
- 1Redis Stream 数据结构实现原理真的很强
- 2算法细节系列(13):买卖股票_算法 当买得越多亏损越多
- 3《算法二》选择排序算法及它的时间复杂度_选择排序的时间复杂度是多少
- 4python pip中的Fatal error in launcher错误及解决_pip fatal error in launcher
- 5CSS盒子模型[盒子模型分为哪几部分?/ 内容区/内边距/边框/边框样式/外边距/]_css盒子模型由哪几部分组成盒子的宽度是由哪些内容组成
- 6com.rabbitmq.client.ShutdownSignalException_shutdownsingleexception
- 7基于微信小程序高校学校校园系统 (后台java+Springboot框架)答辩常规问题和如何回答(答辩指导)毕设毕业设计_springboot答辩问题及回答
- 8真的醉了!程序员必备技能:时间复杂度与空间复杂度的计算_cpu计算能力 mhz 时间复杂度
- 9旋翼无人机常用仿真工具_无人机仿真软件
- 10FTP协议——LightFTP安装(Linux)
阿里云部署ACGC - 文本生视频_阿里acgc
赞
踩
本文介绍如何使用GPU云服务器搭建Stable Diffusion模型,并基于ModelScope框架,实现使用文本生成视频。
背景信息
自多态模型GPT-4发布后,AIGC(AI Generated Content,AI生成内容)时代正扑面而来,从单一的文字文本,演化到更丰富的图片、视频、音频、3D模型等。
本文基于阿里云GPU服务器和文本生成视频模型,采用Unet3D结构,通过从纯高斯噪声视频中,迭代去噪的过程,实现文本生成视频功能。
重要
-
阿里云不对第三方模型“文本生成视频大模型”的合法性、安全性、准确性进行任何保证,阿里云不对由此引发的任何损害承担责任。关于模型的详细信息,请参见文本生成视频大模型。
-
您应自觉遵守第三方模型的用户协议、使用规范和相关法律法规,并就使用第三方模型的合法性、合规性自行承担相关责任。
操作步骤
创建ECS实例
-
前往实例创建页。
-
按照界面提示完成参数配置,创建一台ECS实例。
需要注意的参数如下,其他参数的配置,请参见自定义购买实例。
-
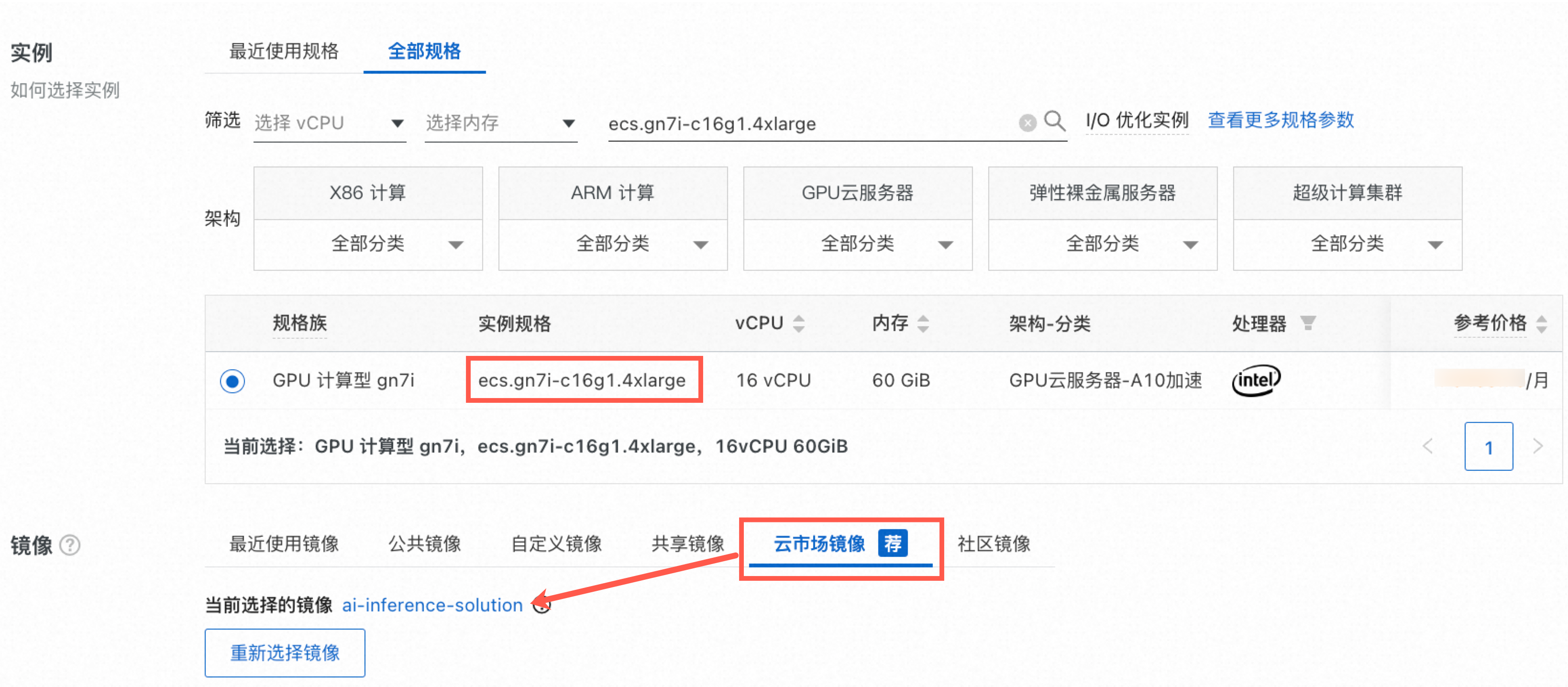
实例:选择实例规格为ecs.gn7i-c16g1.4xlarge。
-
镜像:本文使用已部署好推理所需环境的云市场镜像,名称为ai-inference-solution。
-
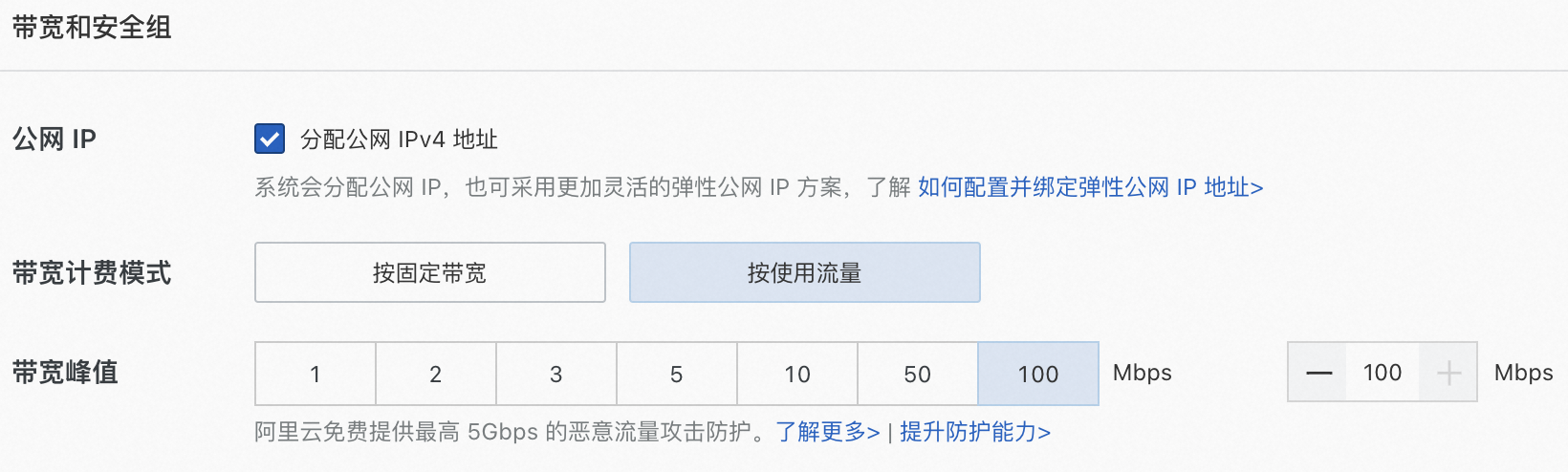
公网IP:选中分配公网IPv4地址,带宽计费模式选择按使用流量,带宽峰值设置为100 Mbps,以加快模型下载速度。
-
-
添加安全组规则。
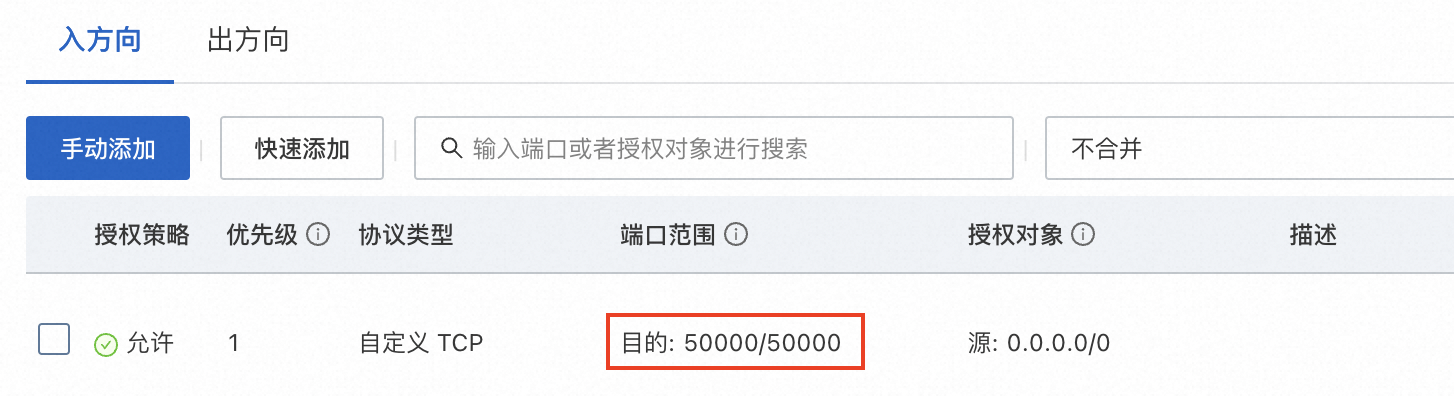
在ECS实例安全组的入方向添加安全组规则并放行50000端口。具体操作,请参见添加安全组规则。
-
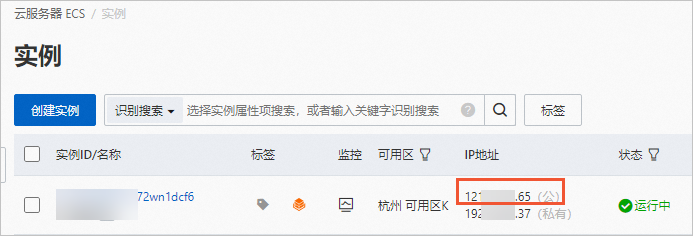
创建完成后,在ECS实例页面,获取公网IP地址。
说明公网IP地址用于生成图片测试时访问WebUI服务。
下载并配置模型
-
使用root用户远程连接ECS实例。
该市场镜像中,运行环境及模型都安装在
/root目录下,连接实例时需使用root用户。具体操作,请参见通过密码或密钥认证登录Linux实例。 -
执行如下命令,下载v1-5-pruned-emaonly.safetensors模型。
- cd ~/stable-diffusion-webui/models/Stable-diffusion
- wget "https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors"
当显示如下图所示的回显信息时,说明已下载完成。
-
为Nginx添加用户登录验证。
该镜像预装了Nginx软件,用于登录鉴权,以防止非授权用户登录。
-
执行如下命令,创建登录用户和密码。
说明${UserName}请替换为您自定义的用户名,例如admin;'${Password}'请替换为您自定义的密码,例如ECS@test1234。htpasswd -bc /etc/nginx/password ${UserName} '${Password}' -
执行如下命令,重启Ngnix。
systemctl restart nginx -
执行如下命令,查看Ngnix状态。
systemctl status nginx当显示如下图所示的回显信息时,说明Ngnix处于运行中。
-
执行如下命令,设置Ngnix开机自启动。
systemctl enable nginx
-
文本生成视频
-
使用root用户远程连接ECS实例。
该市场镜像中,运行环境及模型都安装在
/root目录下,连接实例时需使用root用户。具体操作,请参见通过密码或密钥认证登录Linux实例。 -
执行如下命令,切换conda环境到modelscope中。
conda activate modelscope -
执行如下命令,切换到
scripts目录。cd /root/scripts -
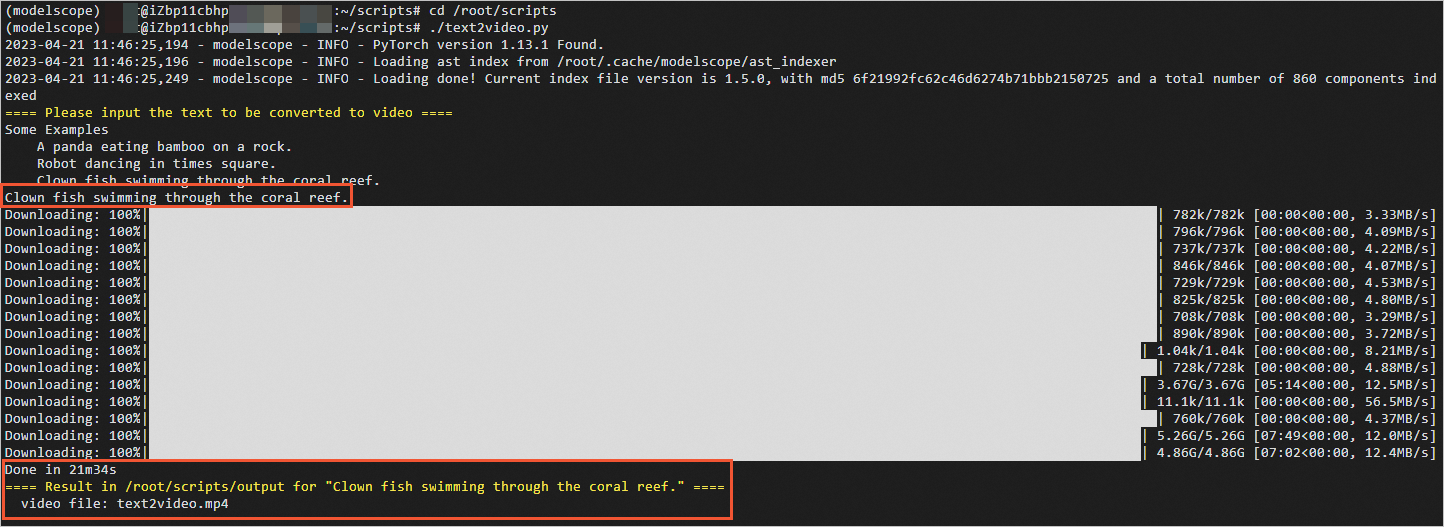
执行如下脚本,生成视频。
./text2video.py运行过程中,请根据提示输入英文文本,例如
说明Clown fish swimming through the coral reef.。首次执行脚本时,会通过公网自动下载所需模型库,100 Mbps带宽下载时间大约为20分钟,请耐心等待。
-
文件存放:生成的text2video.mp4视频文件存放在
/root/scripts/output目录中。 -
文件下载:在左上角顶部菜单栏,选择文件> 打开新文件树,找到目标文件后右键,单击下载文件即可。本文生成示例如下:
-


