
vit细粒度图像分类(五)TransFC学习笔记_transf 细粒度图像分类
赞
踩
1.摘要
细粒度图像具有不同子类间差异小、相同子类内差异大的特点。现有网络模型在处理过程中存在特征提取能力不足、特征表示冗余和归纳偏置能力弱等问题,因此提出一种改进的 Transformer图像分类模型。
首先,利用外部注意力取代原 Transformer模型中的自注意力,通过捕获样本间相关性提升模型的特征提取能力;其次,引入特征选择模块筛选区分性特征,去除冗余信息,加强特征表示能力;最后,引入融合的多元损失,增强模型归纳偏置和区分不同子类、归并相同子类的能力。
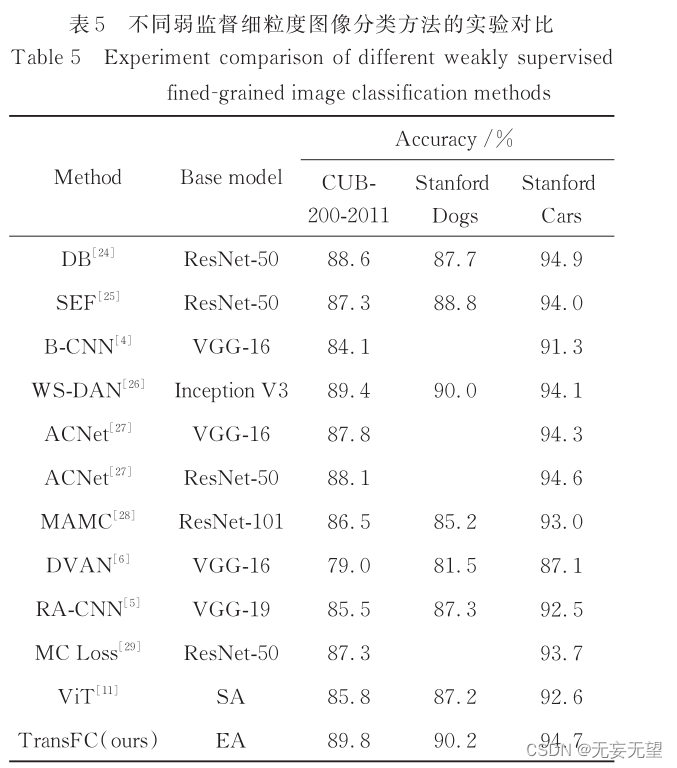
实验结果表明,所提方法在 CUB-200-2011、Stanford Dogs和 Stanford Cars三个细粒度图像数据集上的分类精度分别达 89. 8%、90. 2% 和 94. 7%,优于多个主流的细粒度图像分类方法,分类结果较好。
2.问题
细粒度图像分类作为区分同一父类下不同子类的研究任务,通常用于识别不同种类的鸟、狗、汽车等。细粒度图像具有类间差异小和类内差异大的特点,区分性特征通常存在于局部区域,难以提取和捕获,极具挑战性 。
2.1发现
针对以上问题,研究人员提出了基于强监督的分类方法,其中极具代表性的有 Part R - CNN[3] ,该类方法虽然分类精度较高,但过分依赖人工标注信息,缺乏实用性。目前,以 B - CNN[4] 、RA - CNN [5] 、DVAN [6] 等为代表的弱监督方法成为主要研究趋势,通过改进卷积神经网络(CNN)模型来提高分类精度。张志刚等[7]改进 ResNeXt50[8] ,改进后的方法在野生菌分类任务中取得较好的分类结果。王彬州等[9] 通过在 RA - CNN中引入基于多重注意力机制的方法增强模型的特征提取能力,但该类模型存在因感受野较小无法捕获长距离依赖关系的问题,导致模型的特征提取能力受到限制[10] 。
2.2发展
Vision Transformer(ViT)模 型 由 Dosovitskiy等[11] 于 2020 年提出,通过自注意力(SA)模块捕获长距离依赖关系,提取图像全局特征,分类准确率明显得到提高。但 ViT模型只能捕获单个图像样本内像素间的相关性,导致输出特征提取能力不足,且参数量较大[12] 。此外,ViT 模型使用末层 Transformer 输出的class patch作为最终特征表示,存在大量冗余,导致区分
性特征表示能力不佳[13] 。虽然ViT克服了 CNN无法捕获长距离依赖的缺点,但其归纳偏置的能力较弱[14] 。
2.3创新
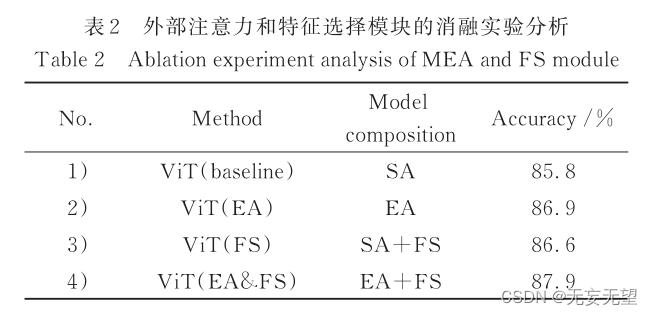
综 上 ,本 文 以 ViT 为 基 础 ,提 出 基 于 改 进Transformer 的细粒度图像分类模型(TransFC)。主要贡献:采用外部注意力(EA)模块[12] 代替自注意力模块,同时捕获单个样本内的长距离依赖关系和样本之间的潜在相关性,增强特征表示能力的同时降低原模型参数量;在模型当中引入特征选择(FS)模块[13] ,在提取并融合区分性区域特征的同时去除冗余特征;引入一种融合的多元损失[13 - 14] ,以扩大不同子类差异,缩小相同子类差异,并使模型具有归纳偏置的能力。在3个公用细粒度数据集上通过与原模型及主流弱监督分类方法进行对比实验,结果表明所提方法具有较好的分类结果。
3.网络
3.1整体结构
TransFC 的整体架构如图 2 所示。首先在 patch序列末尾添加一个 x dis ∈ R 1 × D 用于计算多元损失;然后将每个 Transformer 层内部的自注意力替换为外部注意力;再采用特征选择模块对末层 Transformer的输入 进 行 筛 选 ,去 除 冗 余 特 征 ;最 后 利 用 末 层Transformer的输出从多方面计算损失并融合

3.2 引入外部注意力
自 注 意 力 机 制 作 为 ViT 中 的 主 要 特 征 提 取 方法 ,详 细 架 构 如 图 3 所 示
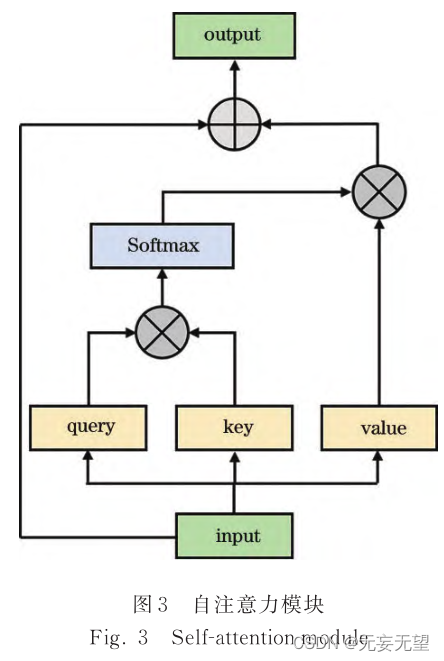
首 先 ,将 输 入 特 征 图F ∈ R N'× d 线 性 映 射 为 Q query ∈ R N'× d' 、 K key ∈ R N'× d' 和
V value ∈ R N'× d ,其中 N' 为像素数量,d 为特征图维度,并利用 Q query 和 K key 计算得到注意力权重矩阵,具体计算过程为
![]()
以上计算过程中,式(5)利用枚举的方式计算同一样本内像素点之间的相关性,忽略了样本间的潜在相关性,导致模型特征提取能力不足[12] ;单个样本内大多数像素点只和其他少数像素点之间有相关性,枚举的计算方式造成大量冗余计算,导致模型参数量较大[16] 。
为解决自注意力存在的问题,本文引入 Guo 等提出的具有线性结构的外部注意力[12] ,通过两个可学习的外部记忆单元使模型可以同时捕获样本内和样本间相关性,增强模型特征提取能力,同时减少模型参数量 ,详 细 结 构 如 图 4 所 示 。

就这两个M,在其他的优化模型中也看到过,但是不知道从哪里来的,又或者说是一种中介,催化剂之类的存在。
首 先 ,将 输 入 特 征 图F ∈ R N'× d 映射为向量 Q E ∈ R N'× d' ,之后利用一个可学习的外部记忆单元 M k ∈ R S × d' 与 Q E 相乘,对结果进行正则化处理后得到注意力权重图 A E ,表达式为
![]()
然后,使用 A E 与另一个外部记忆组件 M v ∈ R S × d 联合计算出一个更为精细的特征图,再与输入特征进行残差操作,得到最终的输出结果 F out ,表达式为
![]()
3.3 引入特征选择模块
在 TransFC 采用滑动窗口方式生成的 patch 序列中,有些 patch 只包含背景信息或少部分前景对象,当滑动窗口步长减小时,类似 patch还会增多。由于细粒度图像区分性特征一般存在于具有细微差异的局部区域,而大量 patch内缺乏有效信息会导致输出特征存在冗余,因此,为去除冗余,引入特征选择模块来提取区分性区域特征。
对于原始 patch序列,在没有任何注意力权重信息的情况下无法选取区分性 patch。特征选择模块根据前 L - 1 层的注意力权重筛选出第 L - 1 层输出的区分性特征,并将其作为第 L 层的输入进一步细化特征。设第 L - 1层 Transformer输出为
![]()
前 L - 1层的注意力权重可表示为
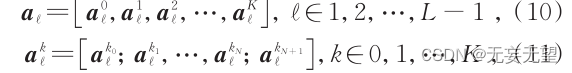
式中:K 为注意力头的数量。特征选择模块使用连乘操作整合前 L - 1层的注意力权重,即
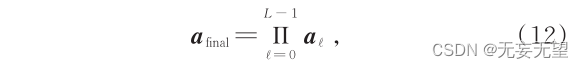
式中: a final 记录了注意力权重由第 1层到第 L - 1层的传递过程。之后从中分别选取 k个注意力头的最大值对应的索引 [ A 1 ,A 2 ,⋯,A K ] ,并根据索引选择输入到第L层的特征,被选中的序列可表示为
![]()
Z select 作为末层输入,舍弃了大量从背景区域提取到的无效特征,避免了模型最终输出特征存在冗余的问题
3.4 融合的多元损失函数
针对细粒度图像不同类间差异小、相同类内差异大的特点和 Transformer模型偏置归纳能力弱的问题,从多角度对损失函数进行优化,提出融合的多元损失函数。
ViT 使用的交叉熵损失可捕获到比较明显的类间差异,但缺少对类间细微差异和类内差异的捕获能力;而对比损失(contrastive loss)可以在增大不同子类特征差异的同时减小相同子类特征差异。本文保留 ViT利用末层 Transformer 输出的 class patch 计算的交叉熵损失,同时利用该 patch 计算对比损失,计算过程可表示为
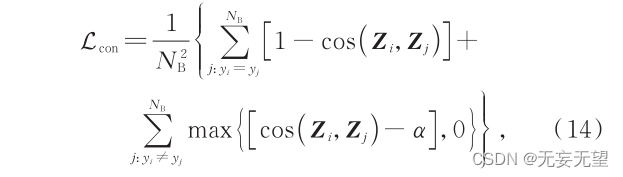
式中: N B 为 batch size 的大小 ; Z i 为第 i 个图像经过TransFC 后输出的 calss patch,也是最终的特征表示;cos ( Z i ,Z j ) 表示 Z i 和 Z j 的余弦相似度,其大于超参数 α时才会在对比损失中起作用。 L con 经过反向传播可以扩大不同子类别之间的特征表示,缩小相同子类别内的特征表示,缓解了类间差异小和类内差异大造成的分类困难问题。
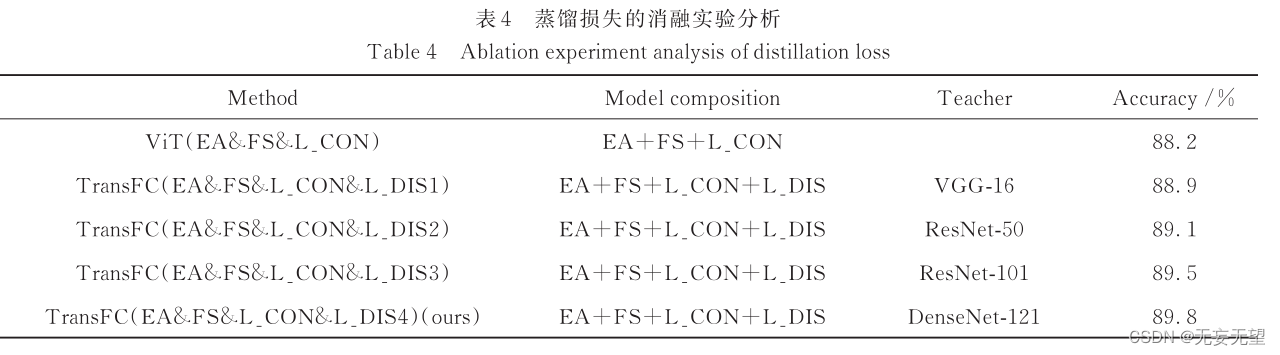
其次,由于归纳偏置能力是影响 Transformer模型特征提取能力的关键因素,而 CNN 模型具有较强的偏置归纳能力,因此利用 CNN 引入蒸馏损失(distillationloss)[14] ,使得 TransFC 能够从 CNN 中学习到归纳偏置能力,以进一步提升模型的特征提取能力。
Hinton 等[17]提 出 的 知 识 蒸 馏 (knowledgedistillation)是一种将知识从 teacher模型转移到 student模型的训练策略,其联合二者 Softmax 层输出的预测标签共同计算出蒸馏损失,实现知识迁移。本文引入蒸馏损失作为总损失的一部分,在输入的 patch序列后增 加 一 个 distillation patch,与 class patch 类 似 ,distillation patch 在多个 Transformer 层内与其他 patch相互作用,最终聚合图像的特征表示;但与 class patch不同,distillation patch 的目标是再现 teacher 模型输出的预测标签,而不是真实标签。联合依据 distillationpatch计算得到的标签与 teacher模型(CNN)的输出标签,通过计算二者之间 Kullback - Leibler (KL)散度的方 式 得 到 蒸 馏 损 失 ,作 为 总 损 失 的 一 部 分 ,指 导student 模型(TransFC)进行反向传播 ,具体计算方法为
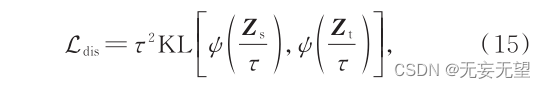
式中: Z s 为利用 distillation patch进行分类时的 logist函数输出; Z t 为 teacher模型的 logist函数输出; ψ ( · ) 表示Softmax函数; τ 表示蒸馏温度,使 Softmax层的输出的概率分布更加接近。综上,从三个角度分别计算交叉熵损失、对比损失和蒸馏损失后进行融合,帮助模型区分不同子类差异,归并相同子类差异,并赋予模型归纳偏置能力,使输出特征更加精细化,更有区分性。因交叉熵损失和对比损失是利用同一个 class patch 计算得到的,所以融合过程中将二者之和视为总损失的一部分,蒸馏损失视为另一部分。具体的融合方式为
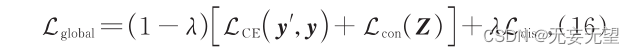
式中: L CE ( y',y ) 为 class patch 的预测标签 y' 和真实标签 y 之间的交叉熵损失; λ 为超参数。
4.实验
4.1实验设置
4.1.1 数据集

4.1.2 实验细节
Dosovitskiy 等[11] 在提出 ViT 模型时通过大量实验证明,当 Transformer 模型层数达 12 时,继续增加层数并不能明显提升模型分类准确率,却大大增加了模型参数量,因此本文采用 12 层 Transformer 架构。patch 的数量也是影响模型参数量的一个重要因素,其数量与 patch 大小成反比,与输入图像的分辨率成正比。为保证 TransFC 模型具有充足的数据输入量,并避免模型因参数量较大在训练阶段不易收敛,使用448×448分辨率的输入图像,在训练阶段采用随机裁剪,测试阶段采用中心裁剪,保留原 ViT 模型 16×16的 patch 大小,同时将滑动窗口的步长设置为 12。模型训练阶段,均采用加载 ImageNet 预训练参数的方式进行微调,将对比损失中的超参数 α 设置为 0. 4,使用 随 机 梯 度 下 降 法(SGD)作 为 优 化 方 法 ,动 量(momentum)设 置 为 0. 9,batch size 为 32。 考 虑 到Stanford Dogs 数据集的训练集相较于其他两个数据集较多,在 Stanford Dogs数据集上训练时将学习率初始化为 0. 003,而在其他两个数据集上将学习率初始化为 0. 03,采用余弦退火(cosine annealing)控制学习率的下降幅度。
4.2对比试验
4.3消融实验

 4.4 可视化
4.4 可视化

5.结语
在 ViT 的基础上,针对细粒度图像分类的特点和Transformer 网络特征提取能力不足、特征表示冗余、归纳偏置能力弱等问题,提出基于改进 Transformer的细粒度图像分类模型。采用外部注意力替换原有的特征提取方法,以捕获样本间和样本内的相关性,进而提升模型特征提取能力,同时降低模型的参数量;引入特征选择模块来去除冗余特征,使最终的特征表示更加精细;引入多元损失加强模型的偏置归纳能力,并增强模型区分不同子类、归并相同子类的能力,使模型更适用于细粒度图像分类任务。实验结果表明,所提方法在多个细粒度数据集上均具有较高的分类精度,优于多个主流的细粒度分类方法。通过蒸馏学习的方式,利用 CNN 指导 Transformer 模型训练的方式比较繁琐,在未来工作中,将 CNN 直接融入 Transformer模型是后续工作的方向。

