
- 1Bilstm双向长短期神经网络多输入单输出回归分析
- 2Python实现植物大战僵尸_做基于python植物大战僵尸思路
- 3小甲鱼Python3 分支循环
- 4【计算机网络】 0、各网络命令 + tcpdump + Wireshark、抓包实战、TCP 握手挥手、防火墙、保活、MTU_wireshark tcpdump动态实时抓包
- 5数字孪生智慧校园三维可视化运维检测平台_智慧校园运营监测平台
- 6【读书笔记】商业自传-PayPal程序员-硅谷钢铁侠-埃隆·马斯克,SpaceX CEO、特斯拉公司CEO、太阳城公司董事会主席。_霍尔曼 spacex 车阀门
- 7区块链的层级结构_区块链技术的体系结构,区块链一般分为几层,每层的主要功能是什么?
- 8【MongoDB】windows安装MongoDB6.0.5+可视化界面软件_mongodb图形化界面
- 9Mac上如何装Nacos?_mac 安装nacos
- 10三级分销这种,多层关系的会员锁定代码
【AI绘画原理】--扩散模型Diffusion model_ai扩散模型
赞
踩
如今,midjourney,stable diffusion等大部分AI绘图软件层出不穷
那么,究竟生成图片的原理是什么
以stable diffusion为例,其整个过程大致为

Clip模型——用于接受文字输入,并变成向量输入进去,以找到图像特征
diffusion model扩散模型——在生成图片时候是逆扩散,可以理解把一大堆高斯噪声“变回”图片(潜在空间)
而后是VAE模型,把潜在空间里的图片解码变成真正的图片
由于涉及更深层的知识,今天仅解释Diffusion model扩散模型
一 --起源
2015年,斯坦福大学四位研究者通过思考物理学中的熵增定律——即,物体总是朝着更混乱的方向发展,后,提出Diffusion model扩散模型
红墨水滴入水杯里,红色色素迅速充满整个水杯,这个过程是分子的无序运动,而这个过程里,色素分子无序运动,是“”混乱“”的,是随机的

而研究者们,则思考能不能将这种随机混乱的效果运用到图像处理上面
二——原理过程
所谓扩散模型,小楚先避个雷,以下是我的个人思考观点,希望大佬指出错误。
首先是将一个正常图片,不断的添加高斯噪声(这个过程里,每次添加的噪声的量是固定,比如50高斯噪声,那么每一次都是50高斯噪声,)直至一张图片几乎完全是噪声

而后通过训练模型,来让一个模型实现,从“这幅已经是噪声的狗狗”还原成最初的狗狗图片,
而这个过程就是“”无“”中生有的过程,也就是“生成图片”
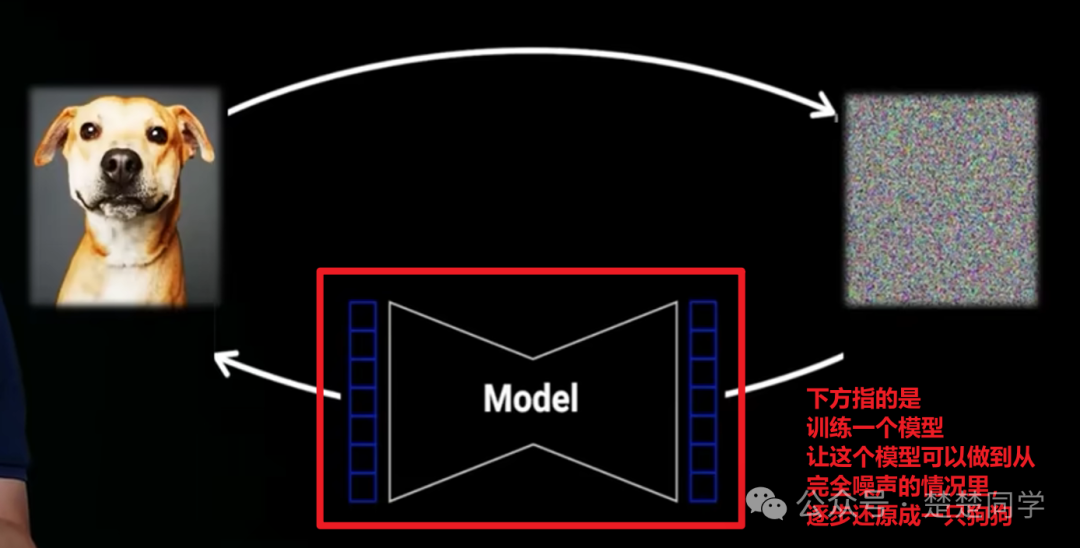
比如每一次还原50个高斯噪声,经过n步还原回去
听起来好像很简单,事实上,这个过程极度复杂
而其做到的方法其实离不开马尔科夫链+信息熵,来一步一步指导图片还原,事实上情况非常复杂
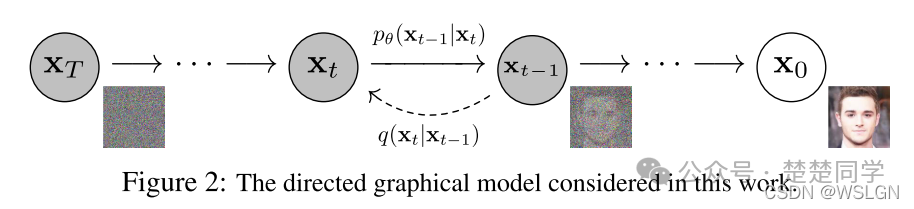


这里仅能用目前理解的东西告诉大家
所谓AI绘画,本质上就是一个可以将“高斯噪声”图片还原回去的过程
我们输入“一只快乐的狗在草原上奔跑”
clip会将 ‘一只’,‘快乐的’,‘狗’,‘草原上’,‘奔跑’分解成一个个向量,来寻找——“绘图意向”
你可以理解为有很多空间,其中一块空间全部放的是各种的狗,一个“狗的空间”,每一只狗是其中的一个点,
Diffusion model在还原图片的时候,就会靠近“狗”的这个空间,来尽可能像“一只狗”来还原,但是高斯噪声是随机的,所以最后图片上的狗每一次都长的不一样
同样,尽可能靠近草原,靠近快乐,
但是AI绘画远没有这么简单,在进一步了解以后,未来可能会给大家带来生成对抗模型、变微分自动编码器、流模型等各大生成模型
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除

