
- 1猫头虎分享:Element UI & Element Plus组件的安装及使用_element-plus安装
- 2十大计算机专业证书,考过了同事对你刮目相看,老板给你升职加薪_计算机cct和ncre哪个好
- 3Git:查看本地分支基于哪个分支创建_查看当前分支是基于哪个分支
- 4mysql 操作命令小结_select,insert, update, delete, create, drop, reloa
- 5linux-DNS服务器的搭建_linux搭建dns服务器
- 6Ubuntu22.04虚拟机配置及使用代理工具_ubuntu 代理软件
- 7华为外包hr面试刷人吗,面试一个百度T7 Java 岗,简单聊聊2024年Java开发的现状和思考
- 8git代码提交推送报错:remote: The project you were looking for could not be found的解决
- 9Unity引擎学习笔记之【触摸屏监听操作】_unity touchphase.began
- 10为什么 Python 能成为最受欢迎的编程语言之一?_python为什么在程序员中很受欢迎?
轻量级模型:MobileNet V2_caffe mobilenet 模型
赞
踩
一、论文:
非官方Caffe代码:https://github.com/shicai/MobileNet-Caffe
二、论文理解
MobileNet V2 是对 MobileNet V1 的改进,同样是一个轻量级卷积神经网络。
1)基础理论--深度可分离卷积(DepthWise操作)
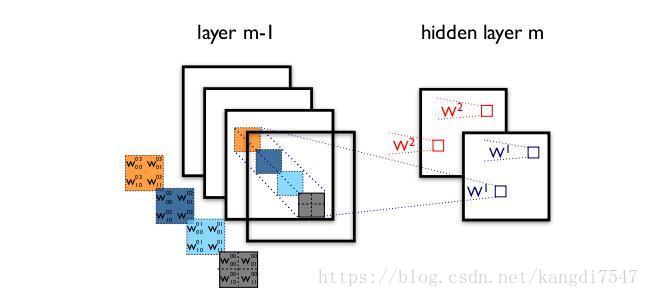
标准的卷积过程可以看上图,一个2×2的卷积核在卷积时,对应图像区域中的所有通道均被同时考虑,问题在于,为什么一定要同时考虑图像区域和通道?我们为什么不能把通道和空间区域分开考虑?
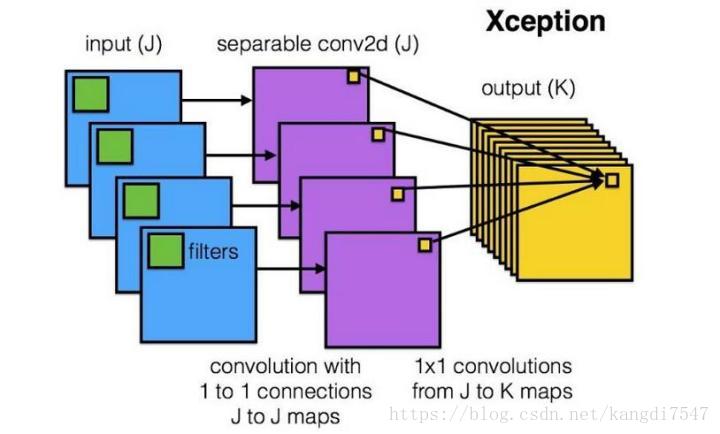
Xception网络就是基于以上的问题发明而来。我们首先对每一个通道进行各自的卷积操作,有多少个通道就有多少个过滤器。得到新的通道feature maps之后,这时再对这批新的通道feature maps 进行标准的1×1跨通道卷积操作。这种操作被称为“DepthWise convolution”,缩写“DW”。
这种操作是相当有效的,在 ImageNet 1000 类分类任务中已经超过了InceptionV3 的表现,而且也同时减少了大量的参数,我们来算一算,假设输入通道数为3,要求输出通道数为256,两种做法:
1. 直接接一个3×3×256的卷积核,参数量为:3×3×3×256 = 6,912
2. DW 操作,分两步完成,参数量为:3×3×3 + 3×1×1×256 = 795,又把参数量降低到九分之一!
因此,一个 Depthwise 操作比标准的卷积操作降低不少的参数量,同时论文中指出这个模型得到了更好的分类效果。
2)MobileNetV1遗留的问题
1、结构问题:
MobileNet V1 的结构其实非常简单,论文里是一个非常复古的直筒结构,类似于VGG一样。这种结构的性价比其实不高,后续一系列的 ResNet, DenseNet 等结构已经证明通过复用图像特征,使用 Concat/Eltwise+ 等操作进行融合,能极大提升网络的性价比。
2、Depthwise Convolution的潜在问题:
Depthwise Conv确实是大大降低了计算量,而且N×N Depthwise +1×1PointWise的结构在性能上也能接近N×N Conv。在实际使用的时候,我们发现Depthwise部分的kernel比较容易训废掉:训练完之后发现Depthwise训出来的kernel有不少是空的。当时我们认为,Depthwise每个kernel dim相对于普通Conv要小得多,过小的kernel_dim, 加上ReLU的激活影响下,使得神经元输出很容易变为0,所以就学废了。ReLU对于0的输出的梯度为0,所以一旦陷入0输出,就没法恢复了。我们还发现,这个问题在定点化低精度训练的时候会进一步放大。
3)MobileNet V2的创新点
1、Inverted Residual Block
MobileNet V1没有很好的利用Residual Connection,而Residual Connection通常情况下总是好的,所以MobileNet V2加上。先看看原始的ResNet Block长什么样,下图左边:
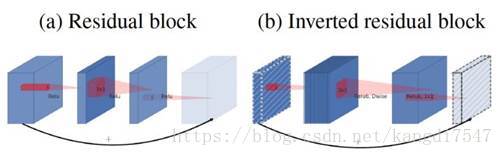
先用1x1降通道过ReLU,再3x3空间卷积过ReLU,再用1x1卷积过ReLU恢复通道,并和输入相加。之所以要1x1卷积降通道,是为了减少计算量,不然中间的3x3空间卷积计算量太大。所以Residual block是沙漏形,两边宽中间窄。
但是,现在我们中间的3x3卷积变为了Depthwise的了,计算量很少了,所以通道可以多一点,效果更好,所以通过1x1卷积先提升通道数,再Depthwise的3x3空间卷积,再用1x1卷积降低维度。两端的通道数都很小,所以1x1卷积升通道或降通道计算量都并不大,而中间通道数虽然多,但是Depthwise 的卷积计算量也不大。作者称之为Inverted Residual Block,两边窄中间宽,像柳叶,较小的计算量得到较好的性能。
2、ReLU6
首先说明一下 ReLU6,卷积之后通常会接一个 ReLU 非线性激活,在 MobileNet V1 里面使用 ReLU6,ReLU6 就是普通的ReLU但是限制最大输出值为 6,这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率,如果对 ReLU 的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。
本文提出,最后输出的 ReLU6 去掉,直接线性输出,理由是:ReLU 变换后保留非0区域对应于一个线性变换,仅当输入低维时ReLU 能保留所有完整信息。
在看 MobileNet V1的时候,我就疑问为什么没有把后面的 ReLU去掉,因为Xception已经实验证明了 Depthwise 卷积后再加ReLU 效果会变差,作者猜想可能是 Depthwise 输出太浅了, 应用 ReLU会带来信息丢失,而 MobileNet V1还引用了 Xception 的论文,但是在 Depthwise 卷积后面还是加了ReLU。在 MobileNet V2 这个 ReLU终于去掉了,并用了大量的篇幅来说明为什么要去掉。
总之,去掉最后那个 ReLU,效果更好。
4) 网络结构
这样,我们就得到 MobileNet V2的基本结构了,左边是 V1 的没有 Residual Connection并且带最后的 ReLU,右边是 V2 的带Residual Connection 并且去掉了最后的 ReLU:
![计算机生成了可选文字:convIXI,Relu6Dwise3x3,stride=s,Relu6input(b)MobileNet[26]11.Linear0、e耘3@Relu61獄以06Stride1b《0改convIXI.Linear§e。乙Relu6ConvIxl,5貊de能20改(d)MobilenetV2](https://img-blog.csdn.net/20180805152857168?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2thbmdkaTc1NDc=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
网络的整体配置清单如下:
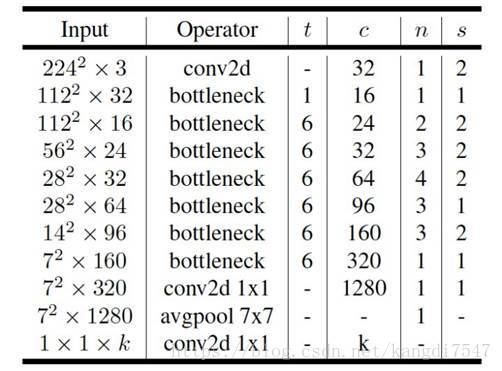
其中:
t 是输入通道的倍增系数(即中间部分的通道数是输入通道数的多少倍)
n 是该模块重复次数
c 是输出通道数
s 是该模块第一次重复时的 stride(后面重复都是 stride 1)
5) 实验结果
通过 Inverted residual block这个新的结构,可以用较少的运算量得到较高的精度,适用于移动端的需求,在 ImageNet 上的准确率如下所示:
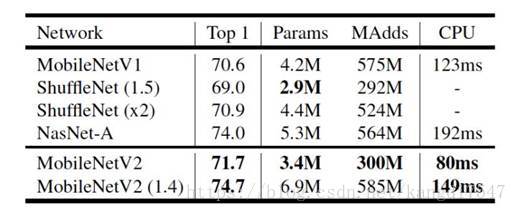
可以说是又小又快又好。另外,应用在目标检测任务上,也能得到很好的效果。
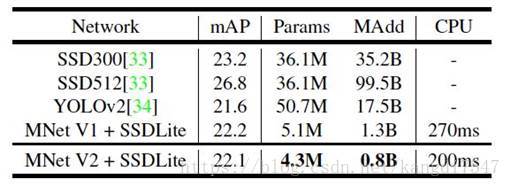
应用在目标检测任务上,基于 MobileNet V2的SSDLite 在 COCO 数据集上超过了 YOLO v2,并且大小小10倍速度快20倍:
6) 总结
1、CNN 在 CV 领域不断突破,但是深度模型前端化还远远不够。目前 MobileNet、ShuffleNet参数个位数(单位 M ),在ImageNet 数据集上,依 top-1 而论,比 ResNet-34,VGG19 精度高,比 ResNet-50 精度低。实时性和精度得到较好的平衡。
2、本文最难理解的其实是 Linear Bottlenecks,论文中用了很多公式来描述这个思想,但是实现上非常简单,就是在 MobileNet V2 微结构中第二个PW后去掉 ReLU6。对于低维空间而言,进行线性映射会保存特征,而非线性映射会破坏特征。
三、参考博客
MobileNet V2的Caffe模型:https://github.com/shicai/MobileNet-Caffe
Depthwise Convolutional Layer: github.com/yonghenglh6/DepthwiseConvolution
MobileNet-SSD: https://github.com/chuanqi305/MobileNet-SSD
知乎:https://www.zhihu.com/question/265709710/answer/298927545

