
热门标签
热门文章
- 1【Ubuntu】Ubuntu 22.04 升级 OpenSSH 9.3p2 修复CVE-2023-38408_ubuntu22.04升级openssh
- 2YOLOv10论文解读——实时的端到端目标检测模型【附结构图】
- 3java加密算法pbkdf2_pbkdf2加密算法工具类
- 4STM32CUBEMX配置教程(三)通用GPIO配置_stm32cubemx怎么设置gpio精准输出
- 5从0到1搭建一台属于个人的服务器,永久可运行!
- 6评价得分计算:确立权重的方法
- 7JAVA程序员面试系列(二)_为啥java需要二面
- 8Jenkins的部署过程,从输入分支名开始,后台都经历了哪些
- 9Ollama配置webui连接大预言模型_ollama ui
- 10用树莓派4B安装gitlab,亲测可用~_树莓派 gitlab
当前位置: article > 正文
【大数据技术】实验3:熟悉常用的Hive操作_实验3熟悉hive的基本操作
作者:笔触狂放9 | 2024-06-07 16:09:52
赞
踩
实验3熟悉hive的基本操作
一、实验环境
- 操作系统:Linux(与实验1保持一致);
- Hadoop版本:3.3.1;
- JDK版本:1.8;
- Hive版本:3.1.2
二、实验内容
安装Hive环境
- 完成Hive安装,根据实验1所安装的Hadoop模式,选择Hive的配置模式;
- 将Hive的配置文件详细清单列出;









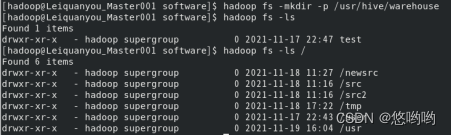
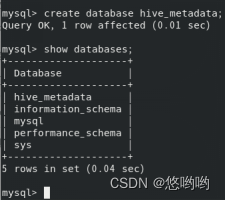
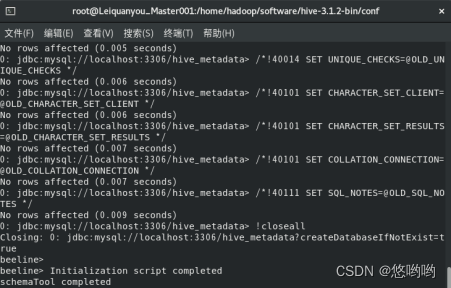
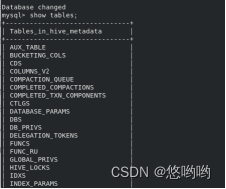
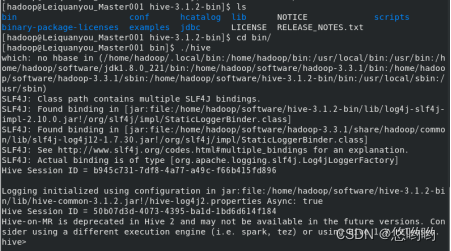
HiveQL练习
classid
dz1955001001
dz1955001001
dz1955001002
dz1955001002
dz1955002001
dz1955002001
dz1955002002
dz1955002002
dz1955003001
dz1955003001
dz1955003002
dz1955003002
dz1955004001
dz1955004001
dz1955004002
dz1955004002
完成以下操作:
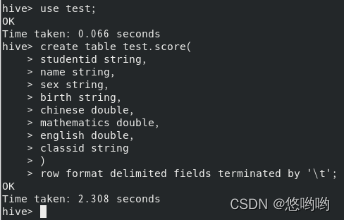
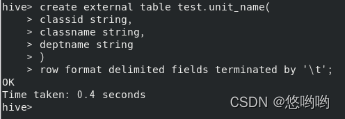
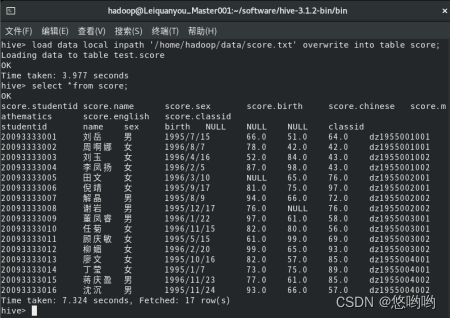
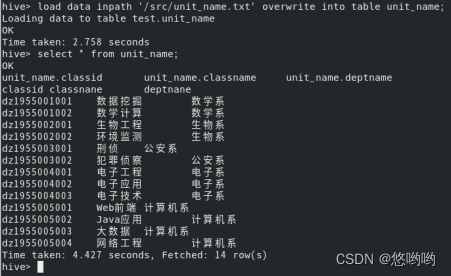
1.创建数据库(自己命名),score为内部表,unit_name为外部表,并加载数据。

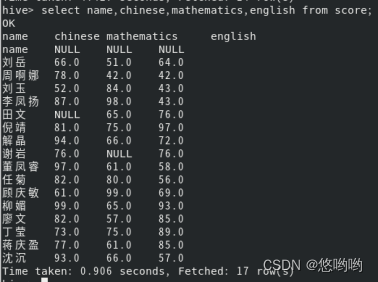
2.查询所有同学的语数英成绩
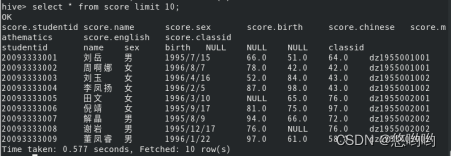
3.查看score表前十行数据
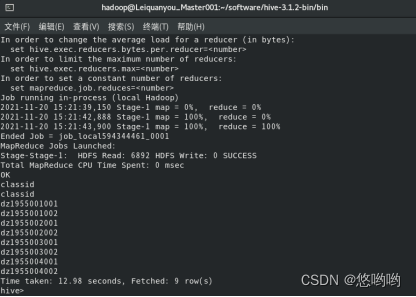
4.查看score表中不同的班级号
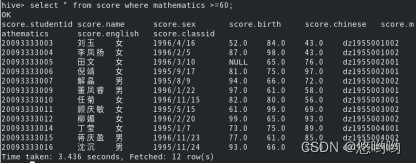
5.查看数学成绩及格的所有同学信息
6.查看各个班英语、数学成绩平均分
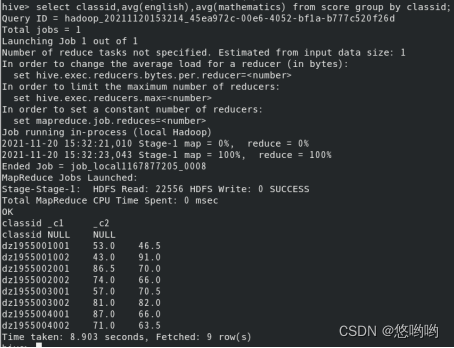
7.查看dz1955001002班的学生及语文成绩,并降序排序
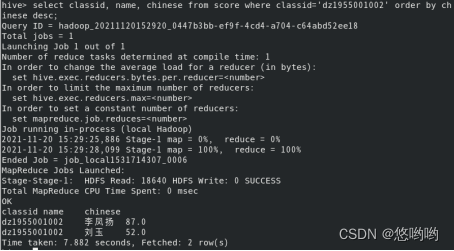
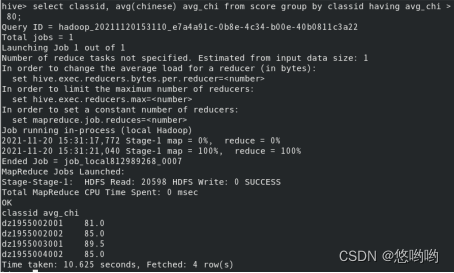
8.查看语文平均成绩大于80的班级
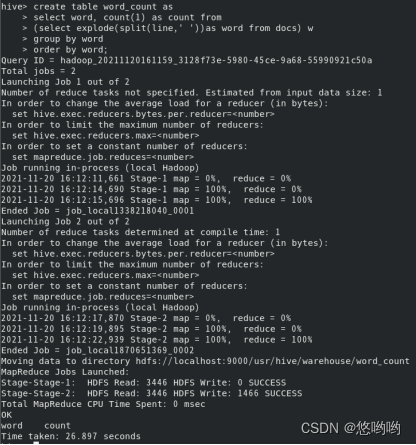
词频统计
重新使用实验2下载的英文短文,编写HiveQL程序,完成词频统计。要求给出代码及具体注释,程序运行结果截图。
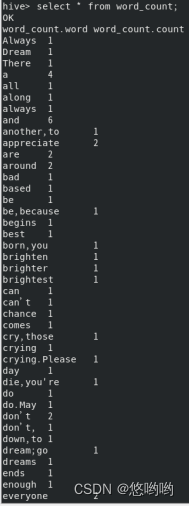
出现的问题
1.hive的使用。
解决办法:
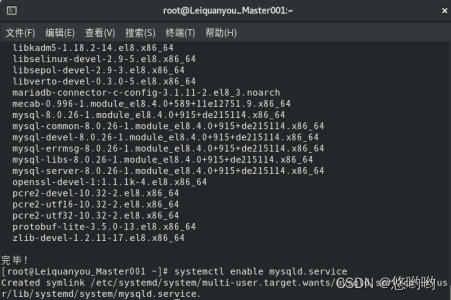
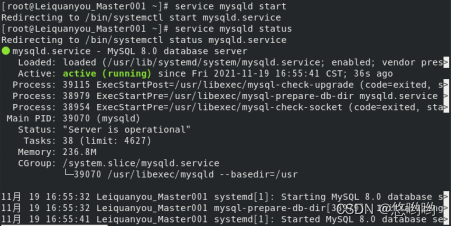
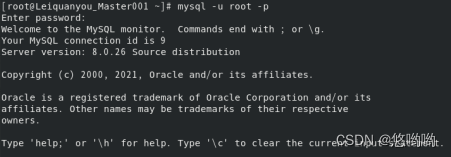
对于hive的使用,在hadoop集群里,先启动hadoop集群,再启动mysql服务,然后,再hive即可。
1、在hadoop安装目录下,sbin/start-all.sh。
2、在任何路径下,执行service mysql start (CentOS版本)、sudo /etc/init.d/mysql start (Ubuntu版本)
3、在hive安装目录下的bin下,./hive。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/686088
推荐阅读
相关标签

