
- 1【SVM时序预测】基于matlab粒子群算法优化支持向量机PSO-SVM期贷时序数据预测【含Matlab源码 2289期】_svm时序融合
- 2python jieba load_userdict 不起效果_jiebaloaduserdict 不生效
- 3使用环绕增强注解解决防重复提交及防重放安全问题_防重放和防重复的区别
- 4用 Python 创作酷炫的几何图形
- 5华为Mate30怎么解账号锁被机主锁定激活锁ID账户锁定强制解除教程_华为mate30怎么改用户锁定
- 6新魔百盒CM201-1_YS_卡刷固件包_cm201-1魔百盒刷机包
- 7Thinkphp3.2的redis配置文件_thinkphp3.2 redis配置参数
- 8多路复用技术_多路复用器用单片机怎么接
- 9Android应用的闪退(crash)分析_com.android.launcher3/u0a121 (adj 100): crash
- 10C# 操作IIS类_c#判断iis站点是否存在
NLP入门:word2vec & self-attention & transformer & diffusion的技术演变_word2vec和自注意
赞
踩
这一段时间大模型的相关进展如火如荼,吸引了很多人的目光;本文从nlp领域入门的角度来总结相关的技术路线演变路线。
1、introduction
自然语言处理(Natural Language Processing),简称NLP,是通过统计学、数学模型、机器学习等相关技术研究人类语言的特征,对其进行数学的表示,并基于这种表示进行计算使其可以处理一些和人类语言相关的事务,模拟人类使用语言的状态。
在人类的思想领域中,针对人的认识,一直以来都有两种倾向。一种是认为人类的各种知识是天然具有逻辑合理性的,因此在建构知识时,应当自顶向下的搭建逻辑的结构,获得对知识的把握;而另一种则认为人类的知识是归纳在世界中的经验一点一点形成的,我们认为是逻辑和理性的认知,也是在经验中被我们归纳确认的,因此人类的知识需要从大量的经验中去归纳总结,这是一个自底向上的过程。从哲学史的角度看来,这两者就是所谓的唯理论和经验论的区别。这两种倾向被带入到具体学科领域中,就会得到两套相反的方法。
之所以要提到这个问题,是因为在自然语言处理领域,也曾有偏向规则的(唯理论的)和偏向统计的(经验论)的两种方法。基于规则和语法的自然语言处理算法曾经一度是NLP领域的主流,很多研究者都基于建构一个更合理的语言规则的思路来推进算法对于人类语言的处理能力。现如今,这一主流已经被基于统计学的方法所取代。目前较为流行的BERT、CLIP及类似算法本质上都是基于对大量语料的训练(实际上就是一种更高级的统计分析)得到的。这种基于神经网络训练的方法得到的模型已经具有了较强的人类语言处理能力。
2、词的向量化
在进入正文之前,我们先提出这样一个问题,一个文本,经过分词之后,送入某一个自然语言处理模型之前该如何表示?例如,“人/如果/没用/梦想/,/跟/咸鱼/还有/什么/差别”,向机器学习模型直接输入字符串并不便于模型进行计算和比较,但是对文本进行向量化的表示,也就是由字符串转换为向量可以帮助我们获得这样的能力。
顺便一提,分词领域现在也是风起云涌,多家分词插件号称要做最好的 Python 中文分词组件。以热门的jieba、pku_seg等为例:jieba项目目前的github star数已经达到24k,HanLP star数20k、ansj_seg star数5.6k、pkuseg-python star数5k。就目前而言:jieba分词已经稳居中文分词领域c位。
2.1 one-hot的词向量模型
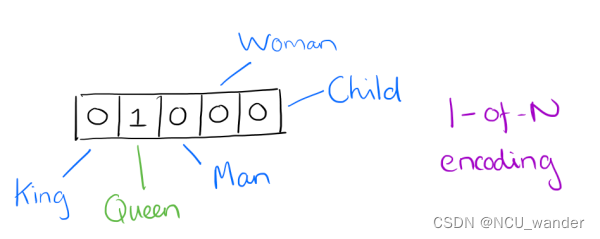
词袋模型把文本看成是一个装着词的袋子,对这个袋子中包含的所有此词汇采用One-Hot编码,每个词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置置为1。比如我们有下面的5个词组成的词汇表:
2.2 Word2vec 词向量模型
Word2Vec是google的Mikolov在2013年推出的一个NLP工具,由论文Exploiting Similarities among Languages for Machine Translation提出,之所以论文和工具的名称不一致,是因为Google论文开源的Git代码仓库名字就叫做“Word2Vec“。它的特点是能够将单词转化为向量来表示,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。
Word2Vec 的训练模型本质上是只具有一个隐含层的神经元网络,如下图所示:
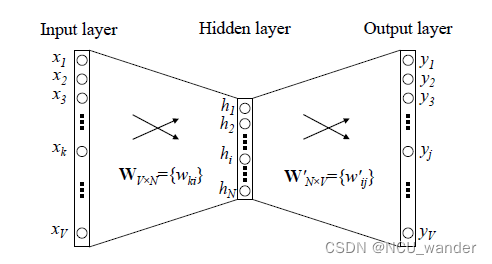
W V ⋅ N W_{V\cdot N} WV⋅N,便是每一个词的采用Distributed Representation的词向量。比如上图中 Xi 单词的Word embedding后的向量便是权重矩阵W的第i行的转置。这样我们就把原本维数为V的词向量变成了维数为N的词向量(一般而言N远小于V,V的大小就是词袋容量大小),并且词向量间保留了一定的相关关系。
Google在Word2Vec的论文中提出了CBOW和Skip-gram两种模型,CBOW适合于数据集较小的情况,而Skip-Gram在大型语料中表现更好。其中CBOW使用围绕目标单词的其他单词(语境)作为输入,在映射层做加权处理后输出目标单词。与CBOW根据语境预测目标单词不同,Skip-gram根据当前单词预测语境下其他单词。假如我们有一个句子“There is an apple on the table”作为训练数据,CBOW的输入为(is,an,on,the),输出为apple。而Skip-gram的输入为apple,输出为(is,an,on,the)。
2.2.1 Continuous Bag of Words(CBOW)
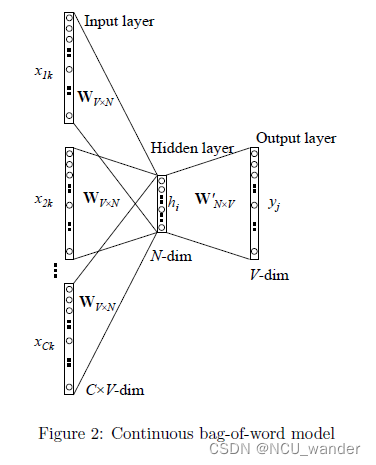
2、初始化一个权重矩阵 W V ⋅ N W_{V\cdot N} WV⋅N ,然后用所有输入的One-Hot编码词向量左乘该矩阵,得到维数为N的向量 ( w 1 , w 2 , ⋅ ⋅ ⋅ w n ) \left (w _{1} , w _{2}, \cdot \cdot \cdot w _{n}\right ) (w1,w2,⋅⋅⋅wn) ,这里的N由自己根据任务需要设置。
3、将所得的向量 ( w 1 , w 2 , ⋅ ⋅ ⋅ w n ) \left (w _{1} , w _{2}, \cdot \cdot \cdot w _{n}\right ) (w1,w2,⋅⋅⋅wn) 相加求平均作为隐藏层向量h。
4、初始化另一个权重矩阵 W V ⋅ N ′ W^{'}_{V\cdot N} WV⋅N′,用隐藏层向量h左乘 ,再经激活函数处理得到V维的向量y,y的每一个元素代表相对应的每个单词的概率分布。
5、y中概率最大的元素所指示的单词为预测出的中间词(target word)与true label的One-Hot编码词向量做比较,误差越小越好(根据误差更新两个权重矩阵)
在训练前需要定义好损失函数(一般为交叉熵代价函数),采用梯度下降算法更新W和W’。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的Distributed Representation表示的词向量,也叫做word embedding。因为One-Hot编码词向量中只有一个元素为1,其他都为0,所以第i个词向量乘以矩阵W得到的就是矩阵的第i行,所以这个矩阵也叫做look up table,有了look up table就可以免去训练过程,直接查表得到单词的词向量了。
2.2.2 Skip-gram
这部分感兴趣的自行了解,再次不进行赘述。
2.2.3 算法改进
前面部分介绍的简化版Word2Vec过程实际上是为了便于大家理解而概括出来的。这个理想的模型当中存在一些无法回避的问题,比如输出的部分是一个50000维的One-Hot向量,因此数据经过网络后应该得到的也是一个50000维的向量,对这个输出向量进行Softmax计算所需的工作量将是一个天文数字。
Google论文里真实实现的Word2Vec对模型提出了两种改进思路,即Hierarchical Softmax模型和Negative Sampling模型。Hierarchical Softmax是用输出值的霍夫曼编码代替原本的One-Hot向量,用霍夫曼树替代Softmax的计算过程。Negative Sampling(简称NEG)使用随机采用替代Softmax计算概率,它是另一种更严谨的抽样模型NCE的简化版本。
3、多头注意力机制与Temperature
3.1 多头注意力机制
多头注意力机制起源于Google的论文《Attention is all you need》,之前在李沐的论中阅读中有看过,但是第一次涉略似懂非懂,如今因为大模型的原因重新涉略,果然温故而知新,孔子诚不我欺。
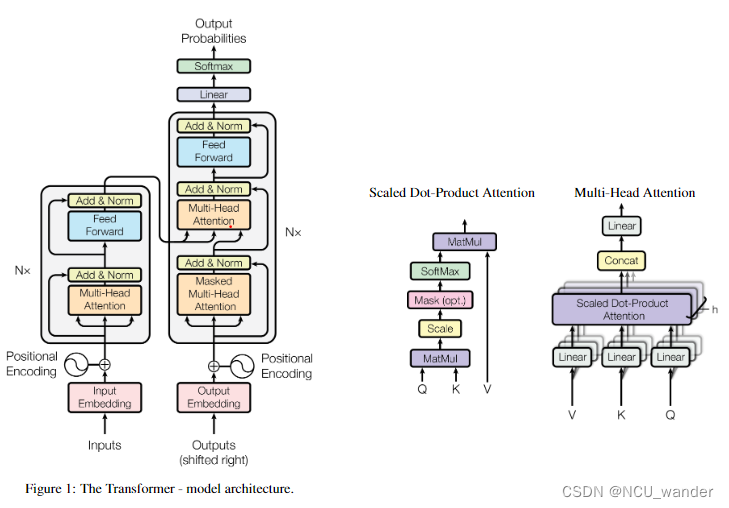
图片的来源是论文原文,可以看出scaled-dot-product-attention到multi-head-attention最后才到transformer的结构,整体上层层递进还是非常明晰的。inputs经过word2vec之后就成为词向量;词在语句中是有位置顺序的,因此需要加上positional encoding部分,通过position encoding添加词语的位置信息。
根据沐神的讲解,原论文中的scaled-dot-product-attention的结构中作为输入层的Q K V其实就是input的输入向量,Query=Key=Value=input。在做计算的过程中,序列中的某一个词语以自身向量作为query,与整个序列其他语句的keys逐个进行点乘;点乘的结果可以用来反应query与keys之间的相似度,毫无疑问他会与自身的key点乘结果最大,这样的结果也是符合常识的。将query与整个序列的keys的点乘结果经过softmax转化为和为1的权重值,这些权重值可以用来表明这个词语与序列中其他词语的相关性关系;将此权重乘上序列的Values就得到最终的attention结果了。
计算过程可以参考:NLP学习—21.自注意力机制(Self-Attention)与Transformer详解,配置了较为精美的插图,便于理解具体的计算过程。
注意一下:
1、Q、K、V可以来自input embedding的线性变化,每一个词向量,都有自己的QKV。通过矩阵变换而来,矩阵可以学习得到。
2、multi-head self-attention 与self-attention 的区别在于可以有多组embedding的线性变化,从而习得多种多样的隐性空间的变换,获得尽可能全面的对于input内在规律的表征。
3.2 Temperature
生成式预训练模型通常使用 Transformer 架构,并通过大量文本数据进行预训练。模型学习语言的规律和模式,从而能够根据给定的上下文生成新的文本。在生成文本时,模型会为每个可能的单词分配一个概率,这个概率反映了模型认为该单词在给定上下文中出现的可能性。生成过程通常使用贪婪搜索、集束搜索(Beam Search)或者 Top-K 采样等策略。
Temperature 参数主要与采样策略有关。在基于概率的采样过程中,Temperature 参数用于调整模型输出的多样性。具体来说,Temperature 是一个正数,用于平滑模型输出的概率分布。
首先我们明确softmax的计算公式:
import numpy as np
def exp_tem(x,tau):
return np.exp(x/tau)/sum(np.exp(x/tau))
print(exp_tem(np.array([1,2,3]),2))
#[0.18632372 0.30719589 0.50648039]
print(exp_tem(np.array([1,2,3]),1))
#[0.09003057 0.24472847 0.66524096]
print(exp_tem(np.array([1,2,3]),0.5))
#[0.01587624 0.11731043 0.86681333]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
解释:tau越大,则x/tau越小,则exp(x/tau)越小,则此时值越接近exp函数的左端,值非常接近1;也就是原始x之前的差异在exp函数之后中和冲淡。在概率抉择的过程中增加了不同x的抉择概率;繁殖来说tau越小,则x之间的差异被放大,在概率抉择的过程中使得原先偏向的x被选择的概率大大增加。
Temperature 参数对生成文本的质量和多样性有显著影响:
当 Temperature 较低时(如 0.1 或 0.2),模型倾向于选择具有较高概率的单词,生成的文本较为连贯和准确,但可能显得过于保守,缺乏创造性和多样性。
当 Temperature 较高时(如 0.8 或 1.0),模型会更倾向于选择概率较低的单词,生成的文本具有较高的多样性和创造性,但可能牺牲了一定的连贯性和准确性。
当 Temperature 接近 0 时,模型几乎总是选择概率最高的单词,生成的文本非常保守,可能导致重复和循环。
在实际应用中,温度参数通常需要根据具体场景进行调整。例如,在机器翻译中,温度参数可以用于调整翻译结果的多样性和准确性。如果我们希望翻译结果更加准确,我们可以将温度参数设置为较低的值,这将使翻译结果更加精确。相反,如果我们希望翻译结果更加自然和流畅,我们可以将温度参数设置为较高的值,这将使翻译结果更加多样化和有趣。
4、Diffusion
如今AIGC主要是基于扩散模型,扩散模型的原理类似给图片去噪,通过学习给一张图片去噪的过程来理解有意义的图像是如何生成,因此扩散模型生成的图片相比 GAN或者VAE模型精度更高,更符合人类视觉和审美逻辑,同时随着样本数量和深度学习时长的累积,扩散模型展现出对艺术表达风格较好的模仿能力。当然吃水不忘挖井人,在Diffusion大获成功的今天我们也不能忘记GAN和VAE曾经做出的杰出贡献。
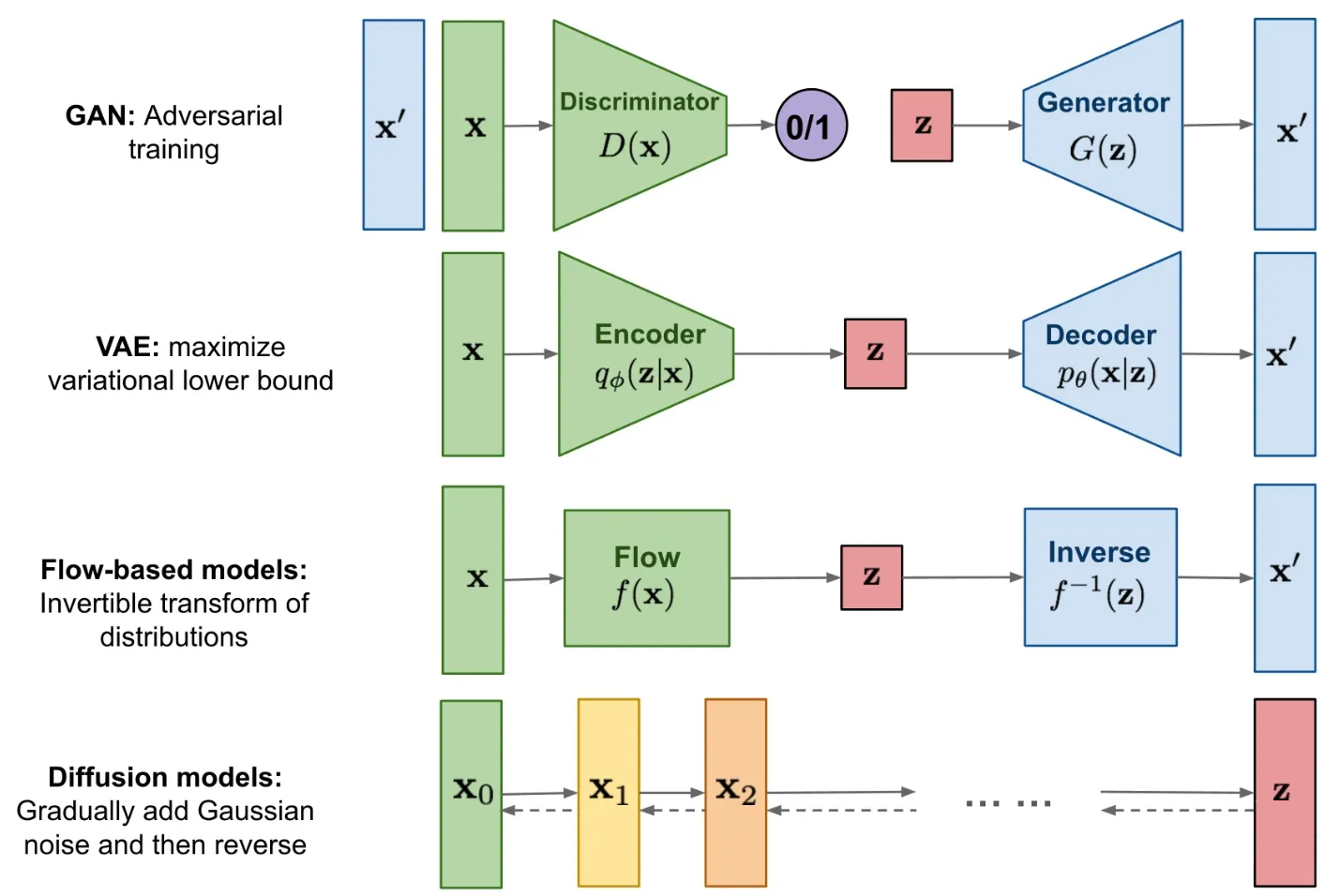
GAN模型通过使得生成器(Generator)生成的图片尽可能去逼近真实图片,从而达到以假乱真的目的,本质上还是去生成和真实图片接近的新图片,因此GAN生成图片的能力受到训练的真实样本的制约。而DDPM是拟合整个从真实图片到随机高斯噪声的过程,再通过反向过程生成新的图片,本身突破了groundtruth对模型生成能力的约束,和GAN有本质的区别。
基于流模型的方法,是建立训练数据和生成数据之间的概率关系,然后用可逆的神经网络来训练,这种关系是一一对应的。代价就是模型设计比较麻烦,因为要保证可逆而且逆函数可以算,还要有足够的灵活度。此种方法应用的不多。
4.1 DDPM模型原理
DDPM包括两个过程:前向过程(forward process)和反向过程(reverse process),其中前向过程又称为扩散过程(diffusion process)。扩散模型的灵感来自非平衡热力学。通过定义了一个扩散步骤的马尔可夫链(Markov chain),以缓慢地将随机噪声添加到数据中,然后学习反转扩散过程以从噪声中构建所需的数据样本。
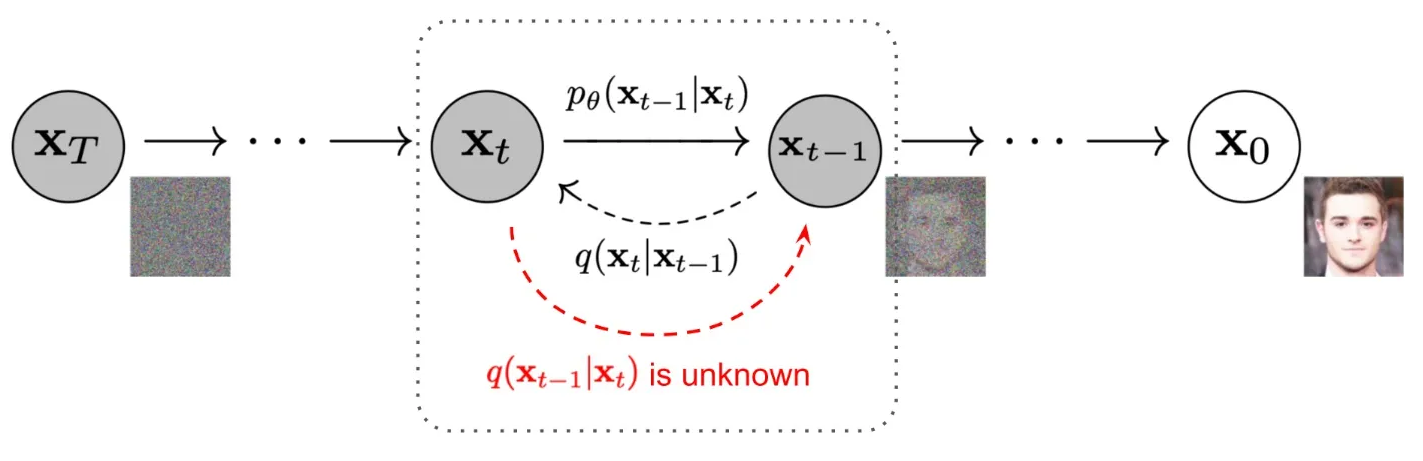
4.2 前向过程
一句话概括,前向过程就是对原始图片 X0 不断加高斯噪声最后生成随机噪声Xt的过程,如下图所示:


