
- 1开源大数据处理工具汇总(上)_大数据汇总
- 2报错Command failed with exit 128:git_command failed with exit code 128: git ls-remote -
- 3Apache Griffin - 数据质量监控工具_griffin数据质量
- 4Odoo|手把手教你Odoo集成drools,完成物料规则配置与报价单自动审核!
- 5超强AI绘画Midjourney-关键词(示例)
- 6最基本的 Git rebase解决分支合并 常用操作_.同一个分支可以用git rebase吗
- 7Jupyterlab+内网云穿透傻瓜式教程_windows miniforge安装
- 8什么是逻辑分析仪?逻辑分析仪的参数、使用步骤和优势
- 9itvbox如意版影视源码 支持苹果CMS资源 tvbox接口 全解最新版源码_tvbox最强接口源码
- 10c语言的二叉树的创建_c语言利用str串创建二叉链
模型汇总23 - 卷积神经网络中不同类型的卷积方式介绍_卷积神经网络卷积类型
赞
踩
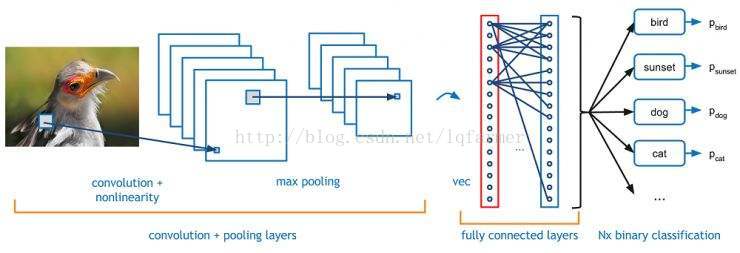
之前在文章《<模型汇总_1>牛逼的深度卷积神经网络CNN》详细介绍了卷积神经网络的基本原理,以及常见的基本模型,如LeNet,VGGNet,AlexNet,ReseNet,Inception Net的基本结构和原理。今天主要总结一下,卷积神经网络家族中,不同类型的卷积方式以及它们各自的优点。为了简单起见,我们仅从2维的角度介绍。
文末提供相关资料下载地址
卷积基本概念
首先,我们首先回顾一下卷积相关的基本概念,定义一个卷积层需要的几个参数。

2维卷积使用卷积核大小为3,步长为1和Padding
卷积核大小(Kernel Size):卷积核大小定义了卷积的视野。2维中的常见选择是3 - 即3x3像素矩阵。
步长(Stride):步长定义遍历图像时卷积核的移动的步长。虽然它的默认值通常为1,但我们可以使用值为2的步长来对类似于MaxPooling的图像进行下采样。
填充(Padding):填充定义如何处理样本的边界。Padding的目的是保持卷积操作的输出尺寸等于输入尺寸,因为如果卷积核大于1,则不加Padding会导致卷积操作的输出尺寸小于输入尺寸。
输入和输出通道(Channels):卷积层通常需要一定数量的输入通道(I),并计算一定数量的输出通道(O)。可以通过I * O * K来计算所需的参数,其中K等于卷积核中参数的数量,即卷积核大小。
下面介绍几种常见的卷积方式。
扩张卷积(Dilated Convolution)
(又称Atrous Convolution)

2维卷积,卷积核大小为3,扩张率(dilation rate)为2,无Padding
扩张卷积在进行卷积操作时引入了另一个参数,即扩张率,用以捕捉像素之间的long dependency。扩张率定义了卷积核中的值与值之间的间隔。扩张率为2的3x3卷积核将具有与与5x5卷积核相同的视野,而只使用9个参数。想象一下,使用一个5x5卷积核并删除第二行和列。
这样操作,使得在相同的计算成本下,卷积计算具有更宽的视野,可以捕捉更长的依赖关系。扩张卷积在实时图像分割领域特别受欢迎。适用于需要更加宽泛的视野并且不用多个卷积或更大的卷积核情况。
https://arxiv.org/abs/1609.03499
Fully Convoluted Network,论文下载地址https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf
可变形(Deformable)卷积
我们常见的卷积核(filter)一般都是呈长方形或正方形的,规则的卷积核往往会限制特征抽取的有效性,更为有效的做法是让卷积和具有任意的形状,那么卷积核是否可以呈圆形或者随意的形状呢?答案是可行的,如下图所示,典型的代表就是Deformable Convolution Network。
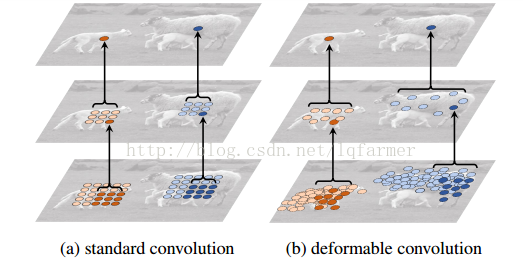
对比上图所示的a、b两图可以发现,任意形状的的卷积核使得网络可以重点关注一些重要的区域,更能有效且准确的抽取输入图像的特征。
怎么样来实现呢?

如上图所示,网络会根据原始的卷积,如图a所示,学习一个offset偏量,通过一些列的旋转、尺度变换、缩放等Transform变换,改变成成任意形状的卷积核,如b、c、d图所示。
Offet代表的Transform怎么实现呢?
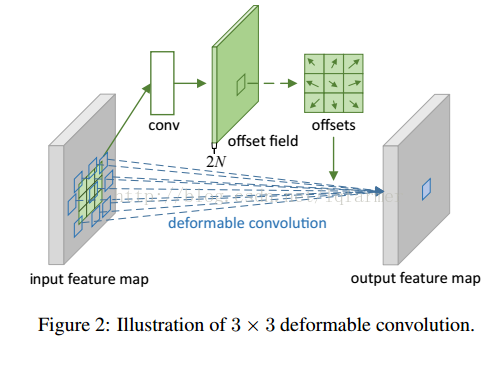
在deformable convolution中,会进行两次卷积,第一次卷积计算得到offset的卷积核,第二次是利用第一步得到的offset卷积核进行常规的卷积得到最终输出。重点是第一步中获得offset卷积核。先从input feature map中通过卷积(conv)计算得到offset field,在基于offset field得到最终的offset。注意,offset得到的输出通道数是input feature map的两倍,因为offset包含了在x和y两个方向上的偏置项。
具体细节可以看考Deformable convolution https://arxiv.org/abs/1703.06211
深度可分离(Depth Separable)卷积
在可分离的卷积中,我们可以将卷积核操作拆分成多个步骤。我们用y = conv(x,k)表示卷积,其中y是输出图像,x是输入图像,k是卷积核。接下来,假设k由公式:k = k1.dot(k2)计算。这就是一个可分离的卷积,因为我们可以使用大小分别为k1和k2两个卷积核进行2个1D卷积来取得相同的结果,而不是用一个大小k进行二维卷积。

Sobel X和Y卷积核
以Sobel卷积核为例,通常用于图像处理。我们可以通过向量[1,0,-1]乘以向量[1,2,1] 来获得相同的卷积核。执行相同的操作,只需要6而不是9个参数。
上面的例子就是所谓的空间可分离卷积,但在深度学习中并不是这样做的。这样介绍主要是举个例子,不至于使人迷惑。在神经网络中,通常使用称为深度可分离卷积的网络,典型的网络Xception Net,示意图如下图所示。

深度可分离卷积在执行空间卷积的同时,保持通道(Channels)之间分离,然后按照深度方向(depth)进行卷积。用一个例子来说明。
假设在16个输入通道和32个输出通道上,采用3x3卷积核进行卷积计算,16个通道上采用3x3卷积核,进行32次重复操作,产生512(16x32)个特征图(feature map)。然后,把这些特征图合并得到一个输出通道。重复执行32次,最终得到了32个输出通道。
对于同一个例子,采用深度可分离方式进行卷积,采用3x3卷积核分别遍历16个通道,最终得到16个特征图。现在,在进行合并操作之前,先采用32个1x1卷积个来遍历这16个特征图,然后再把它们合并到一起。采用可分离卷积,有656(16x3x3 + 16x32x1x1)参数,相反,传统卷积操作有4608(16x32x3x3)参数,大大减少了参数的数目。
该例子是一个典型的深度可分离卷积的例子,其中采用的深度乘数(Depth Multiplier)为1,也是一种最常见的设置。
这样做是基于一个假设,即平面和深度方向信息可以解耦。Xception网络证明了这个假设是有效的。因为可以有效地使用模型的参数,所以深度可分离的卷积可以用于可移动设备上。
典型的模型如Xception https://arxiv.org/abs/1610.02357
Squeeze-and-Excitation Convolution
Squeeze-and-Excitation 来源于ImageNet2017年的冠军网络SEnet。在传统的LeNet、Inception、ReseNet、DenseNet中,我们认为所有的特征通道(Channel)都是同等重要的,那是否可以给每个通道赋予一个权重呢?SEnet就通过Squeeze-and-Excitation block来实现了这一想法,当然CNN的网络结构十分灵活,还有很多其他简单的实现方式,这里就不一一列举。Squeeze-and-Excitation block(简称SES 模块)如下图所示。
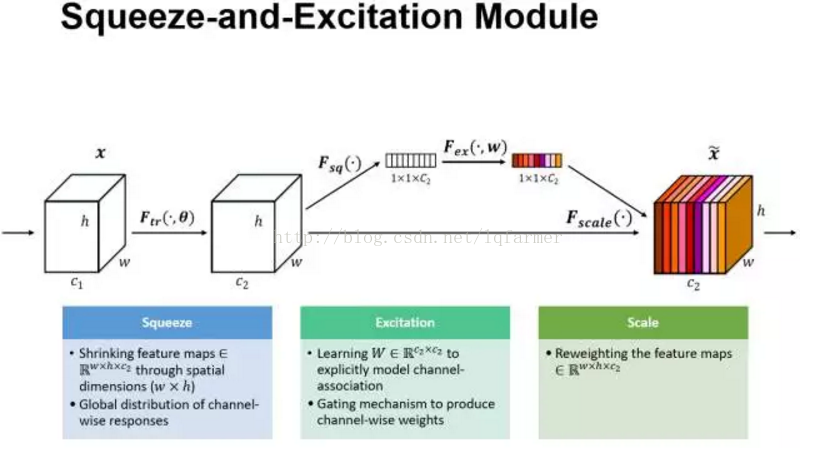
以图中为例,输入X具有C1数目的通道,经过一系列变换得到通道数为C2的SES模块的输入。数据进入SES模块分成两路,如图中,上面一路进行squeeze-excitation,Scale操作,下面一路进行传统的卷积操作。在上面一路中,首先是Squeeze操作,沿着通道C2方向,采用Global Average pooling操作,把尺寸c2 X h X W的输入pooling成一个c2 X 1 X 1的输出,即把每一个二维的特征图转换成一维的实数。Global Average pooling相当于一个全局的感受野,可以获取h X W整张图片信息,对应的标量输出可以代表整张图全局分布。然后进行Excitation操作,借鉴RNN中的Gate机制,为每一个通道赋予一个可训练的权重W,通过W的学习,来建模通道间的重要性。最后是一个Sacle操作,通过Reweight操作把学习的到权重得到传统的卷积得到的通道输出上,得到通道的输出特征的重标定操作。
https://arxiv.org/abs/1709.01507
转置(Transposed)卷积
(也称为deconvolutions 或 fractionally stride卷积)
有些场景下使用deconvolution,这中说法其实不太合适,因为它不是一个deconvolution,真正的deconvolution应该是卷积操作的逆过程。虽然deconvolution确实存在,但它们在深度学习领域并不常见。想象一下,将图像输入到单个卷积层。现在获得输出,把输出扔到一个黑盒子里,再恢复成的原始输入图像。这个黑盒子才叫做deconvolution。Deconvolution是卷积计算过程的逆计算过程。
转置卷积则比较贴切,因为转置会产生相同的空间分辨率。然而,真实执行的数学运算则稍有不同的。转置卷积层一方面会执行常规卷积,同时也会恢复其空间变换。
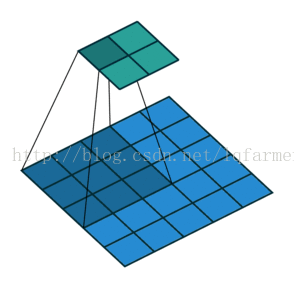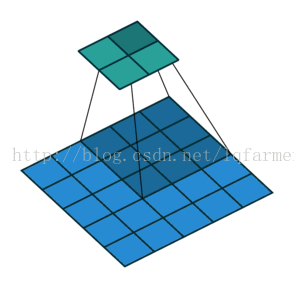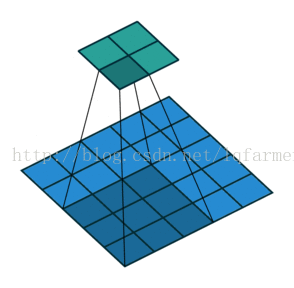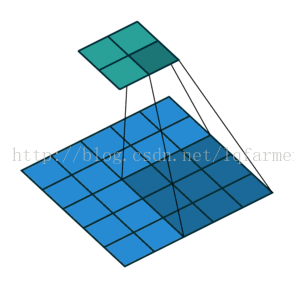
2维卷积无填充,步长为2和卷积核为3
这一点可能会让人觉得有点难以理解,所以我们来看一个具体的例子,如上图。5x5的图像被送入一个卷积层进行卷及计算。步长设置为2,没有填充,卷积核为3x3。输出为一个2x2图像。
如果我们想反转这个过程,我们需要进行数学逆运算,这样每一个输入的像素会产生9个输出值。之后,我们以步长为2的速度遍历输出图像。这将是一个deconvolution操作,如下图所示。

没有填充的2维卷积,步长为2和卷积核为3
转置卷积并不是这样做的。与上述操作相比,唯一的共同之处在于,它保证输出也将是5x5图像,同时仍然执行正常的卷积运算。为了实现这一点,我们需要在输入图像上进行一些漂亮的填充。
你可以想象,这一步不会重复上面的过程。至少,数值上不会。它只是通过一个卷积操作来重构卷积操作的输入。这并不是数学上的逆操作,只是一种Encoder-Decoder架构,但仍然非常有用。通过这种方式,我们可以通过一个卷积来放大一张图片,而不需要进行两个单独的操作。
https://buptldy.github.io/2016/10/29/2016-10-29-deconv/
文中介绍的模型相关论文下载地址:
链接: https://pan.baidu.com/s/1qYA0R8K
密码: 公众号回复“cov”
往期精彩内容推荐:
吴恩达-斯坦福CS229机器学习课程-2017(秋)最新课程分享
VAST最佳论文推荐-Tensorflow中深度学习模型可视化的研究
模型汇总22 机器学习相关基础数学理论、概念、模型思维导图分享
《模型汇总-20》深度学习背后的秘密:初学者指南-深度学习激活函数大全
纯干货13 2017年-李宏毅-最新深度学习/机器学习中文视频教程分享
纯干货11 强化学习(Reinforcement Learning)教材推荐
模型汇总17 基于Depthwise Separable Convolutions的Seq2Seq模型_SliceNet原理解析
模型汇总-14 多任务学习-Multitask Learning概述
<模型汇总-6>堆叠自动编码器Stacked_AutoEncoder-SAE
更多深度学习在NLP方面应用的经典论文、实践经验和最新消息,欢迎关注微信公众号“深度学习与NLP”或“DeepLearning_NLP”或扫描二维码添加关注。


