
- 1python查找两个数组中相同的元素_找出两个数组的相同元素,最优算法?
- 2vivado CLOCK
- 3Selenium自动化测试中常见的异常详解_move target out of bounds
- 4解决ERROR:Can‘t get master address from Zookeeper;znode data == null报错_can't get master address from
- 5【深度学习】名词解释_名词解释深度学习
- 6pytorch实现attention_用自注意力增强卷积:这是新老两代神经网络的对话(附实现)...
- 7存储器粗解
- 8动态规划中的股票问题全解析_动态规划求解买股票问题
- 9nginx实现内外网同时访问
- 10PyPI 镜像使用帮助_pypl 镜像使用帮助
概念深奥看不懂?一文读懂元学习原理
赞
踩
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达选自 | fastforwardlabs
作者 | Shioulin and Nisha
据说元学习是一种学习如何学习的方法,那么它到底和一般的机器学习有什么不同呢?从学习某个任务到学习一大堆任务,本文将解答你想知道的元学习原理。
从手机应用的内容推荐,到寻找暗物质,机器学习算法已经改变了人们的生活和工作方式。但是,传统机器学习算法很大程度上依赖标于特定的标注数据,这一定程度上限制了在某些场景下的应用。
近来,一些研究提出了解决方法,如使用预训练模型的迁移学习。但是在一些场景中,缺乏可提供预训练的原始数据,场景中的数据可能和预训练使用的数据不尽相同,单类别的样本也可能太少,例如罕见疾病的诊断或稀有物种的归类等。因此,很多研究者开始关注元学习(Meta-Learning)算法,它可以解决极少样本情况下的模型训练问题。这种新方法被认为是通向一般人工智能的重要一步。
本文是一篇元学习的原理扫盲博客,作者通过一个简单的图像分类案例,介绍了元学习背后的逻辑,感兴趣的朋友可以通过这篇文章,从概念上理解元学习和传统机器学习算法的不同。
元学习是什么?
主动学习可以帮助我们更聪明地对特定数据创建标签。如果恰当得应用这一技巧,与一般的模型相比可以使用更少的数据进行训练。而在元学习的领域,我们不再关注获取标签。与之相反,我们尝试让机器从少量的数据中更快的学习。
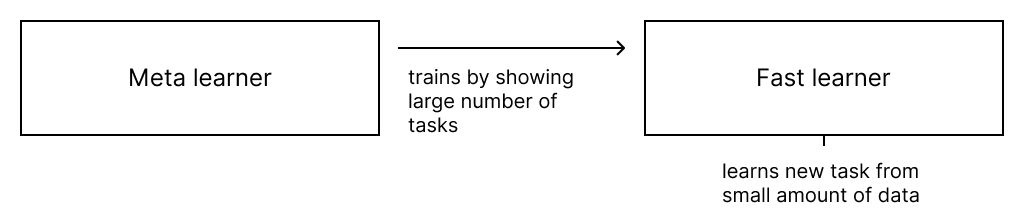
图 1:元学习的概念框架。元学习从大量任务训练模型,并通过少量数据在新任务中更快地学习。
训练元学习器需要一个学习器和一个训练器。学习器(模型)的目标是快速利用少量数据学习新任务。因此,学习器有时也被称为快速学习器(fast learner)。「任务」在这里是指任何监督学习问题,比如预测少量样本的类别。这个学习器可以用元学习器训练,从而能从大量其他类型的任务中学习。学习过程主要即元学习器不断向学习器展示成百上千种任务,最终学习器就会学得众多任务的知识。学习后,需要经过两个阶段:第一个阶段关注从每个任务中快速获取知识;在第二阶段(学习器)缓慢将信息从所有任务中取出并消化。
我们用一个实例来说明一下。例如,我们的目标是训练一个将图片分类到 4 个类别(猫、熊、鱼和鸟)的分类器,但是每个类别只有少量的带标签数据。为了实现这一目标,我们首先定义一个学习器,这个学习器的目标即预测二分类问题,且每个类别只有三个样本。我们然后定义一个元学习器,元学习器的工作是向学习器展示任意两个类别的样本组合,且每个类别只有三个样本。
和一般的深度学习将大量标注数据分为不同的 Batch 不一样,元学习的训练数据表现为集合(set)的形式。首先,我们需要一组样本,或者被称为「支持集」(support set),它由一些属于样本子集的图片构成。例如,在我们的例子中,支持集应该由三张猫和三张熊的图片组成。我们同时需要指定被分类图片,它们组成了一个「目标集」(target set)。在我们的例子中,目标集应该是一些猫或者熊的图片。支持集和目标集共同构成了一个训练 episode。元学习器学习各种各样的训练集,并将它们一个训练集一个训练集的展示给学习器。学习器的工作则是尝试将每一个训练集中的目标集图片正确的分类。

图 2:元学习的训练集。在例子中,需要对猫、熊、鱼和鸟一共 4 类图片进行分类,但每次构建训练集时,只使用这些分类的子集,并将训练集分为支持集和目标集。第一个训练集的支持集是猫和鱼的图片(3 张),目标集是鱼和猫各 1 张图片,它们都需要进行分类。第二个训练集中,使用猫和熊的图片作为支持集,目标集同样是猫和熊的图片。多种类的训练集组合(猫+鱼,猫+熊,熊+鱼)不仅可以使快速学习器学习每一个子集的分类,还可以使它抽取类别之间的共性和特性。
元学习领域的论文经常使用 k 和 N,k 代表了快速学习器学习的机会,N 代表了快速学习器被要求分类的数量。在我们的例子中,N = 2,k = 3,说明这是一个「两步三次」(two-way three-shot)的元学习设置。
聪明的读者可能已经意识到,虽然我们的目标是训练一个可以区分四个类别的分类器(猫,熊,鱼和鸟),但是每个训练集只有两种类别,这是元学习的一个特点。元学习的训练过程,最初是由 Oriol Vinyals 在他的匹配网络(matching networks)论文(链接:https://arxiv.org/abs/1606.04080)中提出的,其基于的原则是训练和测试条件必须匹配。
我们不向快速学习器一次性展示所有类别的原因是因为,当我们在少数几个类别中只展示一些图片时,我们希望模型能够正确的预测结果(在推断时)。另外,并不是所有的类别都会被用于训练集。在我们的例子中,我们可能只使用三类,并希望模型能够准确预测最后一个类别。元学习器可以实现这一点,因为它可以训练并泛化到其他数据集上。每次只给快速学习器展示一个训练集的数据,它只能获得所有类别中一个小子集。元学习器通过多次循环训练集,每次给快速学习器一个不同的子集。最后,快速学习器不仅可以快速给每个小子集分类,它也可以从所有类别中抽取他们的共性和各自的特性。
分类中的相似性
如果我们有一些图片样本,并需要对新图像进行分类,我们本能的会对比新图片和样本,寻找和新图片最相似的样本,并将这个样本的类别作为新图片的类别。为了对新的(目标)图片进行分类,基于已有的样本(支持集),首先寻找和新图片最相似的样本,然后使用这个样本的类别进行预测。
在匹配网络中,图片被转换为嵌入向量,它可以被认为是一组特征(线和边)或图片的密集型表示。匹配网络的目标是,对转换为嵌入向量的图片,寻找与其最相似的支持集合图片标签。
当一个目标集合的图片被分类到一个未见过的类别,匹配网络将其视为和其他图片一样的样本。新图片将和最相似图片归于一个支持集,并使用这个类别用于预测。
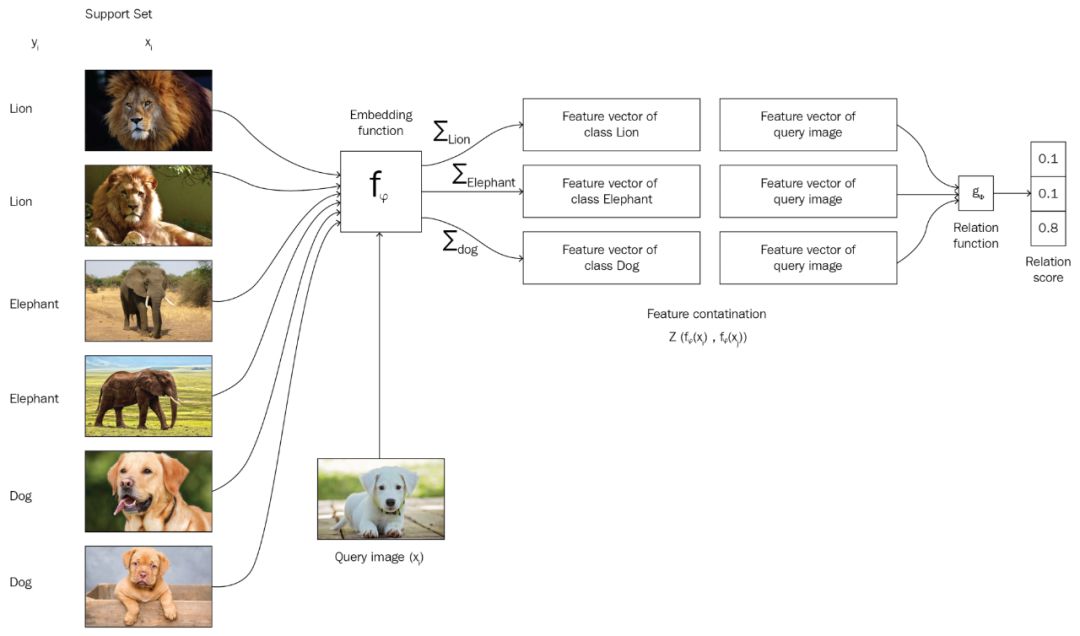
图 3:匹配网络的工作原理。支持集合中有狮子、大象和狗三类,而待分类的图片类别未知。通过嵌入函数将每一个类别(狮子、大象、狗和未知图片)转换为嵌入向量,并使用关系函数(如 Softmax)计算已知分类和未知分类的相似度。图片来自 Hands on Meta Learning with Python,chapter 4。
内部表示
实际上,之前的方法利用了基于嵌入的距离向量,去对比新图片和支持集中的样本图片。这个模型可以使我们从概率的角度,建立新图片和已有样本图片的联系。训练后,我们获得了一个可以生成捕捉了图片中的特性和共性的图片表示(通过嵌入向量)。这说明了另一种根据少量训练数据就可以快速训练机器的方法。
我们首先要寻找可以很容易适应新任务的内部表示,因此模型可以根据少量的数据点快速适应新任务。在深度学习的背景下,内部表示可以被视为神经网络的一组参数。一个好的内部表示可以广泛适应多种任务。对表示的微调可以使模型在新任务中工作良好,这些调整经常出现在迁移学习中。在使用迁移学习的特征抽取例子中,训练网络只需要使用少量的新数据点,并只调整网络的最后一层的权重。使用新数据点对整个模型(或参数)进行重新训练也是可能的,这一过程也被称作微调(fine-tuning)。
但是这种神奇的内部表示从何而来?在迁移学习中,这种表示是预训练神经网络在大量数据中训练得到。初始化后,新的小数据集会重新训练神经网络,既可以是整体的,可能是局部的(只有最后一层)。获得这种表示的另一种方法是采用一组初始的神经网络参数(参考链接:https://arxiv.org/abs/1703.03400)。当这个网络由正确的参数进行初始化,它就可以快而简单地使用少量新数据进行调整。这说明,初始的一组神经网络参数可能对新任务非常敏感,小的参数变化会极大提高损失函数在任何任务上的表现。
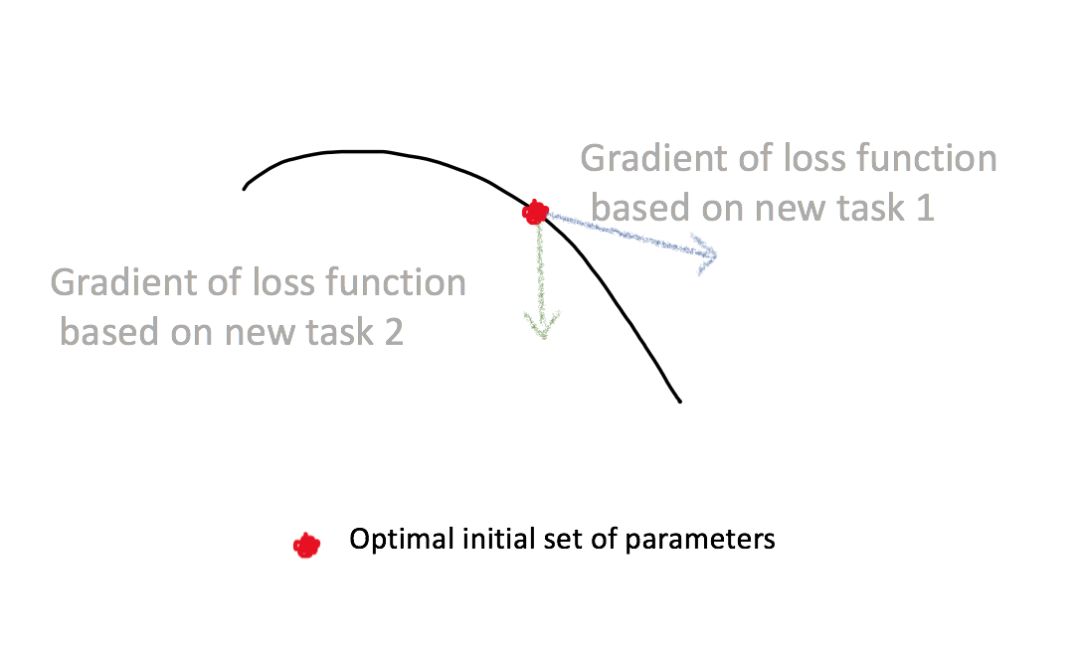
图 4:损失函数在不同任务上的梯度。当初始化一个理想的神经网络后,损失函数的梯度会根据新任务发生变化。
这一方法的基本思路是:我们首先训练一个具有初始参数的模型,即在新任务中使用一个 eposide 的数据进行训练。在训练中,初始的参数被更新。模型的目标是寻找一组初始的参数,在新任务的评价中,可以使损失在使用新参数的时候很小。
这一思路是由迁移学习启发而来,但是迁移学习需要一定数量的数据集,所以在数据集非常小或在和预训练数据非常不同的数据集上效果不佳。元学习中的优化策略则是:优化一组初始参数,或优化一个可以快速在每个任务上表现良好的模型,尝试用系统性的方法去学习一种在各种任务中都非常优秀的初始化参数。
元学习现状总结
元学习被认为是可行的,因为它研究了如何从有限带标签数据中学习的问题,尽管元学习需要不同的数据组合模式。在传统的机器学习问题中,我们关注获取一个类别中大量的样本。在元学习中,我们的关注点转向收集许多种类的任务。间接的,这说明我们需要收集许多不同类别的数据。
在我们的例子中,我们使用了四个分类(猫、熊、鱼和鸟)并定义了一个在每一类只提供三个样本的情况下,做二分类的情况。这提供了 6 个(从 4 个样本中选择 2 个)不同的任务,而且这些显然是不够的。因此,在元学习中,尽管我们不需要很多猫的样本,我们确实需要很多不同种类动物的样本。进一步的,在推断中,也需要构建支持集合和目标集合,这是一种不同的数据需求(或限制)。
很多情况下这种成本是比较高的,甚至在研究中,数据集只能被限制在 Omniglot 和 miniImagenet 中。Omniglot 数据集有一共 1623 个手写字母,每个字母有 20 个样本。在 miniImagenet 数据集中,则有 100 个来自 ImageNet 的数据集,每个有 600 个样本。
元学习是一个快速发展的领域,但是它不会被单一的算法主宰。目前最可行的一类算法似乎是基于优化的方法:这些方法来自迁移学习,并且可能会被快速采用。我们希望在相关算法变得成熟后,元学习能够(在领域内)更加的重要,尤其是在商品分类或罕见疾病的分类任务上。在这些任务中,数据分布在多个类别下,但是每一个类别可能只有一些样本。
参考资料
原文地址:https://blog.fastforwardlabs.com/2019/05/22/metalearners-learning-how-to-learn.html
从零开始,了解元学习(附 Pytorch 代码):https://www.jiqizhixin.com/articles/meta-learning-intro
Hands on Meta Learning with Python:https://github.com/sudharsan13296/Hands-On-Meta-Learning-With-Python
这是一本正在 Github 上更新的元学习 Python 教程书,介绍了包括 Siamese、Prototype Network、Matching Network、Model Agnostic Meta Learning 等的原理和 Kears 或 Tensroflow 的具体实现。
好消息!
小白学视觉知识星球
开始面向外开放啦
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

