- 1【CSS】CSS特效集锦,视觉魔法的碰撞与融合(一)
- 2会画画有什么用?_我要一个画画的布和画画的呗,谢谢你们,你们可以和我找一个吧。
- 3github clone失败问题解决_github clone failed
- 4ChatGPT人工智能对话系统源码 电脑版+手机端+小程序三合一 带完整的安装代码包以及搭建教程_chatgpt 源码下载
- 5Windows电脑搭建HarmonyOS NEXTDeveloper Preview2环境详解_deveco studio next developer preview2
- 6蓝易云 - 在Ubuntu环境下Nacos启动失败,Debug日志显示startup.sh: 130: startup.sh: [[: not found 的解决方案。
- 7两万字长文 _ 面向不确定性环境的自动驾驶运动规划:机遇与挑战
- 8安全左移利器——洞态iast调研(待完成)_洞态 iast
- 9学习FPGA——LPM_COUNTER_lpmcounter aclr
- 10音视频系列5: ffmpeg-python
LLM赋能产业数智化业务系统升级的思考_erp + llm
赞
踩
1概述
-
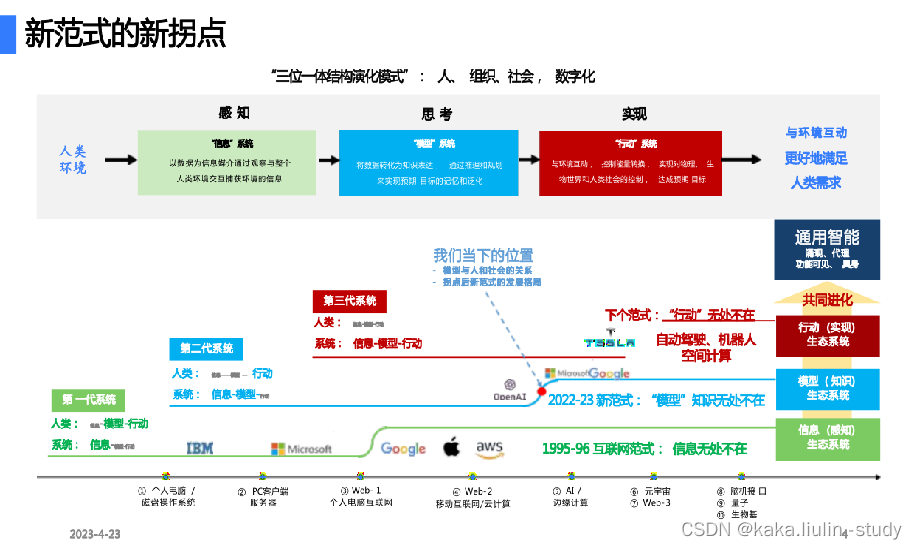
2022年是人工智能的一个分水岭,ChatGPT,DALL E[ DALL E:是一款可以根据文本描述创建图像的AI工具。]和Lensa[ Lensa:是一款AI美图软件。]等几个面向消费者的应用程序发布了,它们的共同主题是使用生成式人工智能(AI Generated Content,简称AIGC),这是人工智能领域的一次范式转换。当前的人工智能使用模式检测或遵循规则来帮助分析数据和做出预测,而Transformer[ Transformer:是特征抽取器,用于特征抽取的一种深层级网络结构。可以完成自然语言处理领域研究的典型任务:如机器翻译,文本生成等,同时又可以构建预训练语言模型,用于不同任务的迁移学习。]架构的出现则开启了一个新领域:生成式人工智能可以通过创建类似于其所训练的数据的新颖数据来模仿人类的创造过程,将人工智能从“赋能者”提升为(潜在的)“协作者”。
-
从城市智慧化发展需求来看,借助智慧城市技术体系补齐城市公共服务短板,促进产业高质量发展,推进城市治理精准化,是实现“设备互联、数据互联、业务互联、产业互联、产城融合”新型智慧城市的重要手段;从产业数字转型来看,发展技术替代劳动是人类社会生产力大幅提升的重要动力,借助新一代核心技术体系建立产业智慧化支撑技术体系,高效地采集、传输、处理、共享海量信息,是将“信息获取-运算-决策-反馈”流程变得更加高效的重要路径。
-
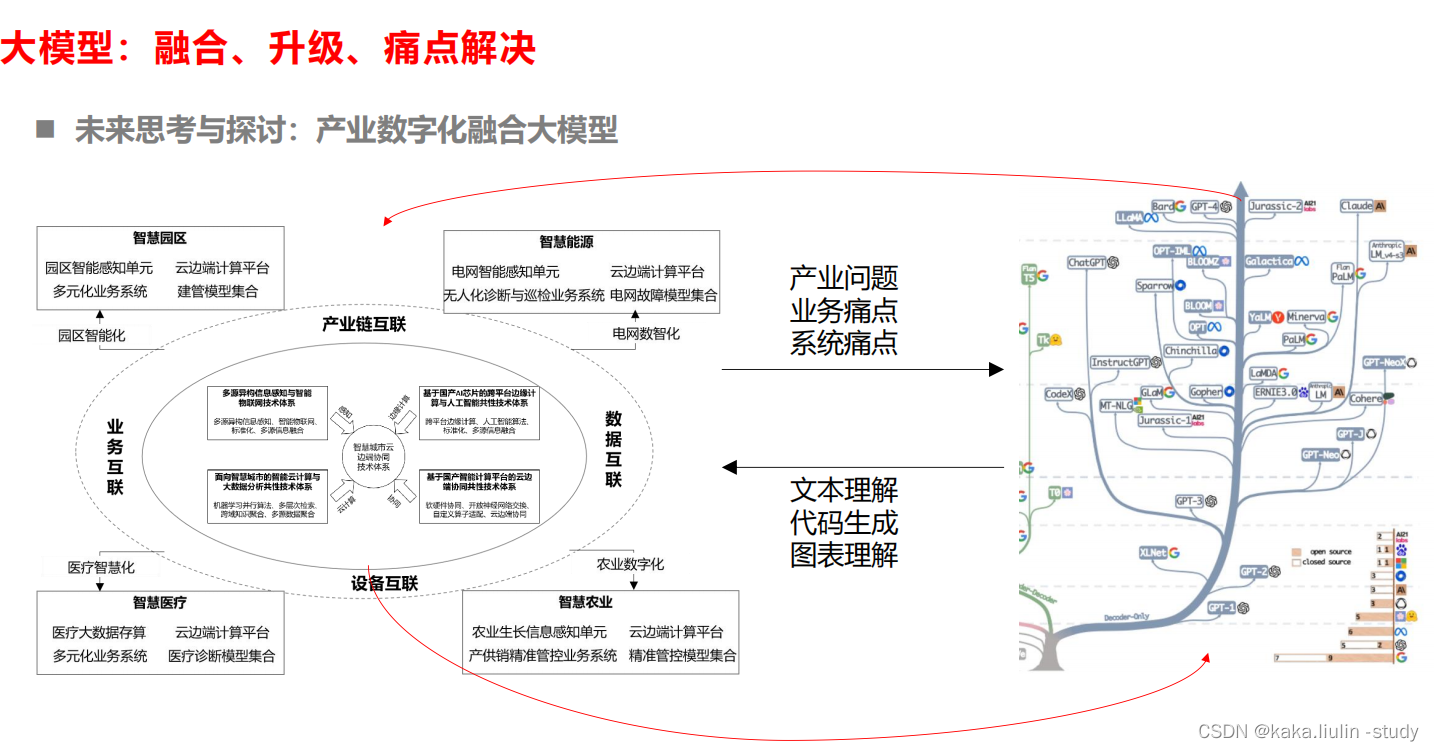
大模型呈现出来的涌现能力将代替数据成为新的基础设施,而且拐点以ChatGPT发布为基线已经到来。从整个创新行业来看,新技术的迭代速度大大加快,以技术引领的重塑行业应用生态已然是进行时。因此建立一个创新技术研究机构和体系越来越重要,紧密跟进前沿技术研究与发展趋势,快速响应技术给行业、业务、应用带来的影响,建立创新研究平台在创新技术研究、技术耦合产业应用、技术变革业务需求将成为科技服务提供者的重要支撑平台。笔者理解的大模型在产业数智化领域的应用落地体现出来的基本能力为:理解人类语言、语言解析+搜索结合下的实时信息获取、代码生成、理解文本重点内容、理解图表。
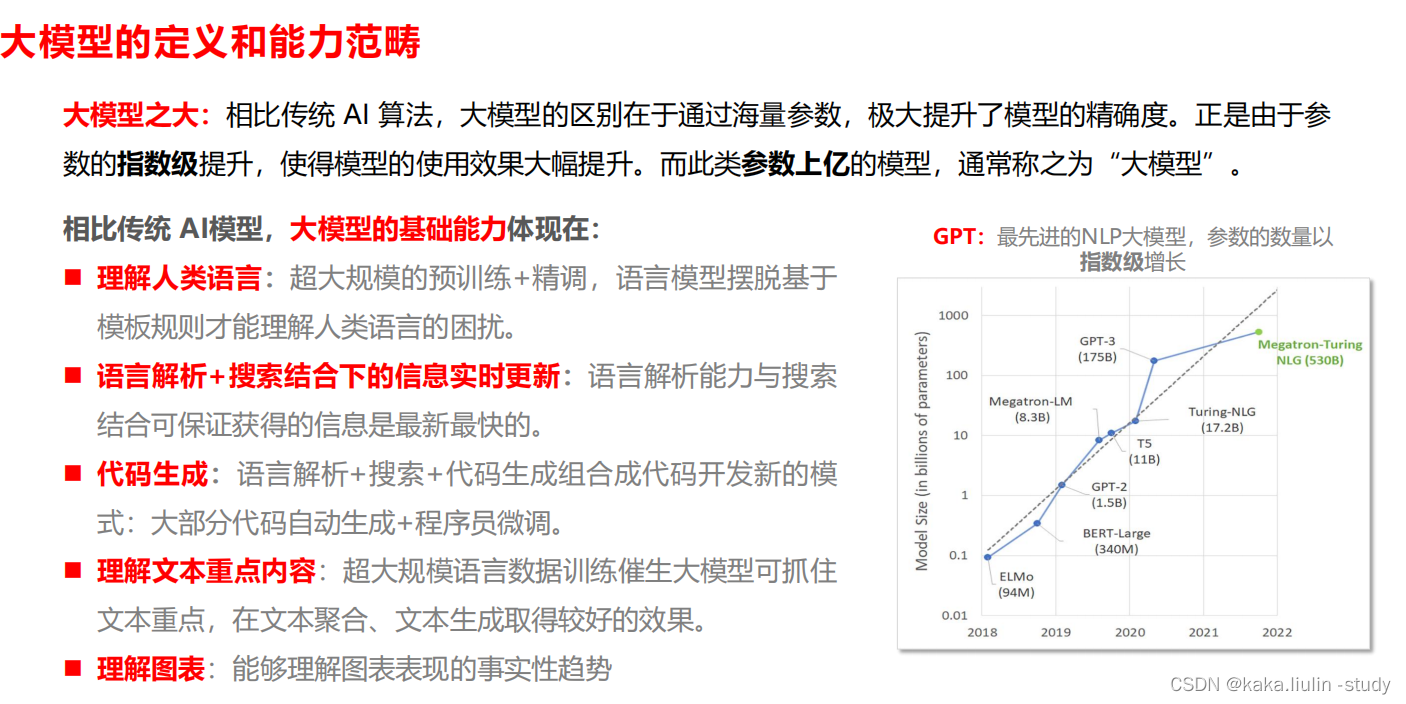
大模型如何创新产业数字化业务系统
当前产业数字化的各业务系统解决了一部分产业端设备、数据、人、组织等的互联协作问题,也带来了一些额外的工作和问题,比如数据采集端,物联设备协议的维护、业务系统(如ERP)数据填报、数据分析工作中查询挑选报表、审批流程的更改替换等,上述工作目前的业务系统还需要靠手工方式,费时费力且极容易造成数据录入的不精准、不及时。另一方面大量重复的工作集中在数据录入、流程调整、异常数据的整理等,而不是基于数据做分析与决策。
大模型与产业数字化业务系统的结合将一方面解决传统业务系统面对的一些痛点问题、解决产业三存在的顽疾;另一方面将大模型作为一个基础设施,通过类chatGPT的对话大模型作为统帅,进一步打通各业务系统的壁垒,调度各类业务系统解决产业协同不足的问题,将多智能体嵌入到产业中。大模型作为基础设施与数据中台、OA系统、ERP系统的结合模式,创新人机交互的模式。
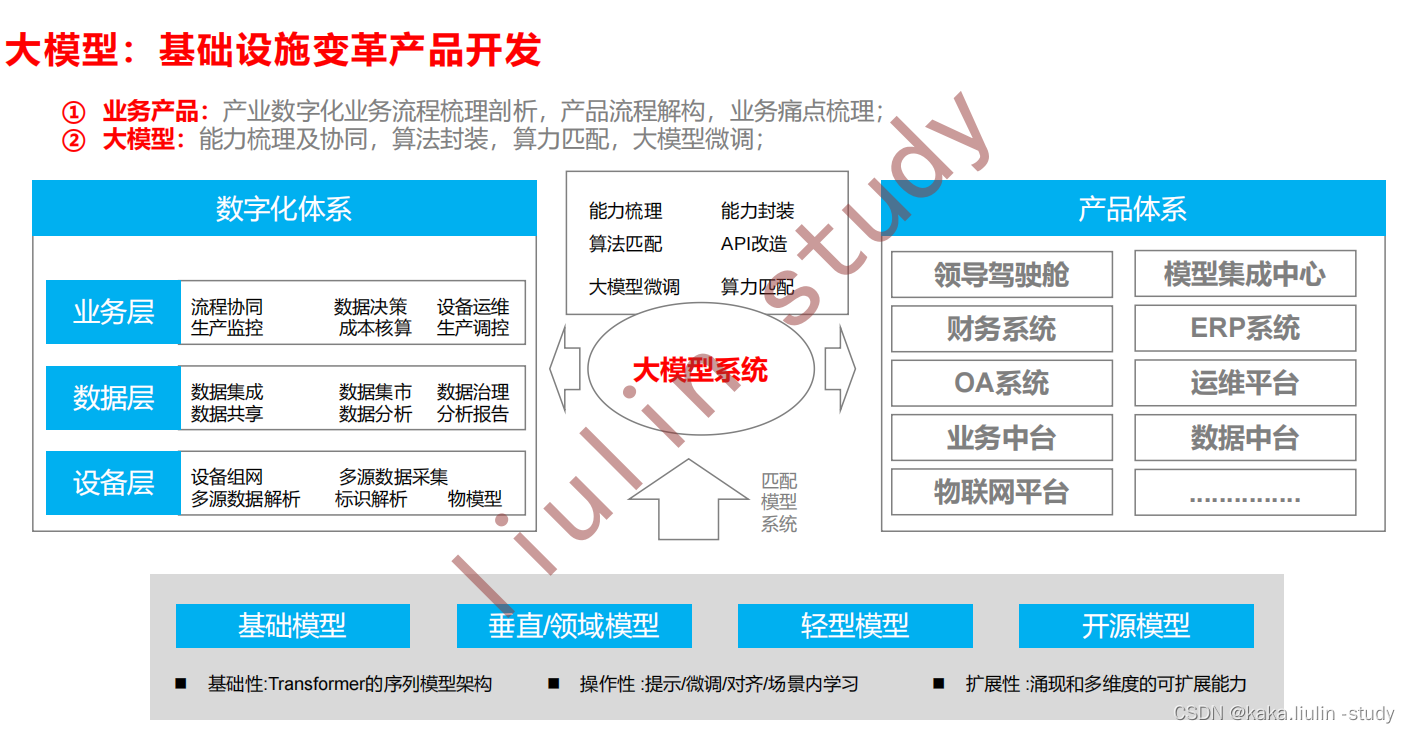
- 数据中台与大模型的结合
当前数据中台的主要功能一般有:数据集成、数据调度、数据建模、BI展示和分析报告,是一个将产业数字化各业务系统以数据链接在一起、数据集中之后发掘数据价值的中间件,对于产业端来说,是产业数字化、解决产业各链条协作问题的关键部件。但是当前数据中台往往成为一个数据管理的构件,建立分析模型发掘数据价值,解决产业问题方面发挥的作用有限,其中主要的问题是对于当前的数据中台,数据分析师的大量工作师在找数据、处理异常数据、撰写数据分析报告中的事实性(趋势描述)描述,而非建立数据分析流程和数据分析模型的建立与优化工作。
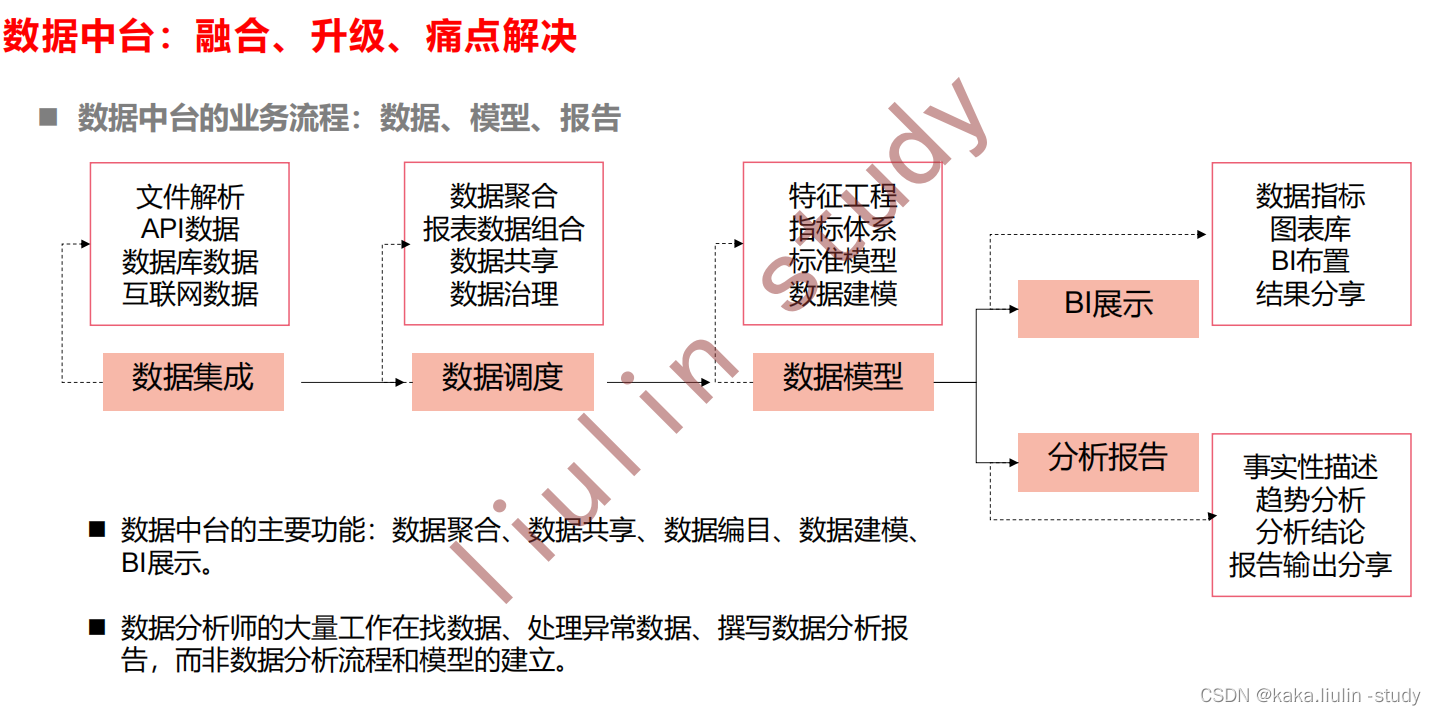
借助大模型在语言理解、代码生成、数据聚合、文本生成等方面的优势,可以解决数据中台在数据获取、报表聚合、数据分析建模、文档生成方面存在的痛点。详情如下:

2实践
大模型赋能数据中台,做数据获取、数据清洗、数据聚合及分析、数据报告生成。
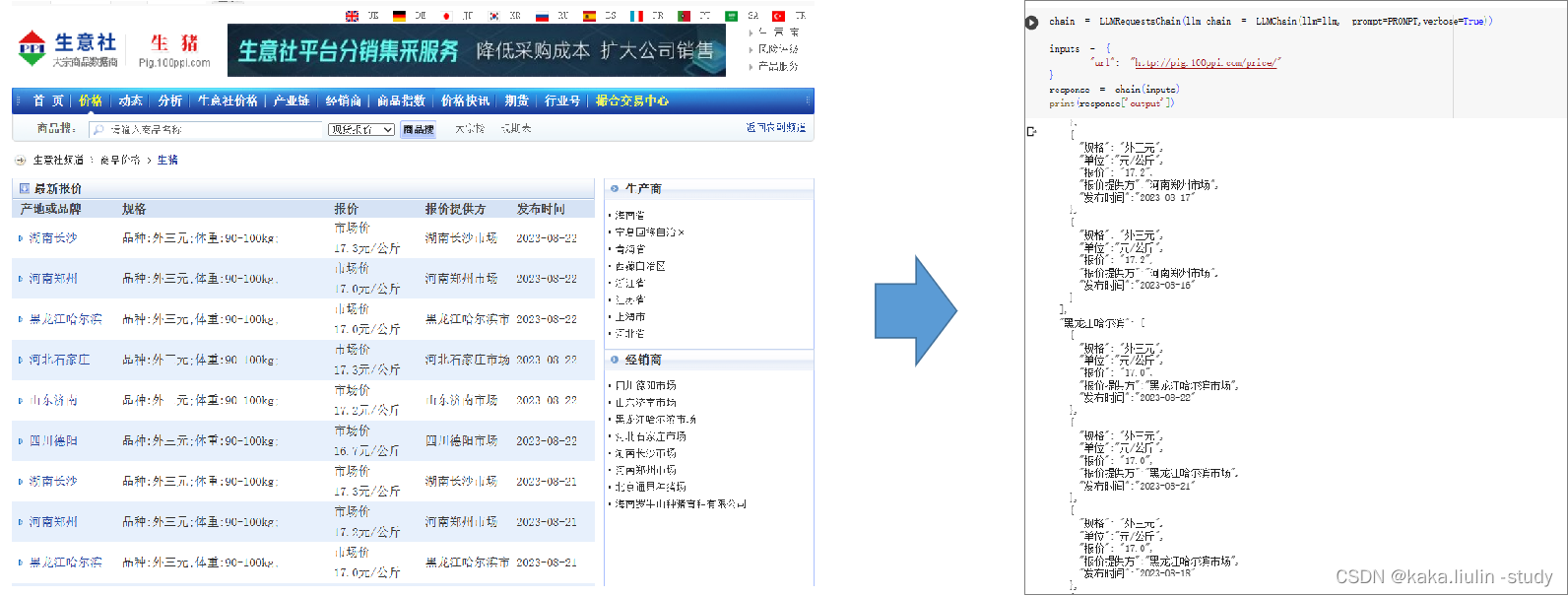
- 数据获取-爬虫
#数据爬虫
from tempfile import template
from langchain.chains.llm import LLMChain
from langchain import prompts
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain.chains import LLMRequestsChain,LLMChain
from langchain.agents import create_csv_agent
from langchain.llms import OpenAI,OpenAIChat
import os
#你申请的openai的api_key
os.environ["OPENAI_API_KEY"] = ""
#定义openai的语言模型llm
llm=OpenAI(model_name="gpt-3.5-turbo-16k-0613",temperature=0)
#定义提示词
template = """在 >>> 和 <<< 之间是网页的返回的HTML内容。
网页是全国生猪市场数据表格。
请抽取参数请求的信息。获取每个产地的生猪市场报价;
>>> {requests_result} <<<
请使用如下的JSON格式返回数据
{{
"province": [
{{
"规格": "a",
"单位":"元/公斤",
"报价": "50",
"报价提供方":"b",
"发布时间":"b"
}},
{{
"规格": "a",
"单位":"元/公斤",
"报价": "50",
"报价提供方":"b",
"发布时间":"b"
}},
]
}}
例如,province为湖南长沙,JSON数据应该是如下形式:
{{
"湖南长沙": [
{{
"规格": "a",
"单位":"元/公斤",
"报价": "50",
"报价提供方":"b",
"发布时间":"b"
}},
{{
"规格": "a",
"单位":"元/公斤",
"报价": "17.0",
"报价提供方":"b",
"发布时间":"b"
}},
]
}}
Extracted:"""
PROMPT = PromptTemplate(
input_variables=["requests_result"],
template=template,
)
chain = LLMRequestsChain(llm_chain = LLMChain(llm=llm, prompt=PROMPT,verbose=True))
inputs = {
"url": "http://pig.100ppi.com/price/"
}
response = chain(inputs)
print(response['output'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
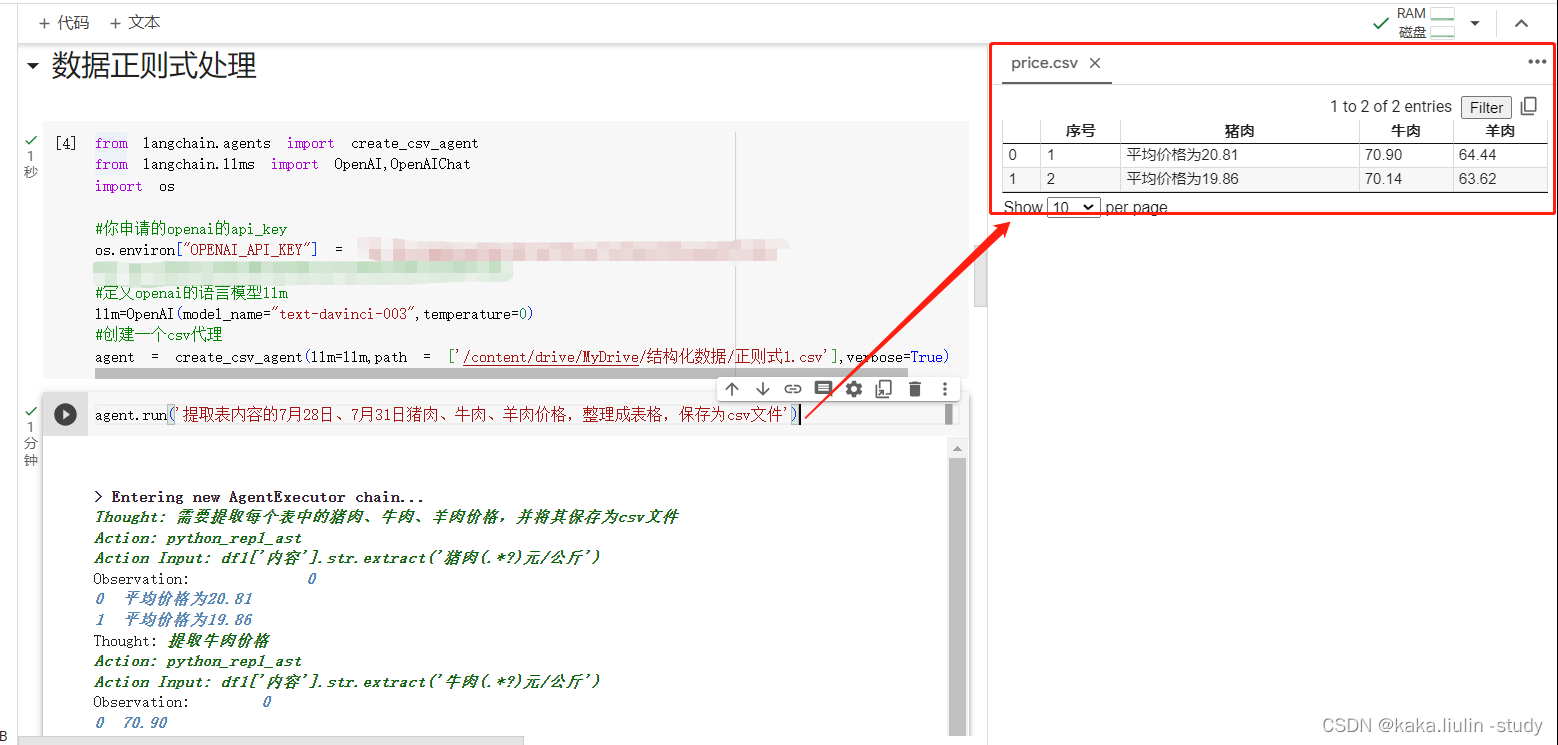
- 数据清洗-正则式
from langchain.agents import create_csv_agent
from langchain.llms import OpenAI,OpenAIChat
import os
#你申请的openai的api_key
os.environ["OPENAI_API_KEY"] = ""
#定义openai的语言模型llm
llm=OpenAI(model_name="text-davinci-003",temperature=0)
#创建一个csv代理
agent = create_csv_agent(llm=llm,path = ['/content/drive/MyDrive/结构化数据/正则式1.csv'],verbose=True)
agent.run('提取表内容的7月28日、7月31日猪肉、牛肉、羊肉价格,整理成表格,保存为csv文件')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
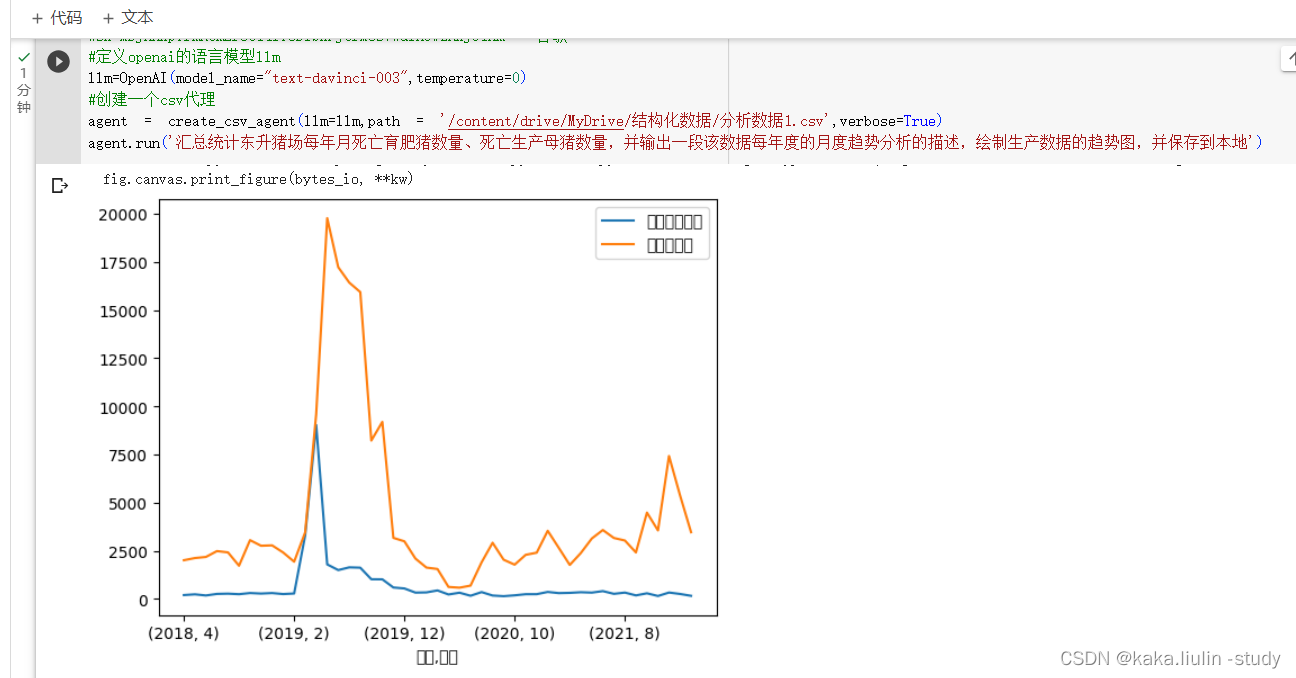
- 数据聚合分析
from langchain.agents import create_csv_agent
from langchain.llms import OpenAI,OpenAIChat
import os
#你申请的openai的api_key
os.environ["OPENAI_API_KEY"] = ""
#定义openai的语言模型llm
llm=OpenAI(model_name="text-davinci-003",temperature=0)
#创建一个csv代理
agent = create_csv_agent(llm=llm,path = '/content/drive/MyDrive/结构化数据/分析数据1.csv',verbose=False)
agent.run('汇总统计东升猪场每年月死亡育肥猪数量、死亡生产母猪数量,并输出一段该数据每年度的月度趋势分析的描述,绘制生产数据的趋势图,并保存到本地')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
思考
**大模型成为新的基础设施:**大模型呈现出来的涌现能力将代替数据成为新的基础设施,而且拐点以ChatGPT发布为基线已经到来。
**”模型系统“:**人类思考协作本质上是一个模型系统,借助于大模型底层研发逻辑,更多的模型系统将通向大模型。
**产品应用的开发需与大模型深度结合:**以后的产品研发逻辑是借助大模型的基础能力做深度的融合,在解决长期未解决的业务痛点上存在可能。