴、橙子、梨、菠萝、释迦果等8个类别的水果,共计3030张图片。该数据集中每个类别的水果都有大量的旋转和不同的光照条件,有助于训练出更加鲁棒的检测模型。本文实验的水果检测识别数据集包含训练集2424张图片,验证集303张图片,测试集303张图片,选取部分数据部分样本数据集如图所示。

由于YOLOv5算法对输入图片大小有限制,需要将所有图片调整为相同的大小。为了在不影响检测精度的情况下尽可能减小图片的失真,我们将所有图片调整为640x640的大小,并保持原有的宽高比例。此外,为了增强模型的泛化能力和鲁棒性,我们还使用了数据增强技术,包括随机旋转、缩放、裁剪和颜色变换等,以扩充数据集并减少过拟合风险。
5. 系统实现
5.1 Python实现
本系统的深度学习模型使用PyTorch实现,基于YOLOv5算法进行目标检测。在训练阶段,我们使用了预训练模型作为初始模型进行训练,然后通过多次迭代优化网络参数,以达到更好的检测性能。在训练过程中,我们采用了学习率衰减和数据增强等技术,以增强模型的泛化能力和鲁棒性。

